









tornado源码分析
本源码为tornado1.0版本
源码附带例子helloworld
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
from tornado.options import define, options
define("port", default=8888, help="run on the given port", type=int)
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
def main():
tornado.options.parse_command_line() # 解析配置文件
application = tornado.web.Application([ # 定义handler,并添加到app中并初始化app
(r"/", MainHandler),
])
http_server = tornado.httpserver.HTTPServer(application) # 将app传入server中并实例化
http_server.listen(options.port) # 配置监听的端口
tornado.ioloop.IOLoop.instance().start() # 运行开始
if __name__ == "__main__":
main()通过上述文件附带使用例子,可以看出tornado的主要构成就是由Application,HTTPServer,IOLoop这三个主要类进行请求的处理。
其中Application分析如下:
class Application(object):
def __init__(self, handlers=None, default_host="", transforms=None,
wsgi=False, **settings):
if transforms is None:
self.transforms = []
if settings.get("gzip"):
self.transforms.append(GZipContentEncoding) # 返回数据是否压缩
self.transforms.append(ChunkedTransferEncoding) # chunked返回
else:
self.transforms = transforms
self.handlers = [] # 处理的handlers
self.named_handlers = {}
self.default_host = default_host
self.settings = settings # 配置参数
self.ui_modules = {} # ui的模块
self.ui_methods = {} # ui的方法
self._wsgi = wsgi
self._load_ui_modules(settings.get("ui_modules", {})) # 加载ui模块
self._load_ui_methods(settings.get("ui_methods", {})) # 加载ui方法
if self.settings.get("static_path"): # 获取静态文件的配置
path = self.settings["static_path"] # 获取静态文件配置的文件夹
handlers = list(handlers or []) # 处理的handler
static_url_prefix = settings.get("static_url_prefix", # 获取静态文件的路由前缀
"/static/")
handlers = [
(re.escape(static_url_prefix) + r"(.*)", StaticFileHandler, # 添加静态文件的路由,并设置静态文件的处理handler
dict(path=path)),
(r"/(favicon\.ico)", StaticFileHandler, dict(path=path)), # 网站小图片的,路由配置
(r"/(robots\.txt)", StaticFileHandler, dict(path=path)), # 网站爬虫规范文件
] + handlers
if handlers: self.add_handlers(".*$", handlers) # 将handler添加进去
# Automatically reload modified modules
if self.settings.get("debug") and not wsgi: # 如果文件修改自动加载
import autoreload
autoreload.start()
def add_handlers(self, host_pattern, host_handlers):
"""Appends the given handlers to our handler list."""
if not host_pattern.endswith("$"):
host_pattern += "$"
handlers = []
# The handlers with the wildcard host_pattern are a special
# case - they're added in the constructor but should have lower
# precedence than the more-precise handlers added later.
# If a wildcard handler group exists, it should always be last
# in the list, so insert new groups just before it.
if self.handlers and self.handlers[-1][0].pattern == '.*$': # 保证最后一个url的匹配是'.*$',保证最新添加的在全部匹配之前
self.handlers.insert(-1, (re.compile(host_pattern), handlers))
else:
self.handlers.append((re.compile(host_pattern), handlers))
for spec in host_handlers: # 遍历handles
if type(spec) is type(()): # 保证每个spec是元组类型
assert len(spec) in (2, 3) # 保证每个spec的长度在2,3之间,如果有第三个参数则第三个参数为静态文件配置
pattern = spec[0] # 路由
handler = spec[1] # 相应路由处理的handler
if len(spec) == 3: # 如果处理参数有三个,
kwargs = spec[2] # 静态文件处理的数据存入,kwargs
else:
kwargs = {}
spec = URLSpec(pattern, handler, kwargs) # 将解析出来的三个参数,实例化一个URLSpec实例
handlers.append(spec) # 添加到handles列表中
if spec.name: # 处理有名字的handler
if spec.name in self.named_handlers:
logging.warning(
"Multiple handlers named %s; replacing previous value",
spec.name)
self.named_handlers[spec.name] = spec
def add_transform(self, transform_class):
"""Adds the given OutputTransform to our transform list."""
self.transforms.append(transform_class) # 添加处理数据传输转换的类
def _get_host_handlers(self, request):
host = request.host.lower().split(':')[0] # 获取request中的域名
for pattern, handlers in self.handlers: # 找出hanlders中,对应该域名的handlers
if pattern.match(host):
return handlers
# Look for default host if not behind load balancer (for debugging)
if "X-Real-Ip" not in request.headers:
for pattern, handlers in self.handlers:
if pattern.match(self.default_host):
return handlers
return None
def _load_ui_methods(self, methods):
if type(methods) is types.ModuleType:
self._load_ui_methods(dict((n, getattr(methods, n))
for n in dir(methods)))
elif isinstance(methods, list):
for m in methods: self._load_ui_methods(m)
else:
for name, fn in methods.iteritems():
if not name.startswith("_") and hasattr(fn, "__call__") \
and name[0].lower() == name[0]:
self.ui_methods[name] = fn
def _load_ui_modules(self, modules):
if type(modules) is types.ModuleType:
self._load_ui_modules(dict((n, getattr(modules, n))
for n in dir(modules)))
elif isinstance(modules, list):
for m in modules: self._load_ui_modules(m)
else:
assert isinstance(modules, dict)
for name, cls in modules.iteritems():
try:
if issubclass(cls, UIModule):
self.ui_modules[name] = cls
except TypeError:
pass
def __call__(self, request):
"""Called by HTTPServer to execute the request."""
transforms = [t(request) for t in self.transforms] # 当有数据进来处理时,如果同时有两个处理类,两个都处理
handler = None
args = []
kwargs = {}
handlers = self._get_host_handlers(request) # 获取request中的,域名配置,找出与域名匹配的处理handers
if not handlers:
handler = RedirectHandler(
request, "http://" + self.default_host + "/")
else:
for spec in handlers:
match = spec.regex.match(request.path) # 匹配当前请求的url
if match:
# None-safe wrapper around urllib.unquote to handle
# unmatched optional groups correctly
def unquote(s):
if s is None: return s
return urllib.unquote(s)
handler = spec.handler_class(self, request, **spec.kwargs) # 找出相应的handler
# Pass matched groups to the handler. Since
# match.groups() includes both named and unnamed groups,
# we want to use either groups or groupdict but not both.
kwargs = dict((k, unquote(v))
for (k, v) in match.groupdict().iteritems()) # 解析出相应的参数
if kwargs:
args = []
else:
args = [unquote(s) for s in match.groups()]
break
if not handler:
handler = ErrorHandler(self, request, 404)
# In debug mode, re-compile templates and reload static files on every
# request so you don't need to restart to see changes
if self.settings.get("debug"):
if getattr(RequestHandler, "_templates", None):
map(lambda loader: loader.reset(),
RequestHandler._templates.values())
RequestHandler._static_hashes = {}
handler._execute(transforms, *args, **kwargs) # 执行相应的方法
return handler
def reverse_url(self, name, *args):
"""Returns a URL path for handler named `name`
The handler must be added to the application as a named URLSpec
"""
if name in self.named_handlers:
return self.named_handlers[name].reverse(*args)
raise KeyError("%s not found in named urls" % name)
主要功能是注册处理请求的handler,将对应的url和handler进行匹配然后处理请求,配置静态文件路径,配置传输的格式等。
HTTPServer类分析如下
class HTTPServer(object):
def __init__(self, request_callback, no_keep_alive=False, io_loop=None,
xheaders=False, ssl_options=None):
"""Initializes the server with the given request callback.
If you use pre-forking/start() instead of the listen() method to
start your server, you should not pass an IOLoop instance to this
constructor. Each pre-forked child process will create its own
IOLoop instance after the forking process.
"""
self.request_callback = request_callback # 传入request-callback,就是application对象
self.no_keep_alive = no_keep_alive # 是保持连接
self.io_loop = io_loop # 循环loop对象
self.xheaders = xheaders
self.ssl_options = ssl_options # https证书文件配置
self._socket = None # server的socket实例
self._started = False
def listen(self, port, address=""):
self.bind(port, address) # 绑定端口
self.start(1) # 开始
def bind(self, port, address=""):
assert not self._socket # 当_socket实例为空继续执行
self._socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) # 生成实例socket
flags = fcntl.fcntl(self._socket.fileno(), fcntl.F_GETFD) # 这个句柄我在fork子进程后执行exec时就关闭
flags |= fcntl.FD_CLOEXEC # 涉及到close-on-exec
fcntl.fcntl(self._socket.fileno(), fcntl.F_SETFD, flags) #http://blog.csdn.net/chrovery/article/details/48545531
self._socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 设置端口可重用
self._socket.setblocking(0) # 设置server为非阻塞
self._socket.bind((address, port)) # 绑定端口
self._socket.listen(128) # 设置最大监听数量
def start(self, num_processes=1):
assert not self._started # 如果已经开始就不能再次开始
self._started = True
if num_processes is None or num_processes <= 0: # 启动的进程数量
# Use sysconf to detect the number of CPUs (cores)
try:
num_processes = os.sysconf("SC_NPROCESSORS_CONF") # 获取系统的cpu个数
except ValueError:
logging.error("Could not get num processors from sysconf; " # 如果获取失败就设置成一个进程
"running with one process") # http://blog.sina.com.cn/s/blog_9b0604b40101g049.html
num_processes = 1
if num_processes > 1 and ioloop.IOLoop.initialized(): # 如果进程数大于1,但是ioloop实力已经存在则不能创建多个,只能创建一个
logging.error("Cannot run in multiple processes: IOLoop instance "
"has already been initialized. You cannot call "
"IOLoop.instance() before calling start()")
num_processes = 1
if num_processes > 1: # 如果数量大于1
logging.info("Pre-forking %d server processes", num_processes)
for i in range(num_processes):
if os.fork() == 0:
self.io_loop = ioloop.IOLoop.instance() # 每生产一个进程就生成一个ioloop实例
self.io_loop.add_handler(
self._socket.fileno(), self._handle_events,
ioloop.IOLoop.READ) # 并将当前socket添加到监听读事件列表中
return
os.waitpid(-1, 0) # 如果子进程杀死,啥也不做,
else:
if not self.io_loop: # 如果只有一个实例
self.io_loop = ioloop.IOLoop.instance()
self.io_loop.add_handler(self._socket.fileno(),
self._handle_events,
ioloop.IOLoop.READ)
def stop(self):
self.io_loop.remove_handler(self._socket.fileno())
self._socket.close()
def _handle_events(self, fd, events):
while True: # socket注册的读事件
try:
connection, address = self._socket.accept() # 接受连接
except socket.error, e:
if e[0] in (errno.EWOULDBLOCK, errno.EAGAIN):
return
raise
if self.ssl_options is not None: # 如果配置了ssl
assert ssl, "Python 2.6+ and OpenSSL required for SSL"
connection = ssl.wrap_socket(
connection, server_side=True, **self.ssl_options) # 对连接进行ssl处理
try:
stream = iostream.IOStream(connection, io_loop=self.io_loop) # 调用IOStream进行处理
HTTPConnection(stream, address, self.request_callback, # 实例化处理的stream
self.no_keep_alive, self.xheaders)
except:
logging.error("Error in connection callback", exc_info=True)HTTPServer类在默认情况下启动就启动一个进程,初始化监听的端口,生成相应的server并将server加入到ioloop的监听列表中,监听处理的时间。
当server接受到请求的时候的处理:
stream = iostream.IOStream(connection, io_loop=self.io_loop) # 调用IOStream进行处理
HTTPConnection(stream, address, self.request_callback, # 实例化处理的stream
self.no_keep_alive, self.xheaders)其中IOStream类分析如下:
class IOStream(object):
def __init__(self, socket, io_loop=None, max_buffer_size=104857600,
read_chunk_size=4096):
self.socket = socket # 接受的新连接
self.socket.setblocking(False) # 连接设置为非阻塞
self.io_loop = io_loop or ioloop.IOLoop.instance() # io_loop实例
self.max_buffer_size = max_buffer_size # 最大缓存区大小
self.read_chunk_size = read_chunk_size # 读的最大缓存区大小
self._read_buffer = "" # 读到的数据
self._write_buffer = "" # 写出的数据
self._read_delimiter = None # 读的终止符
self._read_bytes = None
self._read_callback = None
self._write_callback = None
self._close_callback = None
self._state = self.io_loop.ERROR
self.io_loop.add_handler(
self.socket.fileno(), self._handle_events, self._state) # 注册到io_loop的错误事件中, 注册self._handle_events函数该函数可以处理可读可写出错事件
def read_until(self, delimiter, callback):
"""Call callback when we read the given delimiter."""
assert not self._read_callback, "Already reading"
loc = self._read_buffer.find(delimiter) # 在read_buffer中查找该 delimiter
if loc != -1: # 如果找到该标志
self._run_callback(callback, self._consume(loc + len(delimiter))) # 找到就消费掉
return
self._check_closed() # 检查是否关闭
self._read_delimiter = delimiter # 设置读取的终止符
self._read_callback = callback # request_callback函数
self._add_io_state(self.io_loop.READ) # 在io_loop中注册读方法
def read_bytes(self, num_bytes, callback):
"""Call callback when we read the given number of bytes."""
assert not self._read_callback, "Already reading"
if len(self._read_buffer) >= num_bytes:
callback(self._consume(num_bytes))
return
self._check_closed()
self._read_bytes = num_bytes
self._read_callback = callback
self._add_io_state(self.io_loop.READ)
def write(self, data, callback=None):
"""Write the given data to this stream.
If callback is given, we call it when all of the buffered write
data has been successfully written to the stream. If there was
previously buffered write data and an old write callback, that
callback is simply overwritten with this new callback.
"""
self._check_closed()
self._write_buffer += data # 将要发送的数据添加到缓冲区中
self._add_io_state(self.io_loop.WRITE) # 更改事件为写事件
self._write_callback = callback
def set_close_callback(self, callback):
"""Call the given callback when the stream is closed."""
self._close_callback = callback
def close(self):
"""Close this stream."""
if self.socket is not None:
self.io_loop.remove_handler(self.socket.fileno()) # 移除该事件监听
self.socket.close() # 关闭连接
self.socket = None # 设置为空
if self._close_callback: # 如果注册了关闭回调函数则执行该回调函数
self._run_callback(self._close_callback)
def reading(self):
"""Returns true if we are currently reading from the stream."""
return self._read_callback is not None
def writing(self):
"""Returns true if we are currently writing to the stream."""
return len(self._write_buffer) > 0 # 如果写出缓冲区里面有数据
def closed(self):
return self.socket is None
def _handle_events(self, fd, events):
if not self.socket:
logging.warning("Got events for closed stream %d", fd)
return
if events & self.io_loop.READ:
self._handle_read() # 处理读事件
if not self.socket: # 如果socket没有则停止执行
return
if events & self.io_loop.WRITE:
self._handle_write() # 处理写状态
if not self.socket:
return
if events & self.io_loop.ERROR: # 处理出错状态
self.close()
return
state = self.io_loop.ERROR # 更新状态
if self._read_delimiter or self._read_bytes: # 如果有读取的终止符或者读取的字节数有设置,则继续设置为读状态
state |= self.io_loop.READ
if self._write_buffer: # 如果写出的缓冲区有数据则写出
state |= self.io_loop.WRITE
if state != self._state: # 如果状态有更新
self._state = state
self.io_loop.update_handler(self.socket.fileno(), self._state) # 更新io_loop中的监听事件
def _run_callback(self, callback, *args, **kwargs):
try:
callback(*args, **kwargs) # 调用注册事件的处理函数
except:
# Close the socket on an uncaught exception from a user callback
# (It would eventually get closed when the socket object is
# gc'd, but we don't want to rely on gc happening before we
# run out of file descriptors)
self.close()
# Re-raise the exception so that IOLoop.handle_callback_exception
# can see it and log the error
raise
def _handle_read(self):
try:
chunk = self.socket.recv(self.read_chunk_size) # 读取read_chunk_size大小的数据
except socket.error, e:
if e[0] in (errno.EWOULDBLOCK, errno.EAGAIN):
return
else:
logging.warning("Read error on %d: %s",
self.socket.fileno(), e)
self.close()
return
if not chunk: # 如果没有数据则关闭
self.close()
return
self._read_buffer += chunk # 将读入的数据添加到读入缓冲区
if len(self._read_buffer) >= self.max_buffer_size: # 如果已经接受的数据大小已经超过设置的缓冲区大小则放弃该请求处理
logging.error("Reached maximum read buffer size")
self.close()
return
if self._read_bytes: # 如果设置了读多少字节
if len(self._read_buffer) >= self._read_bytes: # 如果缓冲区数据大于设置的读字节数
num_bytes = self._read_bytes
callback = self._read_callback
self._read_callback = None
self._read_bytes = None
self._run_callback(callback, self._consume(num_bytes)) # 用回调函数处理相应字节数的数据
elif self._read_delimiter: # 如果设置了读取终止位符号
loc = self._read_buffer.find(self._read_delimiter) # 从缓冲区中找该标志位
if loc != -1: # 如果找到
callback = self._read_callback
delimiter_len = len(self._read_delimiter)
self._read_callback = None
self._read_delimiter = None
self._run_callback(callback,
self._consume(loc + delimiter_len)) # 用注册的回调函数处理在该终止位之前的所有数据
def _handle_write(self):
while self._write_buffer:
try:
num_bytes = self.socket.send(self._write_buffer) # 发送相应的数据给客户端
self._write_buffer = self._write_buffer[num_bytes:] # 将_write_buffer更新为剩余的数据
except socket.error, e:
if e[0] in (errno.EWOULDBLOCK, errno.EAGAIN):
break
else:
logging.warning("Write error on %d: %s",
self.socket.fileno(), e)
self.close()
return
if not self._write_buffer and self._write_callback: # 如果写缓冲区已经清空,并且有写完注册函数
callback = self._write_callback
self._write_callback = None
self._run_callback(callback) # 执行回调函数
def _consume(self, loc):
result = self._read_buffer[:loc] # 读取相应loc的数据
self._read_buffer = self._read_buffer[loc:] # 将_read_buffer设置成剩余还没读取的数据
return result
def _check_closed(self):
if not self.socket:
raise IOError("Stream is closed")
def _add_io_state(self, state):
if not self._state & state:
self._state = self._state | state
self.io_loop.update_handler(self.socket.fileno(), self._state) # 更新io_loop中相应的状态
该类的主要功能就是将请求处理的时候,通过新接受的socket,然后接受和发送处理的数据,更改socket的状态。
接着就通过HTTPConnection来处理:
class HTTPConnection(object):
"""Handles a connection to an HTTP client, executing HTTP requests.
We parse HTTP headers and bodies, and execute the request callback
until the HTTP conection is closed.
"""
def __init__(self, stream, address, request_callback, no_keep_alive=False,
xheaders=False):
self.stream = stream # 实例化的stream实例
self.address = address # 接受的地址
self.request_callback = request_callback # request_callback函数
self.no_keep_alive = no_keep_alive # 是否继续存活
self.xheaders = xheaders
self._request = None
self._request_finished = False
self.stream.read_until("\r\n\r\n", self._on_headers) # 调用stream实例中的方法,读取出请求的头部信息
def write(self, chunk):
assert self._request, "Request closed"
if not self.stream.closed():
self.stream.write(chunk, self._on_write_complete) # 调用stream中的写方法,写完调用_on_write_complete方法
def finish(self):
assert self._request, "Request closed"
self._request_finished = True
if not self.stream.writing(): # 如果写出缓冲区中已经没有数据
self._finish_request()
def _on_write_complete(self):
if self._request_finished:
self._finish_request()
def _finish_request(self):
if self.no_keep_alive: # 如果不继续连接为真
disconnect = True # 则断开连接
else:
connection_header = self._request.headers.get("Connection") # 获取请求头部信息中的Connection
if self._request.supports_http_1_1(): # 支持http1.1
disconnect = connection_header == "close" # 如果连接设置成close则关闭连接
elif ("Content-Length" in self._request.headers # 如果不支持http1.1,检查请求方法
or self._request.method in ("HEAD", "GET")):
disconnect = connection_header != "Keep-Alive" # 判断是否是keep-alive
else:
disconnect = True # 断开连接为true
self._request = None
self._request_finished = False
if disconnect:
self.stream.close() # 如果断开连接为真,则关闭连接
return
self.stream.read_until("\r\n\r\n", self._on_headers) # 如果继续处理请求则,注册读事件
def _on_headers(self, data):
eol = data.find("\r\n") # 找到第一个请求行
start_line = data[:eol] # 获取第一行的内容
method, uri, version = start_line.split(" ") # 获取方法,uri, http版本号
if not version.startswith("HTTP/"):
raise Exception("Malformed HTTP version in HTTP Request-Line")
headers = httputil.HTTPHeaders.parse(data[eol:]) # 将剩余的数据,传入并解析http头数据
self._request = HTTPRequest(
connection=self, method=method, uri=uri, version=version,
headers=headers, remote_ip=self.address[0]) # 实例化出一个request对象
content_length = headers.get("Content-Length") # 如果头部数据中有长度信息
if content_length:
content_length = int(content_length)
if content_length > self.stream.max_buffer_size: # 如果长度大于设置的接受缓冲区大小则报错
raise Exception("Content-Length too long")
if headers.get("Expect") == "100-continue": # 如果获取是继续传送
self.stream.write("HTTP/1.1 100 (Continue)\r\n\r\n") # 直接发送该报文给客户端
self.stream.read_bytes(content_length, self._on_request_body) # 读取相应字节数的数据,读完后设置_on_request_body处理该数据
return
self.request_callback(self._request) # 执行application方法
def _on_request_body(self, data):
self._request.body = data
content_type = self._request.headers.get("Content-Type", "") # 获取提交数据的类型
if self._request.method == "POST": # 如果提交方法为post
if content_type.startswith("application/x-www-form-urlencoded"): # form提交数据
arguments = cgi.parse_qs(self._request.body)
for name, values in arguments.iteritems():
values = [v for v in values if v]
if values:
self._request.arguments.setdefault(name, []).extend(
values)
elif content_type.startswith("multipart/form-data"): # 如果form提交数据并且里面是多个不同类型数据上传
if 'boundary=' in content_type:
boundary = content_type.split('boundary=',1)[1]
if boundary: self._parse_mime_body(boundary, data) #通过boundary解析出相应数据
else:
logging.warning("Invalid multipart/form-data")
self.request_callback(self._request) # 执行application方法
def _parse_mime_body(self, boundary, data):
# The standard allows for the boundary to be quoted in the header,
# although it's rare (it happens at least for google app engine
# xmpp). I think we're also supposed to handle backslash-escapes
# here but I'll save that until we see a client that uses them
# in the wild.
if boundary.startswith('"') and boundary.endswith('"'): # 解析每个boundary边界
boundary = boundary[1:-1]
if data.endswith("\r\n"):
footer_length = len(boundary) + 6
else:
footer_length = len(boundary) + 4
parts = data[:-footer_length].split("--" + boundary + "\r\n")
for part in parts:
if not part: continue
eoh = part.find("\r\n\r\n")
if eoh == -1:
logging.warning("multipart/form-data missing headers")
continue
headers = httputil.HTTPHeaders.parse(part[:eoh])
name_header = headers.get("Content-Disposition", "")
if not name_header.startswith("form-data;") or \
not part.endswith("\r\n"):
logging.warning("Invalid multipart/form-data")
continue
value = part[eoh + 4:-2]
name_values = {}
for name_part in name_header[10:].split(";"):
name, name_value = name_part.strip().split("=", 1)
name_values[name] = name_value.strip('"').decode("utf-8")
if not name_values.get("name"):
logging.warning("multipart/form-data value missing name")
continue
name = name_values["name"]
if name_values.get("filename"):
ctype = headers.get("Content-Type", "application/unknown")
self._request.files.setdefault(name, []).append(dict(
filename=name_values["filename"], body=value,
content_type=ctype))
else:
self._request.arguments.setdefault(name, []).append(value)先在ioloop中注册注册该socket的读事件,第一次只读取请求的头部数据,并解析头部数据,根据请求的方法再判断是否有提交的内容如果有提交的内容就解析该提交的内容,如果没有就解析头部信息即可。
在解析完成请求后,通过HTTPRequest类来将解析的数据进行封装。
class HTTPRequest(object):
"""A single HTTP request.
GET/POST arguments are available in the arguments property, which
maps arguments names to lists of values (to support multiple values
for individual names). Names and values are both unicode always.
File uploads are available in the files property, which maps file
names to list of files. Each file is a dictionary of the form
{"filename":..., "content_type":..., "body":...}. The content_type
comes from the provided HTTP header and should not be trusted
outright given that it can be easily forged.
An HTTP request is attached to a single HTTP connection, which can
be accessed through the "connection" attribute. Since connections
are typically kept open in HTTP/1.1, multiple requests can be handled
sequentially on a single connection.
"""
def __init__(self, method, uri, version="HTTP/1.0", headers=None,
body=None, remote_ip=None, protocol=None, host=None,
files=None, connection=None):
self.method = method # 方法
self.uri = uri # uri
self.version = version # http版本
self.headers = headers or httputil.HTTPHeaders() # 头部数据
self.body = body or "" # 提交内容
if connection and connection.xheaders:
# Squid uses X-Forwarded-For, others use X-Real-Ip
self.remote_ip = self.headers.get(
"X-Real-Ip", self.headers.get("X-Forwarded-For", remote_ip)) # 获取远端访问ip,该情况是出现代理
self.protocol = self.headers.get("X-Scheme", protocol) or "http"
else:
self.remote_ip = remote_ip # 获取远端ip
self.protocol = protocol or "http" # 协议
self.host = host or self.headers.get("Host") or "127.0.0.1" # 如果没有ip 则默认本机
self.files = files or {} # 文件
self.connection = connection # 连接实例
self._start_time = time.time() # 开始处理时间
self._finish_time = None # 完成时间
scheme, netloc, path, query, fragment = urlparse.urlsplit(uri) # 解析出uri上面的参数
self.path = path # http://www.cnblogs.com/cemaster/p/6435711.html
self.query = query
arguments = cgi.parse_qs(query)
self.arguments = {}
for name, values in arguments.iteritems():
values = [v for v in values if v]
if values: self.arguments[name] = values # 如果解析出数据则,添加到self.arguments字典中
def supports_http_1_1(self):
"""Returns True if this request supports HTTP/1.1 semantics"""
return self.version == "HTTP/1.1"
def write(self, chunk):
"""Writes the given chunk to the response stream."""
assert isinstance(chunk, str)
self.connection.write(chunk) # 写数据
def finish(self):
"""Finishes this HTTP request on the open connection."""
self.connection.finish() # 结束该次请求
self._finish_time = time.time() # 完成时间
def full_url(self):
"""Reconstructs the full URL for this request."""
return self.protocol + "://" + self.host + self.uri # 该次请求完整的url
def request_time(self):
"""Returns the amount of time it took for this request to execute."""
if self._finish_time is None:
return time.time() - self._start_time
else:
return self._finish_time - self._start_time # 返回该次请求处理的时间
def __repr__(self):
attrs = ("protocol", "host", "method", "uri", "version", "remote_ip",
"remote_ip", "body")
args = ", ".join(["%s=%r" % (n, getattr(self, n)) for n in attrs])
return "%s(%s, headers=%s)" % (
self.__class__.__name__, args, dict(self.headers))接受请求处理数据的流程已经分析完成,接下来就分析ioloop的处理,来分析数据的发送出去的过程。
class IOLoop(object):
# Constants from the epoll module
_EPOLLIN = 0x001
_EPOLLPRI = 0x002
_EPOLLOUT = 0x004
_EPOLLERR = 0x008
_EPOLLHUP = 0x010
_EPOLLRDHUP = 0x2000
_EPOLLONESHOT = (1 << 30)
_EPOLLET = (1 << 31)
# Our events map exactly to the epoll events
NONE = 0
READ = _EPOLLIN
WRITE = _EPOLLOUT
ERROR = _EPOLLERR | _EPOLLHUP | _EPOLLRDHUP
def __init__(self, impl=None):
self._impl = impl or _poll()
if hasattr(self._impl, 'fileno'):
self._set_close_exec(self._impl.fileno())
self._handlers = {}
self._events = {}
self._callbacks = set()
self._timeouts = []
self._running = False
self._stopped = False
self._blocking_log_threshold = None
# Create a pipe that we send bogus data to when we want to wake
# the I/O loop when it is idle
if os.name != 'nt':
r, w = os.pipe() # 打开管道操作
self._set_nonblocking(r)
self._set_nonblocking(w)
self._set_close_exec(r)
self._set_close_exec(w)
self._waker_reader = os.fdopen(r, "r", 0)
self._waker_writer = os.fdopen(w, "w", 0)
else:
self._waker_reader = self._waker_writer = win32_support.Pipe()
r = self._waker_writer.reader_fd
self.add_handler(r, self._read_waker, self.READ) # 将管道的读句柄加入读事件
@classmethod
def instance(cls):
"""Returns a global IOLoop instance.
Most single-threaded applications have a single, global IOLoop.
Use this method instead of passing around IOLoop instances
throughout your code.
A common pattern for classes that depend on IOLoops is to use
a default argument to enable programs with multiple IOLoops
but not require the argument for simpler applications:
class MyClass(object):
def __init__(self, io_loop=None):
self.io_loop = io_loop or IOLoop.instance()
"""
if not hasattr(cls, "_instance"): # 实现的单例模式
cls._instance = cls()
return cls._instance
@classmethod
def initialized(cls):
return hasattr(cls, "_instance") # 判断是否有_instance属性
def add_handler(self, fd, handler, events):
"""Registers the given handler to receive the given events for fd."""
self._handlers[fd] = handler # 保存该fd对应的handler
self._impl.register(fd, events | self.ERROR) # 注册事件
def update_handler(self, fd, events):
"""Changes the events we listen for fd."""
self._impl.modify(fd, events | self.ERROR) # 更新fd的注册事件
def remove_handler(self, fd):
"""Stop listening for events on fd."""
self._handlers.pop(fd, None) # 移除监听列表该文件描述符
self._events.pop(fd, None) # 移除事件列表中该事件的处理函数
try:
self._impl.unregister(fd) # 取消该fd的监听事件
except (OSError, IOError):
logging.debug("Error deleting fd from IOLoop", exc_info=True)
def set_blocking_log_threshold(self, s):
"""Logs a stack trace if the ioloop is blocked for more than s seconds.
Pass None to disable. Requires python 2.6 on a unixy platform.
"""
if not hasattr(signal, "setitimer"):
logging.error("set_blocking_log_threshold requires a signal module "
"with the setitimer method")
return
self._blocking_log_threshold = s
if s is not None:
signal.signal(signal.SIGALRM, self._handle_alarm)
def _handle_alarm(self, signal, frame):
logging.warning('IOLoop blocked for %f seconds in\n%s',
self._blocking_log_threshold,
''.join(traceback.format_stack(frame)))
def start(self):
"""Starts the I/O loop.
The loop will run until one of the I/O handlers calls stop(), which
will make the loop stop after the current event iteration completes.
"""
if self._stopped:
self._stopped = False
return
self._running = True
while True: # 开始运行
# Never use an infinite timeout here - it can stall epoll
poll_timeout = 0.2
# Prevent IO event starvation by delaying new callbacks
# to the next iteration of the event loop.
callbacks = list(self._callbacks) # 回调函数列表
for callback in callbacks:
# A callback can add or remove other callbacks
if callback in self._callbacks:
self._callbacks.remove(callback)
self._run_callback(callback) # 如果有回调函数就执行该回调函数
if self._callbacks: # 如果有回调函数则优先执行该函数
poll_timeout = 0.0
if self._timeouts: # 如果设置了过期执行回调则执行
now = time.time()
while self._timeouts and self._timeouts[0].deadline <= now: # 如果设置的时间没有到期
timeout = self._timeouts.pop(0) # 找出该事件
self._run_callback(timeout.callback) # 执行对应的回调方法
if self._timeouts:
milliseconds = self._timeouts[0].deadline - now
poll_timeout = min(milliseconds, poll_timeout) # 判断该时间后回调执行完成后的时间,选择最小的时间作为轮训时间
if not self._running: # 如果没有运行则退出
break
if self._blocking_log_threshold is not None:
# clear alarm so it doesn't fire while poll is waiting for
# events.
signal.setitimer(signal.ITIMER_REAL, 0, 0)
try:
event_pairs = self._impl.poll(poll_timeout) # 轮训事件
except Exception, e:
# Depending on python version and IOLoop implementation,
# different exception types may be thrown and there are
# two ways EINTR might be signaled:
# * e.errno == errno.EINTR
# * e.args is like (errno.EINTR, 'Interrupted system call')
if (getattr(e, 'errno') == errno.EINTR or
(isinstance(getattr(e, 'args'), tuple) and
len(e.args) == 2 and e.args[0] == errno.EINTR)):
logging.warning("Interrupted system call", exc_info=1)
continue
else:
raise
if self._blocking_log_threshold is not None:
signal.setitimer(signal.ITIMER_REAL,
self._blocking_log_threshold, 0)
# Pop one fd at a time from the set of pending fds and run
# its handler. Since that handler may perform actions on
# other file descriptors, there may be reentrant calls to
# this IOLoop that update self._events
self._events.update(event_pairs) # 更新未处理时间到列表中
while self._events:
fd, events = self._events.popitem() # 处理第一个事件
try:
self._handlers[fd](fd, events) # 处理对应连接的回调函数 对应iostream中的_handle_events方法
except (KeyboardInterrupt, SystemExit):
raise
except (OSError, IOError), e:
if e[0] == errno.EPIPE:
# Happens when the client closes the connection
pass
else:
logging.error("Exception in I/O handler for fd %d",
fd, exc_info=True)
except:
logging.error("Exception in I/O handler for fd %d",
fd, exc_info=True)
# reset the stopped flag so another start/stop pair can be issued
self._stopped = False
if self._blocking_log_threshold is not None:
signal.setitimer(signal.ITIMER_REAL, 0, 0)
def stop(self):
"""Stop the loop after the current event loop iteration is complete.
If the event loop is not currently running, the next call to start()
will return immediately.
To use asynchronous methods from otherwise-synchronous code (such as
unit tests), you can start and stop the event loop like this:
ioloop = IOLoop()
async_method(ioloop=ioloop, callback=ioloop.stop)
ioloop.start()
ioloop.start() will return after async_method has run its callback,
whether that callback was invoked before or after ioloop.start.
"""
self._running = False
self._stopped = True
self._wake()
def running(self):
"""Returns true if this IOLoop is currently running."""
return self._running
def add_timeout(self, deadline, callback):
"""Calls the given callback at the time deadline from the I/O loop."""
timeout = _Timeout(deadline, callback) # 添加过期时间执行的回调函数
bisect.insort(self._timeouts, timeout) # 把该实例添加到列表中
return timeout
def remove_timeout(self, timeout):
self._timeouts.remove(timeout) # 移除该过期的事件
def add_callback(self, callback):
"""Calls the given callback on the next I/O loop iteration."""
self._callbacks.add(callback) # 添加回调函数
self._wake()
def remove_callback(self, callback):
"""Removes the given callback from the next I/O loop iteration."""
self._callbacks.remove(callback) # 移除回调函数
def _wake(self):
try:
self._waker_writer.write("x")
except IOError:
pass
def _run_callback(self, callback):
try:
callback() # 执行回调函数
except (KeyboardInterrupt, SystemExit):
raise
except:
self.handle_callback_exception(callback)
def handle_callback_exception(self, callback):
"""This method is called whenever a callback run by the IOLoop
throws an exception.
By default simply logs the exception as an error. Subclasses
may override this method to customize reporting of exceptions.
The exception itself is not passed explicitly, but is available
in sys.exc_info.
"""
logging.error("Exception in callback %r", callback, exc_info=True)
def _read_waker(self, fd, events):
try:
while True:
self._waker_reader.read()
except IOError:
pass
def _set_nonblocking(self, fd):
flags = fcntl.fcntl(fd, fcntl.F_GETFL)
fcntl.fcntl(fd, fcntl.F_SETFL, flags | os.O_NONBLOCK) # 设置成非阻塞方式
def _set_close_exec(self, fd):
flags = fcntl.fcntl(fd, fcntl.F_GETFD)
fcntl.fcntl(fd, fcntl.F_SETFD, flags | fcntl.FD_CLOEXEC) # 设置成在子进程执行就关闭设置
class _Timeout(object):
"""An IOLoop timeout, a UNIX timestamp and a callback"""
# Reduce memory overhead when there are lots of pending callbacks
__slots__ = ['deadline', 'callback']
def __init__(self, deadline, callback):
self.deadline = deadline
self.callback = callback
def __cmp__(self, other):
return cmp((self.deadline, id(self.callback)),
(other.deadline, id(other.callback))) # 比较最后需要死亡的时间ioloop的轮训,接受处理的请求,通过注册回调函数处理相应函数。
当在HTTPConnection类中的_on_headers或者_on_request_body最后一行执行
self.request_callback(self._request) 时就调用了Application类中的call方法:
def __call__(self, request):
"""Called by HTTPServer to execute the request."""
transforms = [t(request) for t in self.transforms] # 当有数据进来处理时,如果同时有两个处理类,两个都处理
handler = None
args = []
kwargs = {}
handlers = self._get_host_handlers(request) # 获取request中的,域名配置,找出与域名匹配的处理handers
if not handlers:
handler = RedirectHandler(
request, "http://" + self.default_host + "/")
else:
for spec in handlers:
match = spec.regex.match(request.path) # 匹配当前请求的url
if match:
# None-safe wrapper around urllib.unquote to handle
# unmatched optional groups correctly
def unquote(s):
if s is None: return s
return urllib.unquote(s)
handler = spec.handler_class(self, request, **spec.kwargs) # 找出相应的handler
# Pass matched groups to the handler. Since
# match.groups() includes both named and unnamed groups,
# we want to use either groups or groupdict but not both.
kwargs = dict((k, unquote(v))
for (k, v) in match.groupdict().iteritems()) # 解析出相应的参数
if kwargs:
args = []
else:
args = [unquote(s) for s in match.groups()]
break
if not handler:
handler = ErrorHandler(self, request, 404)
# In debug mode, re-compile templates and reload static files on every
# request so you don't need to restart to see changes
if self.settings.get("debug"):
if getattr(RequestHandler, "_templates", None):
map(lambda loader: loader.reset(),
RequestHandler._templates.values())
RequestHandler._static_hashes = {}
handler._execute(transforms, *args, **kwargs) # 执行相应的方法
return handler执行到
handler._execute(transforms, *args, **kwargs)时,通过uri的匹配找到相应的handler,然后调用handler._execute方法来执行。
我们分析一下handler类,分析如下:
class RequestHandler(object): # 处理handler
"""Subclass this class and define get() or post() to make a handler.
If you want to support more methods than the standard GET/HEAD/POST, you
should override the class variable SUPPORTED_METHODS in your
RequestHandler class.
"""
SUPPORTED_METHODS = ("GET", "HEAD", "POST", "DELETE", "PUT")
def __init__(self, application, request, transforms=None):
self.application = application
self.request = request
self._headers_written = False
self._finished = False
self._auto_finish = True
self._transforms = transforms or []
self.ui = _O((n, self._ui_method(m)) for n, m in
application.ui_methods.iteritems())
self.ui["modules"] = _O((n, self._ui_module(n, m)) for n, m in
application.ui_modules.iteritems())
self.clear()
# Check since connection is not available in WSGI
if hasattr(self.request, "connection"):
self.request.connection.stream.set_close_callback(
self.on_connection_close)
@property
def settings(self):
return self.application.settings
def head(self, *args, **kwargs):
raise HTTPError(405)
def get(self, *args, **kwargs):
raise HTTPError(405)
def post(self, *args, **kwargs):
raise HTTPError(405)
def delete(self, *args, **kwargs):
raise HTTPError(405)
def put(self, *args, **kwargs):
raise HTTPError(405)
def prepare(self):
"""Called before the actual handler method.
Useful to override in a handler if you want a common bottleneck for
all of your requests.
"""
pass
def on_connection_close(self):
"""Called in async handlers if the client closed the connection.
You may override this to clean up resources associated with
long-lived connections.
Note that the select()-based implementation of IOLoop does not detect
closed connections and so this method will not be called until
you try (and fail) to produce some output. The epoll- and kqueue-
based implementations should detect closed connections even while
the request is idle.
"""
pass
def clear(self):
"""Resets all headers and content for this response."""
self._headers = {
"Server": "TornadoServer/1.0",
"Content-Type": "text/html; charset=UTF-8",
}
if not self.request.supports_http_1_1():
if self.request.headers.get("Connection") == "Keep-Alive":
self.set_header("Connection", "Keep-Alive")
self._write_buffer = []
self._status_code = 200
def set_status(self, status_code):
"""Sets the status code for our response."""
assert status_code in httplib.responses
self._status_code = status_code # 设置响应状态码
def set_header(self, name, value):
"""Sets the given response header name and value.
If a datetime is given, we automatically format it according to the
HTTP specification. If the value is not a string, we convert it to
a string. All header values are then encoded as UTF-8.
"""
if isinstance(value, datetime.datetime):
t = calendar.timegm(value.utctimetuple()) # 转换时间格式
value = email.utils.formatdate(t, localtime=False, usegmt=True)
elif isinstance(value, int) or isinstance(value, long):
value = str(value) # 转换数字类型
else:
value = _utf8(value)
# If \n is allowed into the header, it is possible to inject
# additional headers or split the request. Also cap length to
# prevent obviously erroneous values.
safe_value = re.sub(r"[\x00-\x1f]", " ", value)[:4000] # 确保头部没有空格等影响http协议解析的字符
if safe_value != value:
raise ValueError("Unsafe header value %r", value)
self._headers[name] = value # 存入数据
_ARG_DEFAULT = []
def get_argument(self, name, default=_ARG_DEFAULT, strip=True):
"""Returns the value of the argument with the given name.
If default is not provided, the argument is considered to be
required, and we throw an HTTP 404 exception if it is missing.
If the argument appears in the url more than once, we return the
last value.
The returned value is always unicode.
"""
args = self.get_arguments(name, strip=strip)
if not args:
if default is self._ARG_DEFAULT:
raise HTTPError(404, "Missing argument %s" % name)
return default
return args[-1]
def get_arguments(self, name, strip=True):
"""Returns a list of the arguments with the given name.
If the argument is not present, returns an empty list.
The returned values are always unicode.
"""
values = self.request.arguments.get(name, [])
# Get rid of any weird control chars
values = [re.sub(r"[\x00-\x08\x0e-\x1f]", " ", x) for x in values]
values = [_unicode(x) for x in values]
if strip:
values = [x.strip() for x in values]
return values
@property
def cookies(self):
"""A dictionary of Cookie.Morsel objects."""
if not hasattr(self, "_cookies"):
self._cookies = Cookie.BaseCookie() # 设置存储cookie
if "Cookie" in self.request.headers: # 如果头部文件中有Cookie
try:
self._cookies.load(self.request.headers["Cookie"]) # 将头部信息中的cookie信息保存在请求handler中
except:
self.clear_all_cookies()
return self._cookies
def get_cookie(self, name, default=None):
"""Gets the value of the cookie with the given name, else default."""
if name in self.cookies:
return self.cookies[name].value
return default
def set_cookie(self, name, value, domain=None, expires=None, path="/",
expires_days=None, **kwargs):
"""Sets the given cookie name/value with the given options.
Additional keyword arguments are set on the Cookie.Morsel
directly.
See http://docs.python.org/library/cookie.html#morsel-objects
for available attributes.
"""
name = _utf8(name) # 设置cookie
value = _utf8(value)
if re.search(r"[\x00-\x20]", name + value):
# Don't let us accidentally inject bad stuff
raise ValueError("Invalid cookie %r: %r" % (name, value))
if not hasattr(self, "_new_cookies"): # 如果没有_new_cookies则设置为空列表
self._new_cookies = []
new_cookie = Cookie.BaseCookie()
self._new_cookies.append(new_cookie) # 添加到_new_cookies列表中
new_cookie[name] = value
if domain:
new_cookie[name]["domain"] = domain # 设置域名
if expires_days is not None and not expires: # 过期时间
expires = datetime.datetime.utcnow() + datetime.timedelta(
days=expires_days)
if expires:
timestamp = calendar.timegm(expires.utctimetuple())
new_cookie[name]["expires"] = email.utils.formatdate(
timestamp, localtime=False, usegmt=True)
if path: # 路径
new_cookie[name]["path"] = path
for k, v in kwargs.iteritems():
new_cookie[name][k] = v # 如果cookie中有多个值存入
def clear_cookie(self, name, path="/", domain=None):
"""Deletes the cookie with the given name."""
expires = datetime.datetime.utcnow() - datetime.timedelta(days=365)
self.set_cookie(name, value="", path=path, expires=expires,
domain=domain) # 将cookie的时间设置成负数则该cookie过期
def clear_all_cookies(self):
"""Deletes all the cookies the user sent with this request."""
for name in self.cookies.iterkeys():
self.clear_cookie(name) # 清除所有的cookie
def set_secure_cookie(self, name, value, expires_days=30, **kwargs):
"""Signs and timestamps a cookie so it cannot be forged.
You must specify the 'cookie_secret' setting in your Application
to use this method. It should be a long, random sequence of bytes
to be used as the HMAC secret for the signature.
To read a cookie set with this method, use get_secure_cookie().
"""
timestamp = str(int(time.time()))
value = base64.b64encode(value) # 设置安全的cookie,base64转码内容
signature = self._cookie_signature(name, value, timestamp) # cookie签名
value = "|".join([value, timestamp, signature]) # 将值进行拼接,设置到cookie中
self.set_cookie(name, value, expires_days=expires_days, **kwargs)
def get_secure_cookie(self, name, include_name=True, value=None):
"""Returns the given signed cookie if it validates, or None.
In older versions of Tornado (0.1 and 0.2), we did not include the
name of the cookie in the cookie signature. To read these old-style
cookies, pass include_name=False to this method. Otherwise, all
attempts to read old-style cookies will fail (and you may log all
your users out whose cookies were written with a previous Tornado
version).
"""
if value is None: value = self.get_cookie(name) # 解析加密的cookie
if not value: return None
parts = value.split("|")
if len(parts) != 3: return None
if include_name:
signature = self._cookie_signature(name, parts[0], parts[1])
else:
signature = self._cookie_signature(parts[0], parts[1])
if not _time_independent_equals(parts[2], signature):
logging.warning("Invalid cookie signature %r", value)
return None
timestamp = int(parts[1])
if timestamp < time.time() - 31 * 86400:
logging.warning("Expired cookie %r", value)
return None
try:
return base64.b64decode(parts[0]) # 返回解密后的数据
except:
return None
def _cookie_signature(self, *parts):
self.require_setting("cookie_secret", "secure cookies")
hash = hmac.new(self.application.settings["cookie_secret"],
digestmod=hashlib.sha1) # 加密cookie
for part in parts: hash.update(part)
return hash.hexdigest()
def redirect(self, url, permanent=False):
"""Sends a redirect to the given (optionally relative) URL."""
if self._headers_written:
raise Exception("Cannot redirect after headers have been written") # 如果没有头部信息则报错
self.set_status(301 if permanent else 302) # 设置响应头的状态值
# Remove whitespace
url = re.sub(r"[\x00-\x20]+", "", _utf8(url)) #去除多余空格信息
self.set_header("Location", urlparse.urljoin(self.request.uri, url)) # 将重定向设置到头部信息中
self.finish() # 将数据发送出去
def write(self, chunk):
"""Writes the given chunk to the output buffer.
To write the output to the network, use the flush() method below.
If the given chunk is a dictionary, we write it as JSON and set
the Content-Type of the response to be text/javascript.
"""
assert not self._finished
if isinstance(chunk, dict):
chunk = escape.json_encode(chunk)
self.set_header("Content-Type", "text/javascript; charset=UTF-8")
chunk = _utf8(chunk) # 转换内容格式
self._write_buffer.append(chunk) # 添加到写缓冲区中
def render(self, template_name, **kwargs):
"""Renders the template with the given arguments as the response."""
html = self.render_string(template_name, **kwargs) # 模板渲染
# Insert the additional JS and CSS added by the modules on the page
js_embed = []
js_files = []
css_embed = []
css_files = []
html_heads = []
html_bodies = []
for module in getattr(self, "_active_modules", {}).itervalues():
embed_part = module.embedded_javascript()
if embed_part: js_embed.append(_utf8(embed_part))
file_part = module.javascript_files()
if file_part:
if isinstance(file_part, basestring):
js_files.append(file_part)
else:
js_files.extend(file_part)
embed_part = module.embedded_css()
if embed_part: css_embed.append(_utf8(embed_part))
file_part = module.css_files()
if file_part:
if isinstance(file_part, basestring):
css_files.append(file_part)
else:
css_files.extend(file_part)
head_part = module.html_head()
if head_part: html_heads.append(_utf8(head_part))
body_part = module.html_body()
if body_part: html_bodies.append(_utf8(body_part))
if js_files:
# Maintain order of JavaScript files given by modules
paths = []
unique_paths = set()
for path in js_files:
if not path.startswith("/") and not path.startswith("http:"):
path = self.static_url(path)
if path not in unique_paths:
paths.append(path)
unique_paths.add(path)
js = ''.join('<script src="' + escape.xhtml_escape(p) +
'" type="text/javascript"></script>'
for p in paths)
sloc = html.rindex('</body>')
html = html[:sloc] + js + '\n' + html[sloc:]
if js_embed:
js = '<script type="text/javascript">\n//<![CDATA[\n' + \
'\n'.join(js_embed) + '\n//]]>\n</script>'
sloc = html.rindex('</body>')
html = html[:sloc] + js + '\n' + html[sloc:]
if css_files:
paths = set()
for path in css_files:
if not path.startswith("/") and not path.startswith("http:"):
paths.add(self.static_url(path))
else:
paths.add(path)
css = ''.join('<link href="' + escape.xhtml_escape(p) + '" '
'type="text/css" rel="stylesheet"/>'
for p in paths)
hloc = html.index('</head>')
html = html[:hloc] + css + '\n' + html[hloc:]
if css_embed:
css = '<style type="text/css">\n' + '\n'.join(css_embed) + \
'\n</style>'
hloc = html.index('</head>')
html = html[:hloc] + css + '\n' + html[hloc:]
if html_heads:
hloc = html.index('</head>')
html = html[:hloc] + ''.join(html_heads) + '\n' + html[hloc:]
if html_bodies:
hloc = html.index('</body>')
html = html[:hloc] + ''.join(html_bodies) + '\n' + html[hloc:]
self.finish(html)
def render_string(self, template_name, **kwargs):
"""Generate the given template with the given arguments.
We return the generated string. To generate and write a template
as a response, use render() above.
"""
# If no template_path is specified, use the path of the calling file
template_path = self.get_template_path() # 获取配置的模板文件路径
if not template_path:
frame = sys._getframe(0)
web_file = frame.f_code.co_filename
while frame.f_code.co_filename == web_file:
frame = frame.f_back
template_path = os.path.dirname(frame.f_code.co_filename)
if not getattr(RequestHandler, "_templates", None): # 如果获取为空,则创建一个字典
RequestHandler._templates = {}
if template_path not in RequestHandler._templates: # 如果模板文件不再字典中则添加对应的名称和loader进该字典
loader = self.application.settings.get("template_loader") or\
template.Loader(template_path)
RequestHandler._templates[template_path] = loader # 要么使用配置的Loader要么使用默认的load
t = RequestHandler._templates[template_path].load(template_name)
args = dict(
handler=self,
request=self.request,
current_user=self.current_user,
locale=self.locale,
_=self.locale.translate,
static_url=self.static_url,
xsrf_form_html=self.xsrf_form_html,
reverse_url=self.application.reverse_url
)
args.update(self.ui)
args.update(kwargs)
return t.generate(**args)
def flush(self, include_footers=False):
"""Flushes the current output buffer to the nextwork."""
if self.application._wsgi:
raise Exception("WSGI applications do not support flush()")
chunk = "".join(self._write_buffer) # 拼接处理完成的数据
self._write_buffer = [] # 将写缓存清空
if not self._headers_written: # 如果头部为空
self._headers_written = True
for transform in self._transforms:
self._headers, chunk = transform.transform_first_chunk(
self._headers, chunk, include_footers) # 处理压缩转换的数据
headers = self._generate_headers() # 获取拼接的头部文件字符串
else:
for transform in self._transforms:
chunk = transform.transform_chunk(chunk, include_footers)
headers = ""
# Ignore the chunk and only write the headers for HEAD requests
if self.request.method == "HEAD":
if headers: self.request.write(headers)
return
if headers or chunk:
self.request.write(headers + chunk)
def finish(self, chunk=None):
"""Finishes this response, ending the HTTP request."""
assert not self._finished
if chunk is not None: self.write(chunk) # 调用完成后调用,此时写入传入值
# Automatically support ETags and add the Content-Length header if
# we have not flushed any content yet.
if not self._headers_written: # 如果头部长度为空,自动添加长度等返回信息
if (self._status_code == 200 and self.request.method == "GET" and # 第一次请求数据的时候,
"Etag" not in self._headers): # 详情可参考:https://www.cnblogs.com/softidea/p/5986339.html
hasher = hashlib.sha1()
for part in self._write_buffer:
hasher.update(part)
etag = '"%s"' % hasher.hexdigest() # 对将要发送的数据进行sha1计算
inm = self.request.headers.get("If-None-Match")
if inm and inm.find(etag) != -1:
self._write_buffer = []
self.set_status(304) # 如果该数据已经发送,则不发送该数据
else:
self.set_header("Etag", etag) # 如果首次就设置etag
if "Content-Length" not in self._headers:
content_length = sum(len(part) for part in self._write_buffer)
self.set_header("Content-Length", content_length) # 设置返回长度信息
if hasattr(self.request, "connection"):
# Now that the request is finished, clear the callback we
# set on the IOStream (which would otherwise prevent the
# garbage collection of the RequestHandler when there
# are keepalive connections)
self.request.connection.stream.set_close_callback(None)
if not self.application._wsgi:
self.flush(include_footers=True) # 将处理的数据写出
self.request.finish() # 调用request.finish()
self._log()
self._finished = True
def send_error(self, status_code=500, **kwargs):
"""Sends the given HTTP error code to the browser.
We also send the error HTML for the given error code as returned by
get_error_html. Override that method if you want custom error pages
for your application.
"""
if self._headers_written:
logging.error("Cannot send error response after headers written")
if not self._finished:
self.finish()
return
self.clear()
self.set_status(status_code)
message = self.get_error_html(status_code, **kwargs)
self.finish(message)
def get_error_html(self, status_code, **kwargs):
"""Override to implement custom error pages.
If this error was caused by an uncaught exception, the
exception object can be found in kwargs e.g. kwargs['exception']
"""
return "<html><title>%(code)d: %(message)s</title>" \
"<body>%(code)d: %(message)s</body></html>" % {
"code": status_code,
"message": httplib.responses[status_code],
}
@property
def locale(self):
"""The local for the current session.
Determined by either get_user_locale, which you can override to
set the locale based on, e.g., a user preference stored in a
database, or get_browser_locale, which uses the Accept-Language
header.
"""
if not hasattr(self, "_locale"):
self._locale = self.get_user_locale()
if not self._locale:
self._locale = self.get_browser_locale()
assert self._locale
return self._locale
def get_user_locale(self):
"""Override to determine the locale from the authenticated user.
If None is returned, we use the Accept-Language header.
"""
return None
def get_browser_locale(self, default="en_US"):
"""Determines the user's locale from Accept-Language header.
See http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.4
"""
if "Accept-Language" in self.request.headers: # 获取语言字段
languages = self.request.headers["Accept-Language"].split(",")
locales = []
for language in languages:
parts = language.strip().split(";")
if len(parts) > 1 and parts[1].startswith("q="):
try:
score = float(parts[1][2:])
except (ValueError, TypeError):
score = 0.0
else:
score = 1.0
locales.append((parts[0], score))
if locales:
locales.sort(key=lambda (l, s): s, reverse=True)
codes = [l[0] for l in locales]
return locale.get(*codes)
return locale.get(default)
@property
def current_user(self):
"""The authenticated user for this request.
Determined by either get_current_user, which you can override to
set the user based on, e.g., a cookie. If that method is not
overridden, this method always returns None.
We lazy-load the current user the first time this method is called
and cache the result after that.
"""
if not hasattr(self, "_current_user"):
self._current_user = self.get_current_user()
return self._current_user
def get_current_user(self):
"""Override to determine the current user from, e.g., a cookie."""
return None
def get_login_url(self):
"""Override to customize the login URL based on the request.
By default, we use the 'login_url' application setting.
"""
self.require_setting("login_url", "@tornado.web.authenticated")
return self.application.settings["login_url"]
def get_template_path(self):
"""Override to customize template path for each handler.
By default, we use the 'template_path' application setting.
Return None to load templates relative to the calling file.
"""
return self.application.settings.get("template_path")
@property
def xsrf_token(self):
"""The XSRF-prevention token for the current user/session.
To prevent cross-site request forgery, we set an '_xsrf' cookie
and include the same '_xsrf' value as an argument with all POST
requests. If the two do not match, we reject the form submission
as a potential forgery.
See http://en.wikipedia.org/wiki/Cross-site_request_forgery
"""
if not hasattr(self, "_xsrf_token"): # 跨站请求token
token = self.get_cookie("_xsrf")
if not token:
token = binascii.b2a_hex(uuid.uuid4().bytes)
expires_days = 30 if self.current_user else None
self.set_cookie("_xsrf", token, expires_days=expires_days)
self._xsrf_token = token
return self._xsrf_token
def check_xsrf_cookie(self):
"""Verifies that the '_xsrf' cookie matches the '_xsrf' argument.
To prevent cross-site request forgery, we set an '_xsrf' cookie
and include the same '_xsrf' value as an argument with all POST
requests. If the two do not match, we reject the form submission
as a potential forgery.
See http://en.wikipedia.org/wiki/Cross-site_request_forgery
"""
if self.request.headers.get("X-Requested-With") == "XMLHttpRequest": # 检查跨站请求token
return
token = self.get_argument("_xsrf", None)
if not token:
raise HTTPError(403, "'_xsrf' argument missing from POST")
if self.xsrf_token != token:
raise HTTPError(403, "XSRF cookie does not match POST argument")
def xsrf_form_html(self):
"""An HTML <input/> element to be included with all POST forms.
It defines the _xsrf input value, which we check on all POST
requests to prevent cross-site request forgery. If you have set
the 'xsrf_cookies' application setting, you must include this
HTML within all of your HTML forms.
See check_xsrf_cookie() above for more information.
"""
return '<input type="hidden" name="_xsrf" value="' + \
escape.xhtml_escape(self.xsrf_token) + '"/>' # 从html中获取跨站请求信息标签
def static_url(self, path):
"""Returns a static URL for the given relative static file path.
This method requires you set the 'static_path' setting in your
application (which specifies the root directory of your static
files).
We append ?v=<signature> to the returned URL, which makes our
static file handler set an infinite expiration header on the
returned content. The signature is based on the content of the
file.
If this handler has a "include_host" attribute, we include the
full host for every static URL, including the "http://". Set
this attribute for handlers whose output needs non-relative static
path names.
"""
self.require_setting("static_path", "static_url") # 获取静态文件路径
if not hasattr(RequestHandler, "_static_hashes"):
RequestHandler._static_hashes = {}
hashes = RequestHandler._static_hashes
if path not in hashes:
try:
f = open(os.path.join(
self.application.settings["static_path"], path))
hashes[path] = hashlib.md5(f.read()).hexdigest()
f.close()
except:
logging.error("Could not open static file %r", path)
hashes[path] = None
base = self.request.protocol + "://" + self.request.host \
if getattr(self, "include_host", False) else ""
static_url_prefix = self.settings.get('static_url_prefix', '/static/')
if hashes.get(path):
return base + static_url_prefix + path + "?v=" + hashes[path][:5]
else:
return base + static_url_prefix + path
def async_callback(self, callback, *args, **kwargs):
"""Wrap callbacks with this if they are used on asynchronous requests.
Catches exceptions and properly finishes the request.
"""
if callback is None:
return None
if args or kwargs:
callback = functools.partial(callback, *args, **kwargs)
def wrapper(*args, **kwargs):
try:
return callback(*args, **kwargs)
except Exception, e:
if self._headers_written:
logging.error("Exception after headers written",
exc_info=True)
else:
self._handle_request_exception(e)
return wrapper
def require_setting(self, name, feature="this feature"):
"""Raises an exception if the given app setting is not defined."""
if not self.application.settings.get(name):
raise Exception("You must define the '%s' setting in your "
"application to use %s" % (name, feature))
def reverse_url(self, name, *args):
return self.application.reverse_url(name, *args)
def _execute(self, transforms, *args, **kwargs):
"""Executes this request with the given output transforms."""
self._transforms = transforms
try:
if self.request.method not in self.SUPPORTED_METHODS: # 判断该请求的方式是否是支持的方式
raise HTTPError(405)
# If XSRF cookies are turned on, reject form submissions without
# the proper cookie
if self.request.method == "POST" and \
self.application.settings.get("xsrf_cookies"): # 如果是post请求还需要检查xsrf
self.check_xsrf_cookie()
self.prepare() # 在处理请求之前调用该函数,
if not self._finished:
getattr(self, self.request.method.lower())(*args, **kwargs) # 获取method方法对应的处理方法处理
if self._auto_finish and not self._finished:
self.finish() # 结束该次请求
except Exception, e:
self._handle_request_exception(e)
def _generate_headers(self):
lines = [self.request.version + " " + str(self._status_code) + " " +
httplib.responses[self._status_code]] # 返回头第一行
lines.extend(["%s: %s" % (n, v) for n, v in self._headers.iteritems()]) # 将头部序列化进lines
for cookie_dict in getattr(self, "_new_cookies", []): # 如果_new_cookies中有数据则写入
for cookie in cookie_dict.values():
lines.append("Set-Cookie: " + cookie.OutputString(None))
return "\r\n".join(lines) + "\r\n\r\n" # 拼成头部字符串
def _log(self):
if self._status_code < 400:
log_method = logging.info
elif self._status_code < 500:
log_method = logging.warning
else:
log_method = logging.error
request_time = 1000.0 * self.request.request_time()
log_method("%d %s %.2fms", self._status_code,
self._request_summary(), request_time)
def _request_summary(self):
return self.request.method + " " + self.request.uri + " (" + \
self.request.remote_ip + ")"
def _handle_request_exception(self, e): # 处理出错信息的处理
if isinstance(e, HTTPError):
if e.log_message:
format = "%d %s: " + e.log_message
args = [e.status_code, self._request_summary()] + list(e.args)
logging.warning(format, *args)
if e.status_code not in httplib.responses:
logging.error("Bad HTTP status code: %d", e.status_code)
self.send_error(500, exception=e)
else:
self.send_error(e.status_code, exception=e)
else:
logging.error("Uncaught exception %s\n%r", self._request_summary(),
self.request, exc_info=e)
self.send_error(500, exception=e)
def _ui_module(self, name, module): # 获取ui渲染模板
def render(*args, **kwargs):
if not hasattr(self, "_active_modules"):
self._active_modules = {}
if name not in self._active_modules:
self._active_modules[name] = module(self)
rendered = self._active_modules[name].render(*args, **kwargs)
return rendered
return render
def _ui_method(self, method):
return lambda *args, **kwargs: method(self, *args, **kwargs)每个处理handler需要继承RequestHandler,需要该handler就重写相应的get,post等方法,
def _execute(self, transforms, *args, **kwargs):
"""Executes this request with the given output transforms."""
self._transforms = transforms
try:
if self.request.method not in self.SUPPORTED_METHODS: # 判断该请求的方式是否是支持的方式
raise HTTPError(405)
# If XSRF cookies are turned on, reject form submissions without
# the proper cookie
if self.request.method == "POST" and \
self.application.settings.get("xsrf_cookies"): # 如果是post请求还需要检查xsrf
self.check_xsrf_cookie()
self.prepare() # 在处理请求之前调用该函数,
if not self._finished:
getattr(self, self.request.method.lower())(*args, **kwargs) # 获取method方法对应的处理方法处理
if self._auto_finish and not self._finished:
self.finish() # 结束该次请求
except Exception, e:
self._handle_request_exception(e)执行完成后就完成了请求的处理。
至此,基本框架分析完成。
框架的大致运行流程:
server的运行流程(侵权删)
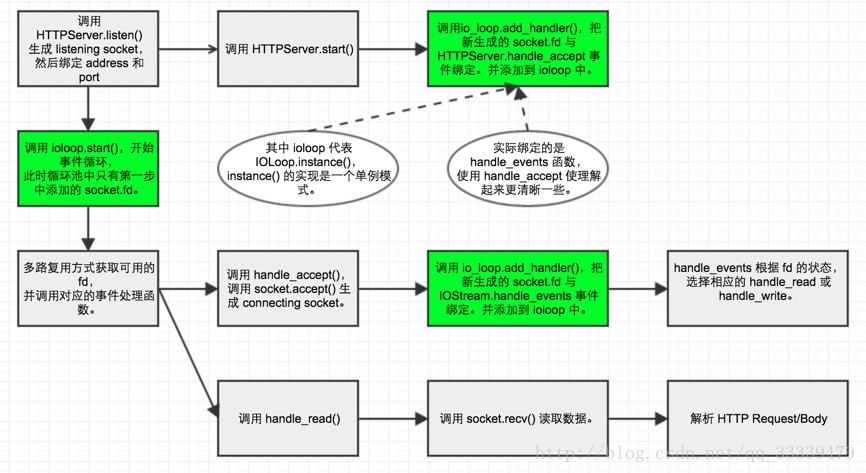
requesthandler处理流程(侵权删)
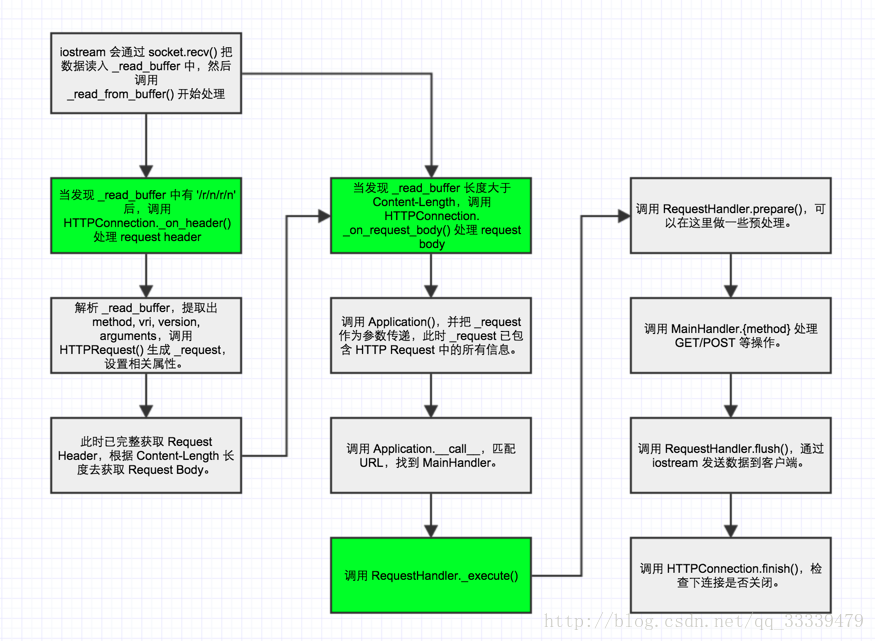
至此框架的运行原理的大概流程图如下作为补充:
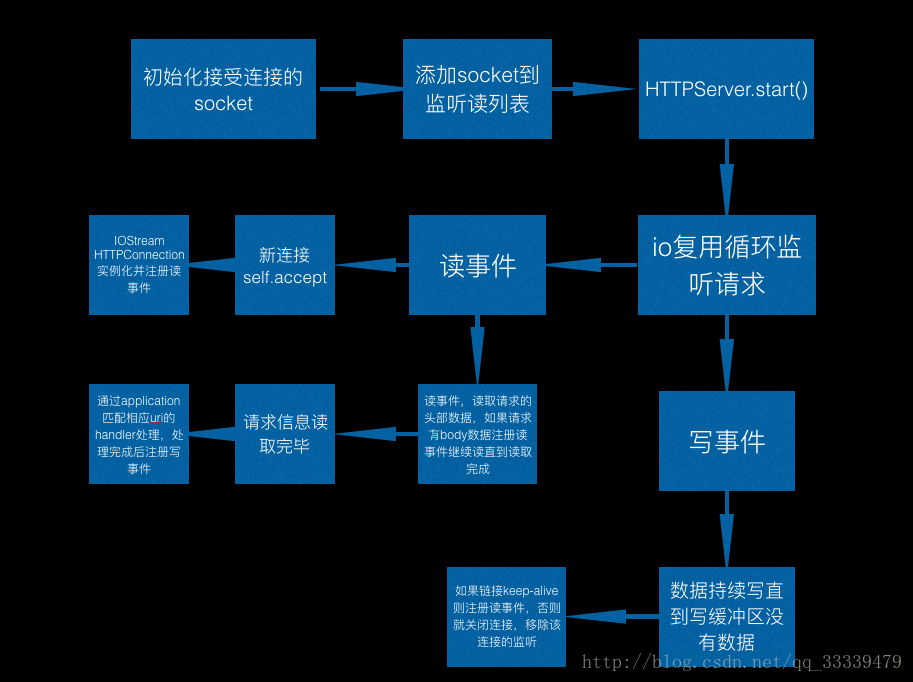















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









