







一、JDK / JRE / JVM
作为一个 Java 开发人员,你肯定听说过JDK、JRE、JVM,那么这三者是否存在什么关系与区别呢?
JDK 是整改 JAVA SE 的核心,其中包括了 Java 运行环境、Java 编译工具(javac)、Java 打包工具(jar.exe) 和 Java 基础类库,还包括了 JRE。JDK 安装目录如下:
其中真正在 Java 运行时发挥作用的是 bin、include、lib、 jre这四个目录。
bin:存放了 JDK 的各种工具命令,如 javac、javainclude:存放了一些平台特定的头文件lib:类库jre:java运行时环境
JRE,Java 运行环境,包含 JVM 标准实现(JVM虚拟机)与 Java 核心类库。
JVM,Java 虚拟机,是 Java 运行时的环境。
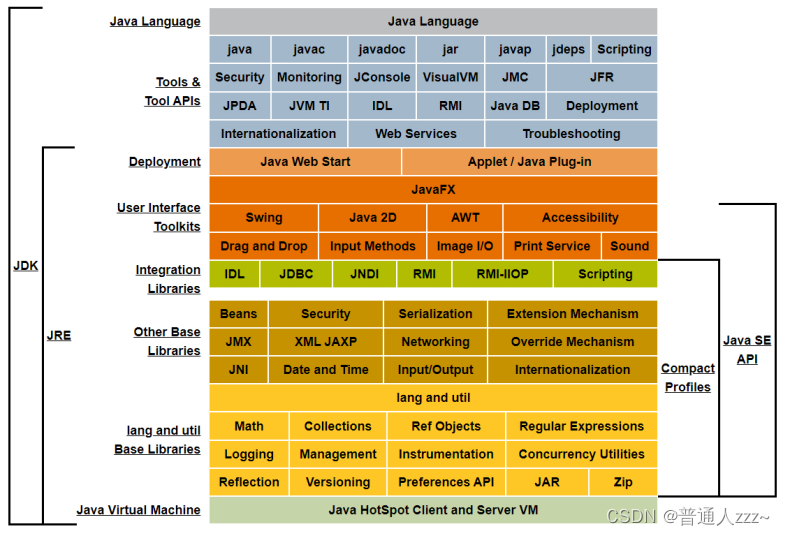
三者关系如下:
二、.Java 文件运行过程
在日常 Java 开发过程中,从代码编写到运行,步骤如下:
- 第一步我们会创建一个
.java后缀的文件,在其编写对应的逻辑代码。
// HelloWorld.java 代码
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello world!!!!!");
}
}
- 第二步如果不使用开发工具,我们需通过
javac对其编译,生成一个.class文件。
javac HelloWorld.java
- 最后,通过
java命令将.class文件交由 JVM 运行。
java HelloWorld
整体过程如下:
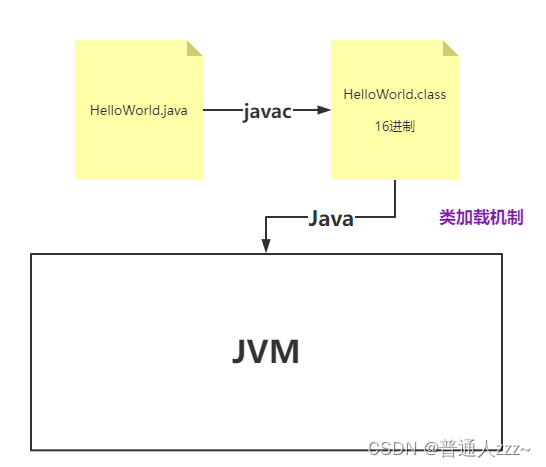
javac 命令会将其 .java 文件编译成 .class 文件,那么 java HelloWorld 命令将其 .class 交由 JVM 运行,期间做了哪些动作呢?如下:
- 装载:通过类加载器(ClassLoader)扫描所有需要运行的 .class 文件,将其 .class 文件转换为字节码交由 JVM 存储。
- 链接
2.1 校验:校验 .class 类信息是否符合 JVM 规范,如是否以CA FE BA BE开头等
2.2 准备:为类中的静态变量分配内存空间,并将其初始化为默认值,如:类中存在static int i = 10类的成员属性,经过该步骤后,会变为static init i = 0。
2.3 解析:将类的符号引用转变为直接引用。这句话非常抽象,辣么什么是符号引用、直接引用? 符号引用:是一组用来描述所引用的目标的符号,符号可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可,简单来说就是一组描述目标的符号。 直接引用:指向目标的指针,通过直接引用,JVM 可以知道引用类的实际内存地址。 - 初始化:对类的静态变量、静态代码块执行初始化操作
三、JVM运行时数据区

用一句话来总结这五个区的作用及关系:JAVA 通过类加载机制,将 .class 文件信息、常量等存放在 Method Area(方法区),程序在运行时,创建 Bean 对象,存放在 Heap(堆)中,线程在运行时,通过Java虚拟机栈记录方法的调用关系,在线程运行时,通过 Native Method Stacks(本地方法栈)记录 Native 方法调用状态,当CPU进行时间片切换调度时,通过 The PC Register(程序计数器) 记录正在执行的Java虚拟机字节码指令地址。
下面详细说明一下这五个区的作用。
3.1 Method Area
方法区是各个线程共享的内存区域,在虚拟机启动时创建,用于存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,一般我们也将方法区叫做非堆。
注意:当方法区无法满足内存分配需求时,将抛出 OOM(OutOfMemoryError) 异常。
3.2 Heap
Java 堆是 Java 虚拟机所管理内存中最大的一块,在虚拟机启动时创建,被所有线程共享,用于存储程序运行时实例对象。
注意:当堆内存空间不足时,也会抛出 OOM(OutOfMemoryError) 异常。
3.3 Java Virtual Machine Stacks
Java 虚拟机栈是一个用于保存线程运行状态的区域,所以 Java 虚拟机栈是线程私有的,随着线程的创建而创建。
每一个被线程执行的方法,为该栈中的栈帧,即每个方法对应一个栈帧。调用一个方法,就会向栈中压入一个 栈帧;一个方法调用完成,就会把该栈帧从栈中弹出。如下:
- 代码
public class Test {
public static void main(String[] args) {
aMethod();
}
private static void aMethod() {
bMethod();
cMethod();
}
private static void bMethod() {}
private static void cMethod() {}
}
- Java虚拟机栈

3.4 Native Method Stacks
本地方法栈是用于记录线程中调用 Native 方法运行状态的区域,结构同 Java Virtual Machine Stacks 类似。
3.5 The PC Register
程序计数器用于记录正在执行的 Java 虚拟机字节码指令地址,是线程私有的,随着线程的创建而创建,是当 CPU 进行线程上下文切换时,会通过程序计数器记录当前线程执行指令地址。
注意:如果线程正在执行Java方法,则计数器记录的是正在执行的虚拟机字节码指令的地址。如果正在执行的是Native方法,则这个计数器为空。
四、JVM内存模型
上面对 JVM 运行时数据区做了详细描述,其中 Java虚拟机栈、本地方法栈、程序计数器都是线程私有的,而用于存储数据的方法区(也叫非堆)和堆是线程共享的。所以 JVM内存主要涉及 方法区 和 堆,下面对这两大块进行详细描述。
JVM将其内存分为两大块,一块是方法区(Method Areas,也叫非堆),另外一快是堆(Heap)。整体模型如下:
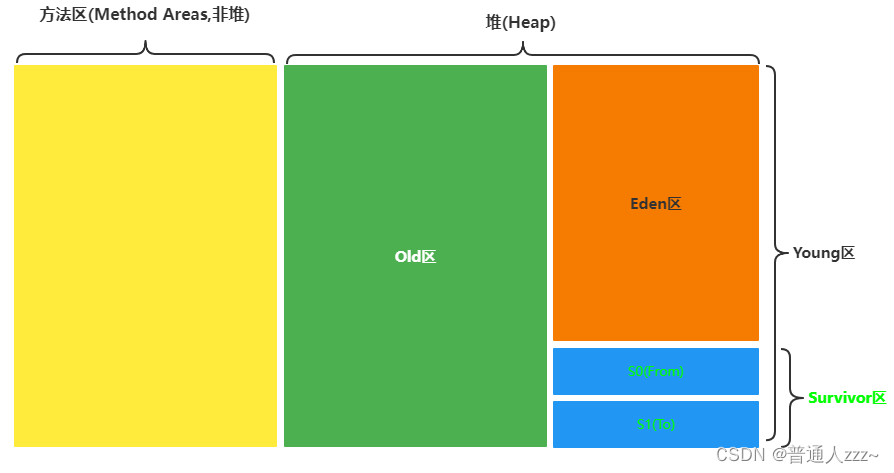
方法区(Method Areas):用于存储类对象(.class)、常量、静态变量、即时编译器编译后的代码信息等。
堆(Heap):用于存储运行时实例对象。其中 堆(Heap) 又分为 Young区(年轻代) 和 Old区(年老代),用于存储不同生命周期的实例对象,其中,Young区 用于存储生命周期较短的瞬时对象,Old区 用于存储生命周期长 和 某些大对象,当 Young区 的对象存活较长后,会放入 Old 区进行存储(默认是15次垃圾回收后,可通过参数 -XX:MaxTenuringThreshold=N 指定最大年龄),其次,当对象超过一定字节大小后,也会直接叫由 Old 区进行存储(可通过参数 --XX:PretenureSizeThreshold=3145728 设置,单位是 byte,此处表示 3MB)。
默认情况下,Young(新生代) 和 Old(老年代) 的比值是 1:2 分配,可以通过参数 -XXNewRatio=2 来指定,如下:
# 新生代:老年代=1:2
-XX:NewRatio=2
# 新生代:老年代=1:4
-XX:NewRatio=4
而在 JVM 中,为了更好的管理 Young区 的内存空间,又将 Young区 分为了 Eden区 和 Survivor区。
Eden区:用于存储线程运行创建的对象,不过大多数对象都是“朝生夕死”,存活时间非常短。
Survivor区:用于存储 Eden区 发生垃圾回收后,存活下来的对象。并且 Survivo区 内部还划分为了 S0 和 S1 区(也称为From、To区),在同一个时间点上,S0 和 S1 只能有一个区有数据,另一个是空的。
Oracle JVM 官网描述 Eden区 和 Survivor区 的S0、S1 空间默认所占的比例是 8:1:1,可以通过 -XX:SurvivorRatio=8 调整这个空间的比例,如下:
# Eden:S0:S1=8:1:1(默认)
-XX:SurvivorRatio=8
# Eden:S0:S1=6:2:2
-XX:SurvivorRatio=6
JVM 将其内存这样分配的主要目的最大的利用内存空间,并且保证其内存空间的连续性。
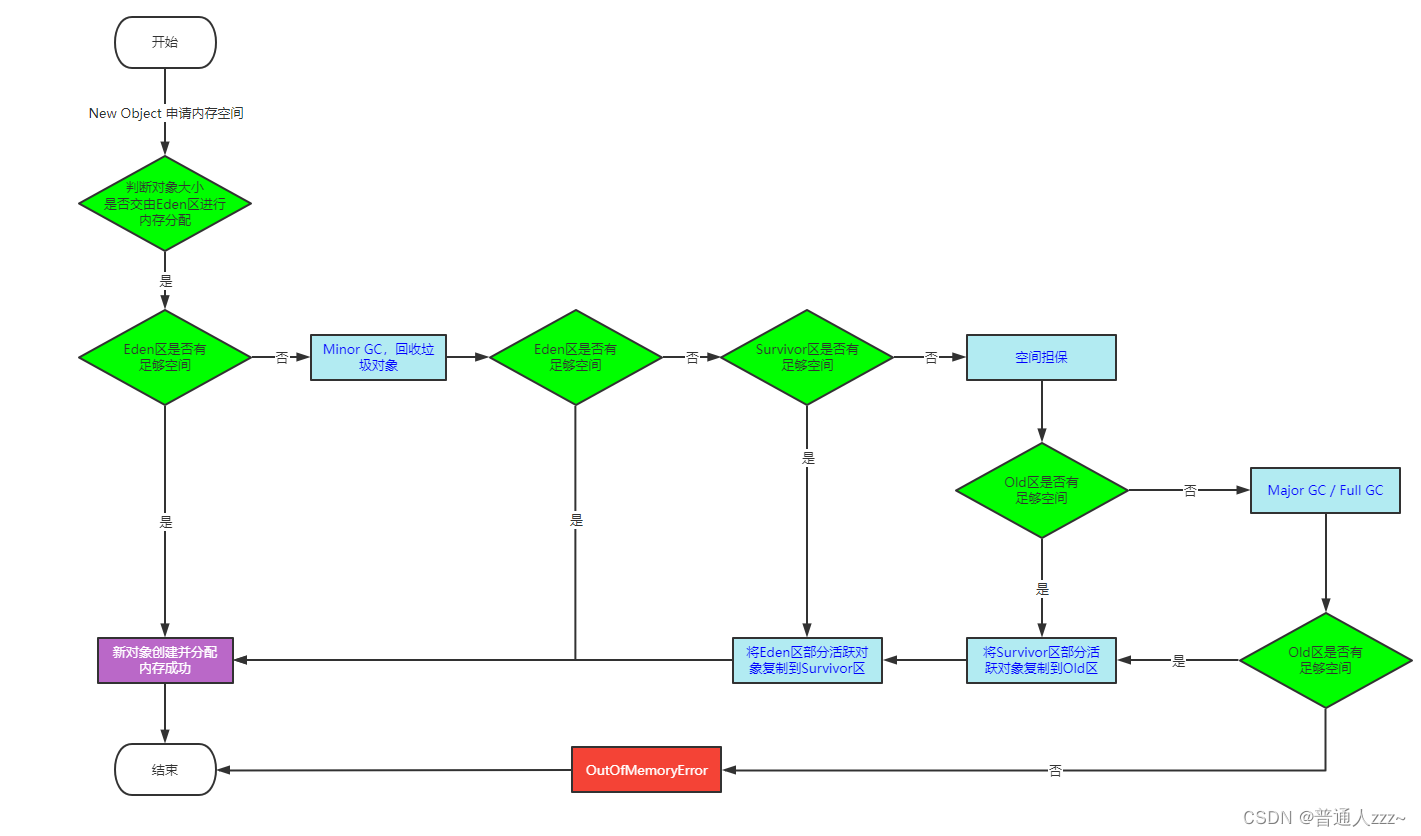
4.1 JVM对象创建和回收过程
JVM 将内存划分为多个可用区域,用于对象创建时内存的分配,主要步骤如下:
- 大多数对象的创建一般会优先在 Eden区 分配内存空间进行存储,当 Eden区 内存不足时,会发生 Minor GC(也叫Young GC)。
- Minor GC 会回收掉 Eden区、Survivor区 中的垃圾对象,并且将 Eden区 以及 Survivor区(假设为S0) 中存活的对复制到 Survivor区 中的 S1 区中,然后清除 Eden区 和 Survivor区 中标记为垃圾的对象,重复此操作。
- 如果 Eden区、Survivor区内存分配不足,会将对象放入 Old区 进行存储。
- 如果 Old区 内存不足,会先进行一次 Major GC 或者 Full GC,然后再次判断 Old区 是否存在可分配内存。
- 当发送 Full GC 后,Old 区还是无可分配内存,JVM就会抛出 OOM(OutOfMemoryError) 异常。
通过以上的内存分配机制,保证了 JVM Young区内存空间的最大利用率以及内存空间的连续性。
注意:因为 Young区 的对象大多数都是"朝生夕死"的,一般来说Eden:S0:S1=8:1:1 是较为合理的,假如是 6:2:2 的话,就会浪费20%的 Young区 内存,并且 Eden区 只有60%,这样会导致较为频繁的 Young GC。
流程图:
五、垃圾收集
Java 程序在运行是会不断创建新的对象,存放在 Young区、Old区,内存的空间是有限的,所以需要一定的算法,来进行内存的回收。在JVM中,那些对象才是需要被回收的呢?
- 首选,需要确定哪些对象需要被回收
- 然后,通过一定算法,进行垃圾回收
5.1 确定垃圾收集对象
5.1.1 引用计数法
对于某个对象而言,只要应用程序中持有该对象的引用,就说明该对象不是垃圾,如果一个对象没有任何指针对其引用,它就是垃圾。
- 判断当前对象引用数量是否为0,如果为0,则可进行垃圾回收
- 每个对象都存在一个引用计算器,被引用则+1,完成引用则-1
优点:执行效率高,程序执行受影响较小
缺点:无法检测出循环引用的情况,会导致 OOM
5.1.2 可达性分析
通过 GC Root 判断对象的引用是否可达来判断对象是否可回收,不可达,则可以尝试进行垃圾回收。
那么, 那些对象能够作为 GC Root 呢?
- JVM虚拟机栈的本地变量表
- static成员变量
- 常量引用
- 活跃线程
- 本地方法栈的变量
- …
如下:
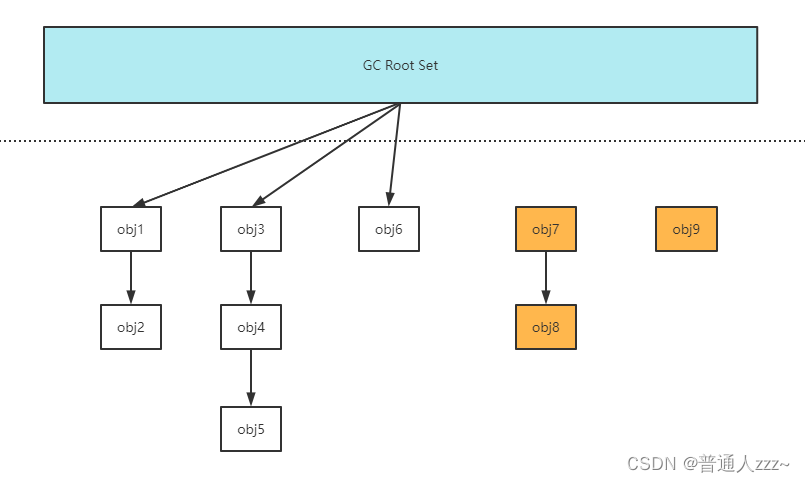
其中,obj7、obj8、obj9 无 GC Root 直接关联,所有判断为垃圾对象。
由于引用计数法存在OOM的缺点,JVM内部采用可达性分析,来判断当前对象是否可进行垃圾回收。
5.2 垃圾收集算法
JVM 通过可达性分析来判断哪些对象需要进行垃圾回收后,则需要根据不同场景选用不同算法进行垃圾回收,常用的垃圾回收算法有:
- 标记-清除
- 标记-整理
- 标记-复制
5.2.1 标记-清除
- 标记:通过可达性分析,找出内存中需要回收的对象,并进行标记。
- 清除:清除被标记的需要回收的对象,释放对应内存空间。
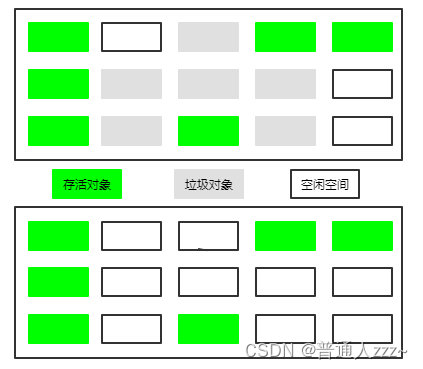
缺点:- 执行效率会随着堆的增加而降低,标记需要遍历整个堆,且如果有大量对象都需要被回收,清除的效率也会很低。
- 产生大量空间碎片。大量的空间碎片会导致在分配大java对象时没有足够的内存空间,进而提前引发一次垃圾回收。
5.2.2 标记-整理
- 标记:通过可达性分析,找出内存中需要回收的对象,并进行标记。
- 整理:让所有存活对象向内存的一端移动,然后直接清除掉边界以外的全部区域。
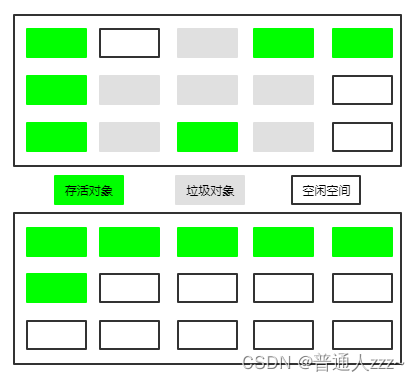
标记-整理 算法解决了 标记-清除 内存碎片问题
5.2.3 标记-复制
- 标记:通过可达性分析,找出内存中需要回收的对象,并进行标记。
- 复制:将一个区域的内存还存活的对象复制到另一个相同大小的内存区域,然后对其内存一次性全部清除
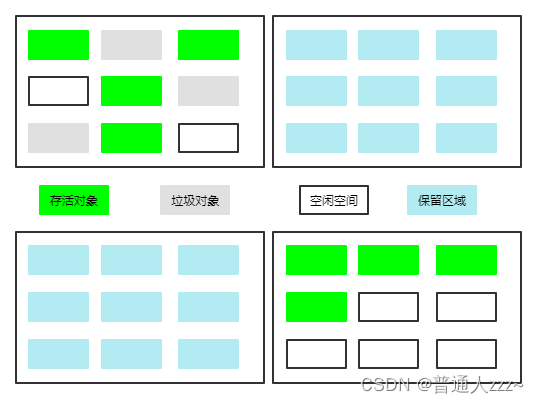
标记-复制 算法是典型的以空间换时间,解决了 标记-清除 内存碎片问题、大量对象可回收清除时的效率问题。
5.3 JVM不同区垃圾回收算法选择
- Young区:标记-清除,标记-复制(通过S0、S1进行复制)
- Old去:标记-清除,标记整理
六、垃圾收集器
什么是垃圾收集器?
垃圾收集器是对不同垃圾回收算法的一种具体实现。
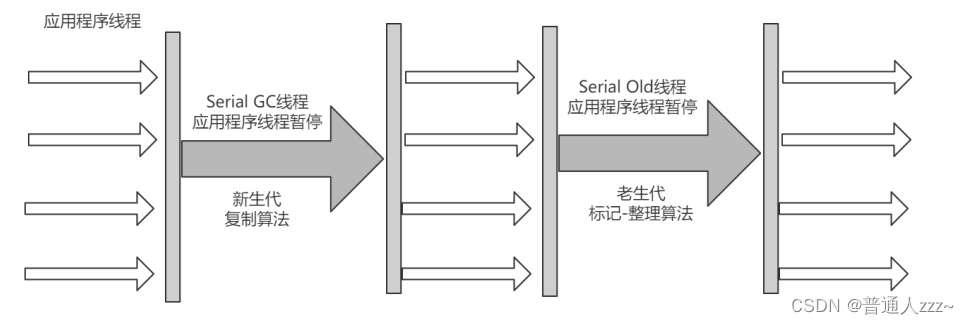
6.1 Serial
串行收集器,通过使用一个线程执行所有垃圾回收工作。
- Serial 收集器可以用于新老年代
- 新生代:采用标记-复制算法
- 老年代:采用标记-整理算法
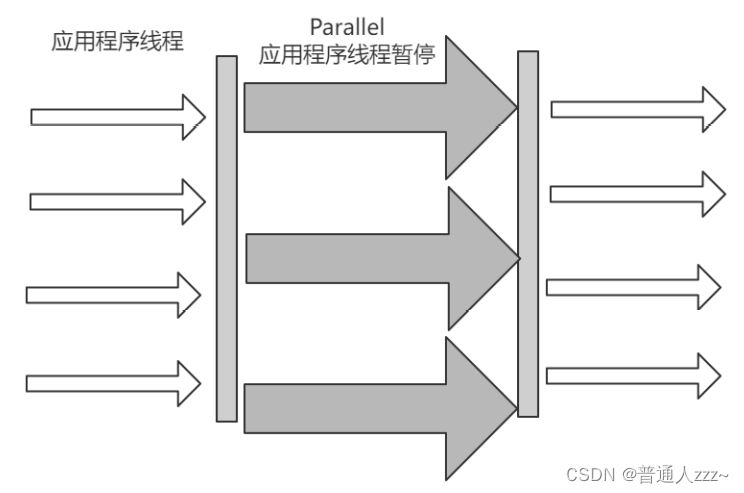
6.2 Parallel
并行收集器,也被称为吞吐量收集器,它是一种类似于串行收集器的分代收集器。
串行和并行收集器之间的主要区别是并行收集器具有多个线程,用于加速垃圾收集。
- Parallel 收集器可以用于新老年代
- 新生代:采用标记-复制算法
- 老年代:采用标记-整理算法
6.3 CMS(ConcMarkSweepGC)
英文全名Concurrent Mark Sweep,并发标记扫描(CMS)收集器,也称为并发低暂停收集器,它试图通过与应用程序线程并发执行大多数垃圾收集工作,以此来最小化由于垃圾收集造成的主线程暂停。
- CMS 只可用于老年代
- 老生代:采用标记-清除算法
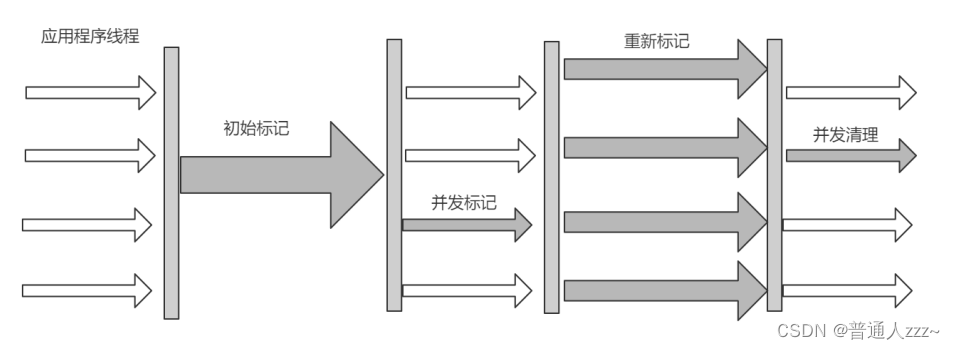
运行步骤如下:
- 初始标记:标记 GC Root 直接关联对象,暂停时间的持续时间通常较短
- 并发标记:在Java应用程序线程执行时,并发的遍历 GC Root 下所有可达对象。
- 重新标记:备注查找由于在Java应用程序线程并发收集器完成跟踪对象后,对对象进行更新而在并发标记阶段遗漏的对象,简单来说,就是并发标记因用户程序变动的内容。
- 并发清理:并发扫描并清除不可达对象,进行内存空间回收。
在并发时产生的新的垃圾,称为浮动垃圾,交由下次清理。
6.4 G1(Garbage-First)
G1是一个并发收集器,其工作原理主要是优先回收垃圾最多的Region区域。通过 G1 可以满足高概率暂停时间目标的能力,同时实现高吞吐量。
什么是 Region区?
使用G1收集器时,Java 堆的内存布局与就与其他收集器有很大差别,它将整个 Java 堆划分为多个大小相等的独立区域(Region),虽然还保留有
新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分 Region(不需要连续)的集合。如下:
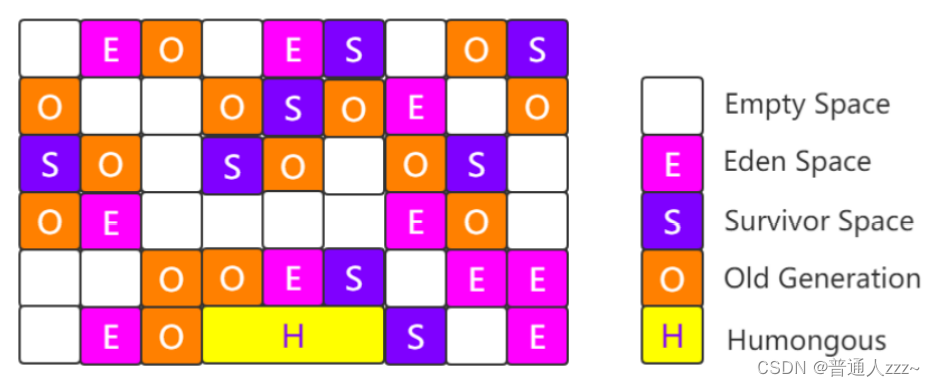
每个 Region 大小都是一样的,可以是 1M~32M 之间的数值,但是必须保证是 2的 n次幂。如果对象太大,一个 Region 放不下[超过Region大小的50%],那么就会直接放到 H(Humongous) 中。可通过参数 ‐XX:G1HeapRegionSize=32M 设置 Region大小。
- G1 可用于新老年代
- 新生代、老年代:标记整理
在 Oracle OpenJDK 官网中,有这样一段描述:G1 作为并发标记-清除收集器(CMS)的长期替代品。将 G1 与 CMS 进行比较,有一些差异使 G1 成为更好的解决方案
- G1是一个压缩收集器。G1 进行了充分的压缩,避免了使用细粒度的自由列表进行分配,而是依赖于区域。这大大简化了收集器的某些部分,并基本上消除了潜在的碎片问题。
- G1 提供了比 CMS 收集器更可预测的垃圾收集暂停,并允许用户指定所需的暂停目标。
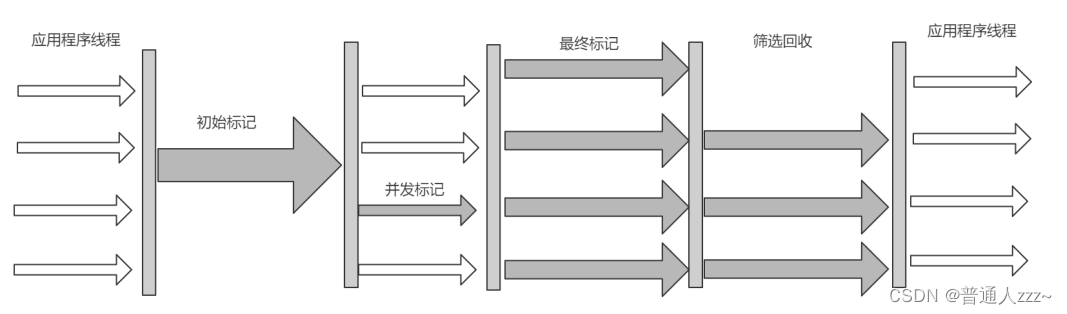
运行步骤如下:
- 初始标记:标记 GC Root 能够关联的对象,并且修改 TAMS 的值,需要暂停用户线程
- 并发标记:从 GC Root 进行可达性分析,找出存活的对象,与用户线程并发执行。
- 最终标记:修正在并发标记阶段因为用户程序的并发执行导致变动的数据,需暂停用户线程
- 筛选回收:对各个 Region 的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间制定回收计划。
6.5 ZGC(The Z Garbage Collector)
ZGC(The Z Garbage Collector)也是一种并发收集器,是 JDK 11 中推出的一款追求极致低延迟的实验性质的垃圾收集器。
在ZGC中,不管是物理上还是逻辑上,ZGC 中已经不存在新老年代的概念了,整体内存上会分为一个个 Page,当进行 GC 操作时会对 Page 进行压缩,因此没有碎片问题。
ZGC只能在64位的 Linux上使用。
ZGC特定:
(1)可以达到 10ms 以内的停顿时间要求。
(2)支持 8MB~4TB 级别的堆内存,并声称未来可以支持 8MB ~ 16TB的堆内存。
(3)堆内存变大后停顿时间还是在10ms以内。
6.6 垃圾收集器分类
- 串行收集器:Serial,特点:适用内存较小的嵌入式设备。
- 并行收集器:Parallel,特点:高吞吐量,适用科学计算、后台处理等。
- 并发收集器:CMS、G1、ZGC,低延迟,适用 Web 交互场景。
6.7 垃圾收集器参数
-XX:+UseSerialGC:表示新生代和老年代都使用串行回收器。-XX:+UseParNewGC:ParNew收集器是 Serial 收集器的多线程版本,表示新生代采用并行回收,老年代仍旧使用串行回收。-XX:+UseParallelGC:表示新生代使用 Parallel 收集器,老年代使用串行收集器。-XX:+UseParallelOldGC:表示新生代和老年代都使用并行收集器。-XX:+UseConcMarkSweepGC:表示老年代采用 CMS 收集器。-XX:+UseG1GC:表示新生代和老年代都采用G1收集器。
6.8 Reponsiveness and throughput
Reponsiveness:响应时间,也叫停顿时间,指垃圾收集器在进行垃圾回收时,终端应用执行响应的时间。
Throughput:吞吐量,指特定定时间内,应用程序执行工作量。
如何测量吞吐量??
- 在给定时间内完成的事务数。
- 批处理程序在一小时内可以完成的作业数。
- 一小时内可以完成的数据库查询数。
6.9 垃圾收集发生时机
GC 是由 JVM 自动完成的,根据 JVM 系统环境而定,所以时机是不确定的。
当然,我们可以手动进行垃圾回收,比如调用 System.gc() 方法通知 JVM 进行一次垃圾回收,但是具体什么时刻运行也无法控制。 也就是说 System.gc() 只是通知要回收,什么时候回收由 JVM 决定。但是不建议手动调用该方法,因为 GC 消耗的资源比较大。
JVM在如下场景,会进行垃圾回收:
(1)当Eden区或者S区不够用了: Young GC 或 Minor GC
(2)老年代空间不够用了: Old GC 或 Major GC
(3)方法区空间不够用了: Metaspace GC
Full GC=Young GC+Old GC+Metaspace GC
七、JVM调优
7.1 参数调优
JVM常用参数列表:
设置JVM垃圾收集器
| 参数 | 说明 |
|---|---|
-XX:+UseSerialGC | 表示新生代和老年代都使用串行回收器 |
-XX:+UseParNewGC | ParNew收集器是 Serial 收集器的多线程版本,表示新生代采用并行回收,老年代仍旧使用串行回收。 |
-XX:+UseParallelGC | 表示新生代使用 Parallel 收集器,老年代使用串行收集器。 |
-XX:+UseParallelOldGC | 表示新生代和老年代都使用并行收集器。 |
-XX:+UseConcMarkSweepGC | 表示老年代采用 CMS 收集器。 |
-XX:+UseG1GC | 表示新生代和老年代都采用G1收集器。 |
内存分配
| 参数 | 含义 | 说明 |
|---|---|---|
-XX:+InitialHeapSize=1024M | 初始化堆大小 | 简写为-Xms100M |
-XX:+MaxHeapSize=1024M | 最大堆大小 | 简写为-Xmx100M |
-XX:+NewSize=1024M | 设置年轻代大小 | |
-XX:+MaxNewSize=1024M | 年轻代最大大小 | |
-XX:+OldSize=1024M | 设置老年代大小 | |
-XX:+MaxOldSize=1024M | 老年代最大大小 | |
-XX:+MetaspaceSize=1024M | 设置方法区大小 | |
-XX:+MaxMetaspaceSize=1024M | 方法区最大大小 | xxxx |
-XX:+NewRatio=4 | 新老年代所占堆空间比值 | 比如 -XX:+NewRatio=4 ,表示新生代 : 老年代 = 1:4 |
-XX:+SurvivorRatio=8 | S0、S1和Eden区的比值 | 比如 -XX:+SurvivorRatio=8,表示 Eden:S0:S1=8:1:1 |
其他参数
| 参数 | 含义 | 说明 |
|---|---|---|
-XX:+HeapDumpOnOutOfMemoryError | 启动堆内存溢出日志打印 | 发生OOM,分析dump日志 |
-XX:+HeapDumpPath=heap.hprof | 指定堆内存溢出日志打印目录 | 表示当前目录下生产一个 heap.hprof 日志文件 |
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:g1-gc.log | 打印G1日志文件 | |
-XX:+Xss128k | 设置每个线程的堆栈大小 | 经验值是3000-5000最佳 |
-XX:+MaxTenuringThreshold=15 | Young区对象提升到Old区的最大临界值 | 默认15 |
-XX:+InitiatingHeapOccupancyPercent=45 | 触发并发GC周期,堆内存使用占比 | G1类的并发垃圾收集器,通过该参数触发GC,为0表示一直执行GC循环,默认45 |
-XX:+G1HeapWastePercent | G1收集器允许浪费堆空间占比 | 默认是10%,如果并发标记可回收的空间小于10%,则不会触发Mixed GC |
-XX:+MaxGCPauseMillis=200ms | G1最大停顿时间 | 停顿时间不能太小,太小会导致出现G1跟不上垃圾产生的速度。最终退化成Full GC。所以对这个参数的调优是一个持续的过程,逐步调整到最佳状态。 |
-XX:+ConcGCThreads=n | CMS并发收集器使用的线程数 |
7.1 参数查看
(1)-XX:PrintFlagsFinal参数
用法:
java -XX:+PrintFlagsFinal -version
结果:
[Global flags]
uintx AdaptivePermSizeWeight = 20 {product}
uintx AdaptiveSizeDecrementScaleFactor = 4 {product}
uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product}
....
表格的每一行包括五列,来表示一个参数。
- 第一列表示参数的数据类型
- 第二列是名称
- 第三列”=”表示第四列是参数的默认值,而”:=” 表明了参数被用户或者JVM赋值了。
- 第四列为值
- 第五列是参数的类别。
可以进行过滤,仅查看被修改项:
java -XX:+PrintFlagsFinal -version | grep ":"
使用 java -XX: +PrintFlagsFinal 输出到一个文件中
java -XX:+PrintFlagsFinal >params.txt
(2)通过 jps 命令查看
列出系统中所有的 Java 应用程序
用法:
jps
jps -l
(3)通过 jinfo 命令查看
jinfo 是 JDK 自带的命令,可以用来查看正在运行的 java 应用程序的扩展参数,包括Java System属性和JVM命令行参数;也可以动态的修改正在运行的 JVM 一些参数。当系统崩溃时,jinfo可以从core文件里面知道崩溃的Java应用程序的配置信息
用法:
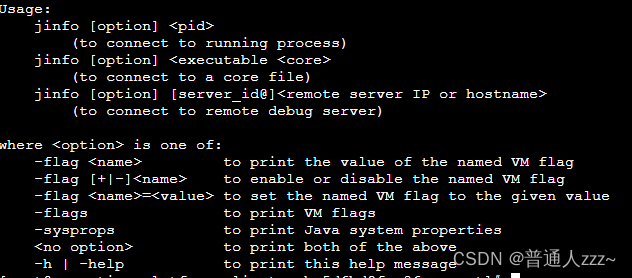
no option 输出全部的参数和系统属性
-flag name 输出对应名称的参数
-flag [+|-]name 开启或者关闭对应名称的参数
-flag name=value 设定对应名称的参数
-flags 输出全部的参数
-sysprops 输出系统属性
(4)通过 stat 命令查看
Jstat是JDK自带的一个轻量级小工具。全称“Java Virtual Machine statistics monitoring tool”,它位于java的bin目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。可见,Jstat是轻量级的、专门针对JVM的工具,非常适用。
用法:
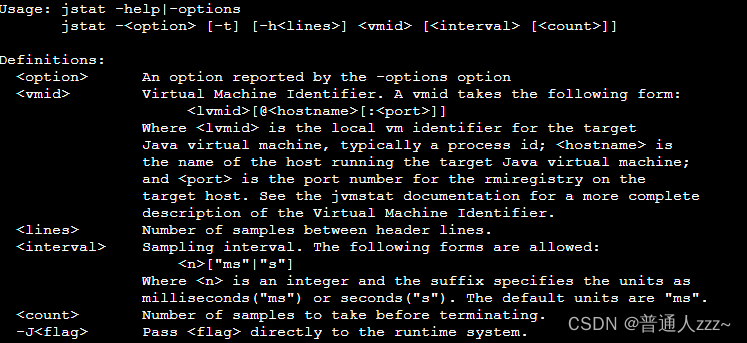
-class:统计class loader行为信息
-compile:统计编译行为信息
-gc:统计jdk gc时heap信息
-gccapacity:统计不同的generations(包括新生区,老年区,permanent区)相应的heap容量情况
-gccause:统计gc的情况,(同-gcutil)和引起gc的事件
-gcnew:统计gc时,新生代的情况
-gcnewcapacity:统计gc时,新生代heap容量
-gcold:统计gc时,老年区的情况
-gcoldcapacity:统计gc时,老年区heap容量
-gcpermcapacity:统计gc时,permanent区heap容量
-gcutil:统计gc时,heap情况
# 查看某个java进程的类装载信息,每1000毫秒输出一次,共输出10次
jstat ‐class PID 1000 10
# 查看某个java进程的GC信息,每1000毫秒输出一次,共输出10次
jstat ‐gc PID 1000 10
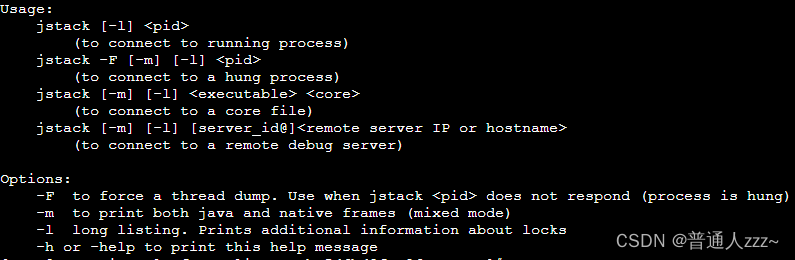
(5)通过 jstack 命令查看
- jstack 命令用于打印指定 Java进程、核心文件或远程调试服务器的Java线程的 Java 堆栈跟踪信息。
- jstack 命令可以生成 JVM 当前时刻的线程快照。线程快照是当前JVM内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
用法:
(6)通过 jmap 命令查看
用法:
# 查看 Java内存信息(可以查看新生代、老年代、s0、s1、eden区信息)
jmap ‐heap PID
# 显示Java堆中对象的统计信息,包括:对象数量、占用内存大小(单位:字节)和类的完全限定名。
# 如果指定了live参数,则只计算活动的对象
jmap -histo PID
jmap -histo:live PID
# 显示Java堆中元空间的类加载器的统计信息,包括:
# - class_loader:当Java虚拟机运行时,类加载器对象的地址
# - classes:已加载类的数量
# - bytes:该类加载器加载的所有类的元数据所占的字节数
# - parent_loader:父类加载器对象的地址,如果没有显示null。
# - alive:是否存活的标识,表示类加载器对象是否将被垃圾回收。
# - type:该类加载器的类名。
jmap -clstats PID
# 生成Java虚拟机的堆转储快照dump文件
jmap -dump:[live,]format=b,file=
# live参数是可选的,如果指定,则只转储堆中的活动对象;如果没有指定,则转储堆中的所有对象。
# format=b表示以hprof二进制格式转储Java堆的内存。
# file=<filename>用于指定快照dump文件的文件名。
# 如:jmap ‐dump:format=b,file=heap.hprof PID
八、常用工具
8.1 JDK常用工具
(1)jconsole
JConsole 是一个内置 Java 性能分析器
(2)jvisualvm
jvisualvm 也是 JDK 自带的一个 Java 性能分析器,功能非常强大,可以对堆内存进行 dump、快照以及性能可视化分析,也可以安装插件对堆外内存进行分析。
8.2 第三方通用工具 - Arthas
Arthas(阿尔萨斯) 是阿里巴巴开源的 Java 诊断工具,基本使用场景是定位复现一些生产环境比较难以定位问题。可以在线排查问题,以及动态追踪 Java代码,实时监控 JVM 状态等等。
8.3 内存分析工具
(1)MAT
MAT 是Memory Analyzer的简称,他是一宽功能强大的Java堆内存分析器。多用于查找内存泄露以及查看内存消耗情况。 基于Eclipse开发,是一款免费的Java性能分析功能。通过 MAT 可以直接打开 dump 日子文件,快速分析、定位问题。
下载安装【https://www.eclipse.org/mat/downloads.php】
(2)HeapHero
HeapHero是一款简单的,易用的内存分析工具,无需登录在线生成分析报告。官网地址:【https://heaphero.io/heap-index.jsp】
(3)Perfma
官网地址:【https://console.perfma.com/】
8.4 GC分析工具
1. GC日志
可以使用不同的参数设置不同的日志文件,比如:‐XX:+PrintGCDetails ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCDateStamps ‐Xloggc:D:\gc.log
2. gcviewer:
在 github 上搜索 gcviewer 项目,并下载到本地。
GCViewer 项目没有提供现成的 release 版本,利用如下 maven 编译命令即可完成 GCViewer 的编译工作,最终生成一个gcviewer-1.36.jar
# 编译
mvn clean install -DskipTests
# 运行
java ‐jar gcviewer‐1.36‐SNAPSHOT.jar
3. gceasy
gceasy是一款可以分析gc日志,形成可视化的报表,支持快速排查问题,并且可以推荐jvm优化的配置(收费)
官网地址:【http://gceasy.io】
4. gcplot
gcplot 是一个灵活强大的jvm gc 查看,分析工具,方便的数据管理以及基于时间的数据筛选。
官网地址:【https://it.gcplot.com/】
推荐用docker 安装:
docker run ‐d ‐p 8088:80 gcplot/gcplot
运行后访问 http://192.168.xx.xx:8080,默认账户 admin / admin















 1237
1237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









