










上一讲讲到的是逻辑回归,并且提出了cross-entropy error(交叉熵误差)的概念,并使用了梯度下降算法;再上一讲讲到是线性回归,第二节课讲的是PLA算法。这三讲将会是我们这一讲的基础。
本节课讲的是用这些线性模型来解决分类问题。
线性模型解决二分类问题
之前的逻辑回归、线性回归和PLA,都有样本特征x的加权运算,我们引入一个线性得分函数s:

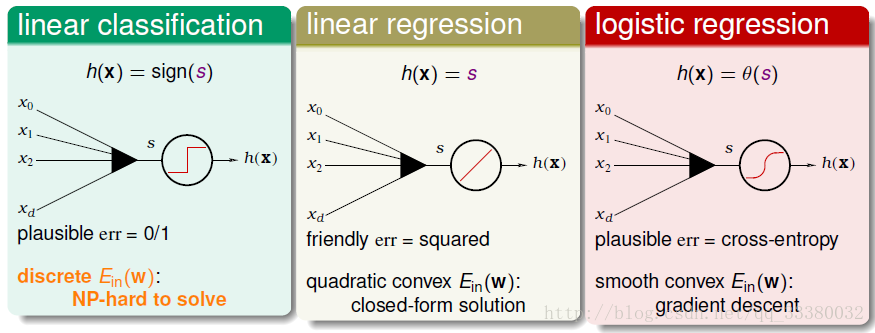
下面回顾个下三种线性模型
第一种是linear classification
hypothesis为h(x)=sign(s)
取值范围是-1,+1两个值
err是0/1的,对应的Ein(w)是离散的
是个NP-hard问题
第二种是linear regression
hypothesis为h(x)=s
取值范围为整个实数空间
err是p平方损失,对应的Ein(w)是开口向上的二次曲线,其解是closed-form,可用最小二乘法
第三种是logistic regression
hypothesis为h(x)=θ(s)
取值范围为[-1,1]之间
err是cross-entropy,对应的Ein(w)是平滑的凸函数,可以使用梯度下降算法
我们发现,linear regression和logistic regression的error function都有最小解。那么应该可以用这两种方法来求解linear classification问题

我们发现了,关键点在这:
上述三种模型的error function都引入了ys变量,ys的物理意义就是指分类的正确率得分我们希望他越大越好。
下面把他们的error functions都画出来(此处略过对逻辑回归的损失函数的scaled处理)
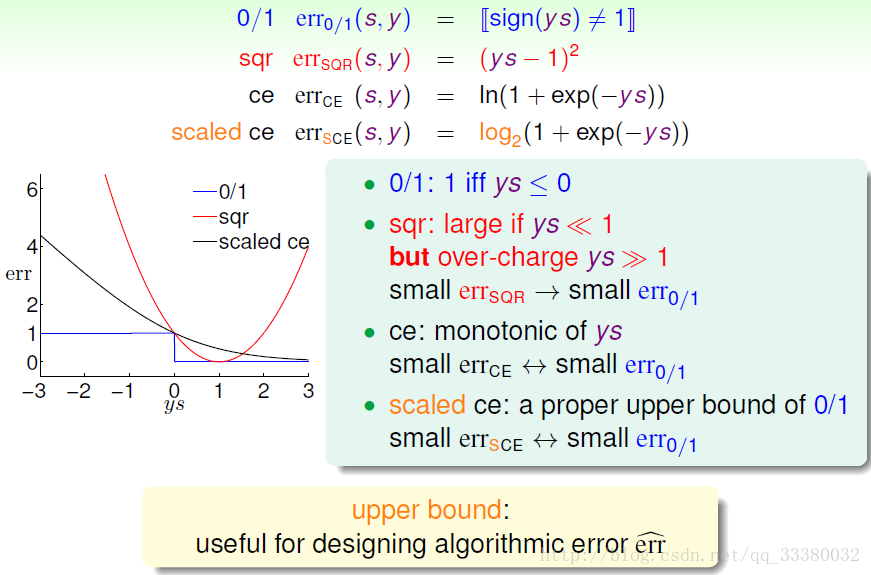
我们从图像中得出一个初步的结论:
err 0/1是被限定在一个上界中。这个上界是由逻辑回归模型的损失函数决定的。而线性回归的其实也是线性分类的一个上届,只是随着sy偏离1的位置越来越远,线性回归的损失函数偏差越来越大。综上所述,线性回归和逻辑回归都可以用来解决线性分类的问题。
证明如下:

现在我们来看下已经被证明可以用来解线性分类问题的三个算法吧:

结合这写个算法的优缺点我们有这样的实践经验:
通常,我们使用线性回归来获得初始化的w0,再用逻辑回归模型进行最优化解。
随机梯度下降算法
PLA算法和逻辑回归算法,都用到了迭代。PLA每次迭代只会更新一个错误点,时间复杂度是O(1)/次迭代;而逻辑回归每次迭代要对所有N个点都进行计算,时间复杂度是O(N)/次迭代。为了提高逻辑回归中梯度下降算法的速度,可以使用另一种算法:随机梯度下降算法。
随机梯度下降算法每次迭代只找到一个点,计算该点的梯度,作为我们下一步更新w的依据。把整体的梯度看成这个随机过程的一个期望值。
写成表达式的过程:
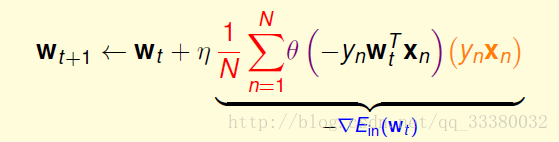
单次看,好像每一步对找到正确梯度方向有影响,但是整体上,没有差太多,同样能找到最小值位置。随机梯度下降的优点是减少计算量,提高运算速度,而且便于online学习;
缺点是不够稳定,每次迭代并不能保证按照正确的方向前进,而且达到最小值需要迭代的次数比梯度下降算法一般要多,毕竟省时间不省力啊。
和PLA比较一下:

我们把基于随即梯度下降的逻辑回归称之为softPLA,因为PLA只对分类错误的点进行修正,而基于随即梯度下降的逻辑回归每次迭代都会进行或多或少的修正。
那么终止条件是什么呢?
easy:
1、迭代次数。足够多
2、学习率η。η的取值是根据实际情况来定的,一般取值0.1就可以了。
基于逻辑回归的多分类
下面要将下图中的四个元件分出来:

我们可以通过四次二分类,但是下面花圈的地方该怎么办呢
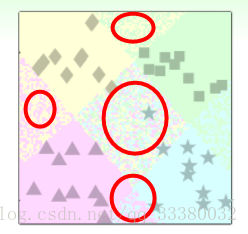
针对这种问题,我们可以使用另外一种方法来解决:soft软性分类,即不用{-1,+1}这种binary classification,而是使用logistic regression,计算某点属于某类的概率、可能性,去概率最大的值为那一类就好。
处理过程和之前类似,同样是分别令某类为正,其他三类为负,不同的是得到的是概率值,而不是{-1,+1}。最后得到某点分别属于四类的概率,取最大概率对应的哪一个类别就好。效果如下图所示:
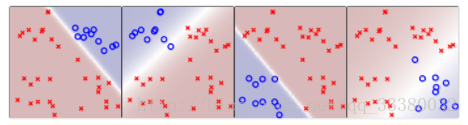
一旦被夹在中间,就比一比谁的概率更大就好了~
但是有个缺陷是:没有规定加起来要是1
这种方式给她一个名字:

我们称之为One-Versus-All(OVA) Decomposition。这种方法的优点是简单高效,可以使用logistic regression模型来解决。
但是不太适合类别很多的时候。
基于二分类的多分类
我们刚刚讲的多分类算法OVA,但是这种方法存在一个问题,就是当类别k很多的时候,造成正负类数据不平衡,会影响分类效果,表现不好。现在,我们介绍另一种方法来解决当k很大时,OVA带来的问题。
看要分多少类,设为n,则制作n(n-1)个分类器,之后对于边界,站着多数那边。
例如:
如果平面有个点,有三个分类器判断它是正方形,一个分类器判断是菱形,另外两个判断是三角形,那么取最多的那个,即判断它属于正方形,我们的分类就完成了。
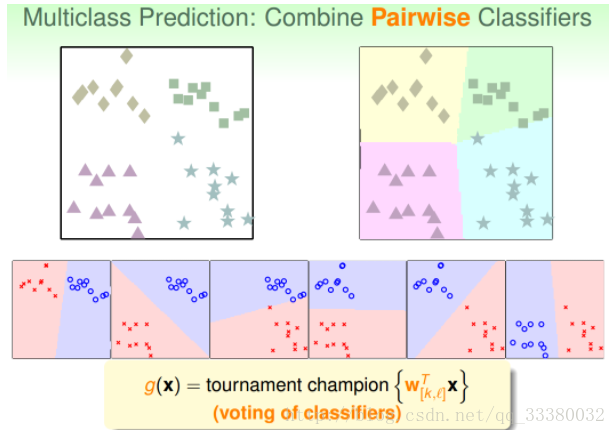
这种区别于OVA的多分类方法叫做One-Versus-One(OVO)

总结
最后总结一下:


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









