







想要更好的阅读体验,可以转我的个人博客: nonlinearthink
2002年前,Linux社区一直急缺一个好用的版本控制系统,Linus一开始选用了一个商业的版本控制系统BitKeeper,但是后来因为社区的人试图破解BitKeeper的协议,最终和BitMover公司翻脸了。Linus被迫无奈,花了两个星期写出了Git。
分布式版本控制系统
集中式的版本控制系统
说到分布式版本控制系统,就必须要说一下传统的集中式版本控制是怎么做的。
在集中式的版本控制系统中,代码被保存在一个服务器中,客户端通过远程连接服务器来更改代码。
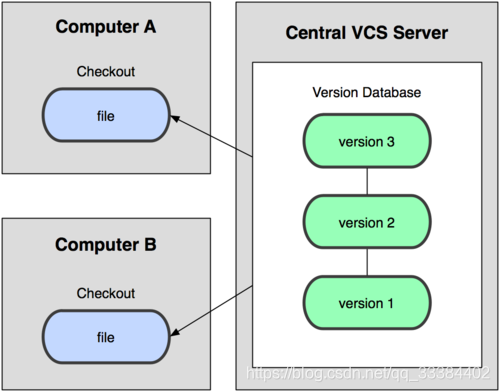
这导致了一旦服务器崩溃,整个项目都面临丢失的风险。
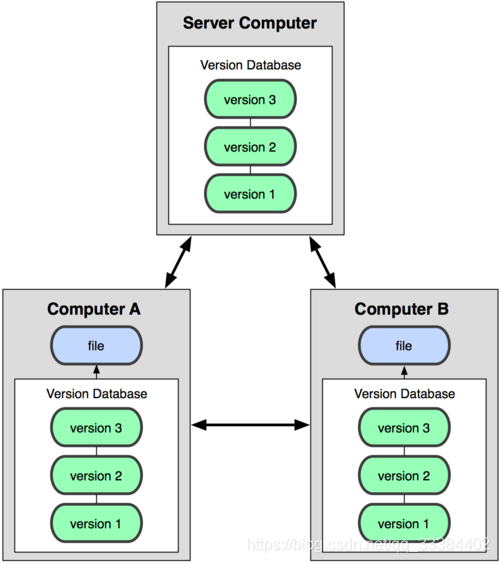
分布式的版本管理系统
类似 Git 的分布式版本控制的做法稍有不同,客户端每次都要拷贝一遍服务器的代码,然后在本地修改后提交到服务器。
这样,就算服务器的代码丢了,客户端这边有很多备份,就没有关系。
远程仓库实战
前面提到了分布式的概念,远程仓库正是这种模式的核心。
克隆远程仓库到本地
获得一个 Git 仓库的其中一个办法,就是克隆别人的仓库。
git clone https://github.com/lifeInZUCC/ZUCC-intersection
这会在当前目录创建一个名叫 ZUCC-intersection 的文件,然后从后面的链接位置把整个仓库克隆下来,这就是我们所说的分布式的概念。
一般情况下,Github 不太容易出现数据丢失,所以我一般还习惯另外一个操作:
git clone https://github.com/lifeInZUCC/ZUCC-intersection --depth=1
--depth=1 代表只克隆最近的一个记录,可以节省很多存储空间和克隆时间,特别对于迭代周期比较长和比较大的项目来说。
把本地创建的仓库关联到远程
如果你的仓库是自己搭建的,不是克隆来的,现在要把这个仓库发布到远程服务器上,则需要关联。
例如,要发布到 Github 上,可以这样做:
git remote add origin git@github.com:nonlinearthink/ZUCC-intersection
这句话的意思是设置了一个默认的远程仓库,名叫 origin。
发布到远程仓库
关联结束之后,你就需要发布了。
可以通过使用 git push 命令实现。
git push origin master
这代表把当前分支发布到 origin 远程仓库的 master 分支上。
同步远程仓库
在多人合作的场景下,如果别人改了远程仓库,我们就需要把别人的更改的内容同步到本地。
git fetch
fetch 只检查远程仓库和本地仓库的内容,但不更新。
git pull
pull 会直接更新。
文件管理系统
时刻监察文件状态
你不可能修改了文件或目录之后,Git 对此却一无所知。
Git 使用 SHA-1 算法计算数据的校验和。通过对比校验和,来判断文件是否改变了。
每过一段时间都要计算一次。所以,如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git 都能立即察觉。
不保存差异,保存整个文件
这是一个比较有争议的点,很多人觉得这会增大 Git 的体积。
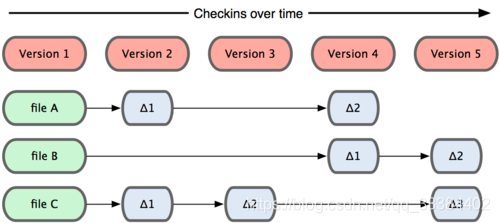
在传统的模式中,每一个文件都维护来一个链表,每次文件更新之后,才会创建一个新的链表项,只保留差异的部分。
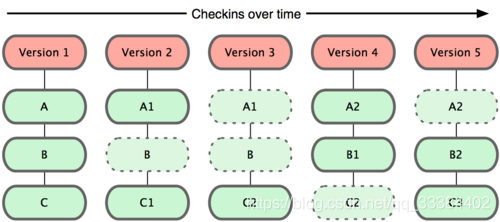
Git 使用的是上图的这种模式,每当文件更新的时候就记录一次快照,如果没有更新,会保存一个快照的指针,指向上一个文件快照。
虚线代表了一个指针,而不是实体。
文件的三状态模型
Git 的文件有三种状态,commited、staged、modified。
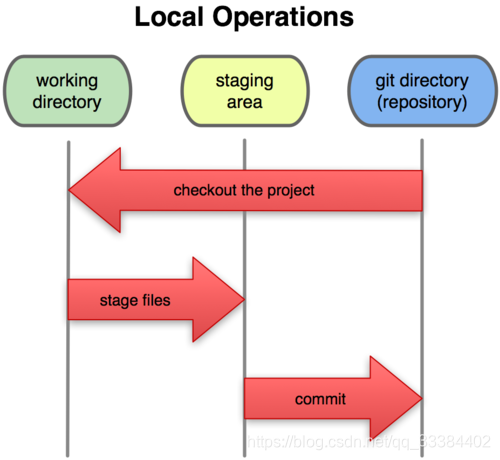
为什么要设计三种状态?
- 当处于
modified状态的时候,代表文件被修改,但是还没暂存记录,这个时候你可以随意更改文件。 - 当你工作了一半,为了防止数据丢失,可以把
modified状态的文件暂时存储一下,也就是转到了staged状态。如果你反悔了,只要取消暂存,原来的文件又回来了。 - 当一部分工作做完之后,你觉得可以提交到代码仓库里去了,那就把
staged状态的文件转到commited状态,代表了正式提交到代码仓库中。
上面说了,Git 是分布式的,所以第三步只是在本地的代码仓库提交了代码,你还得把本地的代码提交到服务器。
很多大公司有自己的 Git 服务器,更多的个人开发者则喜欢使用类似于
Github、Gitlab、Gitee、Coding等等的网站来做服务器。目前
Github是全球最大的代码托管平台,目前由微软资助。
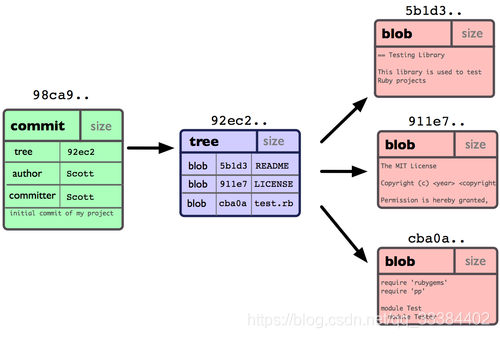
commit的五对象模型
Git 仓库中一次 commit(提交) 被分为 5 个对象,可分为 3 类:
- 3 个 blob 对象 (代表类上面说的3种文件)
- 1 个 tree 对象
- 1 个 commit 对象
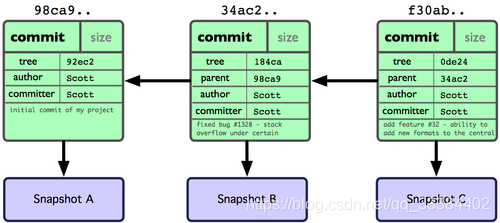
commit之间又是一种链式的关系:
文件状态转换实战
初始化项目
在当前目录下,使用命令:
git init
会创建一个 .git 的文件夹,现在,这个目录就被转换成 Git 项目。
暂存文件
使用git add命令可以把文件加入 Git 的追踪系统,也就是变成staged状态。
当我们修改了这个文件之后,它就变成modified状态。
需要再次使用git add命令,文件才会再次变成staged状态。
Git 的文件通配符就是 shell 的通配符,对 shell 脚本熟悉的话就懂了。
git add *
这条命令会把文件夹下所有文件都加入 Git 的追踪。
有一个例外就是,编写.gitignore,可以忽略一些文件,永远不会被 Git 追踪,可以自己去查怎么编写。
值得一提的是,这种情况下使用git add *会出现警告,我一般推荐使用git add -A,都是添加全部文件,但是它会先检查.gitignore里的内容。
提交代码
git commit 命令会把staged状态的文件转为commited状态。也就是提交到当前的分支中去。
git commit -m "update xxx"
-m 参数后加一个字符串,可以为提交代码做一些说明。
分支的概念
分支是平行宇宙。
当他们在一个节点分离之后,就有了自己的发展方向。
其中,有一个 HEAD 指针,是你当前所在的分支,你可以通过改变这一个指针来切换分支。
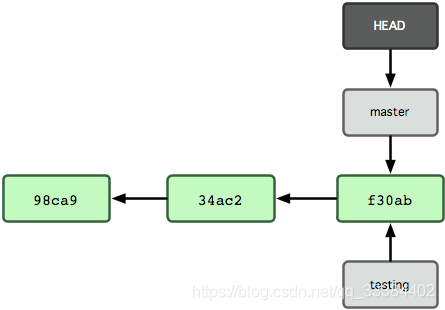
基于分支的开发模型
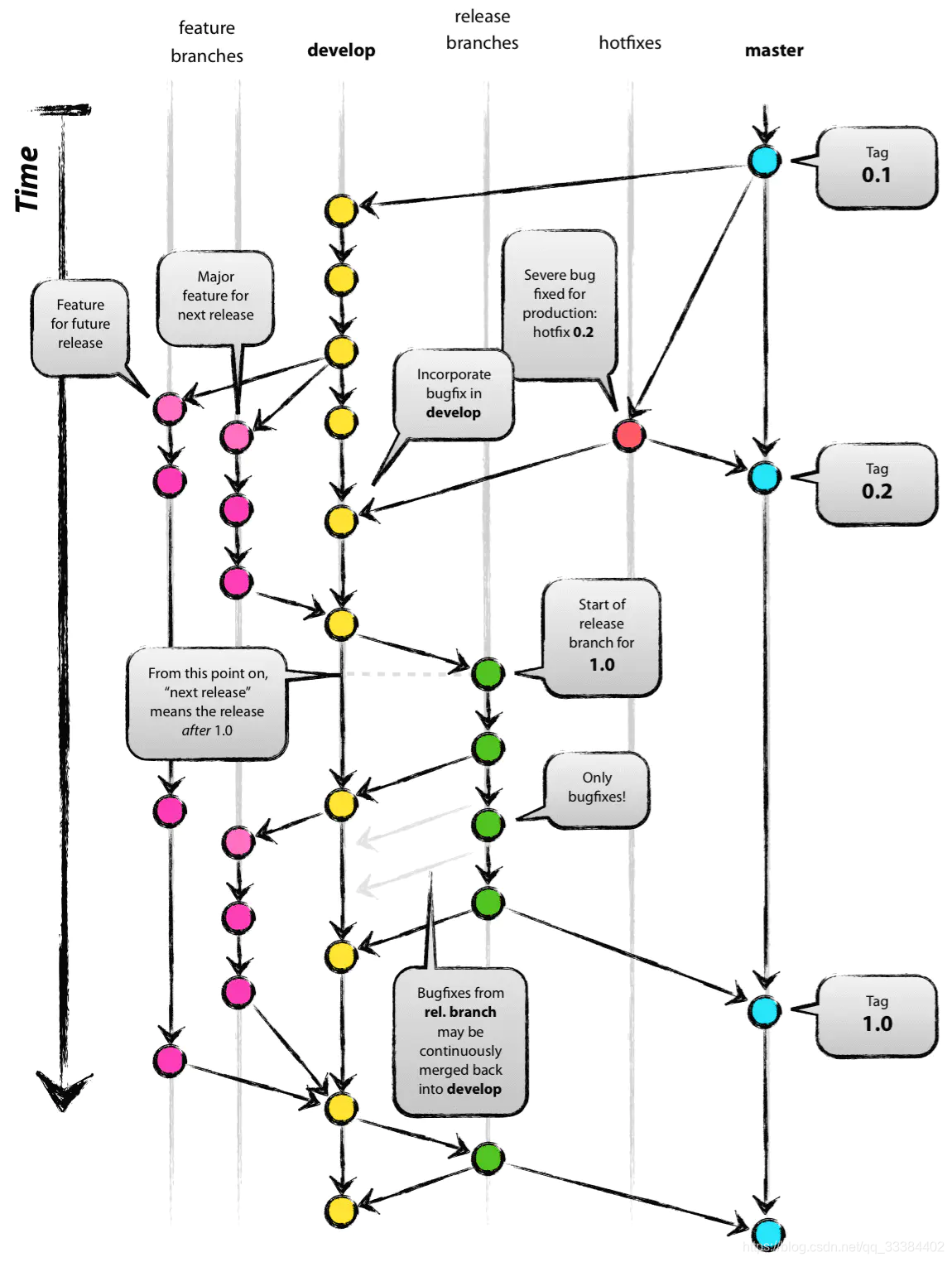
这是一个标准的开发模型,我们不去阐述这么复杂的模型,这里仅仅讨论单分支模型和双分支模型。
看了这张图,你应该知道,所谓的版本管理,就是分支的管理。
单分支模型
就是从头到尾都是一个 master 分支。这个没什么好说的。
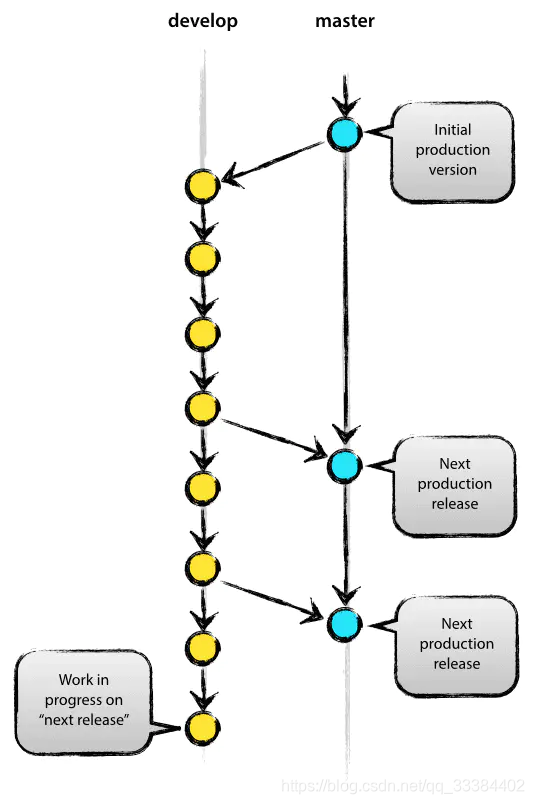
双分支模型
或者也可以叫 master/develop 开发模型。
稳定版的代码发布在 master 分支,而一些新功能和特性。还在开发当中,就放到 develop 分支。
冲突
一个复杂的 Git 系统中,分支众多,当我们合并分支的时候,很容易遇到冲突。
这个时候就需要手动解决一下冲突,然后再合并。这需要你查看报错的地方,然后去找出来并修改。
分支管理实战
创建分支
git branch develop
这个命令会创建一个名叫 develop 的分支。
切换分支
git checkout develop
这个命令会切换分支到 develop 分支,前提是你之前已经创建过了。
这个命令的本质其实就是移动了 HEAD 指针。
默认状态下,使用的是 master 分支。
创建并切换
git branch -b develop
结合了上面两个步骤。
合并分支
我们先切换回 master 分支。
git checkout master
现在把 develop 分支合并到 master 分支。
git merge develop
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











