






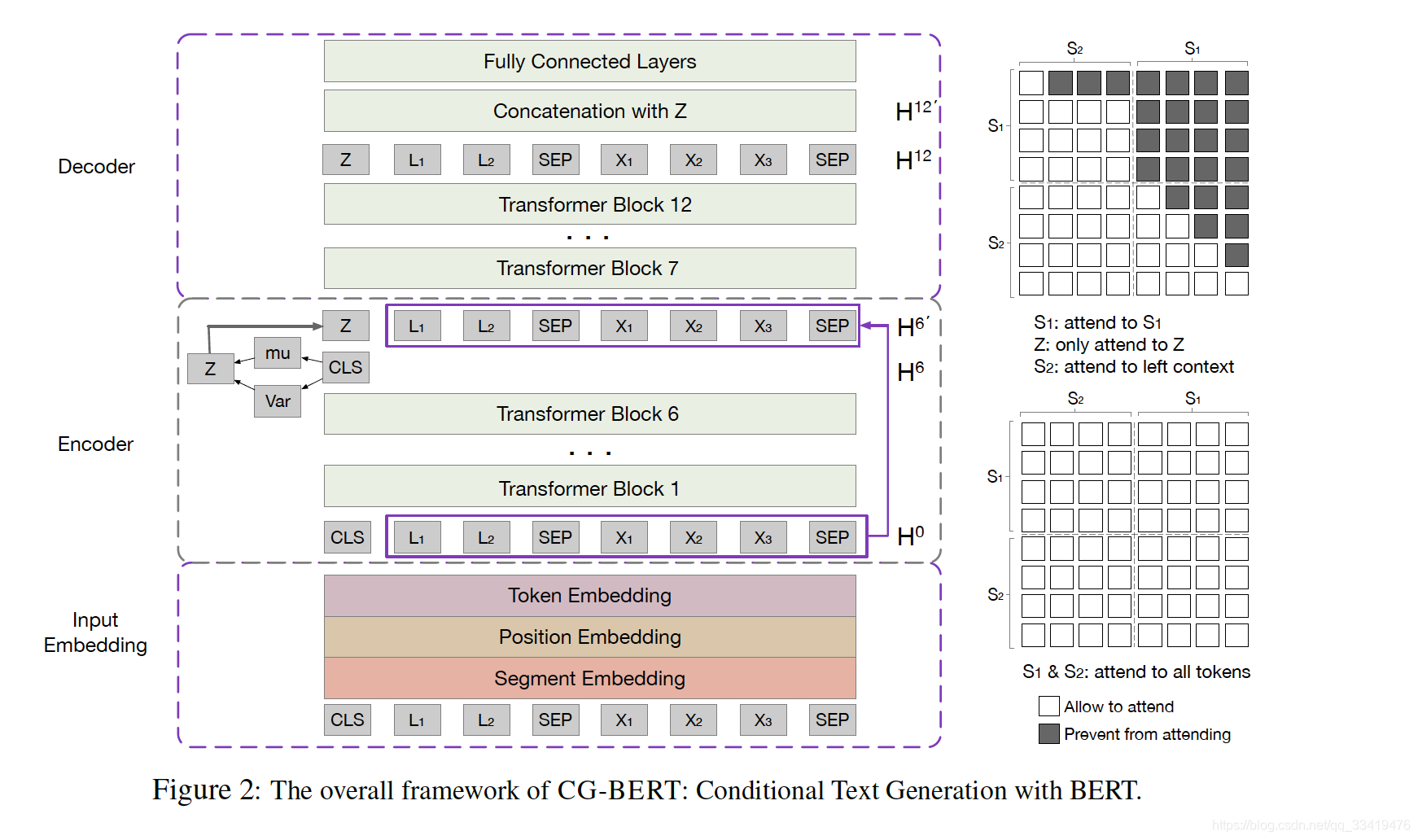
 该博客介绍了一种名为CG-BERT的方法,它结合了条件变分自编码器(CVAE)和BERT,用于处理具有少量样本的新意图的文本生成。CG-BERT的编码器将输入话语和意图编码为潜在变量,解码器则使用这个变量和意图来重构输入。在训练过程中,模型通过采样学习到的分布生成新意图的话语。此外,输入表示为意图和话语文本的串联,通过BERT进行编码,利用自我注意力机制获取深层双向上下文信息。解码器则采用掩码注意力机制以左到右的方式生成文本,适应条件文本生成任务。最后,模型通过微调以提高在少样本意图识别中的表现。
该博客介绍了一种名为CG-BERT的方法,它结合了条件变分自编码器(CVAE)和BERT,用于处理具有少量样本的新意图的文本生成。CG-BERT的编码器将输入话语和意图编码为潜在变量,解码器则使用这个变量和意图来重构输入。在训练过程中,模型通过采样学习到的分布生成新意图的话语。此外,输入表示为意图和话语文本的串联,通过BERT进行编码,利用自我注意力机制获取深层双向上下文信息。解码器则采用掩码注意力机制以左到右的方式生成文本,适应条件文本生成任务。最后,模型通过微调以提高在少样本意图识别中的表现。
目录
discriminate a joint label space consisting of both existing intent which have enough labeled data and novel intents which only have a few examples for each class.
==> Conditional Text Generation with BERT
The proposed method
CG-BERT: adopts the CVAE(Condiional Variational AutoEncoder) framework and incorporates BERT into both the encoder and the decoder.
采用条件变分自编码器,并将BERT融入到encoder-decoder中
- the encoder: encodes the utterance x and its intent y together into a latent variable z and models the posterior distribution p(z|x,y), where y is the condition in the CVAE model.
编码器:同时将话语x和意图y编码为一个潜变量z,并且模拟z的后验概率分布p(z|x,y),y是CVAE模型中的条件。 ==> encoder模拟few-shot intent的数据概率分布
- the decoder: decodes z and the intent y together to reconstruct the input utterance x.
解码器:同时解码变量z和意图y,以便重构输入话语x ==> 利用masked attention的特性限制attend,以保持文本生成这种特定任务left-to-right的特性,保留其autoregressive特性!
- to generate new utterances for an novel intent y, we sample the latent variable z from a prior distribution p(z|y) and utilize the decoder to decode z and y
into new utterances.
为新意图y生成新话语,我们通过从一个先验分布p(z|y)采样潜变量z,并且用解码器解码变量z和y to 新话语。
It's able to generate more utterances for the novel intent through sampling from the learned distribution.
通过从学到的概率分布中采样,为新意图生成更多的话语
Input Representation
input: intent + utterance text sentences (concatenated)
句子S1: CLS token + intent y + SEP token --> first intent sentence
句子S2: utterance x + SEP --> second utterance sentence
whole input: S1 + S2
CLS: as the representation for the whole input
variable z: encode the embeddings for [CLS] to the latent variable z
Text are tokenized into subword units by WordPiece
embedding: obtained for each token --> token embeddings, position embeddings, segment embeddings
a given token: constructed by summing these three embeddings and represented as with a total length of T tokens.
The Encoder
models the distribution of diverse utterances for a given intent.
对给定intent,即few-shot intent,的不同话语分布进行建模
to obtain deep bidirectional context information <-- models the attention between the intent tokens and the utterance tokens
为获得深度双向上下文信息 <-- 利用意图令牌和话语令牌之间的attention进行建模
the input representation:
multiple self-attention heads:
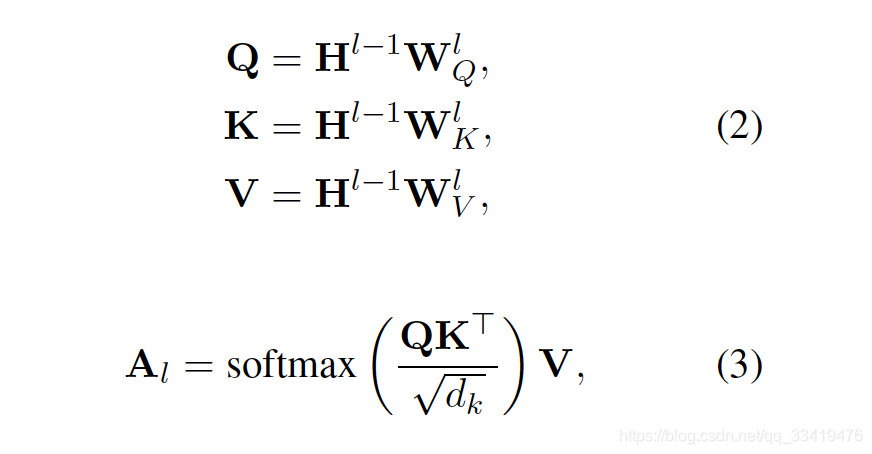
output of the previous layer --> a triple of queries, keys and values
embeddings for the [CLS] token in the 6-th transformer block --> sentence-level representation
sentence-level representation --> a latent variable z = a latent vector z, where prior distribution p(z|y) is a multivariate standard Gaussian distribution.
u and in the Gaussian distribution q(z|x,y) = N(u,
) --> to sample z
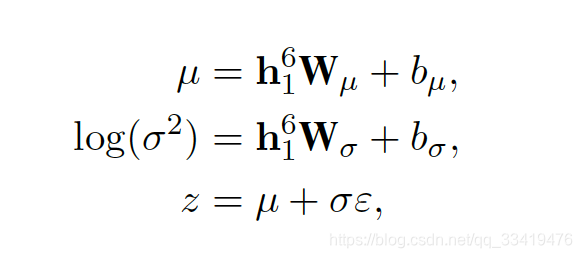
The Decoder
aims to reconstruct the input utterance x using the latent variable z and the intent y.
目的是用潜变量z和意图y重构输入话语x
residual connection from input representation H0 --> decoder H6'残差连接z和H0
==> input of the decoder
left-to-right manner ==> 掩码masked attention
the attention mask --> helps the transformer blocks fit into the conditional text generation task.
attention掩码 --> 帮助transformer块适应有条件文本生成任务
not whole bidirectional attention to the input ==> instead a mask matrix to determine whether a pair of tokens can be attended to each other.
并不是全部双向attention的输入 ==> 而是用一个掩码矩阵去决定一对令牌是否要相互关注
updated Attention:
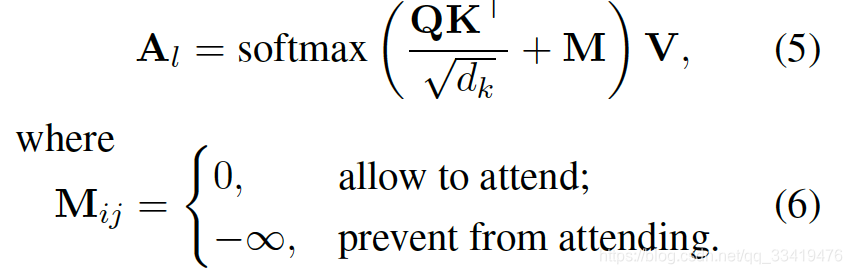
output of 12-th transformer block in decoder ,
is the embeddings for the latent variable z
To further increase the impact of z and alleviate the vanishing latent variable problem,
embeddings of z with all the tokens ,
Two fully-connected layers with a layer normalization to get the final representation
to predict the next token at position t+1 <-- the embeddings in Hf at position t

fine-tuning
in order to improve the performance in the few-shot intent of model learned from existing intents with enough labeled data.
reference: Cross-Lingual Natural Language Generation via Pre-training


















 2592
2592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











