






 本文提出了一种基于Transformer的时空融合网络TSTFN,用于地铁客流预测。该模型整合多种预定义图结构,通过多图卷积捕捉空间依赖性,并利用时空同步自注意力层同时建模时间和空间相关性。
本文提出了一种基于Transformer的时空融合网络TSTFN,用于地铁客流预测。该模型整合多种预定义图结构,通过多图卷积捕捉空间依赖性,并利用时空同步自注意力层同时建模时间和空间相关性。
1.文章信息
本周阅读的论文是题目为《Transformer Based Spatial-Temporal Fusion Network for Metro Passenger Flow Forecasting》的一篇2021年发布在International Conference on Automation Science and Engineering (CASE)会议上的基于时空Transformer预测地铁客流的文章。
2.摘要
客流预测是城市轨道交通系统日常运营中一项重要任务。深度学习得飞速发展为我们提供了一个机会实现端到端的网络级客流预测,然而复杂的客流时空相关性使其充满挑战。现有模型尝试将时间和空间相关性分开建模,会导致信息缺失以及预测效果不佳。同时,无法充分利用人类知识和额外信息进行建模,例如地理信息、地铁网络图信息。在这篇文章中,作者提出一个基于transformer的时空融合网络(TSTFN)。为了整合不同类型的额外信息研究其对客流预测的影响,作者首先使用多重预定义图结构构建多角度GCN以建模空间依赖性,接着提出一个新的时空同步自注意力层同时建模时间和空间相关性。实验表明TSTFN在长时或短时客流预测中的表现均优于现有的先进深度学习模型。该模型重要成分的有效性通过消融实验分析得到验证。
3.介绍
ITS的迅速发展要求我们精确预测地铁客流。从问题描述角度出发,客流预测是一项典型的时空预测任务,主要挑战如下:
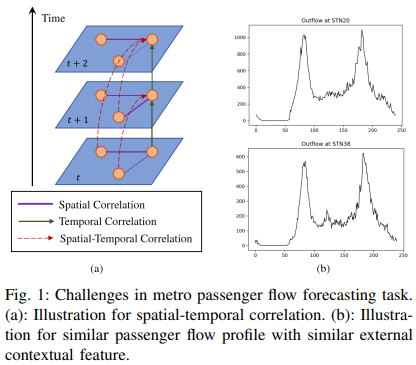
首先,复杂的时空相关性是一个重要问题。如图1(a)所示,如果我们将地铁站点定义为图网络的节点,对于每个单一节点,其客流将十分依赖历史客流变化,这类与时间相关的依赖性可以定义为时间相关性。同样在指定的时间片段,每个节点的客流会影响其他节点客流,这类节点依赖性可以定义为空间相关性。大部分的现有研究选择分别建模这两类相关性,事实上同时建模时空相关性应该被考虑因为每个节点可以直接影响其他节点其他时刻的客流。
其次,我们不仅关注单步预测,同样希望对未来系统有长时了解。为实现这个目标,应该考虑端对端的多步预测。一个重要的挑战是避免误差传播,尤其是一些自回归模型例如RNN,预测误差会不可避免地累积。
第三点,我们可以考虑一些额外信息,这些信息会为建模复杂依赖性提供有力支持。例如,如图1(b)所示,不同地铁站点可能会表现出相似的客流模式。考虑这两个车站的位置信息,附近均存在很多学校、公共设施或者居民小区,这也是为什么它们展示典型的早晚高峰特征。除了上述提到的POI信息,一些其他先验信息例如地铁系统的连通性,地理距离以及客流剖面相似度均可以为预测提供有效信息。但先前的研究仅考虑一种特定类型的知识以建模空间相关性,如何整合不同类型的空间相关性知识仍是一个重要任务。
为解决上述挑战,作者提出了基于Transformer的时空融合网络(TSTFN)并提供了一种端对端的方法实现多步预测。模型同步建模时空依赖性并使用多种类型的额外信息实现多步预测。文章的主要贡献点如下:
作者提出了一个基于Transformer的模型解决时间序列数据的复杂依赖性,尝试同时捕捉时空依赖性,获得了一个更加强大的特征提取模块。
作者使用多种先验额外信息进行建模,考虑越多的额外信息,越复杂越全面的空间依赖性可以被模型捕捉。
作者提出的端对端框架实现了多步预测。模型在两个地铁数据集上的实验结果表明无论是长时或者短时客流预测,TSTFN均具备良好预测效果。
4.模型
Problem Formulation
假设共有N个地铁站点。给定先验额外信息(例如图结构)G,在时刻t,表示输入信号,一共有P个维度特征,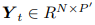 表示目标客流序列,共有个维度。文章问题可以表示为学习一个函数f以根据过去T个历史信号预测未来个时间步的目标客流。映射过程可以表示为:
表示目标客流序列,共有个维度。文章问题可以表示为学习一个函数f以根据过去T个历史信号预测未来个时间步的目标客流。映射过程可以表示为:
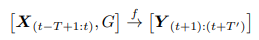
2. Multi-View Spatial Dependence Capture
GCN提供了一个可靠的方式聚合图结构中节点的空间特征。令A为预定义图的邻接矩阵,则归一化拉普拉斯矩阵可以定义为L= 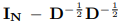 ,此处表示单位矩阵,D表示度矩阵。有关图卷积的计算实现有多种形式,本节使用一种近似但高效的图卷积运算,即使用切比雪夫多项式。
,此处表示单位矩阵,D表示度矩阵。有关图卷积的计算实现有多种形式,本节使用一种近似但高效的图卷积运算,即使用切比雪夫多项式。
其中表示图卷积操作,是可学习参数, ,是拉普拉斯矩阵的最大特征值,切比雪夫多项式为
,是拉普拉斯矩阵的最大特征值,切比雪夫多项式为 。
。
由于GCN的本质是将数据聚合到图上,十分依赖图结构,如果同时考虑多个节点的连通性,则很难提前定义图结构。为解决这个问题,文章提出使用多重预定义图 实现多图卷积。
实现多图卷积。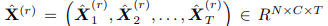 表示第r层多图卷积块的输入,此处C表示隐藏维度。对于时刻t,给定不同图结构,根据上述的切比雪夫多项式,可以得到滤波后的图输出。
表示第r层多图卷积块的输入,此处C表示隐藏维度。对于时刻t,给定不同图结构,根据上述的切比雪夫多项式,可以得到滤波后的图输出。
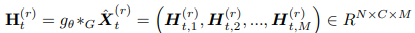
3. Spatial Temporal Synchronous Dependence Capturing
文章使用自注意力机制捕捉不同时间步的时间依赖性以及不同预定义图结构的空间依赖性。根据多图卷积的计算公式,将其所有历史时间步的输出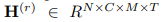 作为第r层时空同步自注意力模块的输入,其中
作为第r层时空同步自注意力模块的输入,其中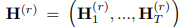 。换句话说,模型将视为长度等于T×M的序列,每个元素的维度为N×C。
。换句话说,模型将视为长度等于T×M的序列,每个元素的维度为N×C。
在注意力模块中,首先将通过可学习权值 映射到子空间得到
映射到子空间得到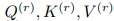 ,如下公式:
,如下公式:
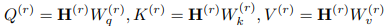
接着计算得到scaled dot-product attention:
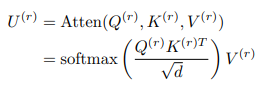
另外,使用多头注意力机制联合学习不同子空间的依赖性:
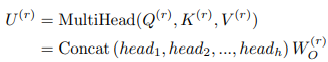
通过注意力机制,每个输入元素可以与其他时间步中来自其他图结构的元素相关,这种大范围调整尝试同时捕捉时间和空间依赖性,最后使用两个带有ReLU激活函数的前馈神经网络层,可以获得最终输出。
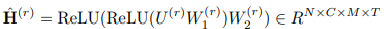
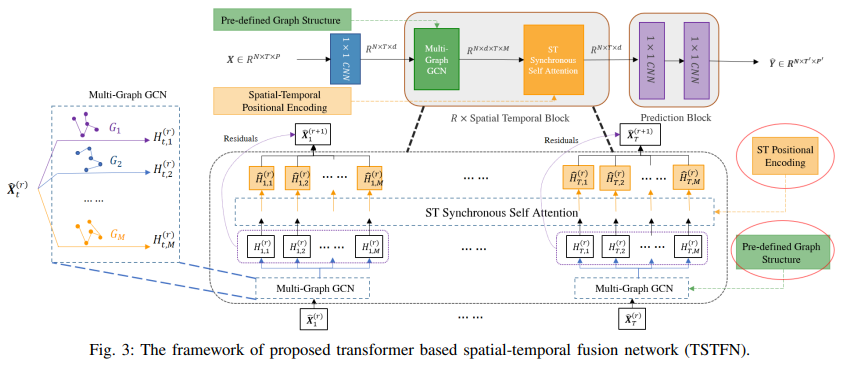
如图三所示,提出的时空transformer网络由堆叠的时空模块和一个预测层组成。每个时空模块由一个spatial transformer和一个temporal transformer构成以联合提取时空特征。时空模块可以进一步堆叠形成深度模型便于捕捉深度时空特征。另外,预测层使用两个单位卷积层以聚合这些时空特征用于交通预测。
4. Model Framework
基于上述提到的模块,文章搭建了如图3所示的模型框架。使用1×1的CNN调整输入维度,并将其依次输入至R个时空模块。每个时空模块包含一个多图卷积层和一个时空同步自注意力层。
由于自注意力机制不存在循环,且不包含序列中每个元素的相对位置信息,因此需要使用额外的位置编码反映元素的位置。在时空同步注意力层中,时间和空间的编码均被考虑。首先是位置编码,与大部分常见的序列模型一样,文章使用Sine和Cosine函数编码位置信息,其中pos表示相关位置,i是编码维度, 是编码向量的长度。
是编码向量的长度。
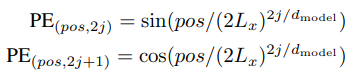
模型使用地铁客流数据的周期特征作为其他类型的时间编码,通过使用one-hot编码整合一天中的研究时间。例如,将一天划分为T个时间段,作者使用一个T维的one-hot编码和一个用于调整维度的线性层作为时间编码。同时,作者使用node2vec作为空间编码,即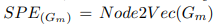 ,其中表示邻接矩阵。
,其中表示邻接矩阵。
最后一个时空模块的输出将输入到预测模块中。与基于RNN的预测方法不同,基于CNN的预测模块可以在避免误差累积的情况下实现多步预测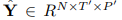 。平均绝对误差被视为训练误差
。平均绝对误差被视为训练误差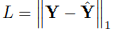 。
。
5.实验分析
文章在两个真实世界数据集CityMetro(经过脱敏)和HZMetro上对模型的预测效果进行实验验证。
(1) Datasets and Experiment Settings
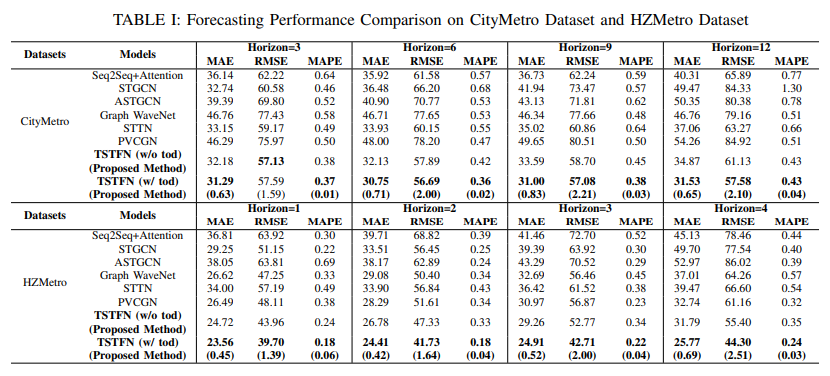
CityMetro:包含2017年前三个月89个地铁车站工作日的客流数据,重点是预测各个车站的出站客流。作者将6分钟的时间间隔作为一个时间步长,同时根据多图从不同角度考虑空间相关性:连通性图(表示地铁系统的连通性)、POI相似性(展示每个站点的功能信息),地理距离(表示站点的地理位置)以及动态时间规整相似性(表示客流断面相似性)。模型利用过去12个时间步的出站流数据预测未来12个时间步的客流。
HZMetro:包含2019年1月1日到1月25日,杭州地铁80个站点的客流数据。初始数据以每15分钟为时间段聚合,即作者以15分钟时间间隔作为一个时间步长。同时模型考虑了相似性图、关联性图以及连通性图在内的额外图结构。模型根据过去4个时间步的客流数据预测未来四个时间步的客流。因为模型仅使用了历史时间步数据,作者还加入了进站流数据以提高出站流数据的预测精度。
文章将数据集按6:2:2划分为训练集、验证集和测试集,使用学习率为0.001的Adam优化器优化参数,其他具体参数信息读者可以阅读原文了解。为了测试不同时间编码策略下模型的预测效果,文章进行一系列控制变量实验。首先定义仅包含第一种类型位置编码(Sin和Cos编码)的模型为TSTFN(w/o tod),意味着TSTFN模型不包含一天时间的信息;仅包含第二种类型位置编码(time-of-day)的模型定义为TSTFN(w/ tod),因为其使用了基于one-hot编码的每日时间信息。
(2) Evaluation Metrics and Baslines
文章根据MAE、MAPE和RMSE来评估STTN和其他基线模型的预测性能。基线模型主要为Seq2Seq+Luong Attention、STGCN、ASTGCN、Graph WaveNet、STTN以及PVCGN。
(3) Experiment Results
表1为TSTFN和其他基线模型在两个数据集上的预测效果指标。从表中可以看出TSTFN比其他深度学习模型预测效果更好,表明该模型均可以处理长时预测任务(CityMetro)和短时预测任务(HZMetro)。具体来说,PVCGN在HZMetro上的预测效果第二好,该模型同样使用了多图并使用了基于RNN的时间模型。二者实验结果的比较说明,一方面基于自注意力的多图GCN比PVCGN中简单将结果相加的做法能更好模拟动态空间依赖性;另一方面与基于RNN的模型相比,基于自注意力机制的模型为捕捉时间依赖性提供了一种新的效果更好的解决方法。
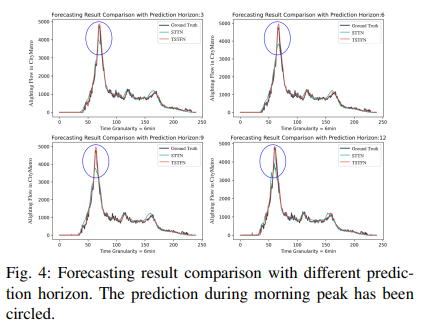
STTN同样是另一个基于Transformer的时空预测模型,使用自注意力层分别学习不同车站不同时间步的依赖性。理论上,自注意力机制可以建模更加普遍的空间依赖性,但同样可能会导致过大的计算费用和过拟合现象。具体来说,两个基于自注意力机制的预测模型STTN和TSTFN在CityMetro数据集下每迭代一次分别需要202s和131s,这意味着文章提出的模型在计算费用方面有更显著的优越性。如果仔细观察客流预测剖面,如图4所示,TSTFN可以更好预测峰值,对日常预测十分关键。
(4) Ablation Studies
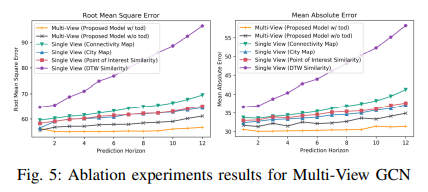
在该章节,作者讨论了多视图空间依赖性捕获和时空融合策略的有效性。如上文提到的,TSTFN考虑了不同类型预定义图结构以增强空间相关性表示的能力。此处,作者仅使用一种类型的图进行消融实验。
图5展示了不同单一视图的预测结果,每个模型仅使用一种特定的图网络信息,而多视图TSFTN则利用所有图信息。根据结构可知,使用多视图结构的情况下预测精度现在提升。单一视图模型的预测效果变化较大,表明图信息是一个重要但棘手的问题。
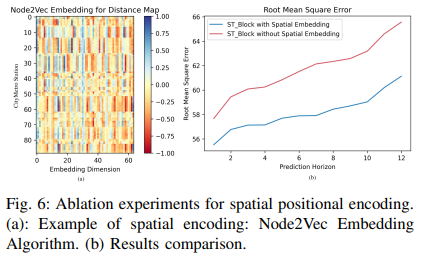
文章还讨论了空间位置编码对预测效果的影响。已知自注意力机制无法区分不同输入元素之间的相对差异因此需要额外的位置编码信息。此处作者主要说明空间位置编码的有效性,可以区分GCN不同视图间的差异。模型中作者采用Node2Vec算法,在不同图结构下可以赋予不同站点不同的空间嵌入值,如图6(a)所示。图6(b)进一步展示了引入空间位置编码与去除空间位置编码的性能比较,验证了空间位置编码的效率。
至于时间位置编码,通过比较TSTFN是否含有time-of-day编码,可以发现由于地铁客流数据存在周期性特征,采用绝对时间信息的时间编码可以提高预测性能,特别是长期预测。
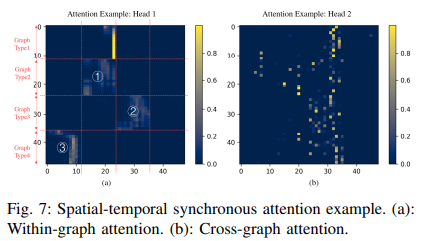
(5) Interpretation of Spatial-Temporal Synchronous Attention
文章进一步研究了自注意力层的学习。由上述可知时空同步自注意力层的输入来自于不同时间步长的客流以及多视图GCN的输出。如图7(a)所示,模型所学习到的注意力表明,来自同一个图结构的输入似乎在同一个图(区块1或2)中有更紧密的关系,或者与来自另一个特定图(区块3)的输入有更紧密的关系,这类图内注意力意味着模型更关注时间相关性建模。另一方面,对于另一个注意力头,如图7(b)所示存在更分散的注意力。不同图的输入存在更紧密的关系,这类跨图注意力意味着它考虑更广泛的依赖性。可解释的注意力可视化图表明,文章提出的时空同步自注意力层可以捕获复杂的相关性,显示了模型的优越性。
6.结论
该文章提出了一种新的基于Transformer的时空混合网络(TSTFN)以实现地铁客流多步预测。研究首先整合了多种类型的预定义图结构,有利于建模多重空间依赖性。文章进一步提出一种时空同步自注意力层整合来自不同时间步和不同图结构的输入,实现了高效的多图信息融合。在两个真实数据集上的实验表明,文章提出的模型能够同时处理长期和短期的预测任务。通过消融实验和注意力可视化可以验证时空同步自我注意层的有效性和解释性。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









