






前言
之前有一点时间对traceRCA比较感兴趣,读了几篇论文,今天突然发现自己的笔记里还有一篇写好笔记。但是没有整理的文章,直接发一下。

查了一下,现在代码已经开源了
code: https://github.com/NetManAIOps/TraceRCA
paper:https://netman.aiops.org/wp-content/uploads/2021/05/1570705191.pdf
一、Introduction
说下其他的缺陷,这个也是大多数算法的情况

强调是更加的practical

说明价值的巨大,这件事的意义所在:微服务巨大的损失,短时间内

二、Related works
分为两种模式
invocation-based:更关注调用异常的相邻微服务更有可能是根本原因
trace-based:更关注于整体的trace链路结构:MicroScope, TraceAnomaly, and MEPFL
三、Concepts
这里主要对trace本身的形成给了一个通俗易懂的解释,但解释的并不全,没有说出span等概念
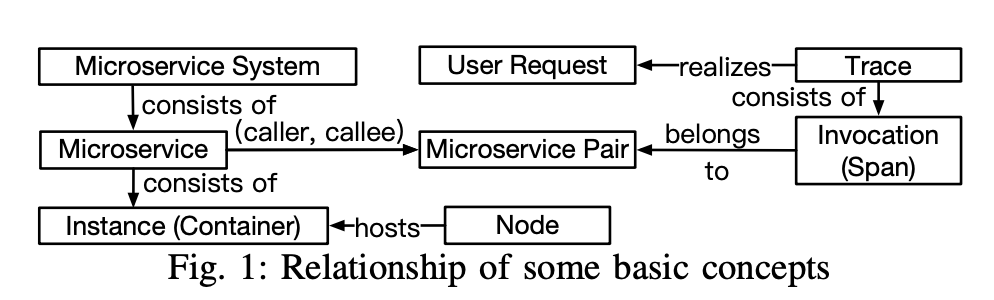
例子理解下:

形成trace,需要在想要监控的链路上进行埋点。
对于span我让chatgpt通俗易懂的解释一下, 其中一道菜可能就是很多个微服务或者一个微服务:
想象一下你在做一道菜,菜单上列出了所有的步骤和所需材料。在这个例子中,整个烹饪过程可以看作是一个追踪,而每一个步骤就是一个span。
每个span都有一个唯一的标识符,就像每个步骤都有一个编号。它还有一个开始时间和结束时间,记录了每个步骤的执行时间。比如,炒菜这个步骤开始的时间是10点,结束的时间是10点15分。
每个span还可以记录一些其他的信息,比如这个步骤的名称、所使用的工具、材料等。比如,炒菜这个步骤可能记录着“炒菜”这个名称,还有使用的锅、油、火等信息。
除了基本信息外,span还可以记录与该步骤相关的事件和标签。事件可以是一些额外的说明,比如在炒菜的过程中发生了一次小小的火灾,可以记录下来。标签可以是一些键值对,用于记录与该步骤相关的特定信息,比如所用的食材、调味料等。
总之,span就是用来描述一个请求或操作的各个步骤的信息,包括开始时间、结束时间、名称、事件和标签等。它们可以帮助我们了解整个操作的执行情况,分析性能问题,找出错误或改进操作过程。
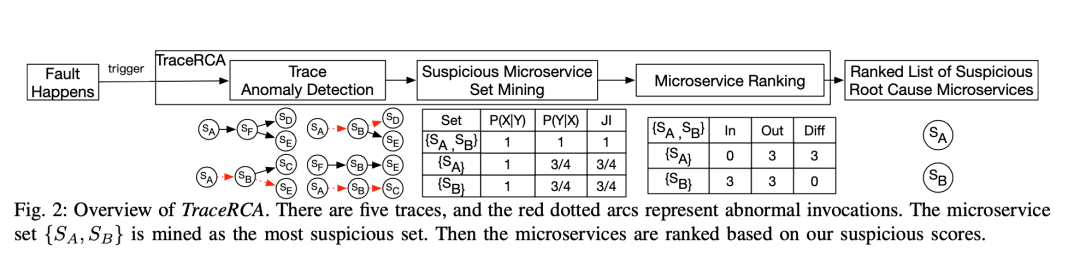
四、Method
包括三个部分
trace anomaly detection
suspicious root-cause microservice set mining
microservice ranking
4.1 trace anomaly detection
Multi-Metric Invocation Anomaly Detection:

taceRCA 检测不正常的trace 通过检测不正常的调用而不是直接检测不正常的trace,trace是不定长的(动态图),需要转换为定长的vector,低效并且不准确 and unsupervised。
特征需要用某种方法进行过滤,不是每个feature都是好用的(存在很多扰动的噪声,错误的user input)
两个步骤:
自适应的选择有用的特征(看一个特征是否有用就看发生error的前后是否分布发生变化->说明有因果关系。)
用选择的特征取检测调用的异常
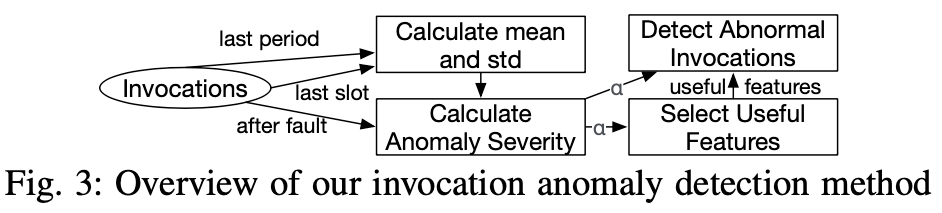
4.1.1 自适应的选择有用的特征
特征的含义,就是调用链上的每个步骤(or 操作/服务),都有自己的指标数据,最常见的就是:延时,错误率,请求量等指标数据

看一个特征是否有用就看发生error的前后是否分布发生变化->说明有因果关系
因为不一样的repair相同的invocation的两端指标可能会差距很大,所以在考虑的时候主要是局部的repair对去考虑。相当于只考虑一个trace的一个局部的pair的,把这个考虑成是一个稳定的分布,对这个稳定的分布做异常检测。稳定分布用mean和标准差去拟合。

为了计算更加robust,引入slot和period
slot就意味着窗口,period就是周期,相当于引入过去的周期的窗口,和紧邻的窗口,因为这种场景下metric的周期性非常明显。
主要这样计算:
slot-> time windows
in the last slot
in the same slot of the last period
每一个invocation都有这些特征,用这些特征分别计算normal情况下的mean和std,之后算anomaly severity,最后算mean,错误发生之后重新计算这些值,错误之前计算这些特征值,做相减(相当于抓错误来临之后的change),大于百分之10,则我们认为这个特征是有用的。
4.1.2 race anomaly inference
每个invocation上,有很多这样构造的feature,如果任何一个feature上是异常的,则这个invocation是异常的。
查看是否存在一个有用的feature出现异常,大于某个threshold,则判定为异常
4.2 Suspicious Root-Cause Microservice Set Mining
找出可能的root cause 微服务集合
这里是microservice sets 而不是 microservice, reason是:

没有挖掘 微服务的序列和subgraph
这里用两个指标来刻画 two key metrics
support: 全部这些abnormal traces中通过全部这些微服务(来自于微服务集合)的trace的比例
confidence: 通过这些微服务的trace中异常的trace的个数
这两个都很高就是root cause microservice, 这两个就是有点类似于 precision和recall。
用核密度估计来画的non root cause和root cause的分布图。
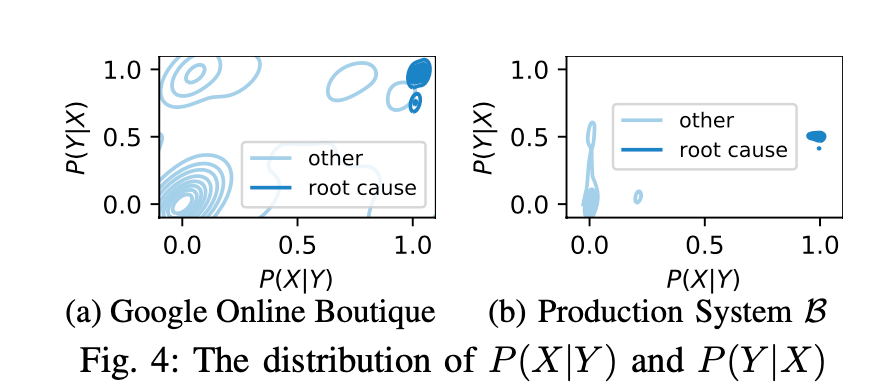
用实验证实了这个定义,两个都高的情况下才更可能是root cause。
这个计算数量太大了,这么算不实际,所以要想办法去缩小范围,之后再计算,这里应用pattern mining algorithm (FP growth)来找出high supports的microservice sets
pattern mining的目标:

图中红色为异常的,{SA,SB,SD,SE}, {SA,SB,SC,SD} and {SA,SB,SC,SE} 其中都有找出SA->SB的调用关系,则这个SA->SB的support=1.0, 把大于0.1的找出来
4.3 Microservice Ranking
通过输入输出的调用关系的分数相减(因果报应)
分数计算:可疑分数是每个可疑集的JI分数和每个可疑集的集内可疑分数的组合。

其中J1:

五、实验部分
用open source的dataset:train-Ticket

注入三种错误
评价指标:

对于:single-root-cause
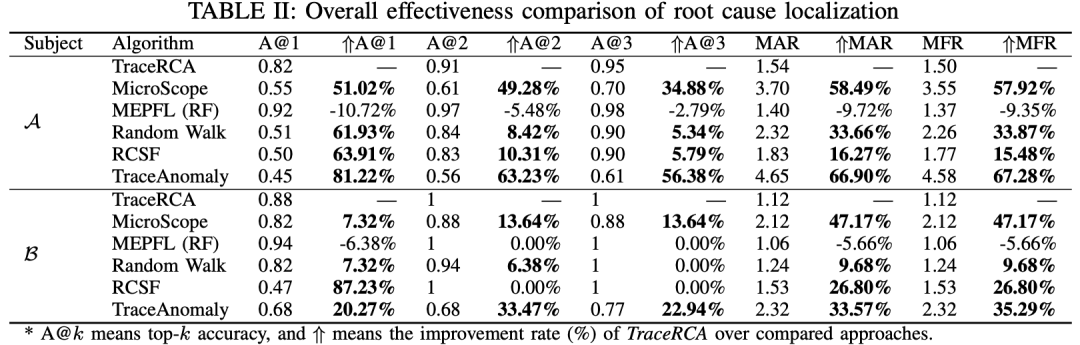
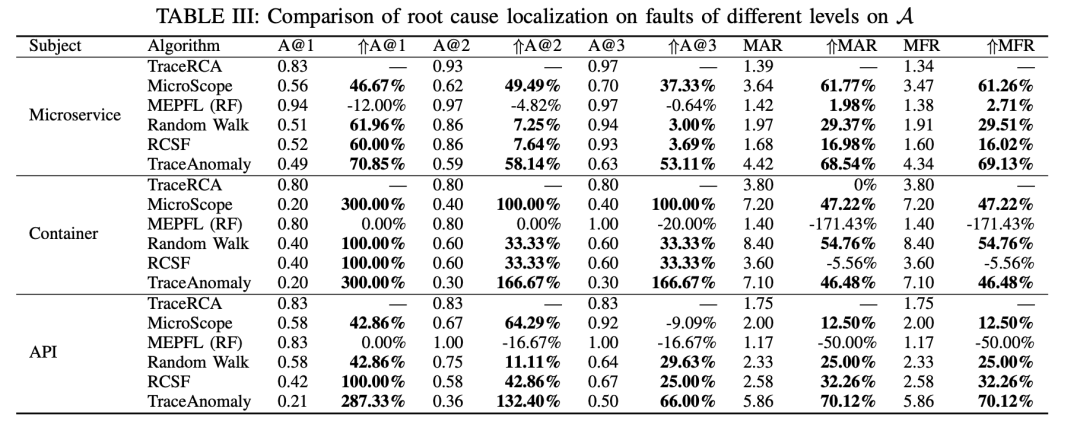
对于:不同level
对于:多root cause

和其他对比异常检测,说明特征选择的重要性:
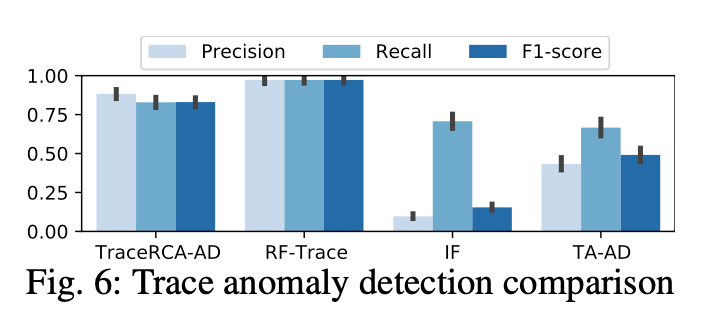
trace(MEPEL) supervised
TraceAnomaly trace-based
IF(isolation forest) invocation-based
做了消融实验

推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









