






前言
COLM 2024 的paper
Instruction Mining: Instruction Data Selection for Tuning Large Language Models

link:https://arxiv.org/pdf/2307.06290
一、摘要
LLM 最初针对广泛的能力进行预训练,然后使用遵循指令的数据集进行微调,以提高其与人类交互的性能。尽管微调方面取得了进步,但选择高质量数据集来优化此过程的标准化指南仍然难以捉摸。
在本文中,提出INSTRUCTMINING方法,旨在自动选择优质指令数据集进行微调LLM。具体来说,IM 利用自然语言指标作为数据质量的衡量标准,将其应用于评估未见过的数据集。
在实验过程中,发现大型语言模型微调中存在双下降现象。基于这一观察,进一步利用 BLENDSEARCH 来帮助找到整个数据集中的最佳子集(即 100,000 个中的 2,532 个)。实验结果表明,在两个最流行的基准测试中实现了最先进的性能。
二、现象和目标
在慢慢增加dataset size的情况下,会出现双重下降的现象(loss损失)
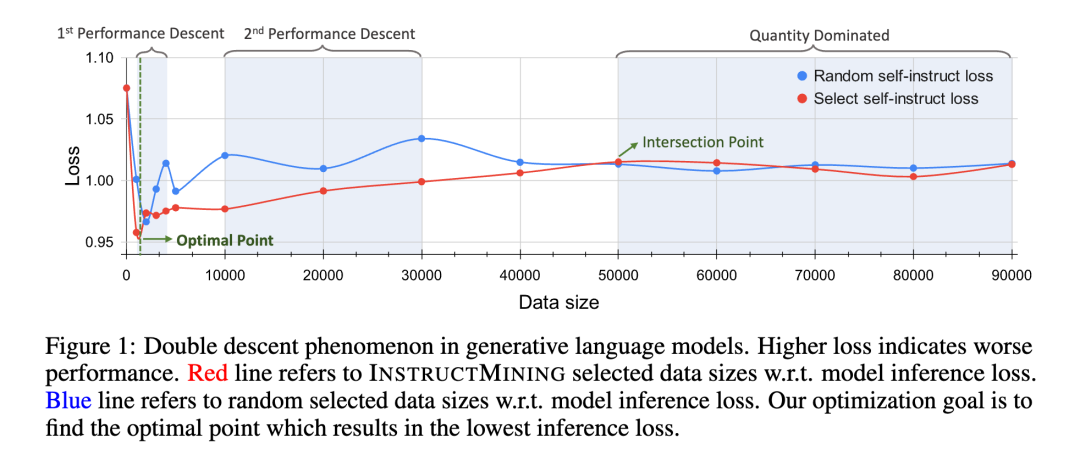
这一观察结果表明,一旦数据大小超过特定阈值,模型性能的主要决定因素就会从数据质量转变为数据数量
文中目标就是找到optimal point,就是找到最佳子集使inference loss最小。
三、方法
两部分: 质量估计、 阈值搜索
3.1 质量估计
3.1.1 instruction quality的定义
依据paper:ess is more for alignment. arXiv preprint arXiv:2305.11206的假设

sft的数据集为D, sft model为M, 用M队Deval进行infer,计算loss,其中Deval为高质量且没有偏差的验证集。
3.1.2 估计instruction quality
因为 sft model需要花的时间太久了,所以 需要用其他的方法去估计,这样会大大的节约时间。
利用一些指标来估计:
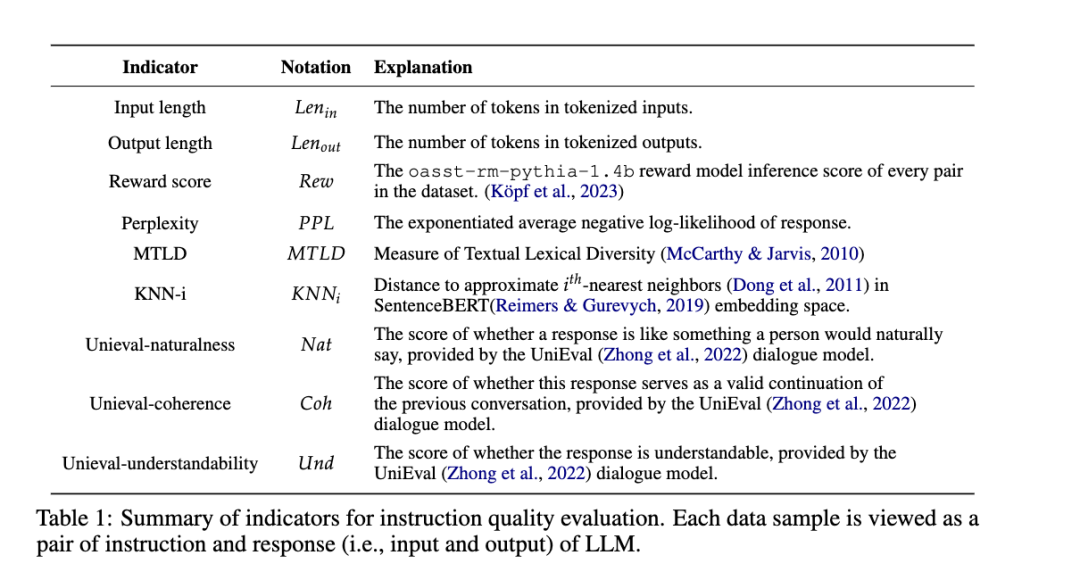
利用这些指标和instruction quality建立联系,之后预估
3.2 阈值搜索
随着数据量的增大,模型性能首先变得更好,然后变得更差。当数据量增长到一定程度后,模型性能再次变得更好。寻找最佳数据大小对于微调更好的语言模型非常重要。
采用BLENDSEARCH算法
BLENDSEARCH:通过贝叶斯优化和不同的局部搜索线程有效地结合了全局和局部优化,使其能够高效地搜索与cost相关的超参数和具有局部最优的复杂搜索空间。
利用对数均匀分布对数据集大小进行随机采样,将数据集大小视为实验cost。搜索目标是最小化评估集上的损失。
四、结果
model: LLAMA-2-7B
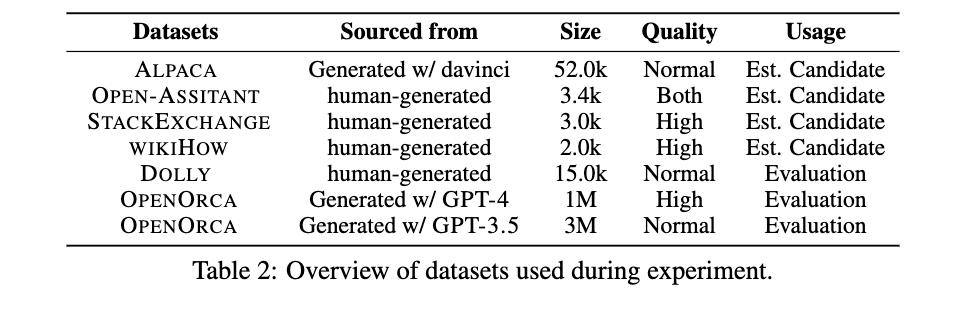
数据集:
4.1 预估loss的参数fit
训练集中抽样129次 subset训练sft model,之后计算每个sft model的loss以及指标,之后通过拟合多变量线性回归找到预估的参数。得到等式:
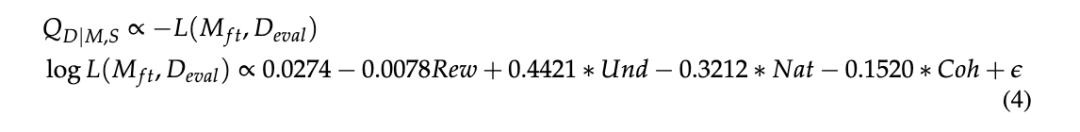
4.2 selection
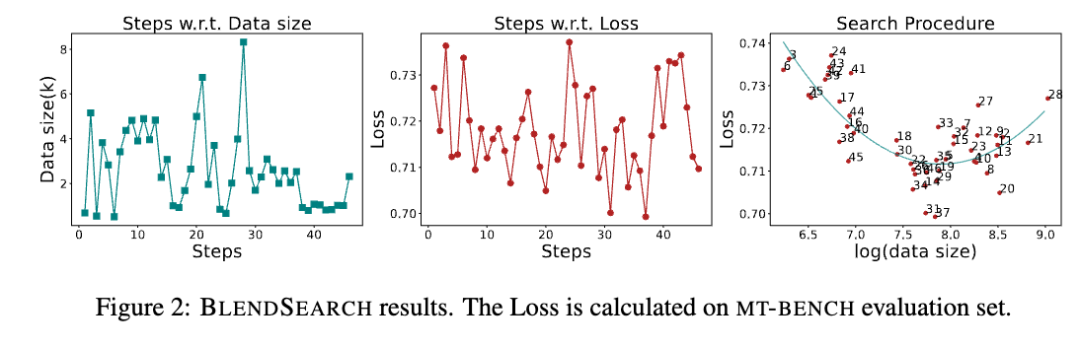
五、总结和分析
本文的策略: 以infer loss最低为目标,根据indicate metirc进行多变量线性回归的拟合预估,通过BLENDSEARCH搜索出最小的subset进行sft
主要的问题: 如果计算infer loss就需要ground truth,这就比较难了,大多数没有ground truth,最多有接近的比较好的答案,如果是严格的QA,A是固定的也比较有说服力,如果偏主观的A的话,那可能不一样的话术都是正确的,则这种loss计算就不太适用了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









