










一、前言
相关网页
https://github.com/Tencent/ncnn/wiki/quantized-int8-inference
https://github.com/BUG1989/caffe-int8-convert-tools
一般都是先prune再量化。
二、下载
其实这篇早就写完了一直没发,手动狗头。
先用git下载代码
git clone https://github.com/BUG1989/caffe-int8-convert-tools.git
三、利用工具进行量化
1.相关资料(特别详细,看了肯定能懂,真心点赞)
https://note.youdao.com/share/?id=829ba6cabfde990e2832b048a4f492b3&type=note#/
这里自己概括一下,方便自己以后看
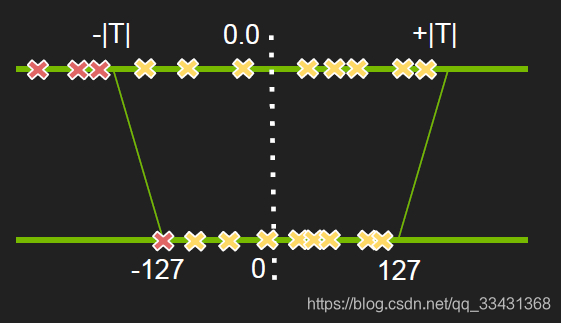
大概总结一下就是上面这个图大概是说上面的float32映射到下面的int中的-127->127
都知道是映射,但是这边有个操作就是左面这些红色的叉点都映射到边界而不直接删掉,选择T值使整个映射的损失和效果最好是最后的优化问题,整个优化转换为一定的数学问题,求出最优解即可为所要的映射的T值。具体请看前人写的博客,真的好,佩服。
2.利用caffe-int8-convert-tools进行量化
①产生.table文件
首先在该文件下创一个test文件夹,如下图所示
文件夹下创建一个images,models

models里为利用caffetools产生的两个新版caffemodel和prototxt
python caffe-int8-convert-tool-dev.py -h
usage: caffe-int8-convert-tool-dev.py [-h] [--proto PROTO] [--model MODEL]
[--mean MEAN MEAN MEAN] [--norm NORM]
[--images IMAGES] [--output OUTPUT]
[--group GROUP] [--gpu GPU]
find the pretrained caffemodel int8 quantize scale value
optional arguments:
-h, --help show this help message and exit
--proto PROTO path to deploy prototxt.
--model MODEL path to pretrained caffemodel
--mean MEAN value of mean
--norm NORM value of normalize(scale value)
--images IMAGES path to calibration images
--output OUTPUT path to output calibration table file
--group GROUP enable the group scale(0:disable,1:enable,default:0)
--gpu GPU use gpu to forward(0:disable,1:enable,default:0)
python caffe-int8-convert-tool-dev.py --proto=test/models/mobilenet_v1.prototxt --model=test/models/mobilenet_v1.caffemodel --mean 103.94 116.78 123.68 --norm=0.017 --images=test/images/ output=mobilenet_v1.table --gpu=1
执行
 过程图
过程图
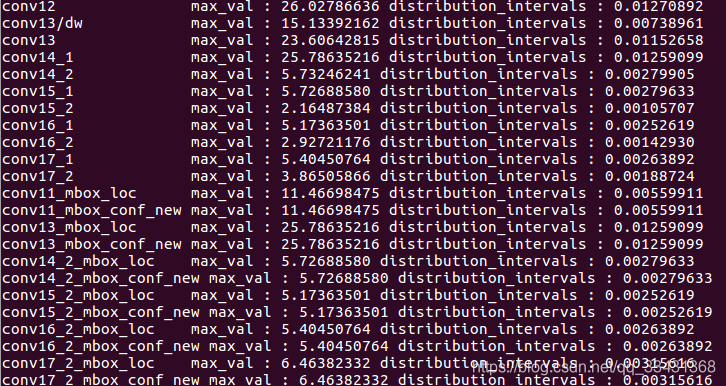 结果如图
结果如图
②利用table文件对ncnnmodel的.bin和网络文件.param进行量化处理

产生两个int文件
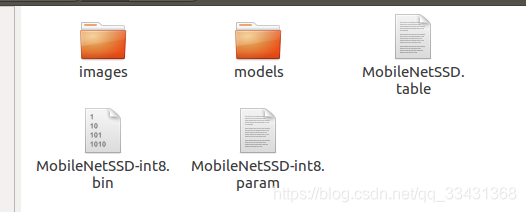
看.bin文件的大小变化
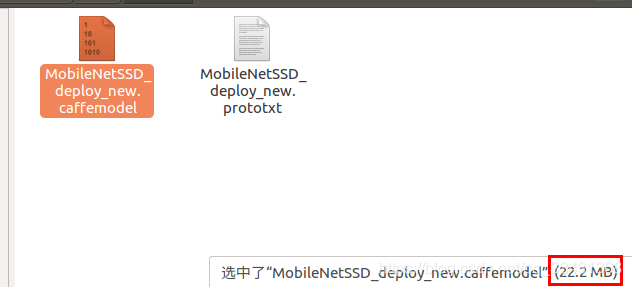
减小成原来的四分之一
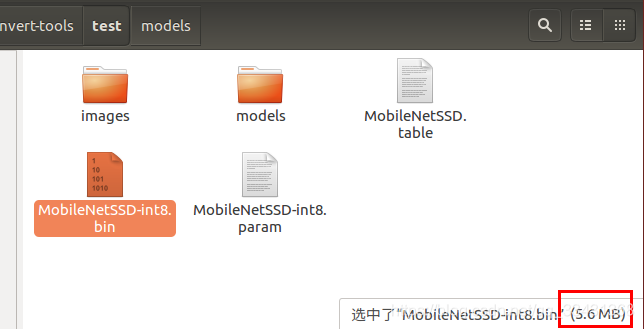
四、效果
客观评价对于MobileNetssd在android手机的速度来说,提升不算很明显,但是有一定提升,精度下降有点多,所以就去请教大神一波。
五、另一种量化
将conv1不量化,即在.table文件中直接把那行删掉
之后进行混合模式量化,256->0

这回产生的.bin基本大小无变化,还是22M
但是移植到android 上有明显速度加成。
我当时的情况差不多 300ms->220ms左右吧,所以想到实时还是需要剪枝请看我下一篇文章
《深度学习笔记》深度学习中模型model的剪枝笔记



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









