









(一)
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431664106267f12e9bef7ee14cf6a8776a479bdec9b9000
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
(二)show and change mysql default character set
1、
Step 3: Modify databases, tables, and columns
Change the character set and collation properties of the databases, tables, and columns to use utf8mb4instead of utf8.
# For each database:
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
# For each table:
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
# For each column:
ALTER TABLE table_name MODIFY column_name VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
# (Don’t blindly copy-paste this! The exact statement depends on the column type, maximum length, and other properties. The above line is just an example for a `VARCHAR` column.) Since utf8mb4 is fully backwards compatible with utf8, no mojibake or other forms of data loss should occur. (But you have a backup, right?)
Step 5: Modify connection, client, and server character sets
In your application code, set the connection character set to utf8mb4. This can be done by simply replacing any variants of SET NAMES utf8 with SET NAMES utf8mb4. If your old SET NAMES statement specified the collation, make sure to change that as well, e.g. SET NAMES utf8 COLLATE utf8_unicode_ci becomes SET NAMES utf8mb4 COLLATE utf8mb4_unicode_ci.
Make sure to set the client and server character set as well. I have the following in my MySQL configuration file (/etc/my.cnf):
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ciYou can easily confirm these settings work correctly:
mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; +--------------------------+--------------------+ | Variable_name | Value | +--------------------------+--------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb4 | | character_set_filesystem | binary | | character_set_results | utf8mb4 | | character_set_server | utf8mb4 | | character_set_system | utf8 | | collation_connection | utf8mb4_unicode_ci | | collation_database | utf8mb4_unicode_ci | | collation_server | utf8mb4_unicode_ci | +--------------------------+--------------------+ 10 rows in set (0.00 sec)
As you can see, all the relevant options are set to utf8mb4, except for character_set_filesystem which should be binary unless you’re on a file system that supports multi-byte UTF-8-encoded characters in file names, and character_set_system which is always utf8 and can’t be overridden.
https://makandracards.com/makandra/2529-show-and-change-mysql-default-character-set

https://stackoverflow.com/questions/3513773/change-mysql-default-character-set-to-utf-8-in-my-cnf
https://mathiasbynens.be/notes/mysql-utf8mb4 (Great)
WAMP uses my.ini(not my.cnf) to save settings.
To set the default to UTF-8, you want to add the following to my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
collation-server = utf8_unicode_ci
init-connect='SET NAMES utf8'
character-set-server = utf8
For making sure your MySQL is UTF-8, run the following queries in your MySQL prompt:
-
First query:
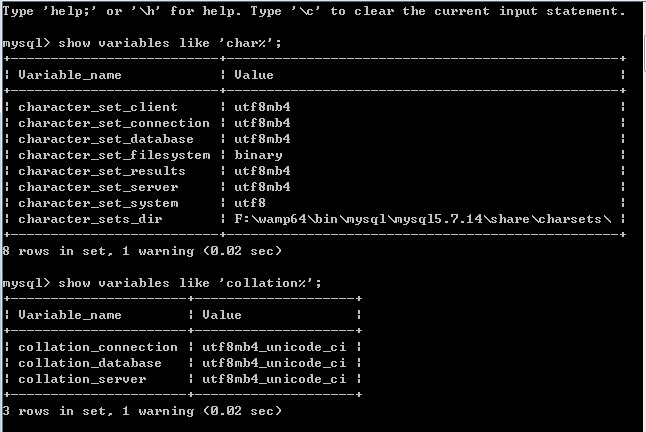
mysql> show variables like 'char%';The output should look like:
+--------------------------+---------------------------------+ | Variable_name | Value | +--------------------------+---------------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/local/mysql/share/charsets/| +--------------------------+---------------------------------+ -
Second query:
mysql> show variables like 'collation%';And the query output is:
+----------------------+-----------------+ | Variable_name | Value | +----------------------+-----------------+ | collation_connection | utf8_general_ci | | collation_database | utf8_unicode_ci | | collation_server | utf8_unicode_ci | +----------------------+-----------------+















 2055
2055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









