







11、线程池
线程池:三大方式、七大参数、四种拒绝策略
池化技术
程序的运行,本质:占用系统的资源!优化资源的使用==> 池化技术
线程池、JDBC 连接池、内存池、对象池等等。
资源的创建、销毁十分消耗资源
池化技术:事先准备好一些资源,如果有人要用,就来我这里拿,用完之后还给我,以此来提高效率。
11.1 线程池的好处:
降低资源的消耗;
提高响应速度;
方便管理;
线程复用、可以控制最大并发数、管理线程;
阿里代码规范,不推荐Executors创建线程,推荐ThreadPoolExecutor

oom:out of memory 内存溢出
ThreadPoolExecutor执行线程
submit和execute
ThreadPoolExecutor执行任务有submit和execute两种方法,这两种方法区别在于
submit方法有返回值,便于异常处理
execute方法没有返回值
@Test
public void Demo02(){
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,
5,
3,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(4),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
try {
for (int i = 0; i < 1; i++) {
//execute方式开启线程
threadPoolExecutor.execute(()->{
System.out.println(Thread.currentThread().getName()+" ok");
});
//submit方式开启线程
Future<?> runnableSubmit = threadPoolExecutor.submit(new RunnableDemo());
System.out.println(runnableSubmit.get());//null
//获取实现Callable接口的线程的返回值
Future<?> CallableSubmit = threadPoolExecutor.submit(new CallableDemo());
System.out.println(CallableSubmit.get());//pool-1-thread-1CallableDemo线程执行
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}
}
class RunnableDemo implements Runnable{
@Override
public void run() {
//pool-1-thread-1RunableDemo线程执行
System.out.println(Thread.currentThread().getName()+"RunableDemo线程执行");
}
}
class CallableDemo implements Callable<String>{
@Override
public String call() throws Exception {
return Thread.currentThread().getName()+"CallableDemo线程执行";
}
}11.2 线程池:三大方法
ExecutorService threadPool = Executors.newSingleThreadExecutor();//创建单个线程
ExecutorService threadPool2 = Executors.newFixedThreadPool(5); //创建一个固定的线程池的大小
ExecutorService threadPool3 = Executors.newCachedThreadPool(); //创建可伸缩的
public class Demo01 {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();//只能创建一个线程
ExecutorService threadPool2 = Executors.newFixedThreadPool(5);//最多可以创建5个线程
ExecutorService threadPool3 = Executors.newCachedThreadPool();//执行100次开启线程,可以创建70多个线程
// 线程池用完必须要关闭线程池
try {
for (int i = 0; i < 100; i++) {
// 通过线程池创建线程
threadPool3.execute(()->{
System.out.println(Thread.currentThread().getName()+"ok");
});
}
} catch (Exception e) {
e.printStackTrace();
}finally {
//关闭线程池
threadPool3.shutdown();
}
}
}Executors是Executor框架的工具类,提供了几种线程池创建方法,以及线程池中默认配置(如线程工厂)的处理,接下来对其中常用的几种创建线程池的方式进行说明。
newSingleThreadExecutor创建单个线程
** **SingleThreadExecutor使用Executors.newSingleThreadExecutor()创建,查看源码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}其中:
corePoolSize和maximumPoolSize都是1
LinkedBlockingQueue是一个最大值为Integer.MAX_VALUE的无界队列
当线程正在执行任务,新任务会被加入到LinkedBlockingQueue队列中,任务加入队列的速度远大于核心线程处理的能力时,无界队列会一直增大到最大值,可能导致OOM
因此newSingleThreadExecutor可用于处理任务量不多,但又不想频繁的创建、销毁需要与虚拟机同周期的场景。
newFixedThreadPool创建一个固定的线程池的大小**
FixedThreadPool使用Executors.newFixedThreadPool() 创建,查看源码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}其中:
corePoolSize和maximumPoolSize值均为nTreads(由入参确定)核心线程和最大线程一致
存活时间为0L,超过核心线程数的空闲线程会被立即销毁
队列依然为LinkedBlockingQueue,当线程数达到corePoolSize时,新任务会一直在无界队列中等待
线程池中的线程数不会超过corePoolSize,新建任务也会一直被加入到队列等待,不会执行拒绝策略
ThreadPoolExecutor中的7个参数,maximumPoolSize,keepAliveTime,RejectedExecutionHandler为无效参数
FixedThreadPool同SingleThreadExecutor,如果nThreads的值设置过小,在任务量过多的场景下,会有可能由于线程数过少,导致任务一直堆积在队列中而引发OOM,相对好处是可以多线程处理,一定程度提高处理效率。
newCachedThreadPool
CachedThreadPool使用Executors.newCachedThreadPool()创建,查看源码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}其中:
corePoolSize为0,maximumPoolSize为Integer.MAX_VALUE,即maximumPool是无界的。最大线程池是2的21次方
keepAliveTime为60L,空闲线程等待新任务的最长时间为60秒,超过60秒后将会被终止
SynchronousQueue为线程池的工作队列,没有容量,不能存放任务
CachedThreadPool中,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,会不断创建新线程,最终导致创建过多线程而耗尽CPU和内存资源。忽略CPU和内存消耗,某种程度上CachedThreadPool可以快速解决短时间并发问题,由于核心线程数为0,并且设置了存活时间,这些临时开辟的线程会在任务处理后被回收掉。
Executors是为了屏蔽线程池过多的参数设置影响易用性而提供的,而实际上这些参数恰恰也不需要进行逐个设置,Executors也是源码中推荐的一种使用方式,但是需要熟知他们各自的特点。
11.3 线程池:七大参数
指的是创建ThreadPoolExecutor线程池的七种参数
ExecutorService threadPool = Executors.newSingleThreadExecutor();//单个线程
ExecutorService threadPool2 = Executors.newFixedThreadPool(5);//创建一个固定的线程池的大小
ExecutorService threadPool3 = Executors.newCachedThreadPool();//可伸缩的
//这三种创建线程的方法底层都是使用ThreadPoolExecutor来创建线程,只不过调用的参数不同
//Executors.newFixedThreadPool(5); 源码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//ThreadPoolExecutor创建线程池源码
public ThreadPoolExecutor(int corePoolSize, //核心线程池大小
int maximumPoolSize, //最大的线程池大小
long keepAliveTime, //超时了没有人调用就会释放
TimeUnit unit, //超时单位
BlockingQueue<Runnable> workQueue, //阻塞队列
ThreadFactory threadFactory, //线程工厂 创建线程的 一般不用动
RejectedExecutionHandler handler //拒绝策略
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}代码图解
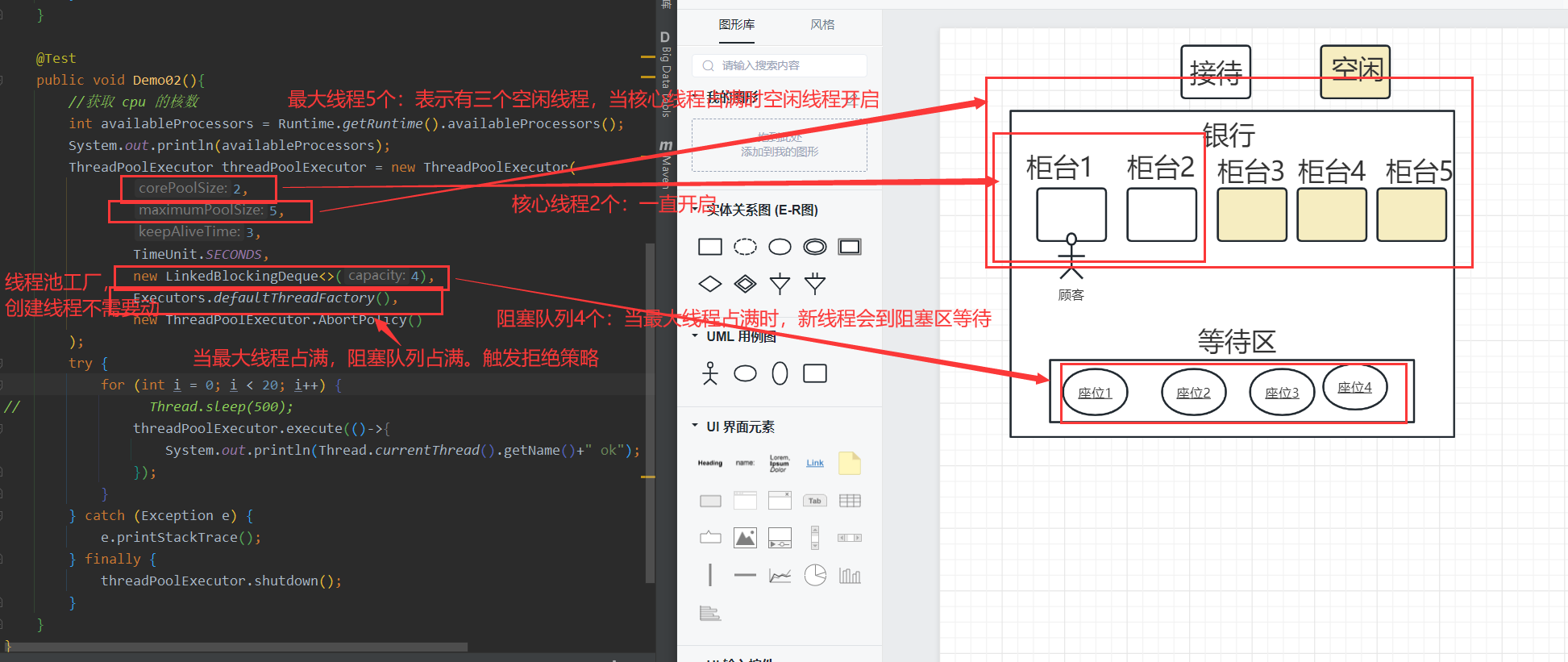
注意:最大线程(maxmumPoolSize)一定要比核心线程(corePoolSize)要大或相等,不然创建线程池会报错。
@Test
public void Demo02(){
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,//核心线程
5,//最大线程
3,//等待时间
TimeUnit.SECONDS,//等待时间单位
new LinkedBlockingDeque<>(4),//阻塞队列
Executors.defaultThreadFactory(),//线程池工厂
new ThreadPoolExecutor.AbortPolicy()//拒绝策略
);
try {
for (int i = 0; i < 20; i++) {
// Thread.sleep(500);
threadPoolExecutor.execute(()->{
System.out.println(Thread.currentThread().getName()+" ok");
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPoolExecutor.shutdown();
}
}同时创建2个线程:线程数量小于核心线程2,只会使用核心线程
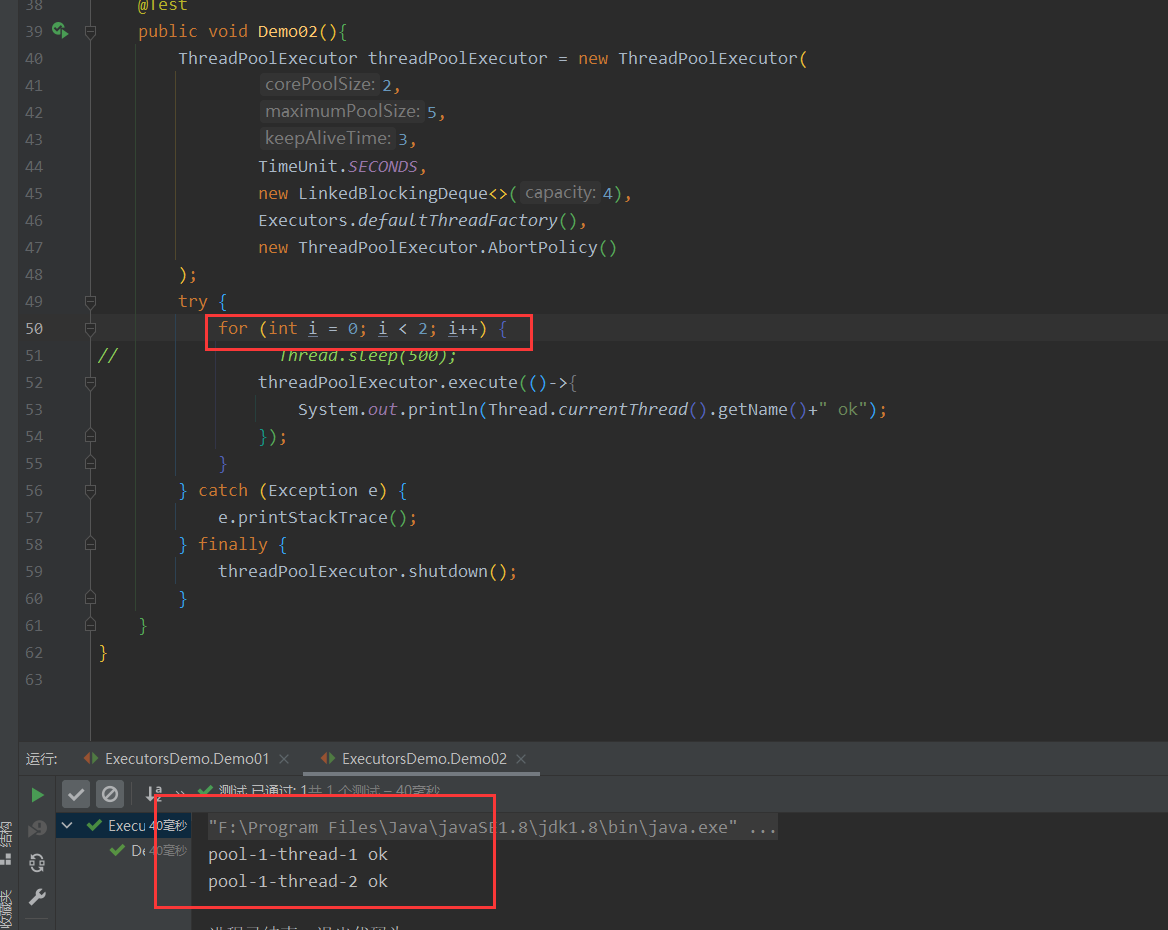
同时创建12个线程:线程创建速度大于核心线程销毁速度,调用3-5空闲线程
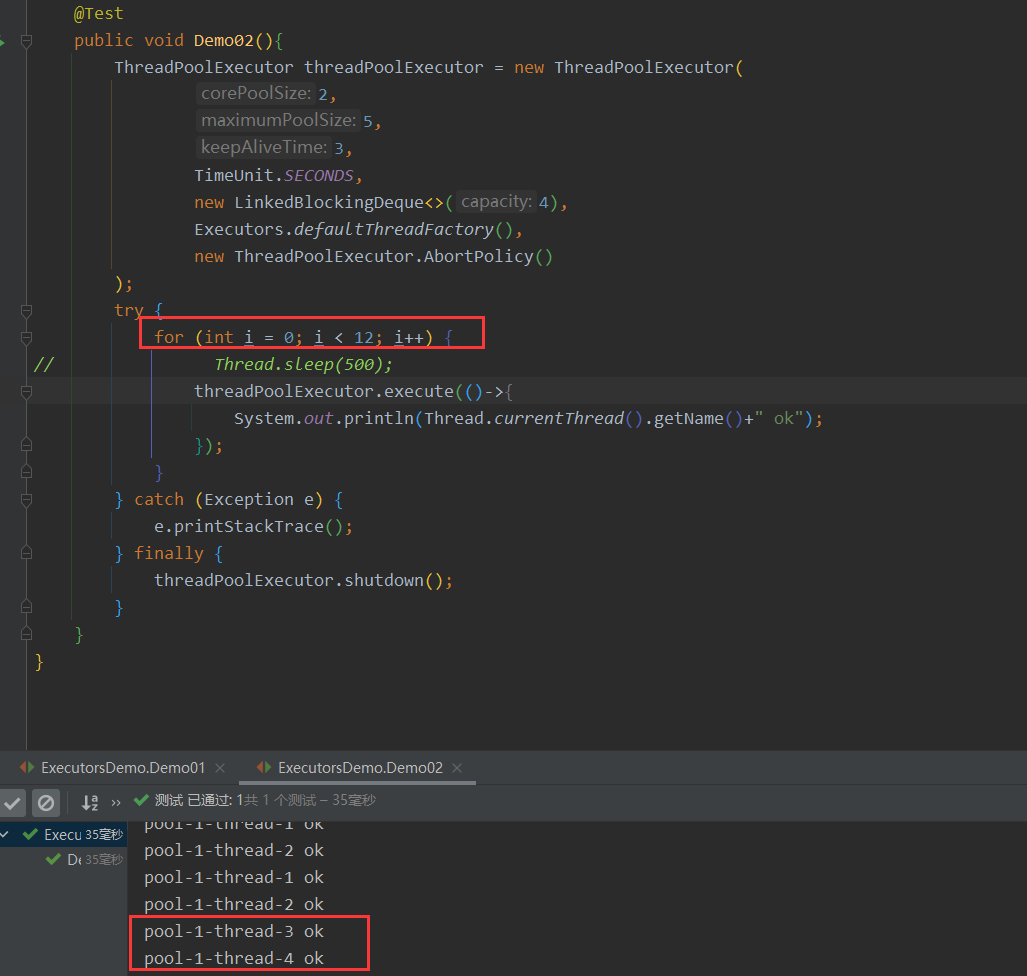
同时创建22个线程:线程创建速度大于cup处理速度并且阻塞队列填满后,调用拒绝策略
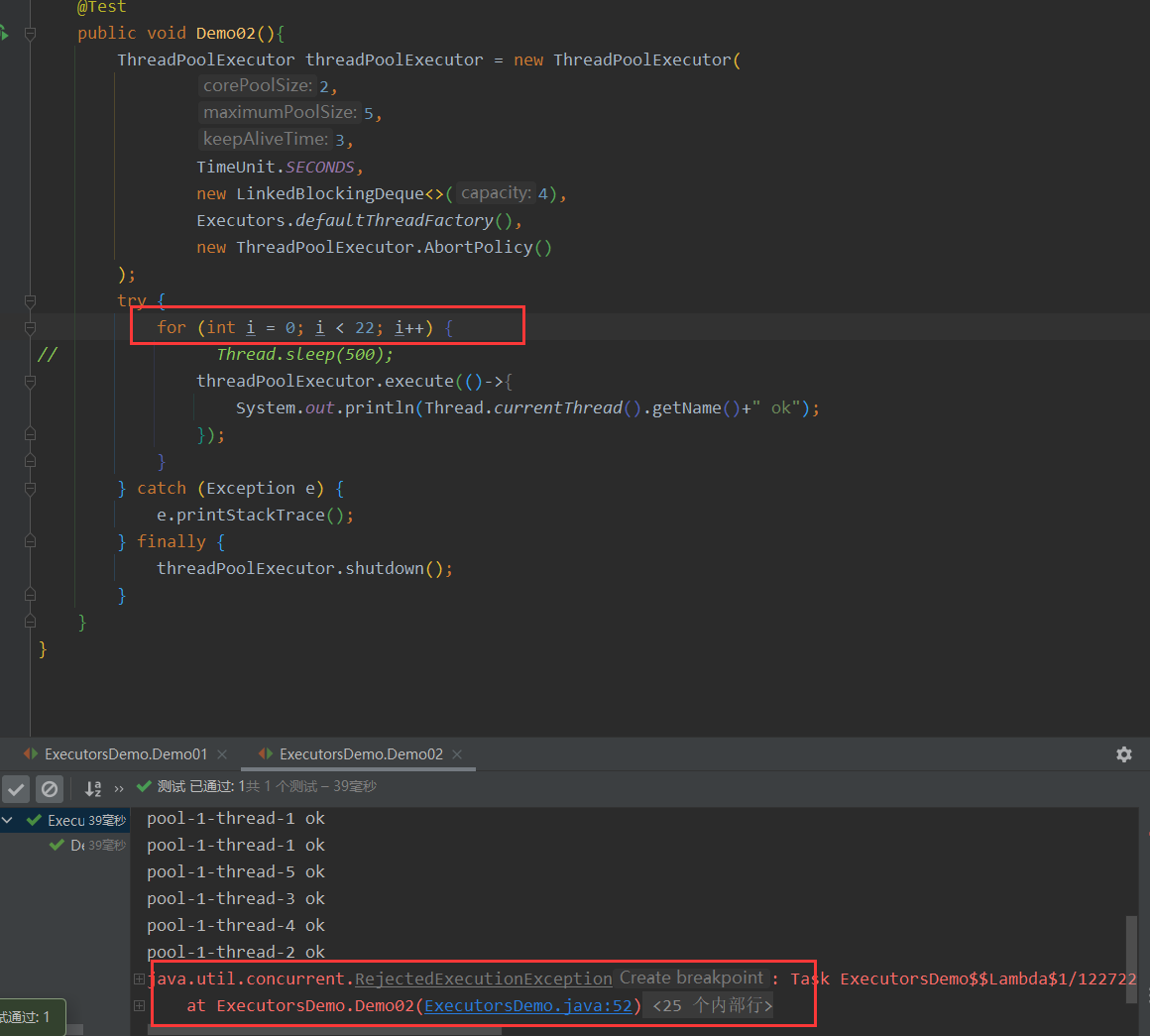
11.4 线程池:4大拒绝策略
new ThreadPoolExecutor.AbortPolicy: // 该 拒绝策略为:银行满了,还有人进来,不处理这个人的,并抛出异常(默认)
new ThreadPoolExecutor.CallerRunsPolicy(): // //该拒绝策略为:哪来的去哪里 main线程进行处理
new ThreadPoolExecutor.DiscardPolicy(): //该拒绝策略为:队列满了无法执行的任务被简单地丢弃,不做任何处理。
new ThreadPoolExecutor.DiscardOldestPolicy(): //该拒绝策略为:队列满了,是把队列最靠前的任务丢弃,重新尝试执行当前任务
11.5 如何设置线程池的大小
CPU 密集型:
电脑的核数是几核就选几;选择maximunPoolSize 的大小(N+1)
// 获取cpu 的核数
int max = Runtime.getRuntime().availableProcessors();
ExecutorService service =new ThreadPoolExecutor(
2,
max,
3,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);I/O密集型:
假如在程序中有15个大型任务,io十分占用资源;I/O 密集型就是判断我们程序中十分耗 I/O 的线程数量,大约是最大 I/O 数的一倍到两倍之间。(2N+1)
12、四大函数式接口(必须掌握)
新时代程序员:lambda 表达式、链式编程、函数式接口、Stream 流式计算
函数式接口:只有一个方法的接口(典型Runnable接口)
//Runnable源码
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
//@FunctionalInterface函数式接口四大原生的函数式接口
Consumer有输入无返回 foreach
Funtion有输入有返回
Predicate无输入有返回
Supplier有输入返回true/false
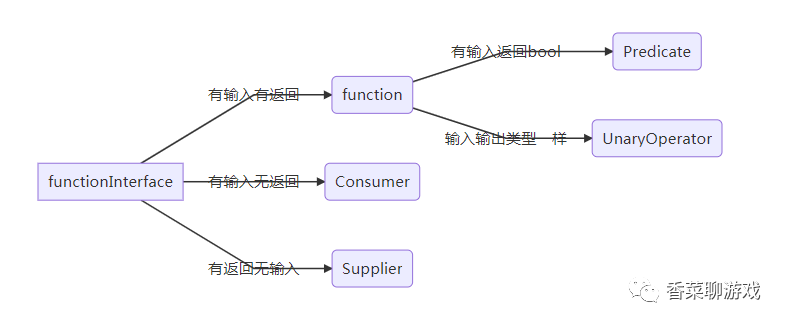
12.1Funtion函数式接口
特点:传入一个obj,返回一个obj
抽象方法:apply()
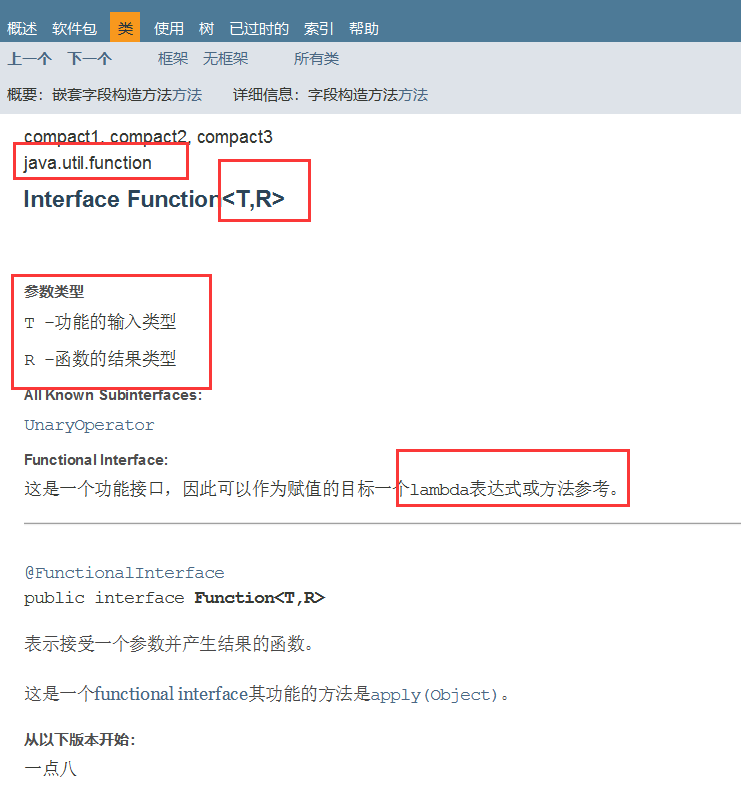
底层源码
//底层源码
package java.util.function;
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
...
}实际操作
@Test
public void demo02(){
//匿名内部类,重写apply方法
Function function = new Function() {
@Override
public Object apply(Object o) {
return o;
}
};
//lambda表达式1
Function function2=(str)->{return str;};
//lambda表达式2
Function function3=str->{return str;};
//lambda表达式3
Function function4=str->str;
System.out.println(function.apply("1"));//1
System.out.println(function2.apply("2"));//2
System.out.println(function3.apply("3"));//3
System.out.println(function4.apply("4"));//4
}12.2 Predicate 断言型接口
特点:传入一个参数T,返回值只能是boolean
一个任意类型的入参,根据我们写的逻辑,然后进行一个判断返回true或者false的抽象吗?
//底层源码
package java.util.function;
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
}代码操作
@Test
public void demo03() {
//匿名内部类,重写test方法
Predicate predicate = new Predicate<Integer>() {
@Override
public boolean test(Integer num) {
return num > 0;
}
};
//lambda表达式1
Predicate<Integer> predicate2=(num)->{return num>0;};
//lambda表达式2
Predicate<Integer> predicate3=num->{return num>0;};
//lambda表达式3
Predicate<Integer> predicate4=num->num>0;
System.out.println(predicate.test(-1));//false
System.out.println(predicate.test(0));//false
System.out.println(predicate.test(1));//true
System.out.println(predicate.test(2));//true
}12.3 Supplier生产者类型接口
生产者的抽象逻辑就是:什么都不用入参,返给外界一个生产出来的对象
特点:没有传入参数,只有返回值。可返回传入的任何类型
//底层源码
package java.util.function;
@FunctionalInterface
public interface Supplier<T> {
T get();
}代码操作
//定义一个方法,用于获取int类型数组中元素的最大值,方法的参数传递Supplier接口,泛型使用Integer
public static int getMax(Supplier<Integer> sup){
return sup.get();
}
@Test
public void demo04() {
//匿名内部类,重写get方法
Supplier supplier=new Supplier() {
@Override
public Object get() {
return "supplier";
}
};
Supplier supplier2=()->{return "supplier";};
Supplier supplier3=()->Math.random()*10;
Supplier supplier4=()->"supplier";
Supplier<Exception> supplier5 = () -> new NullPointerException();
Supplier<User> supplier6=()->new User();
System.out.println(supplier.get());//supplier
System.out.println(supplier2.get());//supplier
System.out.println(supplier3.get());//6.863732353697851
System.out.println(supplier4.get());//supplier
System.out.println(supplier5);//functionInterface$$Lambda$3/971848845@123772c4
System.out.println(supplier6.get().getName());//获取User对象中的名字
//定义一个int类型的数组并赋值
int arr[] = {100,23,456,-23,-90,0,-678,14};
//调用getMax方法,方法的参数Supplier是一个函数式接口,所以可以传递Lambda表达式
int maxValue = getMax(() -> {
//获取数组的最大值,并返回
//定义一个变量,把数组中的的第一个元素赋值给该变量,记录数组中元素的最大值
int max = arr[0];
//遍历数组,获取数组中的其他元素
for (int i : arr) {
if (i > max) {
max = i;
}
}
//返回最大值
return max;
});
System.out.println("数组中元素的最大值:"+maxValue);//数组中元素的最大值:456
}12.4 Consummer 消费者类型接口
为消费者类型的接口。
底层源码
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}代码实现
@Test
public void demo05() {
Consumer consumer = new Consumer() {
@Override
public void accept(Object o) {
System.out.println(o);
}
};
Consumer consumer2 = (s)->{System.out.println(s);};
Consumer consumer3 = s->{System.out.println(s);};
Consumer<Integer> consumer4 = s->System.out.println(s+1);
consumer.accept("1111");//1111
consumer2.accept("2222");//2222
consumer3.accept("3333");//3333
consumer4.accept(4444);//4445
}列如foreach底层也是使用Consummer函数式接口
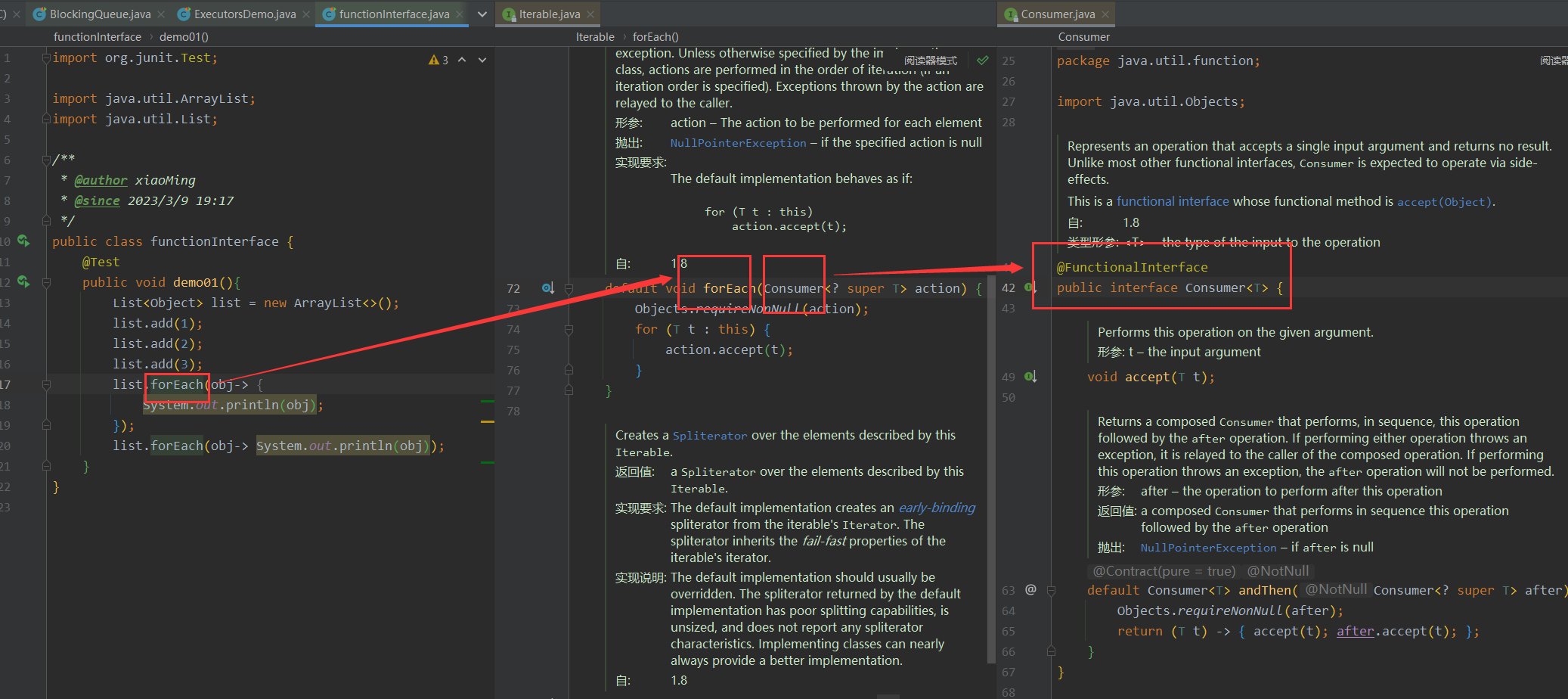
lambda 表达式写法
public class functionInterface {
@Test
public void demo01(){
List<Object> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.forEach(obj-> {
System.out.print(obj);//123
});
list.forEach(obj-> System.out.print(obj));//123
//jdk1.8新写法
list.forEach(System.out::print);//123
}
}12.5、四大函数总结
JDK8之所以要提供这四大函数式接口,主要是对于程序中存在的四种逻辑的抽象:
Predicate判断逻辑【比如if else场景】
Function映射逻辑【比如我们写的各个方法】
Consumer消费型逻辑【比如System.out.println这种对于元素的空返回值消费操作】
Suppiler生产型逻辑【比如new对象】
函数式接口 | 抽象方法 | 对应程序逻辑的抽象 | 具体场景 |
Function<T, R> | R apply(T t); | 程序中映射逻辑的抽象 | 比如我们写得很多的函数:接收入参,返回出参,方法代码块就是一个映射的具体逻辑。 |
Predicate | boolean test(T t); | 程序中判断逻辑的抽象 | 比如各种if判断,对于一个参数进行各种具体逻辑的判定,最后返回一个if else能使用的布尔值 |
Consumer | void accept(T t); | 程序中的消费型逻辑的抽象 | 就比如Collection体系的ForEach方法,将每一个元素取出,交给Consumer指定的消费逻辑进行消费 |
Supplier | T get(); | 程序中的生产逻辑的抽象 | 就比如最常用的,new对象,这就是一个很经典的生产者逻辑,至于new什么,怎么new,这就是Suppiler中具体逻辑的写法了 |
12.6、函数式接口的扩展
甚至通过名字都能看出来,像是LongSuppiler,DoubleConsumer,这不就是泛型参数被具体化
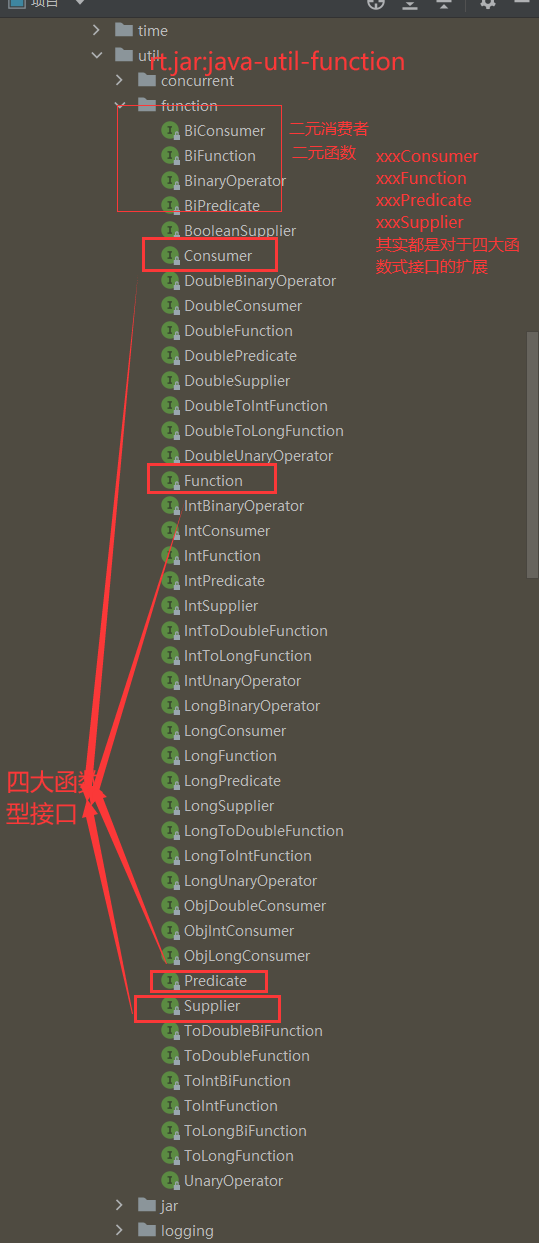
1.BiXXX
其实就是Binary的缩写,Bi翻译过来就是【二元】的意思。
不外乎就是两个泛型入参,但是消费型逻辑是完全没变化的。
//原型
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
//Bi拓展
@FunctionalInterface
public interface BiFunction<T, U, R> {
R apply(T t, U u);
}代码对比
@Test
public void demo06() {
//传入一个obj 返回一个obj
Function function=str->1;
System.out.println(function.apply("hello"));//1
//传入两个obj 返回一个obj
BiFunction biFunction=(a,b)->{
StringBuilder builder = new StringBuilder();
builder.append(a);
builder.append(b);
return builder.toString();
};
BiFunction biFunction2=(str1,str2)->str1.equals(str2)?true:false;
System.out.println(biFunction.apply("he", "llo"));//hello
System.out.println(biFunction2.apply("1", "2"));//false
}2.xxxFunction
有返回有输入
//IntFunction源码
@FunctionalInterface
public interface IntFunction<R> {
R apply(int value);
}
//intFunction测试
IntFunction intFunction=num-> ++num;
//apply()只能传入int类型
System.out.println(intFunction.apply(1));//2
//IntToDoubleFunction源码
@FunctionalInterface
public interface IntToDoubleFunction {
double applyAsDouble(int value);
}
//IntToDoubleFunction测试
IntToDoubleFunction intToDoubleFunction=num -> num+1;
//apply()只能传入int类型,只能返回double类型
System.out.println(intToDoubleFunction.applyAsDouble(1));//2.03.xxxConsumer
有输入无返回
//IntConsumer源码
@FunctionalInterface
public interface IntConsumer {
void accept(int value);
}
//IntConsumer测试
IntConsumer intConsumer=str-> System.out.println(++str);//++str输出4 str++=>输出3
//只能输入int类型
intConsumer.accept(3);4.xxxPredicate
有输入返回boolean
@FunctionalInterface
public interface IntPredicate {
boolean test(int value);
}
IntPredicate intPredicate=str->str>0;
//只能输入int类型
System.out.println(intPredicate.test(-2));//false5.xxxSupplier
无输入有返回
@FunctionalInterface
public interface IntSupplier {
int getAsInt();
}
IntSupplier intSupplier =()->new Random().nextInt(10);
//返回值必须为int
System.out.println(intSupplier.getAsInt());//66.XXXOperator
都是在泛型参数统一化上面做的扩展,出参和入参必须一致
@FunctionalInterface
public interface IntBinaryOperator {
int applyAsInt(int left, int right);
}JDK新特性之:接口默认方法
接口类中使用default关键字修饰抽象方法,则会自动有一个空实现。实现该接口类时,使用default修饰的方法可以不用重写,也不会报错
@Test
public void demo07(){
//方式一:使用匿名内部类,这里没法用Lambda,因为接口有多个抽象。
A a=new A() {
@Override
public void show1() {
System.out.println("调用show1方法");
}
@Override
public void show2() {
System.out.println("调用show2方法");
}
@Override
public void show3() {
System.out.println("调用show3方法");
}
//必须要重写全部抽象方法不然会报错,很麻烦。
@Override
public void show4() {
}
};
a.show1();//调用show1方法
//方式二:创建适配器类的匿名内部类,并且重写该类的show1即可
MyAdapter myAdapter = new MyAdapter(){
@Override
public void show1() {
System.out.println("调用show1方法");
}
};
myAdapter.show1();//调用show1方法
//方式三:在接口类的方法声明最前面加一个关键字:default 来让Java编译器知道这是一个接口的默认方法
B b=()-> System.out.println("调用show1方法");
//留一个抽象方法show1。这样,外部还可以用Lambda表达式来简化只需要实现show1的匿名内部类
b.show1();//调用show1方法
//加上default关键字之后,该方法已经有了默认实现了,所以lambda表达式没有生效
b.show2();
}
}
interface A{
void show1();
void show2();
void show3();
void show4();
}
interface B{
void show1();
default void show2(){};
default void show3(){};
default void show4(){};
}
//给这个接口创建一个适配器类【AdapterClass】里面写好每一个方法的空实现。
//我们以后再去创建A接口对象的时候,我们就可以重写我们指定的那个方法了
class MyAdapter implements A{
@Override
public void show1() {
}
@Override
public void show2() {
}
@Override
public void show3() {
}
@Override
public void show4() {
}
}13、Stream流式计算
什么是Stream流计算
简介:
Stream用于进行计算,是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
Stream并不会存储数据。
Stream并不会改变数据源,它会返回一个含有结果集的Stream。
Stream是延迟加载的,在需要结果时才执行。
代码解析
public class StreamDemo {
/**
* 题目要求:一分钟内完成此题,只能用一行代码实现!现在有个用户!
* 筛选:1、ID必须是偶数
* 2、年龄必须大于21岁
* 3、用户名转为大写字母
* 4、用户名字母倒着排序
* 5、只输出一个用户!
*/
@Test
public void demo01(){
User user1 = new User(1, "a", 21);
User user2 = new User(2, "b", 22);
User user3 = new User(3, "c", 23);
User user4 = new User(4, "d", 24);
User user5 = new User(5, "e", 25);
List<User> list = Arrays.asList(user1, user2, user3, user4, user5);
// lambda、链式编程、函数式接口、流式计算
list.stream()
//ID必须是偶数
.filter(user -> {return user.getId()%2 == 0;})//User(id=2, name=b, age=22) User(id=4, name=d, age=24)
//年龄必须大于21岁
.filter(user -> {return user.getAge()>21;})//User(id=2, name=b, age=22) User(id=4, name=d, age=24)
//用户名转为大写字母
.map(user -> {user.setName(user.getName().toUpperCase());return user;})//User(id=2, name=B, age=22) User(id=4, name=D, age=24)
//用户名字母倒着排序
.sorted((uu1,uu2)->{return uu2.getName().compareTo(uu1.getName());})//User(id=4, name=D, age=24) User(id=2, name=B, age=22)
//只输出一个用户!
.limit(1)//User(id=4, name=D, age=24)
.forEach(System.out::println);
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class User{
private int id;
private String name;
private int age;
}14、ForkJoin
什么是ForkJoin
ForkJoin 在JDK1.7,并行执行任务!提高效率~。在大数据量速率会更快!
大数据中:MapReduce 核心思想->把大任务拆分为小任务!
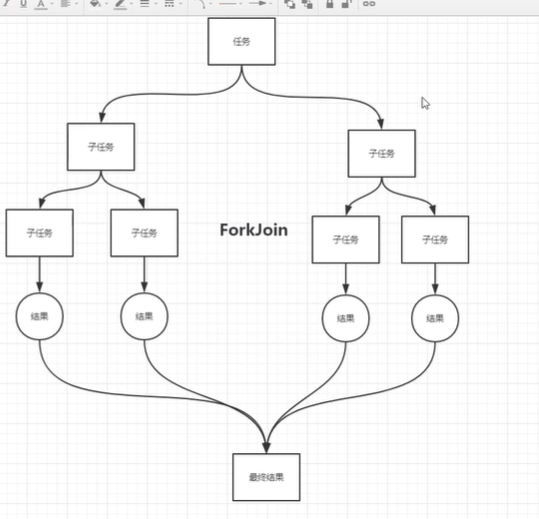
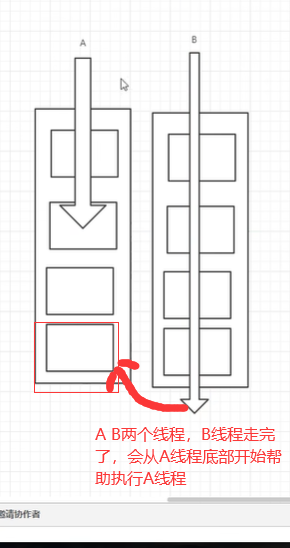
14.1、ForkJoin特点:工作窃取
实现原理:双端队列!从上面和下面都可以去拿到任务进行执行!
14.2、如何使用ForkJoin?
通过 ForkJoinPool 来执行
计算任务 execute(ForkJoinTask<?> task)
计算类要去继承 ForkJoinTask;
ForkJoin 的计算类
public class ForkJoinTest{
private static final long SUM = 20_0000_0000;
public static void main(String[] args) throws ExecutionException, InterruptedException {
test1();//时间:912
test3();//时间:835
}
/*
* 使用普通方法
*
* */
public static void test1(){
long star = System.currentTimeMillis();
long sum = 0L;
for (int i = 0; i < SUM; i++) {
sum+=i;
}
long end = System.currentTimeMillis();
System.out.println(sum);
System.out.println("时间:" + (end-star));
System.out.println("---------------");
}
/*
* 使用流计算
* */
public static void test3(){
long star = System.currentTimeMillis();
long sum = LongStream.range(0L,20_0000_0000L).parallel().reduce(0,Long::sum);
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("时间:" + (end - star));
System.out.println("-------------");
}
}.parallel().reduce(0, Long::sum)使用一个并行流去计算整个计算,提高效率。
15、 异步回调
多线程情况下,我们不知道线程什么时候执行完毕,或者不知道如何处理子线程的结果?
Future 设计的初衷:对将来的某个事件结果进行建模!
15.1、CompletableFuture
资料:https://blog.csdn.net/u012060033/article/details/124469978
CompletableFuture在创建时,如果传入线程池,那么会去指定的线程池工作。如果没传入,那么回去默认的ForkJoinPool
ForkJoinPool的优势在于,可以充分利用多cpu,多核cpu的优势,把一个任务拆分成多个小任务,把多个小任务放到多个处理器核心上并行执行;当多个小任务执行完成之后,再将这些执行结果合并起来即可。
15.2、CompletableFuture创建方式
构造函数创建
最简单的方式就是通过构造函数创建一个CompletableFuture实例。如下代码所示。由于新创建的CompletableFuture还没有任何计算结果,这时调用join,当前线程会一直阻塞在这里。
CompletableFuture<String> future = new CompletableFuture();
String result = future.join();
System.out.println(result);此时,如果在另外一个线程中,主动设置该CompletableFuture的值,则上面线程中的结果就能返回。
future.complete("test");supplyAsync创建
CompletableFuture.supplyAsync()也可以用来创建CompletableFuture实例。通过该函数创建的CompletableFuture实例会异步执行当前传入的计算任务。在调用端,则可以通过get或join获取最终计算结果。
CompletableFuture<String> future
= CompletableFuture.supplyAsync(()->{
System.out.println("compute test");
return "test";
});
String result = future.join();
System.out.println("get result: " + result);异步任务中会打印出compute test,并返回test作为最终计算结果。所以,最终的打印信息为**get result: test**
runAsync创建
CompletableFuture.runAsync()也可以用来创建CompletableFuture实例。与supplyAsync()不同的是,runAsync()传入的任务要求是**Runnable类型的,所以没有返回值**。因此,runAsync适合创建不需要返回值的计算任务。
CompletableFuture<Void> future = CompletableFuture.runAsync(()->{
System.out.println("compute test");
});
System.out.println("get result: " + future.join());
//由于任务没有返回值, 所以最后的打印结果是"get result: null"。15.3 、异步回调方法
同Future相比,CompletableFuture最大的不同是支持流式(Stream)的计算处理,多个任务之间,可以前后相连,从而形成一个计算流。比如:任务1产生的结果,可以直接作为任务2的入参,参与任务2的计算,以此类推。
CompletableFuture中常用的流式连接函数包括:
thenApply——有入参有返回
thenApplyAsync——有入参有返回
thenAccept——有入参无返回
thenAcceptAsync——有入参无返回
thenRun——无入参无返回
thenRunAsync——无入参无返回
thenCombine
thenCombineAsync
thenCompose
thenComposeAsync
whenComplete
whenCompleteAsync
handle
handleAsync
其中,带Async后缀的函数表示需要连接的后置任务会被单独提交到线程池中,从而相对前置任务来说是异步运行的。除此之外,两者没有其他区别。
public class CompletableFutureDemo {
//没有返回值的runAsync异步回调
@Test
@SneakyThrows
public void dome01(){
// 发起一个请求
System.out.println(System.currentTimeMillis());
System.out.println("-----------");
//CompletableFuture.runAsync 没有返回值 不能使用 return
CompletableFuture future = CompletableFuture.runAsync(()->{
// 发起一个异步任务
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"......");
}).thenAccept((oil)->{
System.out.println("获取值");
});
CompletableFuture<Void> voidCompletableFuture = CompletableFuture
//让儿子去打酱油
.supplyAsync(() -> {
try {
System.out.println("儿子跑步去打酱油");
TimeUnit.SECONDS.sleep(1);
System.out.println("酱油打好了");
} catch (InterruptedException e) {
e.printStackTrace();
}
return "酱油";
})
//thenAccept 有入参有返回
.thenAccept(oil -> {
System.out.println("做菜用酱油:" + oil);
});
System.out.println(System.currentTimeMillis());
System.out.println("-------------------------");
System.out.println(future.get());//获取执行结果
}
//有返回值的异步回调supplyAsync
//调用成功返回
@Test
@SneakyThrows
public void dome02(){
CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1024;
});
System.out.println(
completableFuture
//有入参有返回
.thenApply((me)->{
System.out.println(me);//1024
return 1080; //get()到的是这个值
})
//有入参无返回
.thenAccept((num)->{
System.out.println(num);//1024
})
//无入参无返回
.thenRun(()->{
System.out.println("thenRun");
})
//任务完成时的回调通知逻辑
.whenComplete((t,u)->{
//t:获取正常返回结果 没有返回则为null
//u:捕获异常返回信息
System.out.println("t=>" +t);//t=>1024
System.out.println("u=>" +u);//u=>null
})
.exceptionally((e)->{
// error 回调
System.out.println(e.getMessage());
return 404;
})
.get()//1024
);
}
//调用失败返回
@Test
@SneakyThrows
public void dome03(){
CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName());//ForkJoinPool.commonPool-worker-1
try {
TimeUnit.SECONDS.sleep(2);
//设置算术异常代码
int i=10/0;
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1024;
});
System.out.println(
completableFuture.whenComplete((t,u)->{
// success 回调
// t:正常返回结果
System.out.println("t=>" +t);//t=>null
// u:异常赶回 错误信息
System.out.println("u=>" +u);//u=>java.util.concurrent.CompletionException: java.lang.ArithmeticException: / by zero
}).exceptionally((e)->{
//捕获error ,没有这个捕获异常 会把异常抛出到控制台程序结束
System.out.println(e.getMessage());//java.lang.ArithmeticException: / by zero
return 404;
}).get()//404 --程序异常get到的是异常返回的404
);
}
}15.4、thenApply / thenAccept / thenRun互相依赖
这里将thenApply / thenAccept / thenRun放在一起讲,因为这几个连接函数之间的唯一区别是提交的任务类型不一样 :
thenApply提交的任务类型需遵从Function签名,也就是有入参和返回值,其中入参为前置任务的结果
thenAccept提交的任务类型需遵从Consumer签名,也就是有入参但是没有返回值,其中入参为前置任务的结果
thenRun提交的任务类型需遵从Runnable签名,即没有入参也没有返回值
CompletableFuture<Integer> future1
= CompletableFuture.supplyAsync(()->{
System.out.println("compute 1");
return 1;
});
CompletableFuture<Integer> future2
= future1.thenApply((p)->{
System.out.println("compute 2");
return p+10;
});
System.out.println("result: " + future2.join());15.5、thenApply
thenApply 表示某个任务执行完成后执行的动作,即回调方法,会将该任务的执行结果即方法返回值作为入参传递到回调方法中,测试用例如下:
@Test
public void test5() throws Exception {
//CompletableFuture 默认线程 ForkJoinPool
ForkJoinPool pool=new ForkJoinPool();
// 创建异步执行任务:
CompletableFuture<Double> cf = CompletableFuture.supplyAsync(()->{
System.out.println(Thread.currentThread().getName()+" 线程1执行");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
System.out.println(Thread.currentThread().getName()+" 线程1结束");
return 1.2;
},pool);
//cf关联的异步任务的返回值作为方法入参,传入到thenApply的方法中
//thenApply这里实际创建了一个新的CompletableFuture实例
CompletableFuture<String> cf2=cf.thenApply((result)->{
System.out.println(Thread.currentThread().getName()+" 线程2执行");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
System.out.println(Thread.currentThread().getName()+" 线程2结束");
return "test:"+result;
});
System.out.println("主线程开始 获取线程1 开始 时间"+System.currentTimeMillis());
//等待子任务执行完成
System.out.println("线程1返回结果"+cf.get());
System.out.println("主线程开始 获取线程1 结束 时间"+System.currentTimeMillis());
System.out.println("线程2返回结果"+cf2.get());
System.out.println("主线程+ForkJoinPool线程 结束 时间"+System.currentTimeMillis());
/**cf.thenApply((result) 执行结果
*
* ForkJoinPool.commonPool-worker-1 线程1执行 说明是异步进行
*主线程开始 获取线程1 开始 时间1678437309369
*ForkJoinPool.commonPool-worker-1 线程1结束
*ForkJoinPool.commonPool-worker-1 线程2执行
*线程1返回结果1.2
*主线程开始 获取线程1 结束 时间1678437311384
*ForkJoinPool.commonPool-worker-1 线程2结束
*线程2返回结果test:1.2
*主线程+ForkJoinPool线程 结束 时间1678437313391
ForkJoinPool.commonPool-worker-1说明两个CompletableFuture是同一个线程执行
*/
ob1执行结束后,将job1的方法返回值作为入参传递到job2中并立即执行job2。thenApplyAsync与thenApply的区别在于,前者是将job2提交到线程池中异步执行,实际执行job2的线程可能是另外一个线程,后者是由执行job1的线程立即执行job2,即两个job都是同一个线程执行的。将上述测试用例中thenApply改成thenApplyAsync后,执行结果如下:
/**cf.thenApplyAsync((result) 执行结果
*
*ForkJoinPool-1-worker-1 线程1执行
* 主线程开始 获取线程1 开始 时间1678437606176
* ForkJoinPool-1-worker-1 线程1结束
* ForkJoinPool.commonPool-worker-1 线程2执行
* 线程1返回结果1.2
* 主线程开始 获取线程1 结束 时间1678437608187
* ForkJoinPool.commonPool-worker-1 线程2结束
* 线程2返回结果test:1.2
* 主线程+ForkJoinPool线程 结束 时间1678437610196
*ForkJoinPool-1-worker-1 与 ForkJoinPool.commonPool-worker-1不同 说明是不同的线程执行 异步执行
*/
结论:
每个方法都有两个以Async结尾的方法,一个使用默认的Executor实现,一个使用指定的Executor实现,
不带Async的方法是由触发该任务的线程执行该任务,
带Async的方法是由触发该任务的线程将任务提交到线程池,执行任务的线程跟触发任务的线程不一定是同一个
}16、JMM
资料:https://blog.csdn.net/m0_46845579/article/details/125944917
JMM即为JAVA 内存模型(java memory model)。不存在的东西, 是概念,是约定。因为在不同的硬件生产商和不同的操作系统下, 内存的访问逻辑有一定的差异,结果就是当你的代码在某个系统环境下运行良好,并且线程安全,但是换了个系统就出现各种问题。Java内存模型,就是为了 屏蔽系统和硬件的差异,让一套代码在不同平台下能到达相同的访问结果。即达到Java程序能够“ 一次编写,到处运行”。
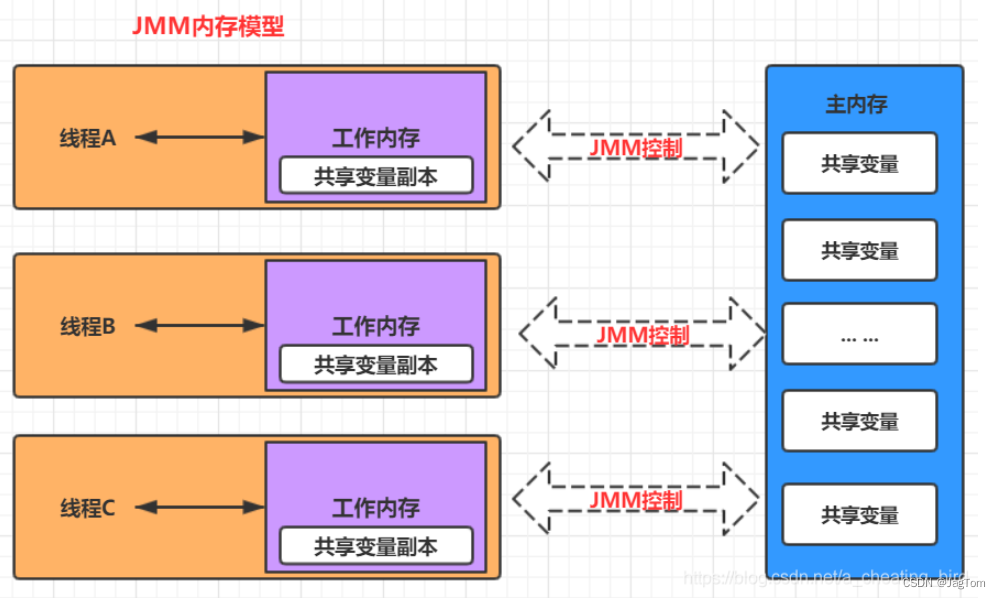
16.1、JMM内存模型
JMM规定了所有的变量都存储在 主内存(Main Memory)中。每个线程还有自己的 工作内存(Working Memory), 线程的工作内存中保存了该线程使用到的变量的主内存的副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量(volatile变量仍然有工作内存的拷贝,但是由于它特殊的操作顺序性规定,所以看起来如同直接在主内存中读写访问一般)。 不同的线程之间也无法直接访问对方工作内存中的变量,线程之间值的传递都需要通过主内存来完成。
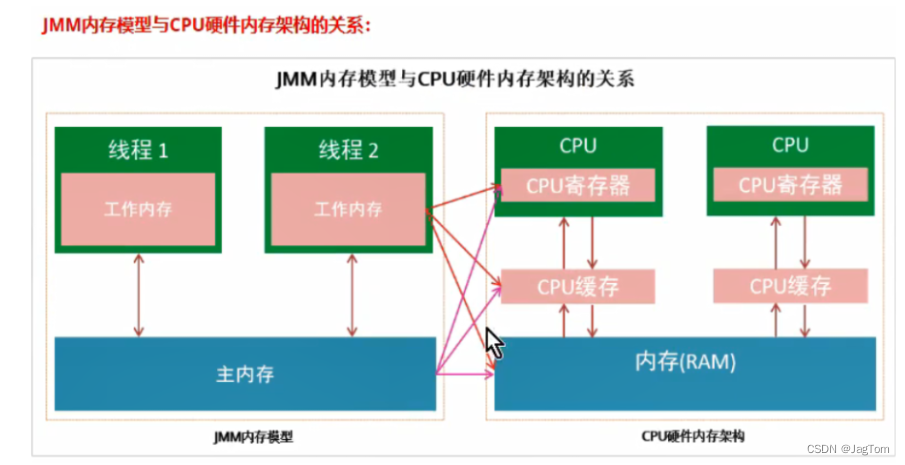
从更底层的来说,主内存对应的是硬件的物理内存,工作内存对应的是寄存器和高速缓存。
问题:当一个线程修改了自己工作内存中变量,对其他线程是不可见的,**会导致线程不安全的问题。**因为JMM制定了一套标准来保证开发者在编写多线程程序的时候,能够控制什么时候内存会被同步给其他线程。
16.2、JMM的三大特性
JMM的三大特性:原子性、可见性、有序性。
1.原子性
一个或多个操作, 要么全部执行,要么全部不执行(执行的过程中是不会被任何因素打断的)。
为什么会有原子性问题:
因为CPU 有时间片的概念,会根据不同的调度算法进行线程调度。当一个线程获得时间片之后开始执行,在时间片耗尽之后,就会失去 CPU 使用权。所以在多线程场景下,由于时间片在线程间轮换,就会发生原子性问题。
a = true; //原子性
a = 5; //原子性
a = b; //非原子性,分两步完成,第一步加载b的值,第二步将b赋值给a
a = b + 2; //非原子性,分三步完成
a ++; //非原子性,分三步完成:1、读取a的值,2、计算a的值+1,3、赋值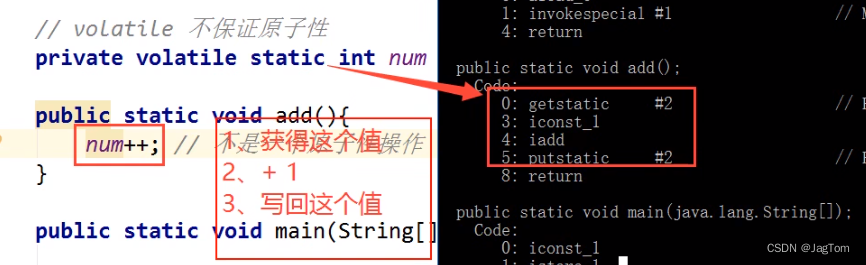
如何保证原子性:
synchronized一定能保证原子性,因为被其修饰的某段代码,只能由一个线程执行,所以一定可以保证原子操作。
juc(java.util.concurrent包)中的lock包和atomic包(原子类),他们也可以解决原子性问题.
2.可见性
只要有一个线程对共享变量的值做了 修改,其他线程都将 马上收到通知,立即获得最新值
为什么会有可见性问题:
根据JMM内存模型,可以看到主内存和线程工作内存之间存在时间差(延迟)问题。这种工作内存与主内存同步延迟现象就造成了可见性问题,另外指令重排以及编译器优化也可能导致可见性问题
如何保证可见性:
volatile的特殊规则保证了volatile变量值修改后的新值立刻同步到主内存,每次使用volatile变量前立即从主内存中刷新,因此volatile保证了多线程之间的操作变量的可见性,而普通变量则不能保证这一点。
除了volatile关键字能实现可见性之外,还有synchronized,Lock,final也是可以的。
synchronized,Lock:通过线程私有的工作内存中的值写入到主内存进行同步
final关键字的可见性是指:被final修饰的变量,在构造函数数一旦初始化完成,并且在构造函数中并没有把“this”的引用传递出去(“this”引用逃逸是很危险的,其他的线程很可能通过该引用访问到只“初始化一半”的对象),那么其他线程就可以看到final变量的值。
3.有序性
在本线程内观察,所有的操作都是有序的;代码按顺序执行
有序性可以总结为:**在本线程内观察,所有的操作都是有序的;而在一个线程内观察另一个线程,所有操作都是无序的。**前半句指 as-if-serial 语义:线程内似表现为串行,后半句是指:“指令重排序现象”和“工作内存与主内存同步延迟现象”。
as-if-serial语义:
不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。(编译器、runtime和处理器都必须遵守as-if-serial语义)
为什么会有有序性问题
处理器为了提高程序的运行效率,提高并行效率,可能会对代码进行优化。编译器认为,重排序后的代码执行效率更优。这样一来,代码的执行顺序就未必是编写代码时候的顺序了,在多线程的情况下就可能会出错。
在代码顺序结构中,我们可以直观的指定代码的执行顺序, 即从上到下按序执行。但编译器和CPU处理器会根据自己的决策,对代码的执行顺序进行重新排序,优化指令的执行顺序,提升程序的性能和执行速度,使语句执行顺序发生改变,出现重排序,但最终结果看起来没什么变化(在单线程情况下)。
有序性问题 指的是在多线程的环境下,由于执行语句重排序后,重排序的这一部分没有一起执行完,就切换到了其它线程,导致计算结果与预期不符的问题。这就是编译器的编译优化给并发编程带来的程序有序性问题。
如何保证有序性
Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性,volatile 是因为其本身包含“禁止指令重排序”的语义,synchronized 是由“**一个变量在同一个时刻只允许一条线程对其进行 lock 操作”**这条规则获得的,此规则决定了持有同一个对象锁的两个同步块只能串行进入。
16.3、JMM同步的规定
1.线程解锁前,必须把共享变量的值刷新回主内存。
2.线程加锁前,必须将主内存的最新值读取到自己的工作内存。
3.加锁解锁是同一把锁。
16.4、8种内存交互操作
虚拟机实现必须保证每一个操作都是原子的,不可在分的(对于double和long类型的变量来说,load、store、read和write操作在某些平台上允许例外)

lock(锁定):作用于主内存的变量,把一个变量标识为线程独占状态
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被**其他线程锁定
read(读取):作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用**
load(载入):作用于工作内存的变量,它把read操作从主存中变量**放入工作内存中
use(使用):作用于工作内存中的变量,它把工作内存中的变量传输给执行引擎,每当虚拟机遇到一个需要使用到变量的值,就会使用到这个指令**
assign(赋值):作用于工作内存中的变量,它把一个从执行引擎中接受到的值放**入工作内存的变量副本中
store(存储):作用于主内存中的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用**
write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
JMM对这八种指令的使用,制定了如下规则:
不允许read和load、store和write操作之一单独出现。即使用了read必须load,使用了store必须write必须组合使用
不允许线程丢弃他最近的assign操作,即工作变量的数据改变了之后,必须告知主存
不允许一个线程将没有assign的数据从工作内存同步回主内存
一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是怼变量实施use、store操作之前,必须经过assign和load操作
一个变量同一时间只有一个线程能对其进行lock。多次lock后,必须执行相同次数的unlock才能解锁
如果对一个变量进行lock操作,会清空所有工作内存中此变量的值,在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值
如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量
对一个变量进行unlock操作之前,必须把此变量同步回主内存

分析:
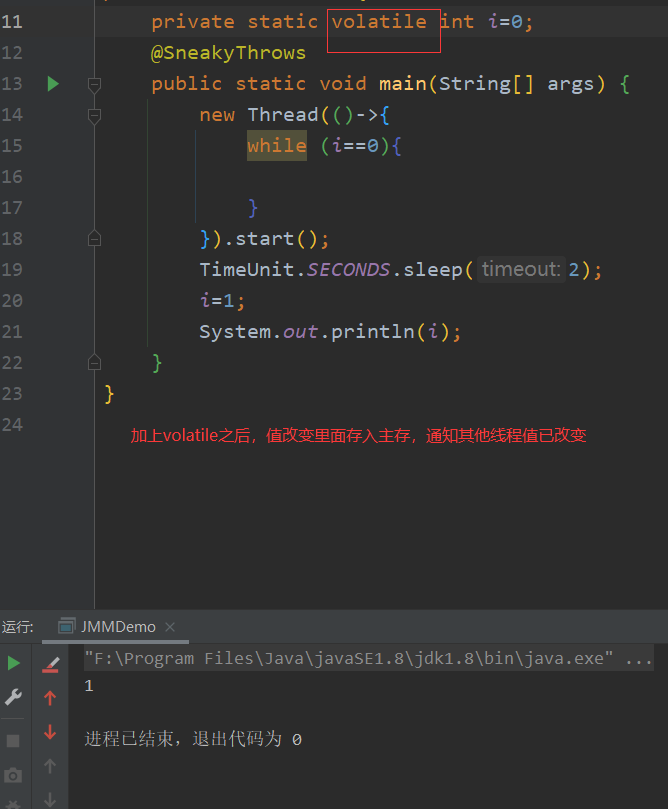
首先,主内存中,initFlag=false。
线程1经过 read、load,工作内存处,initFlag = false,use 之后, 执行引擎处 !initFlag = true,此时,卡在while处。
线程2同理,经过 read、load 之后,此时工作内存处,initFlag=false,经过 use (initFlag=true)、assign后,initFlag=true。
因为线程2处的cpu修改了 initFlag 的值,会 马上回写 到主内存中(经过 store、write两步)。
线程1处的cpu 通过 总线嗅探机制 嗅探到变化,会将工作内存中的数据 失效(initFlag=false失效)
线程1会 重新 去主内存 read 最新的数据(此时,主内存中的数据 initFlag=true)。
那么,线程1在读取最新的数据时,执行引擎处,!initFlag = false,结束循环,输出 “success”。
加上volatile关键字保证可见性
17、volatile
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也称内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
17.1、保证有序性
(禁止指令重排)
什么是指令重排?
我们写的程序,计算机并不是按照我们自己写的那样去执行的
源代码–>编译器优化重排–>指令并行也可能会重排–>内存系统也会重排–>执行
处理器在进行指令重排的时候,会考虑数据之间的依赖性!
int x=1; //1
int y=2; //2
x=x+5; //3
y=x*x; //4
//我们期望的执行顺序是 1_2_3_4 可能通过编译之后的执行的顺序会变成2134 1324。但是不会导致程序逻辑错误。
//可不可能是 4123? 不可能的volatile中会加一道内存的屏障,这个内存屏障可以保证在这个屏障中的指令顺序不会重排。
内存屏障:CPU指令。作用:
1、保证特定的操作的执行顺序;
2、可以保证某些变量的内存可见性(利用这些特性,就可以保证volatile实现的可见性)
volatile的内存屏障策略:
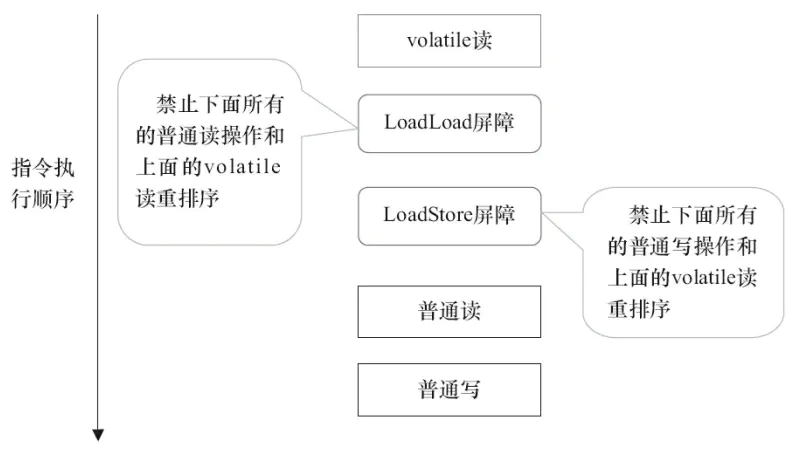
volatile写之前插入StoreStore屏障;(规则a,防止重排)
volatile写之后插入StoreLoad屏障;(规则c,保障可见性)
volatile读之后插入LoadStore屏障;(规则b,防止重排)
volatile读之后插入LoadLoad屏障;(规则b,防止重排)
LoadLoad Barriers
排队,当第一个读屏障指令读取数据完毕之后,后一个读屏障指令才能够进行加载读取
(禁止读和读的重排序)
StoreStore Barriers
当A写屏障指令写完之后且保证A的的写入可以被其他处理器看见,再进行B的写入操作
(禁止写与写的重排序)
LoadStore Barriers
前一个读屏障指令读取完毕后,后一个写屏障指令才会进行写入
(禁止读和写的重排序)
StoreLoad Barriers
全能屏障,同时具有前三个的类型的效果,但开销较大。
先保证A的写入会被其他处理器可见,才进行B的读取指令
(禁止写和读的重排序)
volatile保证有序性原理:在每一个写的volatile前后插入写屏障,读的volatile前后插入读屏障。
写,在每一次写入之前屏障拿到其他的线程修改的数据(因为可见性和重排序)。写入后的屏障可以被其他线程拿到最新的值。
读,在每一个读之前屏障获取某个变量的值的时候,这个值可以被其他线程也获取到。读取后的屏障可以在其他线程修改之前获取到主内存变量的当前值
volatile写 内存屏障原理

volatile读 内存屏障原理
多线程它是怎么保证数据的原子性的哪?
举个例子:
假设线程A和线程B两个线程同时执行getAndAddlInt操作(分别跑在不同CPU上) :
(一). AtomicInteger里面的value原始值为3,即主内存中Atomiclnteger的value为3,根据JMM模型,线程A和线程B各自持有一份值为3的value的副本分别到各自的工作内存。
(二).线程A通过getIntVolatile(var1, var2)拿到value值3,这时线程A被挂起。
(三)线程B也通过getlntVolatile(var1, var2)方法获取到value值3,此时刚好线程B没有被挂起并执行compareAndSwaplnt方法比较内存值也为3,成功修改内存值为4,线程B打完收工,一切OK。
(四).这时线程A恢复,执行compareAndSwaplnt方法比较,发现自己手里的值数字3和主内存的值数字4不一致,说明该值己经被其它线程抢先一步修改过了,那A线程本次修改失败,只能重新读取重新来一遍了。
(五).线程A重新获取value值,因为变量value被volatle修饰,所以其它线程对它的修改,线程A总是能够看到,线程A继续执行compareAndSwaplnt进行比较替换,直到成功。
17.2、保证可见性
volatile很好的保证了变量的可见性,变量经过volatile修饰后,对此变量进行写操作时,汇编指令中会有一个LOCK前缀指令,这个不需要过多了解,但是加了这个指令后,会引发两件事情:
将当前处理器缓存行的数据写回到系统内存
这个写回内存的操作会使得在其他处理器缓存了该内存地址无效
volatile修饰的共享变量在执行写操作后,会立即刷回到主存,以供其它线程读取到最新的记录。
17.3、不保证原子性
volatile只有写操作是原子性的,也就是数据操作完成后会立刻刷新到主内存中。但是被volatile修饰的变量在读的时候可能会被多个线程读。也就是说int i = 1;i++;
A线程读 i = 1同时B线程也读了i = 1,然后自增完成刷新入主内存。i的值是2。
所以如果该变量是volatile修饰的,那可以完全保证此时取到的是最新信息。但在入栈和自增计算执行过程中,该变量有可能正在被其他线程修改,最后计算出来的结果照样存在问题,因此volatile并不能保证非原子操作的原子性,仅在单次读或者单次写这样的原子操作中,volatile能够实现线程安全。
public class JMMDemo {
private static volatile int i=0;
public static void add(){
i++;
}
@SneakyThrows
public static void main(String[] args) {
//创建20个线程,每个线程执行100次i++操作 理论结果输出i=2000
for (int j = 0; j < 20; j++) {
new Thread(()->{
for (int k = 0; k < 100; k++) {
add();
}
}).start();
}
//如果活动线程大于2 (默认有 main gc) 让当前正在执行的线程暂停,但不阻塞
//将线程从运行状态转为就绪状态
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println(Thread.currentThread().getName()+",i = "+i);//main,i = 1970
}
}i++;底层代码不是一个原子操作,是非原子性的
加的次数是固定的,有的线程取的是旧的值,结果肯定小了
volatile只保证了变量在内存中的可见性但无法保证对变量的操作为原子性,在不使用除锁机制的条件下可以使用atomic包下的原子类
使用原子类AutomicInteger
public class JMMDemo {
//AtomicInteger 原子类能保证操作数据原子性 unsafe类涉及到CAS
private static volatile AtomicInteger i=new AtomicInteger(0);
public static void add(){
i.incrementAndGet();//底层是 CAS 保证原子性
}
@SneakyThrows
public static void main(String[] args) {
//创建20个线程,每个线程执行100次i++操作 理论结果输出i=2000
for (int j = 0; j < 20; j++) {
new Thread(()->{
for (int k = 0; k < 100; k++) {
add();
}
}).start();
}
//如果活动线程大于2 (默认有 main gc) 让当前正在执行的线程暂停,但不阻塞
//将线程从运行状态转为就绪状态
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println(Thread.currentThread().getName()+",i = "+i);//main,i = 2000
}
}那么你知道在哪里用这个volatile内存屏障用得最多呢?单例模式
18、 单例模式
任何时候都只能有一个实例。且该类需自行创建这个实例,并对其他的类提供调用这一实例的方法。
单例类只能有一个实例。
单例类必须自己创建自己的唯一实例。
单例类必须给所有其他对象提供这一实例。
单例模式确保某个类只有一个实例,而且自行实例化并向整个系统提供这个实例。在计算机系统中,线程池、缓存、日志对象、对话框、打印机、显卡的驱动程序对象常被设计成单例。这些应用都或多或少具有资源管理器的功能。每台计算机可以有若干个打印机,但只能有一个Printer Spooler,以避免两个打印作业同时输出到打印机中。每台计算机可以有若干通信端口,系统应当集中管理这些通信端口,以避免一个通信端口同时被两个请求同时调用。总之,选择单例模式就是为了避免不一致状态,避免政出多头。
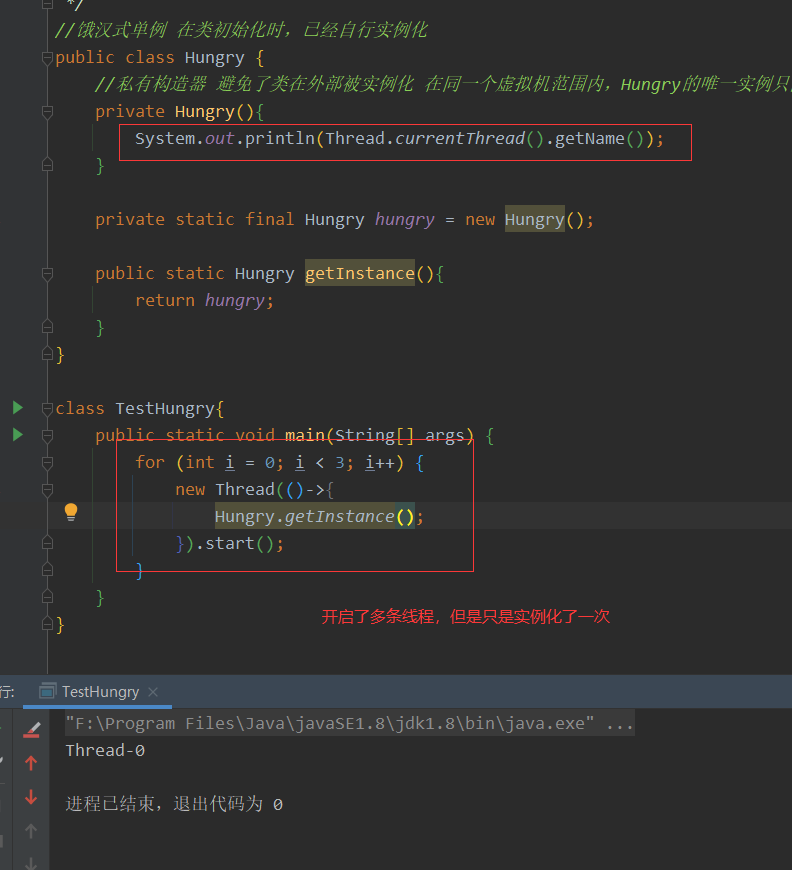
18.1 饿汉式
饿汉式,就是“比较饿”,实例在初始化的时候就已经自行实例化,不管你有没有用到。
优点:线程安全;在类加载(ClassLoader)的同时已经创建好一个静态对象,调用时反应速度快。
缺点:对象提前创建,所以会占据一定的内存,内存占用大 以空间换时间。
//饿汉式单例 在类初始化时,已经自行实例化
public class SingleHungryDemo {
/*
* 可能会浪费空间
* */
private byte[] data1 = new byte[1024*1024];
private byte[] data2 = new byte[1024*1024];
private byte[] data3 = new byte[1024*1024];
private byte[] data4 = new byte[1024*1024];
//SingleHungryDemo通过将构造方法限定为private避免了类在外部被实例化,在同一个虚拟机范围内,SingleHungryDemo的唯一实例只能通过getInstance()方法访问。
private SingleHungryDemo(){
}
/**
* 私有实例,静态变量会在类加载的时候初始化,是线程安全的
*/
private final static SingleHungryDemo hungry = new SingleHungryDemo();
/**
* 唯一公开获取实例的方法(静态工厂方法)
*
* @return
*/
public static SingleHungryDemo getInstance(){
return hungry;
}
}多线程安全。
18.2 DCL 懒汉式
懒汉式就是“比较懒”,就是在用到的时候才去检查有没有实例,如果有则直接返回,没有则新建。
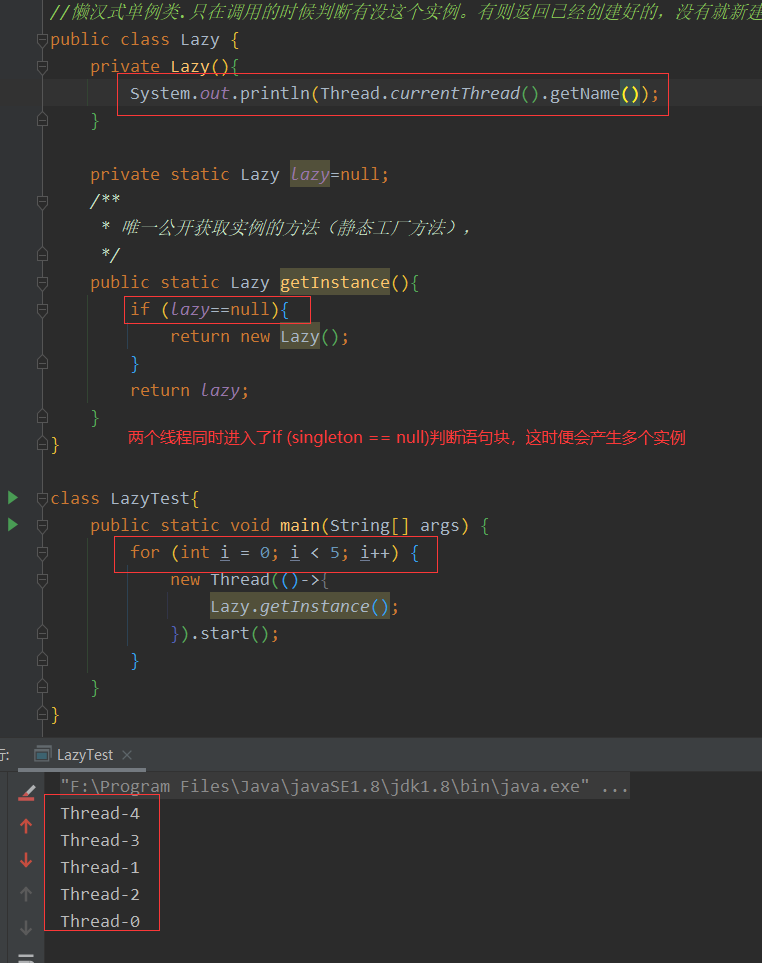
优点:起到了Lazy Loading的效果,但是只能在单线程下使用。
缺点:如果在多线程下,两个线程同时进入了if (singleton == null)判断语句块,这时便会产生多个实例。所以
在多线程环境下不可使用这种方式。
//懒汉式单例类.只在调用的时候判断有没这个实例。有则返回已经创建好的,没有就新建一个
public class Lazy {
private Lazy(){}
private static Lazy lazy=null;
/**
* 唯一公开获取实例的方法(静态工厂方法),
*/
public static Lazy getInstance(){
if (lazy==null){
return new Lazy();
}
return lazy;
}
}线程不安全
要实现线程安全,有以下三种方式,都是对getInstance这个方法改造,保证了懒汉式单例的线程安全,
1.在getInstance方法上加同步
/**
* 唯一公开获取实例的方法(静态工厂方法),
*/
public static synchronized Lazy getInstance(){
if (lazy==null){
return new Lazy();
}
return lazy;
}2、双重检查锁定
/**
* 双重检测锁模式
*/
public static synchronized Lazy getInstance(){
//第一个 if 语句用来避免 lazy 已经被实例化之后的加锁操作
if (lazy==null){
// 加锁 对这个实例加锁防止多线程多次创建
synchronized (Lazy.class){
//第二个 if 语句进行了加锁,所以只能有一个线程进入,就不会出现 lazy == null
// 时两个线程同时进行实例化操作
//判断有没有创建这个实例
if (lazy==null) {
return new Lazy();
}
}
}
return lazy;
}18.3、静态内部类
该模式利用了静态内部类延迟初始化的特性,来达到与双重校验锁方式一样的功能。
缺点: 可以被反射破坏
public class StaticInnerClassSingleton {
private StaticInnerClassSingleton(){}
/**
* 唯一公开获取实例的方法(静态工厂方法)
*
* @return
*/
public static StaticInnerClassSingleton getInstance() {
return LazyHolder.INSTANCE;
}
/**
* 私有静态内部类
*/
private static class LazyHolder {
private static final StaticInnerClassSingleton INSTANCE = new StaticInnerClassSingleton();
}
}反射破坏静态内部类单例模式附上代码:
public static void main(String[] args) {
try {
Constructor<StaticInnerClassSingleton> con = StaticInnerClassSingleton.class.getDeclaredConstructor();
//值为 true 则指示反射的对象在使用时应该取消 Java 语言访问检查
//方便获取私有属性
con.setAccessible(true);
StaticInnerClassSingleton singleton = (StaticInnerClassSingleton) con.newInstance();
System.out.println(singleton);
StaticInnerClassSingleton singleton5 = (StaticInnerClassSingleton) con.newInstance();
System.out.println(singleton5);
//singleton singleton5 不是同一个对象。破坏了单例模式
} catch (Exception e) {
e.printStackTrace();
}
}18.4、枚举
优点:枚举式单例不会被反射破坏 , 内存中只存在一个对象实例,节省了系统资源,对于一些需要频繁创建销毁的对象,使用单例模式可以提高系统性能。
缺点:当想实例化一个单例类的时候,必须要记住使用相应的获取对象的方法,而不是使用new,可能会给其他开发人员造成困扰。
public enum EnumSingle {
INSTANCE;
public EnumSingle getInstance(){
return INSTANCE;
}
}通过IDEA和 javap -p EnumSingle.class 里面有一个无参的构造方法
结果通过软件反编译 枚举类型的最终反编译源码:里面有个一带参的构造方法
public final class EnumSingle extends Enum
{
。。。。
private EnumSingle(String s, int i)
{
super(s, i);
}
....
}18.5 饿汉式与懒汉式的区别
饿汉就是类一旦加载,就把单例初始化完成,保证getInstance的时候,单例是已经存在的了,
懒汉比较懒,只有当调用getInstance的时候,才会去初始化这个单例。
1、线程安全:
饿汉式天生就是线程安全的,可以直接用于多线程而不会出现问题,
懒汉式本身是非线程安全的,为了实现线程安全有几种写法,分别是
在getInstance方法上加同步
双重检查锁定
静态内部类
2、资源加载和性能:
饿汉式在类创建的同时就实例化一个静态对象出来,不管之后会不会使用这个单例,都会占据一定的内存,但是相应的,在第一次调用时速度也会更快,因为其资源已经初始化完成,
而懒汉式顾名思义,会延迟加载,在第一次使用该单例的时候才会实例化对象出来,第一次调用时要做初始化,如果要做的工作比较多,性能上会有些延迟,之后就和饿汉式一样了.
结论:由结果可以得知单例模式为一个面向对象的应用程序提供了 对象惟一的访问点,不管它实现何种功能, 整个应用程序都会同享一个实例对象。
19、深入理解CAS
19.1 什么是CAS?
CAS,compare and swap的缩写,中文翻译成比较并交换。它是一条CPU并发原语。
它的功能是判断内存某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。
CAS并发原语体现在JAVA语言中就是sun.misc.Unsafe类中的各个方法。调用UnSafe类中的CAS方法,JVM会帮我们实现出CAS汇编指令。
CAS 操作包含三个操作数 —— 内存位置(V)、 预期原值(A)和**新值(**B)。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。
CAS通俗的解释就是:
比较当前工作内存中的值和主内存中的值,如果相同则执行规定操作,否则继续比较直到主内存和工作内存中的值一致为止.
import java.util.concurrent.atomic.AtomicInteger;
public class CASDemo {
// CAS: compareAndSet 比较并交换
public static void main(String[] args){
AtomicInteger atomicInteger = new AtomicInteger(2020);
// boolean compareAndSet(int expect, int update)
// 期望值、更新值
// 如果实际值 和 我期望值相同,那么就更新
// 如果实际值 和 我期望值不同,那么就不更新
System.out.println(atomicInteger.compareAndSet(2020,2021));
System.out.println(atomicInteger.get());
// 因为期望值是 2020 ,实际值却变成了2021 所以会修改失败
// CAS 是 CPU 的并发原语
atomicInteger.getAndIncrement();//++操作
System.out.println(atomicInteger.compareAndSet(2020,2021));
System.out.println(atomicInteger.get());
}
}19.2、原子类
JUC 并发包中原子类 , 都存放在 java.util.concurrent.atomic 类路径下:
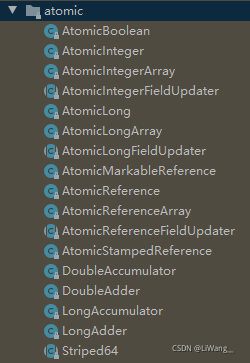
根据操作的目标数据类型,可以将 JUC 包中的原子类分为 4 类:
基本原子类
数组原子类
原子引用类型
字段更新原子类
19.3、原子类AtomicInteger
1、常用的方法:
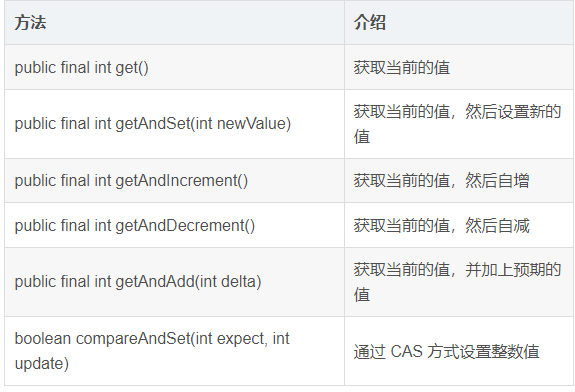
AtomicInteger 案例:
private static void out(int oldValue,int newValue){
System.out.println("旧值:"+oldValue+",新值:"+newValue);
}
public static void main(String[] args) {
int value = 0;
AtomicInteger atomicInteger= new AtomicInteger(0);
//取值,然后设置一个新值
value = atomicInteger.getAndSet(3);
//旧值:0,新值:3
out(value,atomicInteger.get());
//取值,然后自增
value = atomicInteger.getAndIncrement();
//旧值:3,新值:4
out(value,atomicInteger.get());
//取值,然后增加 5
value = atomicInteger.getAndAdd(5);
//旧值:4,新值:9
out(value,atomicInteger.get());
//CAS 交换
boolean flag = atomicInteger.compareAndSet(9, 100);
//旧值:4,新值:100
out(value,atomicInteger.get());
}AtomicInteger 源码解析:
public class AtomicInteger extends Number implements java.io.Serializable {
// 设置使用Unsafe.compareAndSwapInt进行更新
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) {
throw new Error(ex);
}
}
...省略
private volatile int value;
//自动设置为给定值并返回旧值。
public final int getAndSet(int newValue) {
return unsafe.getAndSetInt(this, valueOffset, newValue);
}
//=========================getAndSet底层开始====================
var1 Atomiclnteger对象本身。
var2该对象值得引用地址。
var4需要变动的数量。
var5是用过var1 var2找出的主内存中真实的值。
用该对象当前的值与var5比较:
如果相同,更新var5+var4并且返回true,
如果不同,继续取值然后再比较,直到更新完成。
public final int getAndSetInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
// =================================getAndSet底层结束=====================
//以原子方式将当前值加1并返回旧值。
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
//以原子方式将当前值减1并返回旧值。
public final int getAndDecrement() {
return unsafe.getAndAddInt(this, valueOffset, -1);
}
//原子地将给定值添加到当前值并返回旧值。
public final int getAndAdd(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta);
}
...省略
}public final int getAndIncrement()源码解析
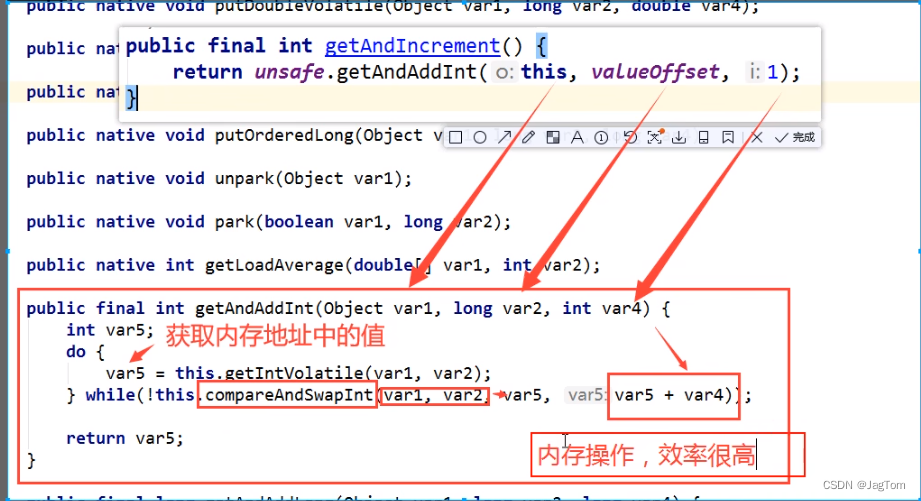
这里的原子类方法用了do while,无限循环,其实就是一个标准的自旋锁。
通过源码我们发现AtomicInteger的增减操作都调用了Unsafe实例的方法,下面我们对Unsafe类做
19.4、Unsafe类
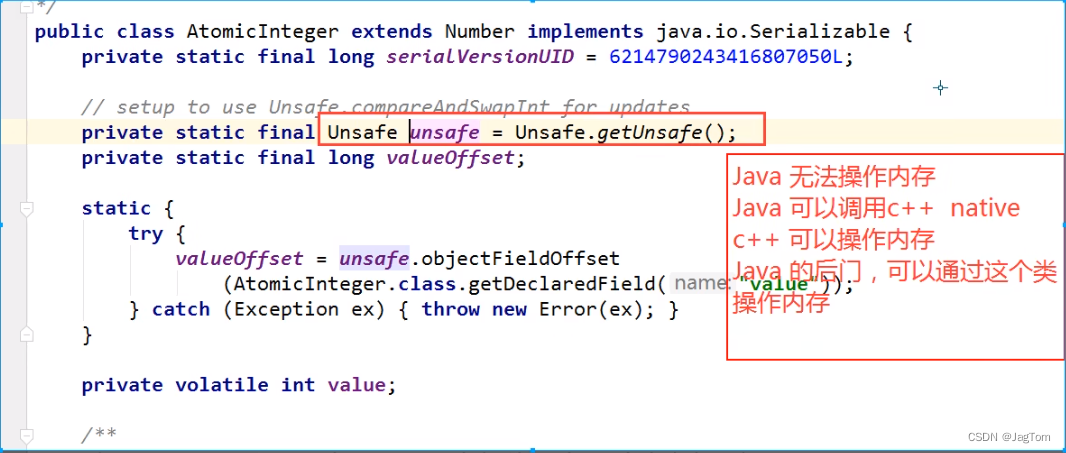
Unsafe 是位于 sun.misc 包下的一个类,Unsafe 提供了CAS 方法,直接通过**native 方式(封装 C++代码)**调用了底层的 CPU 指令 cmpxchg。
Unsafe类,翻译为中文:危险的,Unsafe全限定名是 sun.misc.Unsafe,从名字中我们可以看出来这个类对普通程序员来说是“危险”的,一般应用开发者不会用到这个类。
1、Unsafe 提供的 CAS 方法
主要如下: 定义在 Unsafe 类中的三个 “比较并交换”原子方法
/*
@param o 包含要修改的字段的对象
@param offset 字段在对象内的偏移量
@param expected 期望值(旧的值)
@param update 更新值(新的值)
@return true 更新成功 | false 更新失败
*/
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt( Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong( Object o, long offset, long expected, long update);Unsafe 提供的 CAS 方法包含四个入参:
包含要修改的字段对象、字段内存位置、预期原值及新值。
在执行 Unsafe 的 CAS 方法的时候,这些方法首先将内存位置的值与预期值(旧的值)比
较,如果相匹配,那么处理器会自动将该内存位置的值更新为新值,并返回 true ;如果不相匹配,处理器不做任何操作,并返回 false 。
19.5、CAS存在的缺点
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。
ABA问题
循环时间长开销大
只能保证一个共享变量的原子操作
ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A - 2B-3A。
循环时间长开销大 高并发下N多线程同时去操作一个变量,会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性。解决 CAS 恶性空自旋的较为常见的方案为:
分散操作热点,使用 LongAdder 替代基础原子类 AtomicLong。
使用队列削峰,将发生 CAS 争用的线程加入一个队列中排队,降低 CAS 争用的激烈程度。JUC 中非常重要的基础类 **AQS(抽象队列同步器)**就是这么做的.
只能保证一个共享变量的原子操作。一个比较简单的规避方法为:把多个共享变量合并成一个共享变量来操作。 JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,可以把多个变量放在一个 AtomicReference 实例后再进行 CAS 操作。比如有两个共享变量 i=1、j=2,可以将二者合并成一个对象,然后用 CAS 来操作该合并对象的 AtomicReference 引用。
20、解决ABA问题
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
20.1、AtomicStampReference 的构造器:
/**
* @param initialRef初始引用
* @param initialStamp初始戳记
*/
AtomicStampedReference(V initialRef, int initialStamp)20.2、AtomicStampReference 的常用方法:
public class CASDemo {
public static void main(String[] args) {
//integer默认缓存-128->127,超过这个范围就要new对象了,就会分配新的地址,
// compareAndSet源码是expectedStamp == current.stamp,如果实在缓存范围之内就地址值相同int 2022与2023地址值不相同
// 在比较之前我们手动创建一个int对象让堆里面存在对象这个地址,对比的就是两个对象的引用地址
Integer i = new Integer(2023);
Integer o = new Integer(2024);
boolean state = false;
//设置一个初始值-(一般为对象)和初始版本号
AtomicStampedReference<Integer> atomicStampedReference = new AtomicStampedReference<Integer>(i, 0);
//获取最新版本号
int stamp = atomicStampedReference.getStamp();
//(期望值,更新值,版本号,版本号+1)
state = atomicStampedReference.compareAndSet(i, o, stamp, stamp + 1);
System.out.println("是否更新成功:" + state + ";更新值:" + "" + atomicStampedReference.getReference() + ";版本号:" + atomicStampedReference.getStamp());
//是否更新成功:true;更新值:2024;版本号:1
//修改印戳,更新失败
stamp = 0;
state = atomicStampedReference.compareAndSet(o, i, stamp, stamp + 1);
System.out.println("是否更新成功:" + state + ";更新值:" + "" + atomicStampedReference.getReference() + ";版本号:" + atomicStampedReference.getStamp());
//是否更新成功:false;更新值:2024;版本号:1
}
}Integer缓存问题

21、各种锁的理解
lock、synchronized默认都是可重入锁,非公平锁
21.1、公平锁和非公平锁
公平锁:非常公平,不能够插队,必须先来后到!
非公平锁:非常不公平,可以插队(默认都是非公平)
//ReentrantLock()有参调用公平锁,无参调用非公平锁
public ReentrantLock {
sync = new Nonfairsync(); //默认非公平
}
public ReentrantLock(boolean fair) {
sync = fair ? new Fairsync() : new Nonfairsynco; //如果为true则设置为公平锁21.2、可重入锁
解释一:可重入锁也就是某个线程已经获得某个锁,可以再次获取锁而不会出现死锁
解释二:可重入锁又称递归锁,是指同一个线程在外层方法获取锁的时候,再进入该线程的**内层方法会自动获取锁(**前提是锁对象得是同一个对象),不会因为之前已经获取过锁还没有释放而阻塞。
可重入锁是某个线程已经获得某个锁,可以再次获取锁而不会出现死锁。再次获取锁的时候会判断当前线程是否是已经加锁的线程,如果是对锁的次数+1,释放锁的时候加了几次锁,就需要释放几次锁。
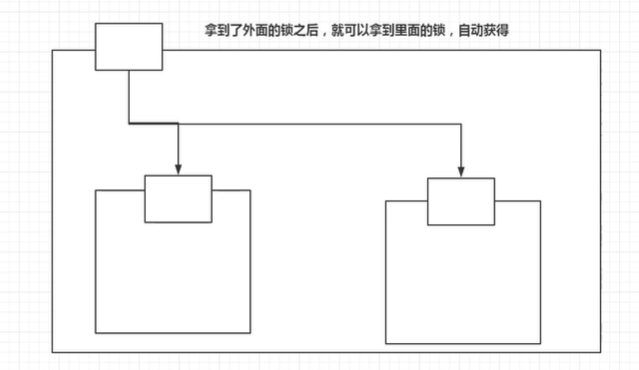
0
Synchronized 锁
package com.sjmp.demo21Lock;
public class SynchronizedDemo {
public static void main(String[] args) {
Phone phone = new Phone();
new Thread(()->{
phone.sms();
},"A").start();
new Thread(()->{
phone.sms();
},"B").start();
}
}
class Phone{
public synchronized void sms(){
System.out.println(Thread.currentThread().getName()+"=> sms");
call();// 这里也有一把锁
}
public synchronized void call(){
System.out.println(Thread.currentThread().getName()+"=> call");
}
}
2.Lock锁
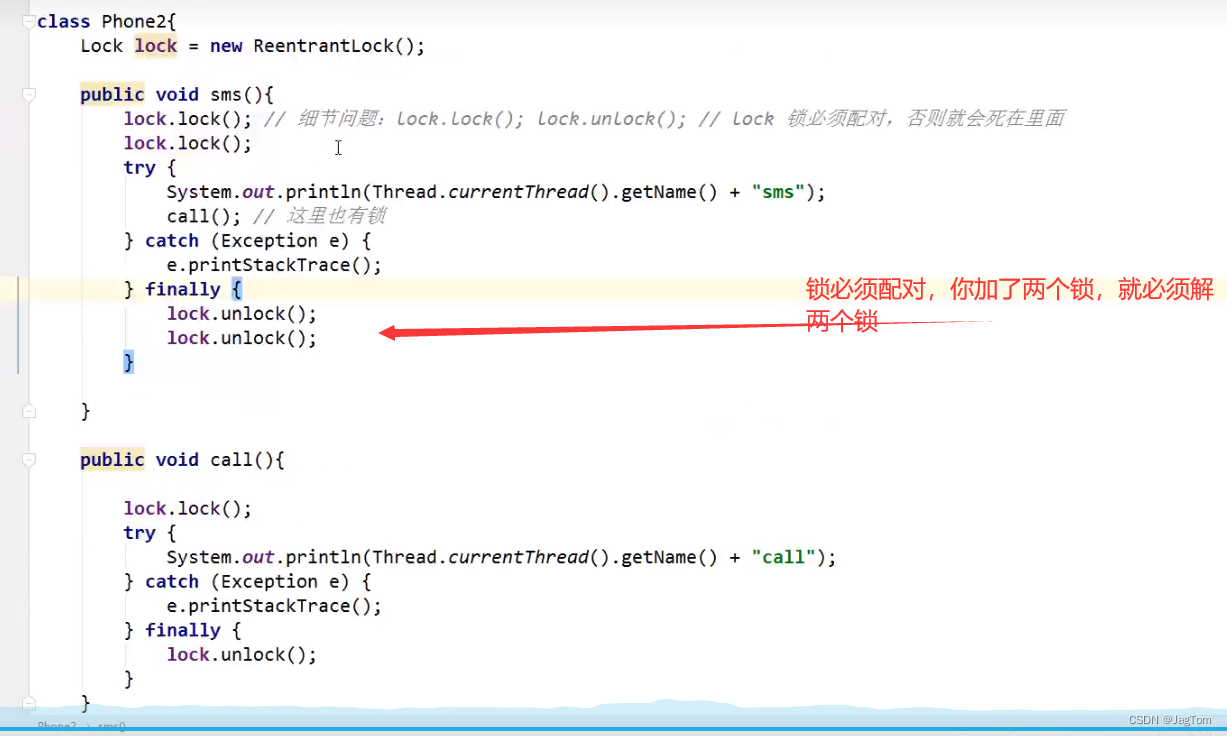
21.3、自旋锁
1.spinlock
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}2.自定义自旋锁
public class TestSpinLock {
// 默认
// int 0
//thread null
AtomicReference<Thread> atomicReference=new AtomicReference<>();
//加锁
public void myLock(){
Thread thread = Thread.currentThread();
System.out.println(thread.getName()+"===> mylock加锁");
//自旋锁
while (!atomicReference.compareAndSet(null,thread)){
System.out.println(Thread.currentThread().getName()+" ==> 自旋中~");
}
}
//解锁
public void myUnlock(){
Thread thread=Thread.currentThread();
System.out.println(thread.getName()+"===> myUnlock解锁");
atomicReference.compareAndSet(thread,null);
}
}测试自定义自旋锁
public class SpinlockDemo {
public static void main(String[] args) throws InterruptedException {
//使用CAS实现自旋锁
TestSpinLock spinlockDemo=new TestSpinLock();
new Thread(()->{
spinlockDemo.myLock();
try {
TimeUnit.SECONDS.sleep(3);
} catch (Exception e) {
e.printStackTrace();
} finally {
spinlockDemo.myUnlock();
}
},"t1").start();
//T1 T2 拿到的锁的是同一个对象spinlockDemo,所以在同一个时间内只能有一把锁
//T1先拿到锁后休眠3(sleep)秒钟,但不释放锁(atomicreference)
//T2 过了1秒钟后开启线程,发现锁(tomicreference)被T1占用了,所以一直自旋等待拿锁.
//T1 3秒休眠之后释放锁,T2拿到了锁结束自旋(自旋时长2秒)
//T2 拿到锁,休眠3秒后解锁,程序结束
TimeUnit.SECONDS.sleep(1);
new Thread(()->{
spinlockDemo.myLock();
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
} finally {
spinlockDemo.myUnlock();
}
},"t2").start();
}
}测试结果
t1===> mylock加锁
t1===> myUnlock解锁
t2 ==> 自旋中~ (两秒)
t2===> mylock加锁
t2===> myUnlock解锁22、死锁
死锁产生的原因
互斥条件:一个资源只能被一个线程占有,当这个资源被占有后其他线程就只能等待
不可剥夺条件:当一个线程不主动释放资源时,此资源一直被拥有线程占有
请求并持有条件:线程已经拥有了一个资源后,又尝试请求新的资源
循环等待条件:产生死锁一定是发生了线程资源环形链
package com.ogj.lock;
import java.util.concurrent.TimeUnit;
public class DeadLock {
public static void main(String[] args) {
String lockA= "lockA";
String lockB= "lockB";
new Thread(new MyThread(lockA,lockB),"t1").start();
new Thread(new MyThread(lockB,lockA),"t2").start();
}
}
class MyThread implements Runnable{
private String lockA;
private String lockB;
public MyThread(String lockA, String lockB) {
this.lockA = lockA;
this.lockB = lockB;
}
//T1x线程拿到A想要B,但是此时T2拿到B想要A,两个人都不放下锁的但是都要获取对方的锁,造成死锁
@Override
public void run() {
synchronized (lockA){
System.out.println(Thread.currentThread().getName()+" lock"+lockA+"===>get"+lockB);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lockB){
System.out.println(Thread.currentThread().getName()+" lock"+lockB+"===>get"+lockA);
}
}
}
}
如何解开死锁
死锁状态下
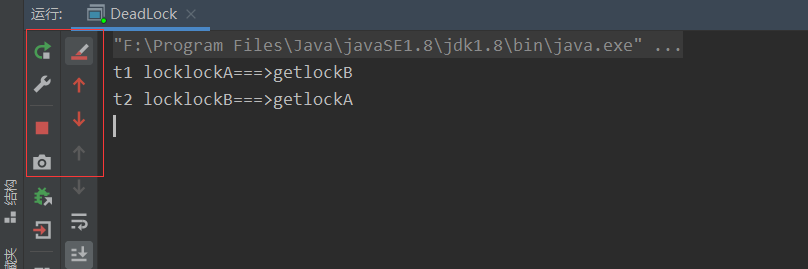
使用 jps 定位进程号,jdk 目录 bin 下 :有一个 jps
命令: jps -l
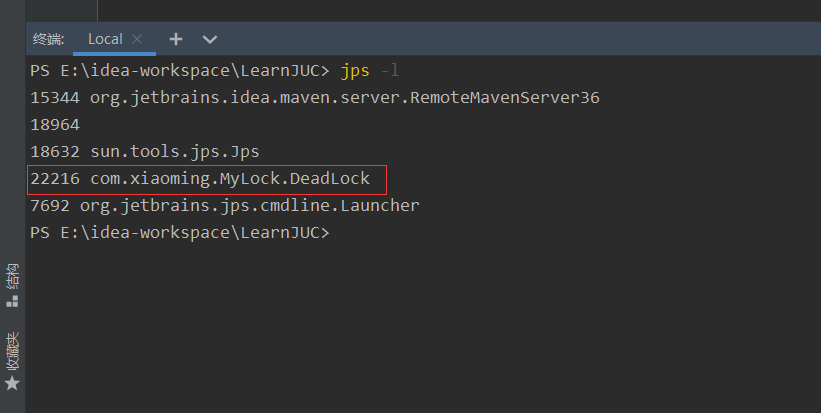
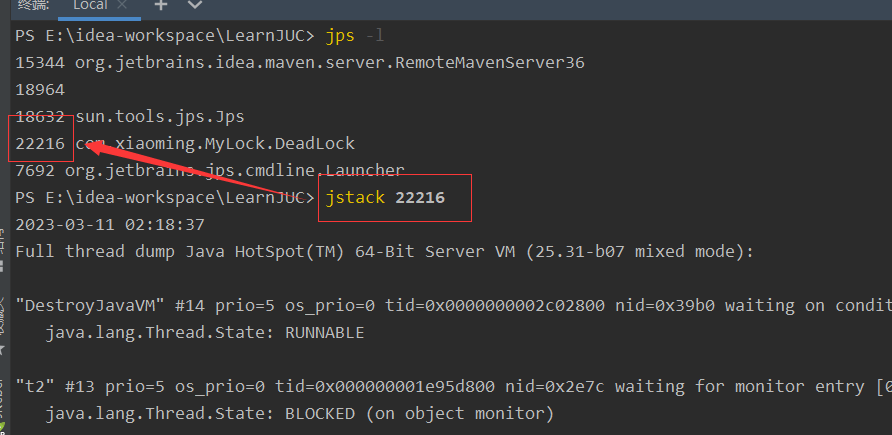
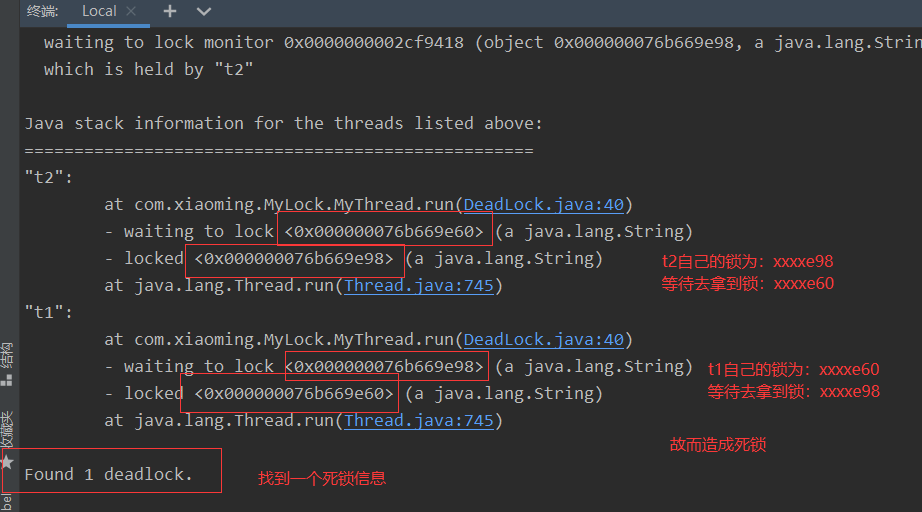
使用 jstack 进程进程号找到死锁信息
命令:jstack 进程号















 2153
2153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









