






因为MySQL不支持在查询的同时进行更新的操作,所以网上很多方法都不可以用。
笔者提供两种删除重复数据的方法:
1、通过创建一个中间表的方式,先将不重复数据存入新表,再将重复数据选其中一行存入新表。(旧表数据顺序会改变)
2、在代码上加一层封装,将旧表数据除自增字段外,存入新表。(旧表数据顺序布标)
目标:将test表中重复的数据删除
方法一:
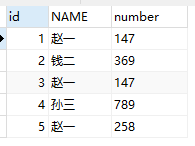
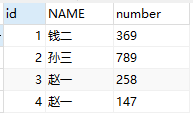
1、新建一个test表,并插入测试数据。(规定:名字和号码都相同的数据为重复数据,表中的号码是不重复的)
###删除表中重复数据###
#新建一个test表,表中有重复的和不重复的数据
CREATE TABLE test ( id INT ( 5 ) auto_increment NOT NULL PRIMARY KEY, NAME VARCHAR ( 10 ), number VARCHAR ( 10 ) );
INSERT INTO test ( NAME, number )
VALUES
( '赵一', '147' ),
( '钱二', '369' ),
( '赵一', '147' ),
( '孙三', '789' ),
( '赵一', '258' );
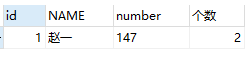
2、查找name和number都相同的数据
#查看name和number都重复的数据个数
SELECT
*,
count( NAME ) AS 个数
FROM
test
GROUP BY
NAME,
number
HAVING
count( NAME ) > 1;
#查看所有name和number都重复的数据内容
SELECT
*
FROM
test
WHERE
NAME IN ( SELECT NAME FROM test GROUP BY NAME HAVING count( NAME ) > 1 )
AND number IN ( SELECT number FROM test GROUP BY number HAVING count( number ) > 1 );
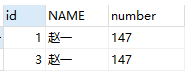
表中有两个名字和编号都相同的数据,现在需要删除一个,留一个。
3、创建中间表
#创建一个与原表结构一样的新表
CREATE TABLE test_tmp LIKE test;
4、把不重复的数据存入新表
ALTER TABLE test_tmp auto_increment = 1;
INSERT INTO test_tmp (NAME , number )
SELECT NAME , number
FROM
test
WHERE
number IN ( SELECT number FROM test GROUP BY number HAVING count( number ) = 1 );
ALTER TABLE test_tmp auto_increment = 1;
此语句的作用是保证每一次插入数据,自增字段都能保持连续性。
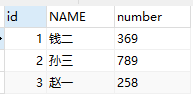
5、在重复数据中筛选所需的那一行数据(此处选择id小的那行数据),存入新表
ALTER TABLE test_tmp auto_increment = 1;
INSERT INTO test_tmp ( NAME, number )
SELECT NAME,number
FROM
test
WHERE
NAME IN ( SELECT NAME FROM test GROUP BY NAME HAVING count( NAME ) > 1 )
AND id IN ( SELECT min( id ) FROM test GROUP BY NAME HAVING count( NAME ) > 1 );
完成重复数据的删除。
方法二:
1、在代码上加一层封装,直接在原表中进行删除操作。
DELETE
FROM
test
WHERE
NAME IN ( SELECT NAME FROM ( SELECT NAME FROM test GROUP BY NAME HAVING count( NAME ) > 1 ) a )
AND number IN ( SELECT number FROM ( SELECT number FROM test GROUP BY number HAVING count( number ) > 1 ) b )
AND id NOT IN (
SELECT
min( id )
FROM
( SELECT min( id ) AS id FROM test GROUP BY NAME HAVING count( NAME ) > 1 ) c
);
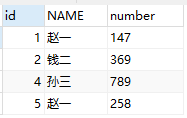
因为MySQL不允许在同一个表上,同时查询并更新,这样会进入死锁状态。所以我们把查询的表格更改成了我们在内存中新建的a、b、c三个新表,这样我们就没有从原来的test表里进行查询,只是进行了删除操作。以最后一行代码为例,我们是从test表中delete的,同时是从c表中select的。写的再清楚一点就是:
SELECT
min( id )
FROM
( SELECT min( id ) AS id FROM test GROUP BY NAME HAVING count( NAME ) > 1 ) AS c
);
表test是在磁盘里的,而a、b、c表是在内存中的,运行结束就释放了。
此时自增字段id是断的。
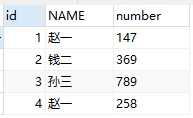
2、将处理过的旧表,除自增字段外,存入新表。
CREATE TABLE test_tmp LIKE test;
ALTER TABLE test_tmp auto_increment = 1;
INSERT INTO test_tmp ( NAME, number )
SELECT NAME,number
FROM
test;
这样,依旧保持了旧表中数据的顺序,并刷新了自增字段。
第二行代码可以写成:
ALTER TABLE test_tmp auto_increment = n;
n表示你希望自增字段开始的值。
在MySQL中删除重复数据的两种方法介绍完毕,恳请大家批评指正。















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









