







本文内容:
- 什么是分布式事务
- 事务的正确性--Serializable
- 并发控制,两阶段锁
- 原子提交,两阶段提交协议
- 崩溃恢复
- 消息丢失
- 总结
什么是分布式事务
假设数据被存在在不同的计算机上,有个事务需要操作存储在多个计算机上的数据,需要让这些操作全部完成或者全部失败(All-or-None),那么这就是一个分布式事务,它可以视作包含执行在不同服务器上的多个事务
事务的正确性--Serializable
在谈及分布式事务的策略时,需要先定义下在考虑多个并发行为的前提下 对于分布式事务 什么才是正确的行为
这里用Serializable来作为标准,如果满足Serializable的分布式事务定义如下
- 如果分布式事务的执行结果,与任何一个这些组成分布式事务的事务的线性顺序执行结果相同,则正确
- 举例:
- 假设分布式事务T包含有事务T1,T2
- 如果T的执行结果与 先执行完T1,再执行完T2 或者反过来结果一致,则它是Serializable的
- 注意:按照这个定义,一个分布式事务有许多合法的执行结果
并发控制
悲观策略:操作数据前加锁
- 两阶段锁
- 在读,写数据前必须获取锁
- 事务提交或放弃时释放所有锁
乐观策略:先操作数据,最后再检测自己执行期间有无其他事务也操作了相同的数据,没有就提交,否则abort(取消)
原子提交
保证多个计算机执行的子任务同时提交或失败
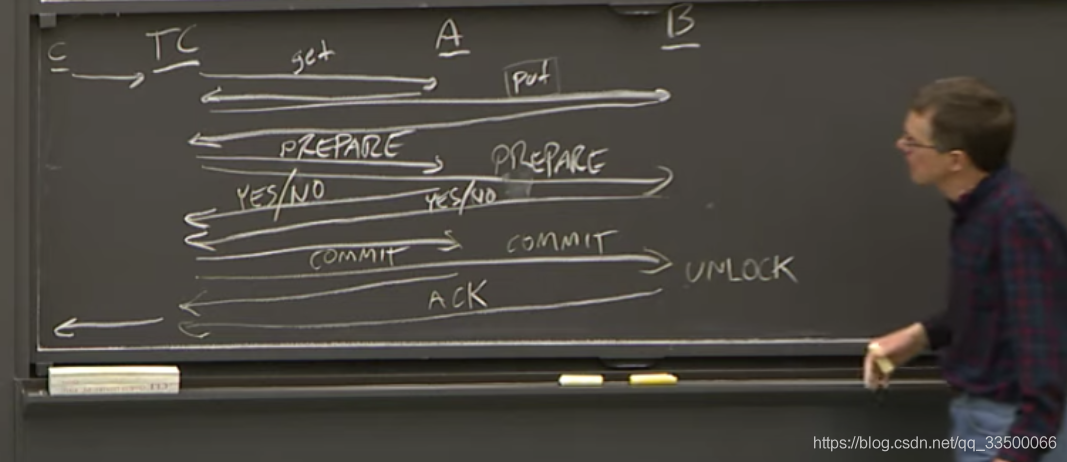
两阶段提交协议
- PC(Particpants):存储数据,对数据执行操作
- TC(Transaction Coordinator):
- 发送执行操作给存储数据的计算机
- 发送相关msg来检测PC是否完成操作、提交、失败
执行流程示例:
- client请TC执行分布式事务
- TC发送命令给PC
- PC执行命令
- TC发送prepare msg给PC,询问它们是否能完成事务(有无遇到无法操作、死锁等)
- PC回复yes/no
- TC收到全部PC回yes,决定commit
- 发送commit给TC,回复client事务已提交
- TC commit,unlock
- 若存在no,则发送abort给TC,撤销
这些msg保证了所有server都能完成commit时才进行commit,否则就abort全部撤销,符合All-or-None原子提交
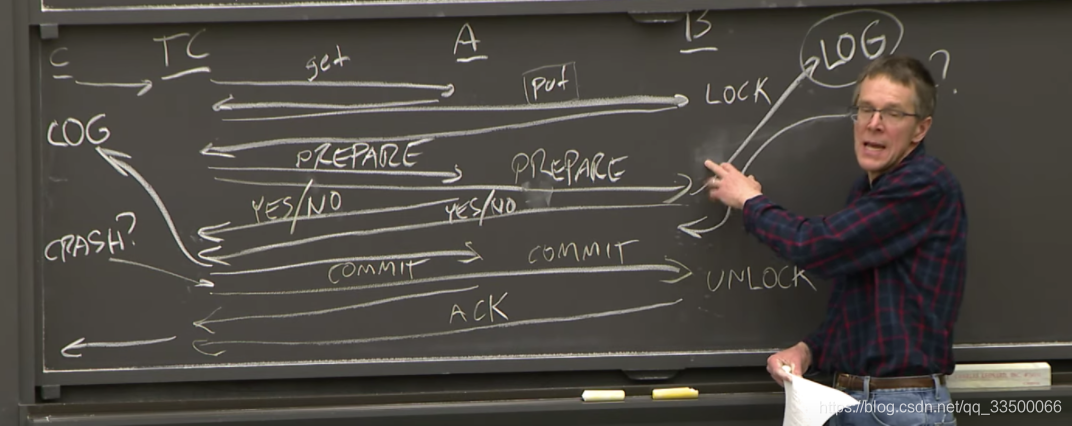
崩溃恢复
PC的三种可能崩溃场景:
- 在响应prepare msg前崩溃
- 重启后错过prepare msg
- 重启后收到prepare msg,不记得于是发no
- 在响应prepare msg后崩溃
- 这里有可能它发了yes,导致事务commit,所以这里不能abort,必须恢复
- 导致它得在响应前将事务状态写入磁盘的log,这样恢复后检查log,收到commit时正常处理
- 在commit后崩溃
- 已经commit了
TC的两种可能崩溃场景:
- 在commit前 => 收到prepare响应时已经不知道该事务了,直接abort
- 在commit后 => 已经commit,必须恢复,在收到所有PC的yes后,将事务状态写入磁盘的log里,重发commit(PC需要在磁盘存已commit的事务,处理重复commit msg)
消息丢失
- prepare respond丢失,TC设置timeout,到点就全部abort(因为要不然PC一直持有锁,影响其他事务)
- prepare msg丢失,PC设置timeout,直接abort,如果PC重启,再收到prepare msg,回no
- TC发的commit msg丢失,block,PC无限期等待(因为有可能TC已经commit了,其他事务已经看到有些服务器commit的数据了)
总结
该协议能实现原子提交的根本在于TC,即单个实体来作决策,要么commit要么abort,这也导致了block问题(PC等待TC的决策)
删除log,当PC收到commit,TC收到所有PC的ACK后可以删除自己当前事务的log了
两阶段提交协议的问题:慢
- 因为有多轮msg的交互
- 磁盘写(log)
- block问题
且不具备可用性,只要crashed就会导致长时间等待,所以考虑引入raft增强可用性














 52
52











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









