







分析目标

作为当时最豪华的游轮之一,泰坦尼克号的处女航也是当时人们关注的一个话题,所有人都期待着这艘船能够往返于大洋,但没想到,这一次的处女航,1500多人永远的沉睡在海底。
假如你灵魂穿越,作为一名泰坦尼克号的乘客,你能预测自己获救的概率吗?
- 描述泰坦尼克号乘客数据集特点
- 泰坦尼克号乘客数据描述性统计分析
- 探索分析泰坦尼克号乘客生存概率与乘客属性之间的关系
- 通过探索性分析,确定建模需要的特征值,并进行特征值处理
- 通过数据建模,预测泰坦尼克号乘客的生存情况
目录
- 泰坦尼克号乘客数据描述统计分析
- 探索性分析乘客的各个特征与其生存概率之间的关系,并确定模型特征值
- 特征工程
- 建模
- 总结
1.数据描述统计分析
train_df = pd.read_csv(r'D:\数据文件\泰坦尼克号\train.csv')
test_df = pd.read_csv(r'D:\数据文件\泰坦尼克号\test.csv')
#将两个数据集组合在一起,方便之后的操作
combine = [train_df, test_df]
print(train_df.info())
print('*'*40)
print(test_df.info())
查看数据集中的缺失值
- 在train_df数据集中age、cabin,embarked三列数据有缺失值,需要处理
- 在test_df数据集中age、cabin、fare有缺失值,需要处理
- 数据集中,浮点数,整型,object对象都存在
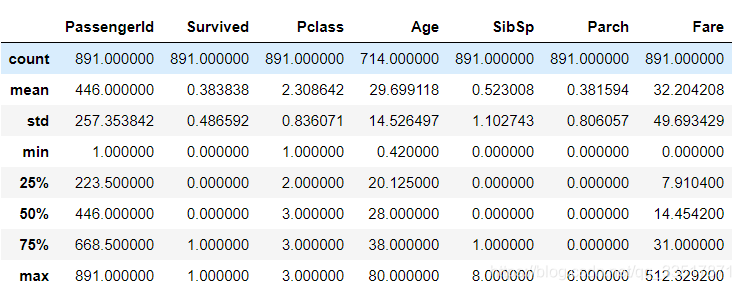
#查看数据集中数值特征的描述性统计
train_df.describe()
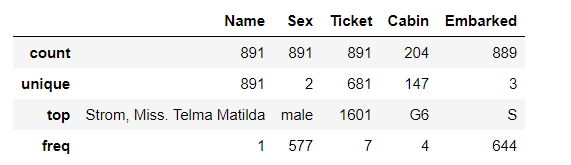
#查看数据集中分类列的描述性统计
train_df.describe(include=['O'])
数据集描述统计分析
- 乘客中,获救人数还不到40%
- 乘客中以3等级的人居多
- 乘客中大多数人都是30岁左右的青壮年,年龄分布稍微向年龄小的方向偏移
- 大多数人都是独自出门旅游
- 船票票价平均32一张,但船票价格波动很大
- 乘客中男性乘客更多,接近三分之二
- 乘客登船港口多数为S港口
2. 探索性分析
- 性别与获救概率的关系(sex)
- 年龄与获救概率的关系(age)
- 社会地位与获救概率的关系(pclass)
- 家庭关系与获救概率的关系(sibsp parch)
- 登船港口(embarked)
- 多个特征与获救概率的关系
社会地位-pclass与乘客获救关系
plt.figure(figsize=(10,4))
plt.subplot(121)
train_df.groupby('Pclass')['Survived'].mean().plot.barh()
plt.title('各社会地位获救概率')
plt.xlabel('获救概率')
plt.subplot(122)
train_df.groupby(['Pclass']).size().plot.barh()
plt.title('各社会地位人数')
plt.xlabel('人数')
plt.show()
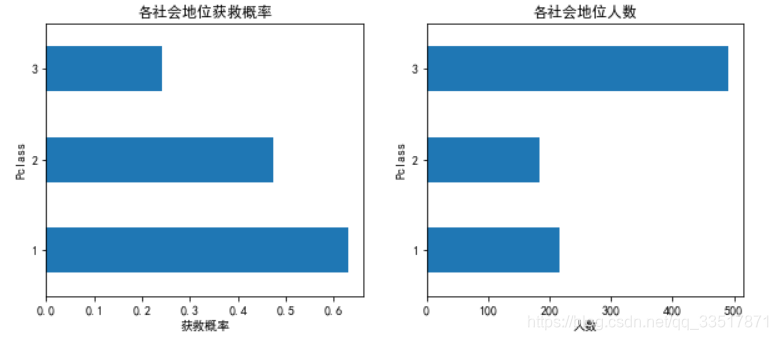
- 社会地位从1-3,数字越大社会地位越低.
- 从图中可看出,乘客中3等级的乘客数量最多,但其获救率最小,1社会等级乘客有最高的获救概率,可以看出pclass对生存有较大影响,因此加入特征值。
乘客社会地位、性别与生存概率的关系
sns.barplot(y='Survived',x='Pclass',hue='Sex',data=train_df)
plt.ylabel('Survived Probability')
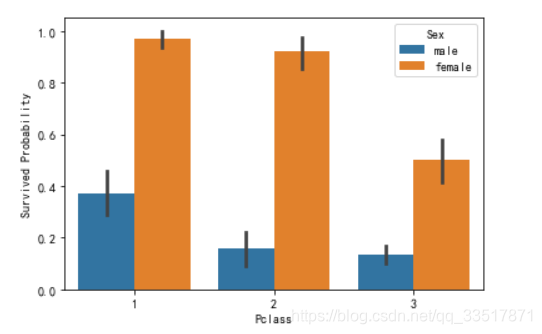
- 每个等级乘客中女性获救概率普遍高于男性
- 在pclass=1时,男性获救概率最高
- 考虑将age作为特征值加入模型
查看获救乘客与未获救乘客年龄的分布情况
g = sns.FacetGrid(train_df,col='Survived')
g.map(plt.hist,'Age',bins=20)
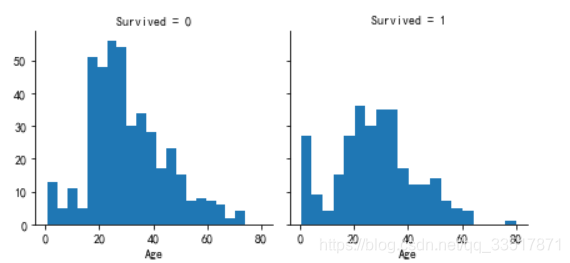
- 0-4岁年龄的乘客有更高的获救概率
- 大部分乘客年龄在15-40岁之间
- 很多15-25岁的乘客没有获救
- 80岁的最老的老人活下来了
家庭关系与获救概率的关系
train_df.groupby('SibSp')['Survived'].mean().reset_index()
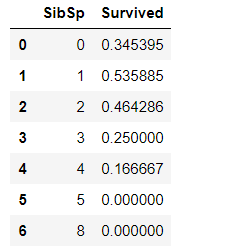
train_df.groupby('Parch')['Survived'].mean().reset_index()

- 乘客的家庭关系,也会影响其生存的概率,一个家庭在船上的成员数量在1-3之间,其生存概率最高
查看乘客年龄age在不同的社会地位中,以及获救与为获救中的分布
g = sns.FacetGrid(train_df,col='Survived',row='Pclass',size=2.2, aspect=1.6)
g.map(plt.hist,'Age',bins=20)
g.add_legend()
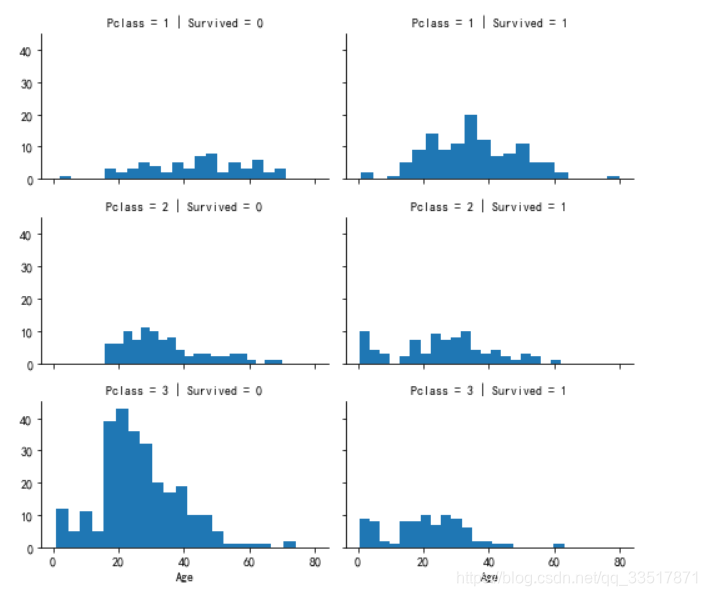
- pclass=1 的乘客在全年龄段都有着较高的获救概率,甚至80岁的老人也得救了
- 在pclass=2、3的乘客中,孩子的获救概率最高,其次获救乘客主要为15-30多岁的中青年人
各个登船港口与性别、获救概率的关系
sns.barplot(x='Embarked',y='Survived',hue='Sex',data=train_df)
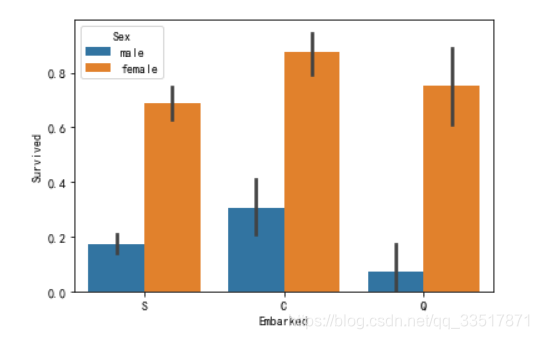
- C登船港口有更高的获救概率
- 考虑加登船港口加入特征值
船票价格与是否获救的关系
g = sns.FacetGrid(train_df,col='Survived',row='Embarked',size=2.2, aspect=1.6) #构造网格
g.map(sns.barplot,'Sex','Fare',ci=None) #确定图表类型,横坐标,纵坐标等
g.add_legend()
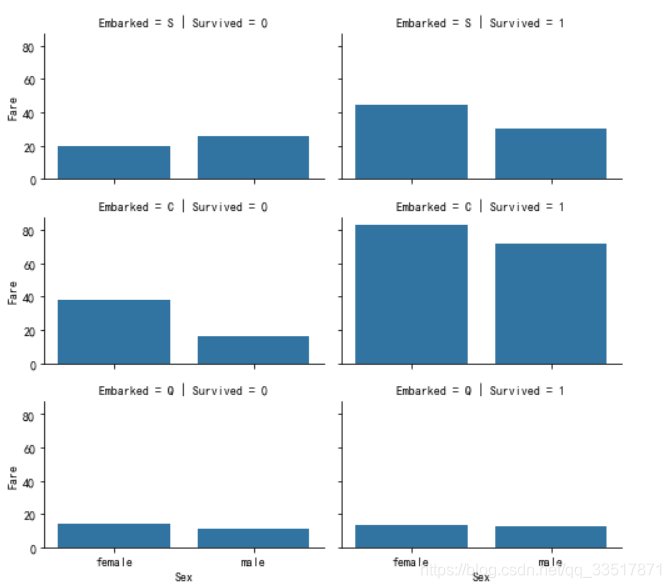
- 船票价格越高,获救的概率似乎越大,而刚好,C登船港口是获救概率最高的港口,其获救概率似乎也不错
探索性分析总结:
- 泰坦尼克号乘客的性别、年龄、社会地位,家庭关系等都会对其生存概率产生影响,并将这些特征作为之后的处理内容。
- 男性生存概率远低于女性
- 社会地位越高的乘客生存概率越高
- 家庭关系也会影响乘客的获救概率,有1-3人出行乘客,获救概率更高
3. 特征工程(数据处理)
将各种特征值中的字符型数据转换为数值型数据,并对某些波动较大的数据如年龄、船票价格等做相应的数据转换处理。
删除一些不需要的特征值
print('删除前:',train_df.shape,test_df.shape,combine[0].shape, combine[1].shape)
train_df.drop(['PassengerId','Name','Ticket','Cabin'],axis=1,inplace=True)
test_df.drop(['Name','Ticket','Cabin'],axis=1,inplace=True)
print('删除后:',train_df.shape,test_df.shape,combine[0].shape, combine[1].shape)
乘客性别数据转换
#将性别数据转换为0,1,0代表女性,1代表男性
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
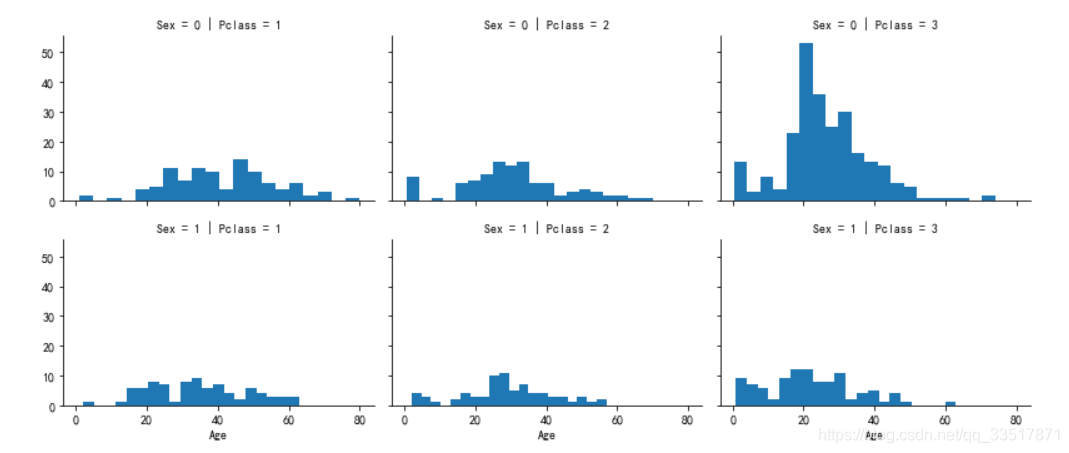
年龄缺失值填充
处理年龄缺失值时,观察年龄与性别、社会地位等关系,根据这两个维度,将乘客年龄划分为六个不同的年龄区间,用六个区间的年龄中位数去填充对应的缺失值
g = sns.FacetGrid(train_df,col='Pclass',row='Sex',size=2.5,aspect=1.5)
g.map(plt.hist,'Age',bins=20)
g.add_legend()
guess_ages = np.zeros((2,3))
for dataset in combine:
for i in range(0,2):
for j in range(0,3):
#按照sex、pclass将年龄分成六个组
guess_df = dataset[(dataset['Sex']==i)&(dataset['Pclass']==j+1)]['Age'].dropna()
age_guess = guess_df.median()
#转换年龄
guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
#对缺失的年龄的值进行填充
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),'Age'] = guess_ages[i,j]
dataset['Age'] = dataset['Age'].astype(int)
#年龄数据离散化
train_df['AgeBand'] = pd.cut(train_df['Age'],5)
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32),'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48),'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64),'Age'] = 3
dataset.loc[(dataset['Age'] > 64) & (dataset['Age'] <= 80),'Age'] = 4
train_df.drop('AgeBand',axis=1,inplace=True)
combine = [train_df,test_df]
train_df.head()

# 对乘客的家庭关系进行处理,新建家庭大小数据
for dataset in combine:
dataset['Familysize'] = dataset['SibSp'] + dataset['Parch'] + 1
for data in combine:
data['Isalone'] = 0 #0代表不是单独一人
data.loc[data['Familysize'] == 1,'Isalone'] = 1
#删除sibsp,parch
train_df.drop(['SibSp','Parch','Familysize'],axis=1,inplace=True)
test_df.drop(['SibSp','Parch','Familysize'],axis=1,inplace=True)
combine = [train_df,test_df]
#对登船港口缺失值填充,对测试数据集中的船票缺失值填充
train_df.Embarked.fillna('S',inplace=True)
test_df.Fare.fillna(13.6,inplace=True) # 13.6为pclass=3的乘客的船票均值
combine = [train_df,test_df]
#对登船港口进行数值转换
for data in combine:
data['Embarked'] = data['Embarked'].map({'S':1,'C':2,'Q':3}).astype(int)
train_df.head()
#对船票价格离散化
train_df['Fareband'] = pd.qcut(train_df['Fare'],4)
for data in combine:
data.loc[data['Fare'] <= 7.91,'Fare'] = 0
data.loc[(data['Fare'] > 7.91) & (data['Fare'] <= 14.454),'Fare'] = 1
data.loc[(data['Fare'] > 14.454) & (data['Fare'] <= 31.0),'Fare'] = 2
data.loc[data['Fare'] > 31.0,'Fare'] = 3
data['Fare'] = train_df['Fare'].astype(int)
train_df.drop(['Fareband'],axis=1,inplace=True)
train_df.head()
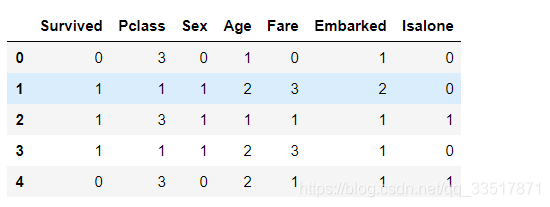
- 特征值的数据处理就暂时完成,通过对特征值的数据进行处理,使得数据集内,只有数值型数据,没有字符型数据,同时,尽量减小数值型数据的波动,可以将数据离散化或者归一化,此处采用离散化。
4. 建模
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor
#构造x变量,y变量,x测试集
x_train = train_df.drop('Survived',axis=1)
y_train = train_df['Survived']
x_test = test_df.drop('PassengerId',axis=1)
#构造逻辑回归模型
lg = LogisticRegression()
model_lg = lg.fit(x_train,y_train)
y_pred = model_lg.predict(x_test)
#交叉检验
scores_lg = -cross_val_score(lg,x_train,y_train,cv=10,scoring='neg_mean_absolute_error')
1-np.mean(scores_lg)
#结果为0.7890205425036886
#随机森林模型
rf = RandomForestClassifier(50)
rf.fit(x_train,y_train)
y_pred_rf = rf.predict(x_test)
scores_rf = -cross_val_score(rf,x_train,y_train,cv=10,scoring='neg_mean_absolute_error')
#结果为:0.80
#K近邻模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3,weights='uniform')
knn.fit(x_train,y_train)
y_pred = knn.predict(x_test)
scores_knn = -cross_val_score(knn,x_train,y_train,
cv=10,scoring='neg_mean_absolute_error')
np.mean(scores_knn)
#结果为:0.79
#决策树模型
dt = DecisionTreeClassifier()
dt.fit(x_train,y_train)
y_pred = dt.predict(x_test)
scores_dt = -cross_val_score(dt,x_train,y_train,
cv=10,scoring='neg_mean_absolute_error')
np.mean(scores_dt )
#结果为:0.81
- 通过对几个模型交叉检验的得分进行比较,最终选取决策树模型,并将结果导出。
5.总结
- 主要针对泰坦尼克号乘客数据进行可视化探索分析与数据处理,数据建模以及模型优化还需要加强














 1645
1645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









