




 本文围绕MySQL的MVCC机制展开,介绍其在可重复读和读已提交隔离级别下的应用。阐述了undo日志版本链,即由事务修改数据后保留的undo回滚日志串联而成;read - view一致性视图的组成;undo版本链比对机制及规则;还梳理了MVCC获取值的全流程,解释了事务查询结果一致的原因。
本文围绕MySQL的MVCC机制展开,介绍其在可重复读和读已提交隔离级别下的应用。阐述了undo日志版本链,即由事务修改数据后保留的undo回滚日志串联而成;read - view一致性视图的组成;undo版本链比对机制及规则;还梳理了MVCC获取值的全流程,解释了事务查询结果一致的原因。
文章目录
前言
最近在梳理自己的知识点,发现MVCC这一块理解不太深刻,去网站上查询了下,也没看到容易理解的,所以有了这篇文章,通过模拟多个事务执行,清晰的可以看见每一步执行步骤,可以清晰的对MVCC有个深刻认识。
什么是MVCC?
Mysql在可重复读这个隔离性就是靠MVCC(Multi-Version Concurrency Control)机制来保证的,对一行数据的读和写两个操作默认是不会通过加锁互斥来保证隔离性,避免了频繁加锁互斥;
而在串行化隔离级别为了保证较高的隔离性是通过将所有操作加锁互斥来实现的。
Mysql在读已提交和可重复读隔离级别下都实现了MVCC机制。
一、undo日志版本链
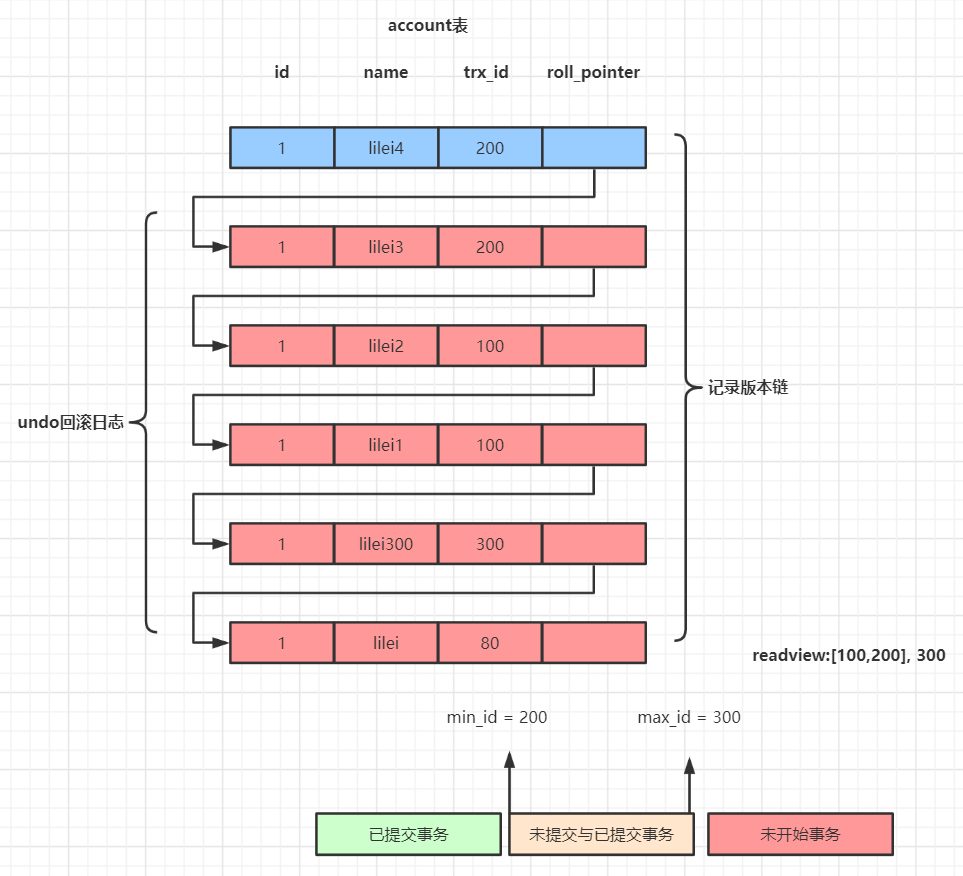
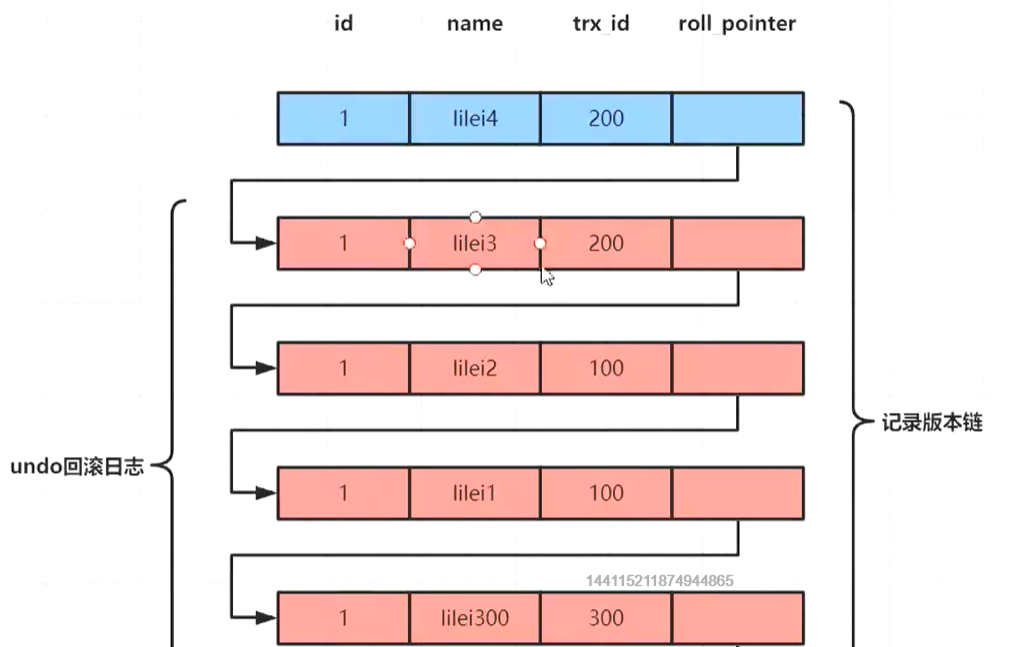
undo日志版本链是指一行数据被多个事务依次修改过后,在每个事务修改完后,Mysql会保留修改前的数据undo回滚日志,并且用两个**隐藏字段trx_id(事务ID)和roll_pointer(指针)**把这些undo日志,串联起来形成一个历史记录版本链;
PS:
事务id trx_id:挨个递增生成,图上是为了显目一点随便写的
指针roll_pointer :指向老数据,同一个数据,多次处理,每次处理的回滚日志的指针都会指向老的那个日志
简单理解就是undo日志版本链其实就是undo回滚日志的集合。
下图是一个undo日志版本链案例
案例解析

mysql依次开启了3个事务,有3个不同的事务id编号(这里的3条sql操作没有关系,不用在意)
并且后面还有一个查询sql(划重点)
这个sql会创建一个read VIew 一致性视图
二、read-view一致性视图
在可重复读隔离级别,当事务开启、执行任何查询sql时会生成当前事务的一致性视图read-view;
该视图在事务结束之前都不会变化(如果是读已提交隔离级别在每次执行查询sql时都会重新生成);
2.1、read-view视图的组成
由执行查询时生成,所有未提交事务id数组(数组里最小的id为min_id)和已创建的最大事务id(max_id)组成,事务里的任何sql查询结果、需要从对应版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果。
结合上面的图来理解如何组成:
上面3个update,2个事务未提交,紧跟着在进行一个select,然后就生成了一致性视图
事务ID100和200 组成 未提交的id数组,已经提交的事务id是300
数组里最小的是100,所以min_id是100,max_id是300
可能会有个疑问
这时候查询上面那个account表 他的结果是lilei300
为什么是lilei300 ,其实是内部有一个undo版本链的比对规则,带着这个疑问往下看
下图来个案例解析
下图可以看见有一张account表,每一行字段有id和name,隐藏字段trx_id(事务ID)和roll_pointer(指针,指向修改前的那一条数据);
三、undo版本链比对机制
通过上面得知:
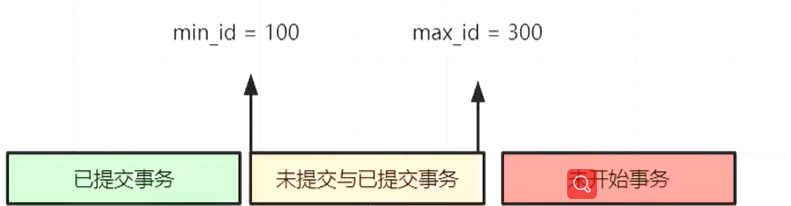
事务数组里最小的是100,所以min_id是100,max_id是300
mysql会根据undo版本链生成3个区间用于比对
绿色:
已经提交事务
小于100的不出意外都是已经提交事务
黄色:
未提交和已经提交的事务
最小的是100,后面的事务由于是挨个依次递增,所以这里面都是 未提交和已经提交的事务
PS:但是注意,这里有一种可能 也存在小于100的在这个区间
比如在100之前,有一个事务id 80的开启了事务并且很快就commit了,也可能在黄色区间你
红色:
未开始的事务
因为最大的是max_id是300,所以大于300的 肯定都是未开始的事务
版本链比对规则:
1、 如果 row 的 trx_id 落在绿色部分( trx_id<min_id ),表示这个版本是已提交的事务生成的,这个数据是可见的;
2、 如果 row 的 trx_id 落在红色部分( trx_id>max_id ),表示这个版本是由将来启动的事务生成的,是不可见的(若 row 的 trx_id 就是当前自己的事务是可见的);
3、如果 row 的 trx_id 落在黄色部分(未提交 和 已经提交事务)(min_id <=trx_id<= max_id),那就包括两种情况
a. 若 row 的 trx_id 在视图数组中,表示这个版本是由还没提交的事务生成的,不可见
(若 row 的 trx_id 就是当前自己的事务是可见的);
b. 若 row 的 trx_id 不在视图数组中,表示这个版本是已经提交了的事务生成的,可见。
trx_id代表当前事务id
所以基于此,上面的事务id 300,所以他在黄色区间,他命中了上面 b 规则,
所以后面的查询,结果是lilei300
ps:
对于删除的情况可以认为是update的特殊情况,会将版本链上最新的数据复制一份,
然后将trx_id修改成删除操作的trx_id,同时在该条记录的头信息(record header)里的(deleted_flag)标记位写上true,来表示当前记录已经被删除,
在查询时按照上面的规则查到对应的记录如果delete_flag标记位为true,意味着记录已被删除,则不返回数据。
注意:begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个修改操作InnoDB表的语句,事务才真正启动,才会向mysql申请事务id,mysql内部是严格按照事务的启动顺序来分配事务id的。
三、MVCC获取值流程(全流程重新梳理一遍)
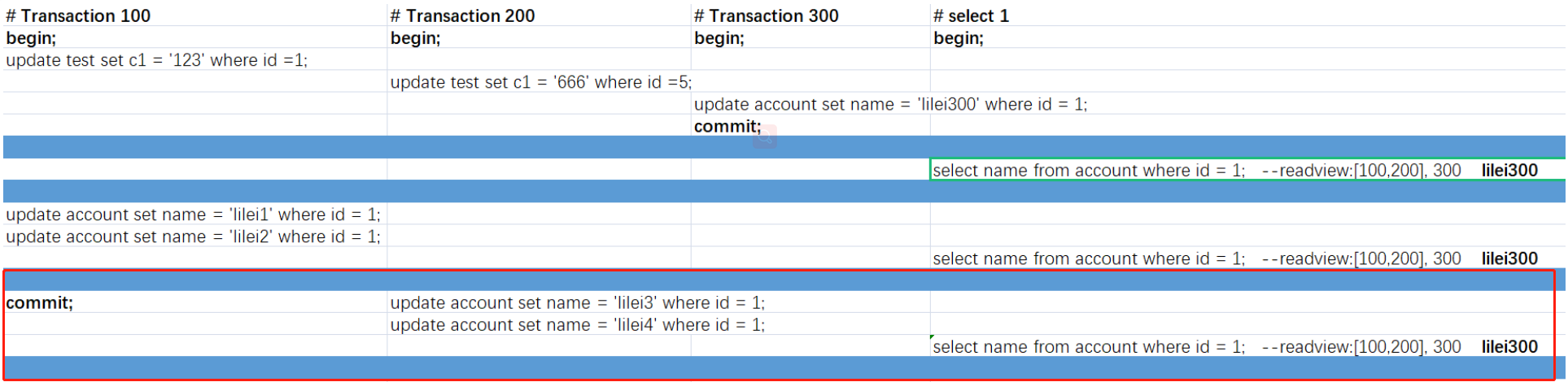
3.1、阶段1
如下图transaction100、transaction200都未提交(这2个就是未提交的事务id数组),加上transaction300已经提交的事务(最大事务id)组成;
在#select1执行查询时就会生成read-view视图;
readview包含的实际值:[100,200], 300

这里数组最小的100,也就是min_id,最大的ID,300为max_id;
下图有3个分区,mysql根据版本比对规则去匹配,拿到最终的快照;
执行下面sql,结果返回的是lilei300?为什么?
select name from account where id = 1
拿上面的sql案例解析
这里时候查询到的数据事务id是300,所以满足上面第3种情况,min_id <=trx_id<= max_id,300是最大事务id,他不在未提交的事务数组内,所以3:a不满足,所以他满足了3:b,表示已经提交了事务,是可见的,所以上面的sql查询结果是lilei300。
3.2、阶段2
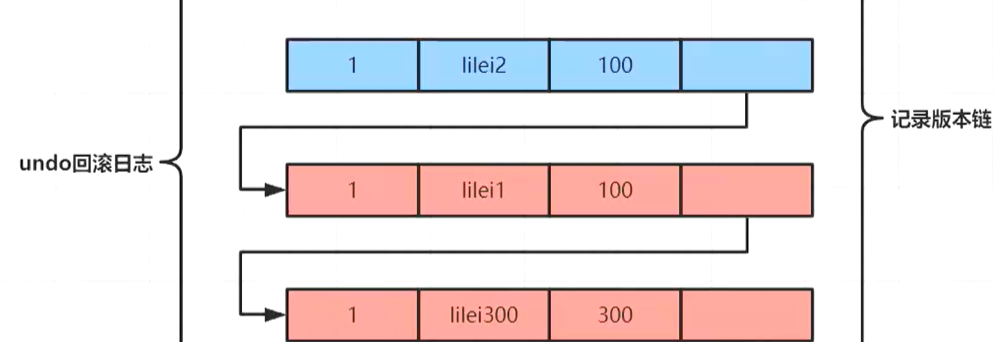
然后接着上面的案例继续往下执行,这时候Transaction100继续执行2条uapdate,然后select1继续查询同一个sql。
然后拿到了之前的那个一致性视图,然后从版本里最新的一条数据去取,发现现在最新一条数据事务ID为100,然后去比对。

执行顺序
1、他会先找到最后update的那一条数据(lilei2,他的事务id是100,),然后按照规则去比对,事务100他是未提交的事务,所以也是落在黄色区域,然后他满足3:a,因为他在事务数组中,所以他是不可见。
2、然后就会往上找(找到lilei1),然后发现他也是落在黄色区域并且也是在数组内,所以满足3:a所以也是不可见。
3、在往上找(找到lilei300),事务id是300,不在数组内,可见,mvcc到此结束。
3.3、阶段3
这里先把Transaction100事务提交,并且transaction200执行了2条update,最后select1再次进行查询。
然后拿到了之前的那个一致性视图,然后从版本里最新的一条数据去取,发现现在最新一条数据事务ID为200,然后去比对。
执行顺序
其实和上面阶段2一样,因为可重复读的一致性视图,没有变,所以事务200,依然属于未提交数组内,所以往上找,找到事务100,还是不可见,直到找到事务300,可见,结束。
总结
undo日志版本链(回滚日志的集合);
read-view一致性视图,包含未提交事务的id和最大id;
比对规则用于查找可见的数据;
MVCC机制的实现就是通过read-view机制与undo版本链比对机制,使得不同的事务会根据数据版本链对比规则读取同一条数据在版本链上的不同版本数据。
这也就是为什么一个事务里查询,每次查询结果是一样的最终原因



















 2435
2435





 到【灌水乐园】发言
到【灌水乐园】发言









