







其它
项目地址
https://gitee.com/yeomanGit/mr.git
本地运行报错
如下报错
java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:791)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:774)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:646)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:434)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:281)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:125)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:348)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303)
at com.laoxiao.mr.RunTest.main(RunTest.java:51)
解决办法
下载文件:https://gitee.com/yeomanGit/mr/blob/master/file/winutils-master.zip ,加压后把对应的版本复制到某个目录(该目录无限制)下,配置系统环境变量:
1、新增一个系统变量,HADOOP_HOME,值例如:F:\soft\bd\hadoop-2.6.0。
2、在系统变量CLASSPATH(无则新增)后添加的值如:F:\soft\bd\bin\hadoop-2.6.0\winutils.exe
普通例子
单词计数
描述
计算文件中每次单词的词频,并对结果进行输出。
例子
wx.txt文件内容如下
hello world
hello hadoop
hello mapreduce
得到结果如下
hadoop 1
hello 3
mapreduce 1
world 1
设计思路
这个例子比较简单直接,可以将文件内容切分成单词,然后将所有相同的单词聚集在一起,统计词频。即在map端切分内容,在reduce端统计词频。若该程序在分布式上可进行优化,由于map端的数据发送到reduce端需要带宽,所以可以减少map端发送到reduce端的数据,在map端切分单词之后,执行combiner操作,即在map任务执行的机器上,先进行一次词频统计,减少数据量。该例子的Combiner类可以为reduce类。
核心代码
map类
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static Text text = new Text();
private static IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//切分每一行数据
String[] ss = value.toString().split("\\s+");
for (String s : ss) {
text.set(s);
//一个单词就是一次
context.write(text, one);
}
}
}
reduce类,即combiner类
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//在combiner类中就是values都是1,reducer类中就不一定了
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
运行类
public class WordCountRunner {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountRunner.class);
//输入输出文件,输入路径需要时文件夹、输出文件夹不能存在
FileInputFormat.setInputPaths(job, new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\wc\\in"));
FileOutputFormat.setOutputPath(job, new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\wc\\out"));
//map reduce、combiner
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
//同时设置map和reduce输出的key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//输入和输入的format class
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//执行任务
job.waitForCompletion(true);
}
}
数据去重
描述
对文件中的数据进行去重,文件中的每行都是一个数据。
例子
dedup1.txt 文件的内容如下
2006-6-9 a
2006-6-10 b
2006-6-11 c
2006-6-12 d
2006-6-13 a
2006-6-14 b
2006-6-15 c
2006-6-11 c
dedup2.txt 文件的内容如下
2006-6-9 b
2006-6-10 a
2006-6-11 b
2006-6-12 d
2006-6-13 a
2006-6-14 c
2006-6-15 d
2006-6-11 c
设计思路
数据去重的最终目的是让文件中出现次数超过一次的数据在输出文件中出现一次,由此想到可以将同一个数据的所有记录输出到同一个reduce的task,无论这个数据出现多少次,只需在最终结果输出一次即可。同样地,这个例子也可以用combiner优化。
核心代码
maper
public class DedupMapper extends Mapper<Object, Text, Text, NullWritable> {
private static NullWritable nil = NullWritable.get();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String v = value.toString().trim();
value.set(v);
//输出的value可以为null,因为输出到combiner/reducer只需要key就可以了
context.write(value, nil);
}
}
combiner/reducer
public class DedupReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//不管有多少输入,只输出一个
context.write(key, NullWritable.get());
}
}
运行类
public class DedupRunner extends Runner {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(DedupRunner.class);
job.setMapperClass(DedupMapper.class);
job.setCombinerClass(DedupReducer.class);
job.setReducerClass(DedupReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\dedup\\in"));
FileOutputFormat.setOutputPath(job, new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\dedup\\out"));
//设置map和reduce的key和value的值
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.waitForCompletion(true);
}
}
排序
描述
对输出文件中的数据进行排序,文件中的每行内容均为一个数字,及一个数字,要求正序输出。
例子
sort1.txt
2
32
654
32
15
756
65223
sort2.txt
5956
22
650
92
sort3.txt
26
54
6
设计思路
本例子仅仅对输入数据进行排序,可利用MapReduce的默认排序,。但注意的是,reduce自动排序仅是对自己所在节点的数据进行排序,无法保证全局的顺序。因为再排序前会有一个分区(partition)的过程,默认无法保证分区后到达reduce的数据保证顺序。可自定义Partitioner,保证顺序。Partitioner的思路:用最大整数除以系统的partition数量作为分割数量的边界增量,然后比较当前值与分区段最小值和最大值比较,若该值大于等于最小值并小于最大值,则返回当前分区的分区值,由此可得,分区i+1的数据总比分区i的要大,从而数据到达reduce是有序的。
核心代码
mapper
public class SortMapper extends Mapper<LongWritable, Text, IntWritable, NullWritable> {
private static NullWritable nil = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//直接将当前的值作为key即可,MapReduce默认的排序会对key进行排序
context.write(new IntWritable(Integer.parseInt(value.toString())), nil);
}
}
partitioner
public class SortPartitioner extends Partitioner<IntWritable, IntWritable> {
@Override
public int getPartition(IntWritable intWritable, IntWritable intWritable2, int i) {
int max = Integer.MAX_VALUE;
int bound = max / i + 1;
int v = intWritable.get();
for (int index = 0; index < i; index++) {
if (v >= bound * index && v < bound * (index + 1 )) {
return index;
}
}
//超出返回内的丢弃了,即这个程序的排序范围为[0,Integer.MAX_VALUE]
return -1;
}
}
reducer
public class SortReducer extends Reducer<IntWritable, NullWritable, IntWritable, NullWritable> {
@Override
protected void reduce(IntWritable key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
单表关联
祖孙关系
描述
文件中给出了child-parent关系信息。要求输出grandchild-grandparent。
例子
gcp.txt
child parent
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
设计思路
假设上述gcp.txt为表gcp,child和parent为字段,例子的意思即是表gcp自我单表连接,可以得到sql为
select a.child grandchild, b.parent grandparent from gcp a join gcp b on a.parent = b.child;
可以把reduce想象成on操作,因为所有相同的key都会发给同一个reducer的task,a.child和b.parent可以作为key的value,如果直接把a.child和b.parent的值直接传入reducer,reducer会分不清哪个value是a.child、哪个是b.parent,所以可以做一个标识。如果是a.child的可以添加前缀c_,如果是b.parent的可以添加前缀p_。
核心代码
mapper
public class GCPMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String relative = value.toString();
String[] cp = relative.split("\\s+");
if (cp[0].equalsIgnoreCase("child")
&& cp[1].equalsIgnoreCase("parent")) {
return;
}
//p_XXX表示value为parent
//c_xxx表示value为child
context.write(new Text(cp[0]), new Text("p_" + cp[1]));
context.write(new Text(cp[1]), new Text("c_" + cp[0]));
}
}
reducer
public class GCPReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//一个人可以有多个parent、也能有多个child
List<String> children = new ArrayList<>();
List<String> grandparent = new ArrayList<>();
for (Text value : values) {
String v = value.toString();
//c_xxx表示为key的child,则加入childrent中
if (v.startsWith("c_")) {
children.add(v.substring(2));
} else if (v.startsWith("p_")){
//p_XXX表示为key的parent,则加入grandparent中
grandparent.add(v.substring(2));
}
}
//输出多个祖孙关系
for (String child : children) {
for (String gParent : grandparent) {
context.write(new Text(child), new Text(gParent));
}
}
}
}
共同好友
描述
文件中给出用户关系的数据,冒号前代表用户,冒号后代表用户的好友。找出哪些用户两两之间有共同好友,以及他俩的共同好友都有哪些人。
例子
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
参考结果(部分)
A-B E,C
A-C D,F
A-D E,F
A-E D,B,C
A-F O,B,C,D,E
A-G F,E,C,D
A-H E,C,D,O
A-I O
A-J O,B
A-K D,C
设计思路
下述描述中,符号【s】表示s为字符串;符号<k,v>表示k和v是key-value关系,k可以表示map和reduce的输入和输出的key,v可以表示map和reduce的输入和输出的value;符号[a,b]表示a和b在同一列表中,符号\n代表换行,符号\e代表分隔两次调用,符号|表示一次调用多次输出,字母均为字符串。
从参考结果能看到,如果传到reducer的数据为<A-B,[E,C]>,直接可以在reducer处理得出结果,即mapper的输出数据为<A-B,[E,C]>。但是mapper读入文件内容时,每一次只能处理一行的数据,从原始输入数据文件来看,即用户A不知道用户B是否用相同的好友。从原始输入文件中的数据可知,若E为用户A和用户B的好友,则,E一定出现在用户A和用户B的好友列中,我们可以通过共同好友E来找到用户A和用户B,所以在mapper中输出<共同好友,用户>格式的数据,在reducer中就可以得到用户E是哪些用户的共同好友,如用户A和用户B,在这个reducer中我们可以知道用户A和用户B有一个共同好友E,即可以输出格式为【E A,B】的数据。有上诉可知,该例子需要两个mapreduce过程。
第一个MapReduce过程:map得到输入格式为【A:C,E】、【B:C,E】、【D:C】的三条字符串数据,输出为<E,A>、<E,B>、<C,A>、<E,B>、<C:D>的key-value数据。相同的key会被发送到同一个reduce,即reduce得到的输入格式为<E,[A,B]>、<C,[A,B,D]>的key-value数据。在这个reduce中,可以将数据格式转换成<E,【A,B】>、<C,【A,B,D】>的格式存储在文件中,但是在文件中输出Text的格式是【E A,B】等字符串,作为下一个的mapreduce的输入文件。
第二个MapReduce过程,map得到的输入格式为【E A,B】、【C A,B,D】的两条字符串数据,处理后可得到格式为<A-B,E>、<A-B,C>、<A-D,C>、<B-D,C>的输出,reduce得到该输出经过简单处理即可得到结果数据。数据格式转换如下:
例子
"赵一:孙三,王五"
"钱二:孙三,王五"
"李四:孙三"
格式变换
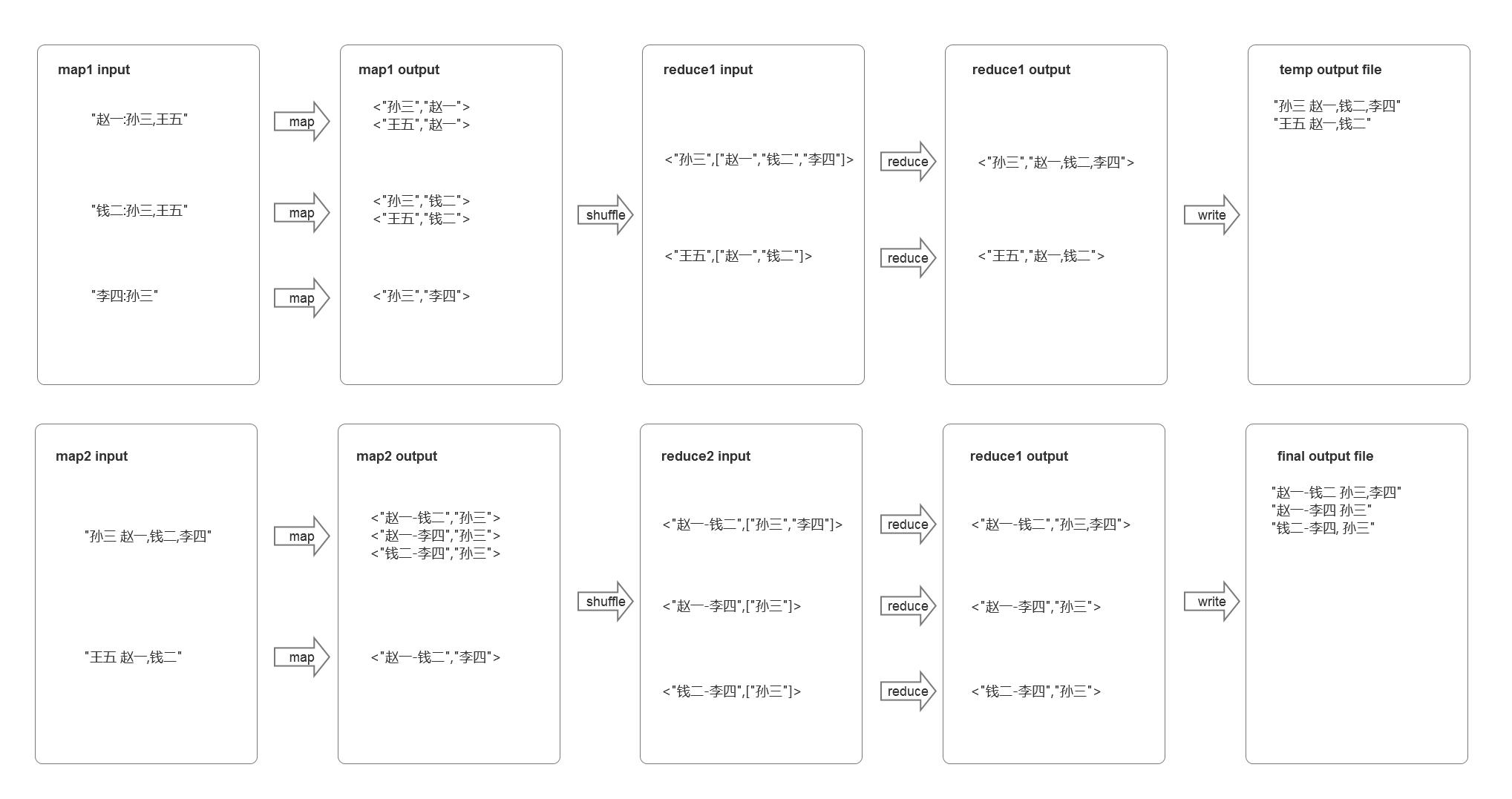
核心代码
map1
public class OneSharedFriendMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] ss = value.toString().split(":");
String[] friends = ss[1].split(",");
Text who = new Text(ss[0]);
//将A:B,C的输入格式转为<B,A>
for (String friend : friends) {
context.write(new Text(friend), who);
}
}
}
map2
public class TwoSharedFriendMapper extends Mapper<Object, Text, Text, Text> {
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] ss = value.toString().split("\\s+");
Text k = new Text(ss[0]);
String[] whose = ss[1].split(",");
//排序是为了减少重复输出
Arrays.sort(whose);
int length = whose.length;
for (int i = 0; i < length - 1; i++) {
for (int j = i + 1; j < length; j++) {
context.write(new Text(whose[i] + "-" + whose[j]), k);
}
}
}
}
reduce1和reduce2,代码一样
public class SharedFriendReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder builder = new StringBuilder();
boolean add = false;
for (Text value : values) {
if (add) {
builder.append(",");
}
builder.append(value.toString());
add = true;
}
context.write(key, new Text(builder.toString()));
}
}
runner
public class SharedFriendRunner {
public static void main(String[] args) throws Exception {
Path in = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\st\\friend\\in");
Path inOut = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\st\\friend\\io");
Path out = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\st\\friend\\out");
//第一个mapreduce的job配置
Configuration conf = new Configuration();
Job one = Job.getInstance(conf, "one");
one.setMapperClass(OneSharedFriendMapper.class);
one.setReducerClass(SharedFriendReducer.class);
one.setOutputKeyClass(Text.class);
one.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(one, in);
FileOutputFormat.setOutputPath(one, inOut);
//第二个mapreduce的job配置,输入为第一个mapreduce的输出
Job two = Job.getInstance(conf, "two");
two.setMapperClass(TwoSharedFriendMapper.class);
two.setReducerClass(SharedFriendReducer.class);
two.setOutputKeyClass(Text.class);
two.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(two, inOut);
FileOutputFormat.setOutputPath(two, out);
//使用jobControl管理两个job
JobControl control = new JobControl("friend");
ControlledJob oJob = new ControlledJob(one.getConfiguration());
ControlledJob tJob = new ControlledJob(two.getConfiguration());
//表示tJob依赖于oJob,需先设置
tJob.addDependingJob(oJob);
control.addJob(oJob);
control.addJob(tJob);
//启动
new Thread(control).start();
while (true) {
//结束了直接关闭control
if (control.allFinished()) {
System.out.println(control.getSuccessfulJobList());
control.stop();
break;
}
}
}
}
多表关联
地址关联
描述
有两个文件,一个代表工厂表,包含工厂名称和地址编号列;另一个代表地址表,包含地址名称和地址编号列。要求从输入数据中找出工厂和帝之命的对应关系。
例子
factory.txt
factoryname addressed
beijing red star 1
shenzhen thunder 3
guangzhou honda 2
beijing rising 1
guangzhou development bank 2
tencent 3
bank of beijing 1
address.txt
addressID addressname
1 beijing
2 guangzhou
3 shenzhen
4 xian
设计思路1
和祖孙关系的例子类似,假设上述factory.txt为表factory,factoryname和addressed为字段,address.txt为表,addressID和addressname为字段,例子的意思即是表factory和表address的自然连接,可以得到sql为
select factoryname,addressname from factory join address on adressed = addressID;
可以把reduce想象成on操作,因为所有相同的key都会发给同一个reducer的task,factoryname和addressname可以作为key的value,如果直接把factoryname和addressname的值直接传入reducer,reducer会分不清哪个value是factoryname、哪个是addressname,所以可以做一个标识。如果是factoryname的可以添加前缀f_,如果是addressname的可以添加前缀addr_。另外,本例假设两个文件在不同的目录下。
核心代码1
mapper for factory.txt
public class FactoryMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String name = "factoryname", v = value.toString();
if (!v.contains(name)) {
v = v.trim();
String n = v.substring(0, v.lastIndexOf(" "));
String id = v.substring(v.lastIndexOf(" ") + 1);
context.write(new Text(id), new Text("f_" + n));
}
}
}
mapper for address.txt
public class AddressMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String name = "addressname", v = value.toString();
if (!v.contains(name)) {
String id = v.substring(0, v.indexOf(" "));
String n = v.substring(v.indexOf(" ") + 1);
context.write(new Text(id), new Text("addr_" + n));
}
}
}
reducer
public class Factory2AddressReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String v;
List<String> factory = new ArrayList<>();
Text address = new Text("");
//遍历value,并区分factoryname和addressname信息
for (Text value : values) {
v = value.toString();
if (v.startsWith("f_")) {
factory.add(v.substring(2));
} else if (v.startsWith("addr_")) {
address.set(v.substring(5));
}
}
if (!address.toString().isEmpty()) {
for (String fac : factory) {
context.write(new Text(fac + " -> "), address);
}
}
}
}
runner
public class Factory2AddressRunner extends Runner {
public static void main(String[] args) throws Exception {
Path f1 = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\mt\\f2a\\factory");
Path f2 = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\mt\\f2a\\address");
Path out = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\mt\\f2a\\out");
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Factory2AddressRunner.class);
//不再设置普通Map类
MultipleInputs.addInputPath(job, f1, TextInputFormat.class, FactoryMapper.class);
MultipleInputs.addInputPath(job, f2, TextInputFormat.class, AddressMapper.class);
job.setReducerClass(Factory2AddressReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, out);
job.waitForCompletion(true);
}
}
设计思路2
该例子的sql的与[设计思路1]的一样,但是,如果address.txt的数据数量较少,我们可以考虑将address.txt的数据先加载到内存中,用hashMap存储,当factory.txt的数据被输入时,使用key获取map中的数据。
核心代码2
map
public class Factory2AddressWithSetupMapper
extends Mapper<LongWritable, Text, Text, Text> {
//用来保存地址信息
Map<String, String> addressMap;
//在开始时执行,只执行一次
@Override
protected void setup(Context context) throws IOException, InterruptedException {
addressMap = new HashMap<>();
//在cache file中获取,需要设置
URI[] uris = context.getCacheFiles();
//可能用多个文件
for (URI uri : uris) {
if (uri.toString().contains("address")) {
try(BufferedReader reader = new BufferedReader(new FileReader(uri.getPath()))) {
String name = "addressname", v;
while ((v = reader.readLine()) != null) {
if (!v.contains(name)) {
String id = v.substring(0, v.indexOf(" "));
String n = v.substring(v.indexOf(" ") + 1);
addressMap.put(id, n);
}
}
} catch (Exception e){
e.printStackTrace();
}
}
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String name = "factoryname", v = value.toString();
if (!v.contains(name)) {
v = v.trim();
String n = v.substring(0, v.lastIndexOf(" "));
String id = v.substring(v.lastIndexOf(" ") + 1);
//当存在地址时写入
if (addressMap.containsKey(id)) {
context.write(new Text(n), new Text(addressMap.get(id)));
}
}
}
}
reducer
public class Factory2AddressWithSetupReducer
extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//直接输出
for (Text value : values) {
context.write(key, new Text(" -> " + value));
}
}
}
runner
public class Factory2AddressWithSetupRunner extends Runner {
public static void main(String[] args) throws Exception {
Path f1 = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\mt\\f2a\\factory");
Path out = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\mt\\f2a\\out");
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Factory2AddressWithSetupRunner.class);
job.setMapperClass(Factory2AddressWithSetupMapper.class);
job.setReducerClass(Factory2AddressWithSetupReducer.class);
Path out = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\mt\\f2a\\out");
Path f1 = new Path("F:\\code\\download\\my\\map-reduce-example\\src\\main\\resources\\mt\\f2a\\factory");
String f2 = "file:///F:/code/download/my/map-reduce-example/src/main/resources/mt/f2a/address/address.txt";
//在cache file中设置address.txt
job.setCacheFiles(new URI[] {new URI(f2)}) ;
FileInputFormat.setInputPaths(job, f1);
FileOutputFormat.setOutputPath(job, out);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, out);
job.waitForCompletion(true);
}
}















 3007
3007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









