







 https://www.docs4dev.com/docs/en/apache-hive/3.1.1/reference/HowToContribute.html
https://www.docs4dev.com/docs/en/apache-hive/3.1.1/reference/HowToContribute.html一、在hive_metastore.thrift中新增函数声明
因为各API的网络通信和序列化等相关的辅助代码是由Thrift编译自动生成的,首先需要新增api相关的声明,包括返回类型、入参、抛出异常等,可以参考其他位置api的写法,如下图所示:
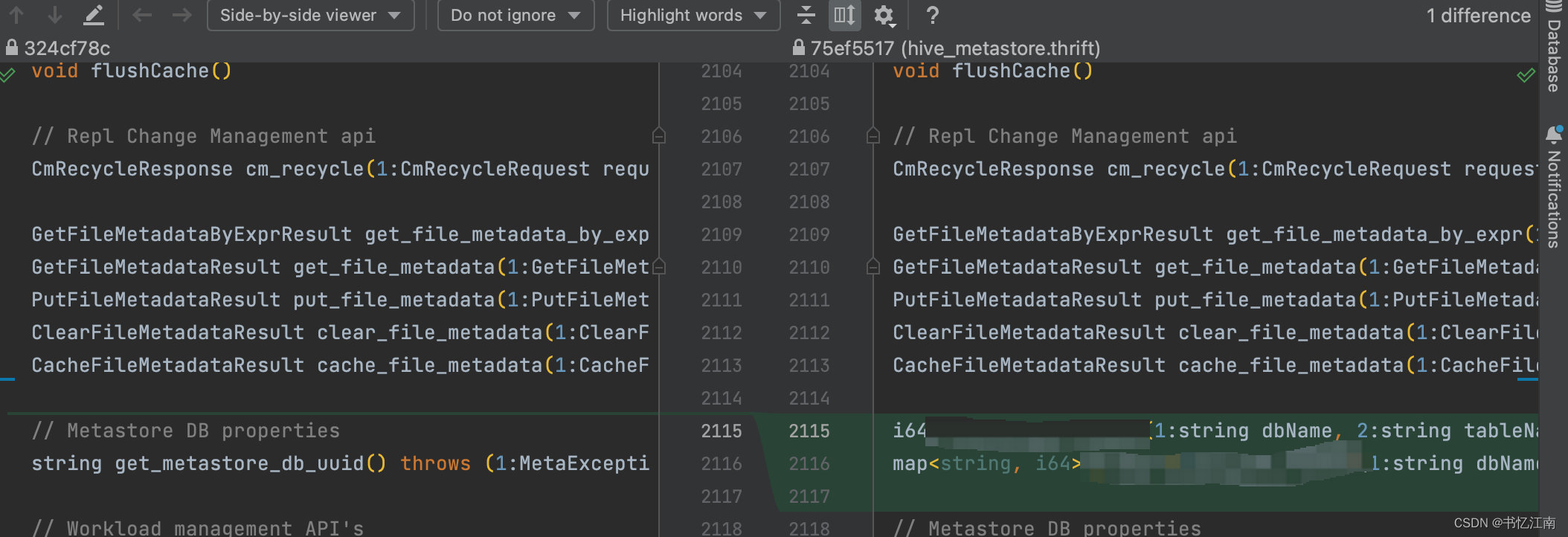
如果是Windows和Linux、intel芯片Mac等系统,则后续可以直接在本机进行代码生成和编译,否则需要先将该文件改动push到git远程分支,再到远程Linux编译机上拉取下来。
如果是要新增thrift常量,也同样是在hive_metastore.thrift中加入相关的声明,如下图所示:

二、在Linux上安装thrift工具,编译.thrift文件
如果工作中使用了m1芯片Mac,则protobuf等底层通信和序列化相关的老版本jar包没有提供osx_aarch64版本(例如hive3依赖的2.5.0版本),本地编译无法通过,需要利用到Linux上的thrift命令行来对hive源码进行编译和自动代码生成。
如果Linux版本较老且上面未安装thrift,可以参考:Apache Thrift - Centos 6.5 Install
安装好thrift后,如果系统是CentOS则还有一步需要注意,需要执行如下命令来提前避免mvn编译时fb303.thrift not being found的问题:
mkdir -p /usr/local/share/fb303/if
cp /thrift下载路径/thrift-0.9.3/contrib/fb303/if/fb303.thrift /usr/local/share/fb303/if接着cd到hive源码目录,使用如下命令进行thrift接口自动代码生成:
mvn clean install -Pthriftif -DskipTests -Dthrift.home=/usr/local编译到最后会报错,因为新thrift api的部分代码和接口已经生成,但是其他实现接口类的子类中还没有override这些新接口,看到如下报错已经说明thrift自动生成代码成功了:
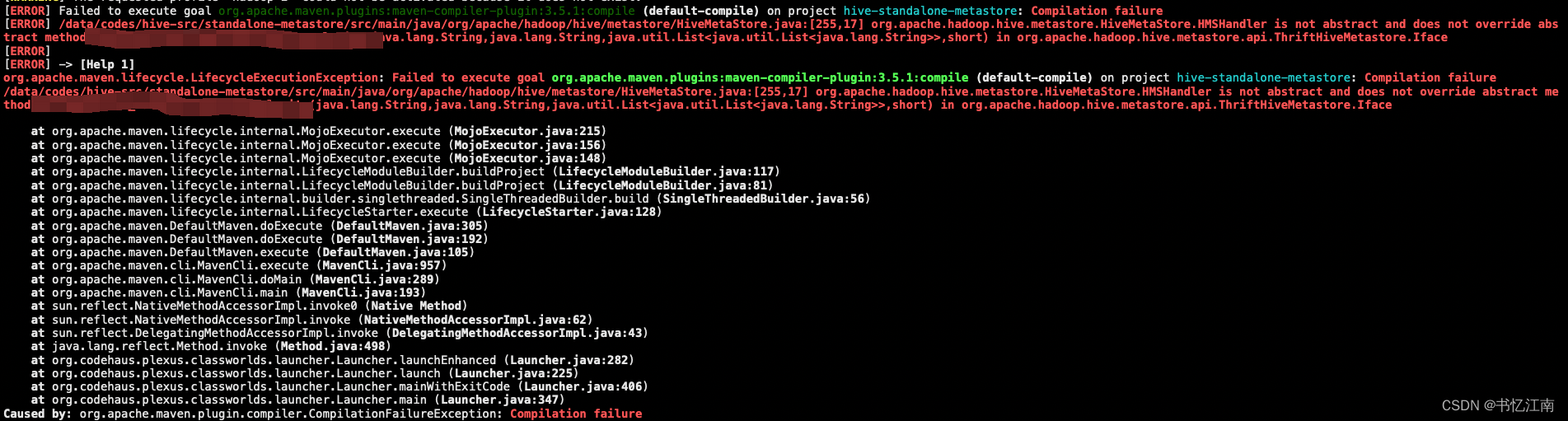
可以看到如下路径的类中自动新增了上千行代码:
standalone-metastore/src/gen/thrift/gen-javabean/org/apache/hadoop/hive/metastore/api/ThriftHiveMetastore.java同时还有.cpp、.php等其他语言文件的改动和生成,如果不需要实现其他语言的接口,可以把除.java以外的文件改动都撤回(例如使用git checkout命令),然后将ThriftHiveMetastore.java的改动提交到远程GitLab。
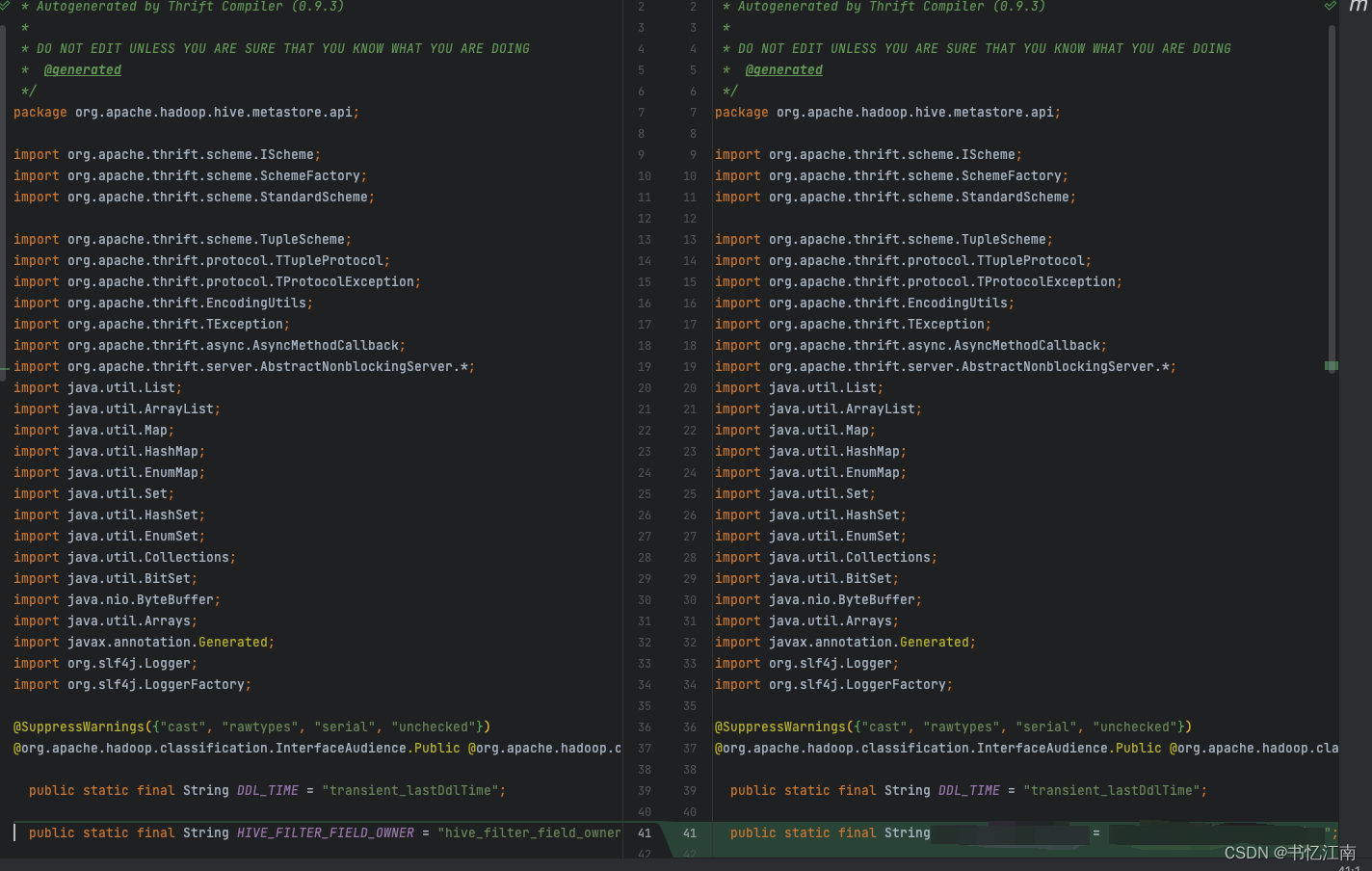
如果在hive_metastore.thrift中添加了常量,则Thrift编译后可被Java引用的常量会自动出现在org.apache.hadoop.hive.metastore.api.hive_metastoreConstants.java中,如下图所示:
三、拉取远程GitLab的thrift代码生成改动,子类实现相关接口
本地将远程编译生成成功的hive thrift源码拉取下来后,需要在hive源码中再实现以下类中的新接口API,因为它继承了ThriftHiveMetastore.java,而thrift自动代码生成导致该父类多了些新的未实现接口:
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/HiveMetaStore.java从rpc通信的client和server端角度,目前完善的是server端的代码,如果HiveMetaStore.java中的新API逻辑需要读取MySQL元数据库中的内容,则同时还需要实现如下类的相关接口代码(省略了其他非关键子类):
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/RawStore.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/ObjectStore.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/MetaStoreDirectSql.java关于MetaStoreDirectSql.java中的SQL如何写,除了可以参考该类中其他方法的写法,还需要对Hive Metastore启动时自动往MySQL中创建的元数据库各表结构有一定的了解,可以参考:https://www.jianshu.com/p/420ddb3bde7f![]() https://www.jianshu.com/p/420ddb3bde7f
https://www.jianshu.com/p/420ddb3bde7f
查看上述几个类源码中已有的其他方法代码,可以发现调用链为:
HiveMetastore -> ObjectStore -> MetaStoreDirectSql四、完善客户端接口代码
上面完善的是Hive Metastore作为服务端,从MySQL元数据库查询相关hive表元信息并返回值的代码,其他应用例如Presto是通过客户端API来调用服务端的代码来接收返回值的,因此还需要实现如下两个类的新接口:
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/IMetaStoreClient.java
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/HiveMetaStoreClient.java五、修改standalone-metastore模块pom.xml的版本并deploy到maven私服
首先在standalone-metastore模块的pom.xml中加入如下的私服发布配置:
<distributionManagement>
<repository>
<id>xx-releases</id>
<name>Nexus Release Repository</name>
<url>http://x.x.x.x/nexus/content/repositories/releases/</url>
</repository>
<snapshotRepository>
<id>xx-snapshots</id>
<name>Nexus Snapshot Repository</name>
<url>http://x.x.x.x/nexus/content/repositories/snapshots/</url>
</snapshotRepository>
</distributionManagement>然后修改standalone-metastore模块pom.xml的<version>标签为内部版本号,接着使用如下命令发布到maven私服:
# 在Hive源码根pom目录下
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=true
# 整个项目编译好后
cd standalone-metastore
mvn deploy -DskipTests source:jar当然为了规范也可以参考这边的方法,修改所有模块的内部版本号,但是会遇到upgrade-acid子模块被root project依赖,而中央仓库没有内部版本号的包,导致一开始编译就报错找不到的问题: https://www.jianshu.com/p/88da01804d3c![]() https://www.jianshu.com/p/88da01804d3c
https://www.jianshu.com/p/88da01804d3c















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









