







Maprudece的Shuffle机制(为了优化,得了解)
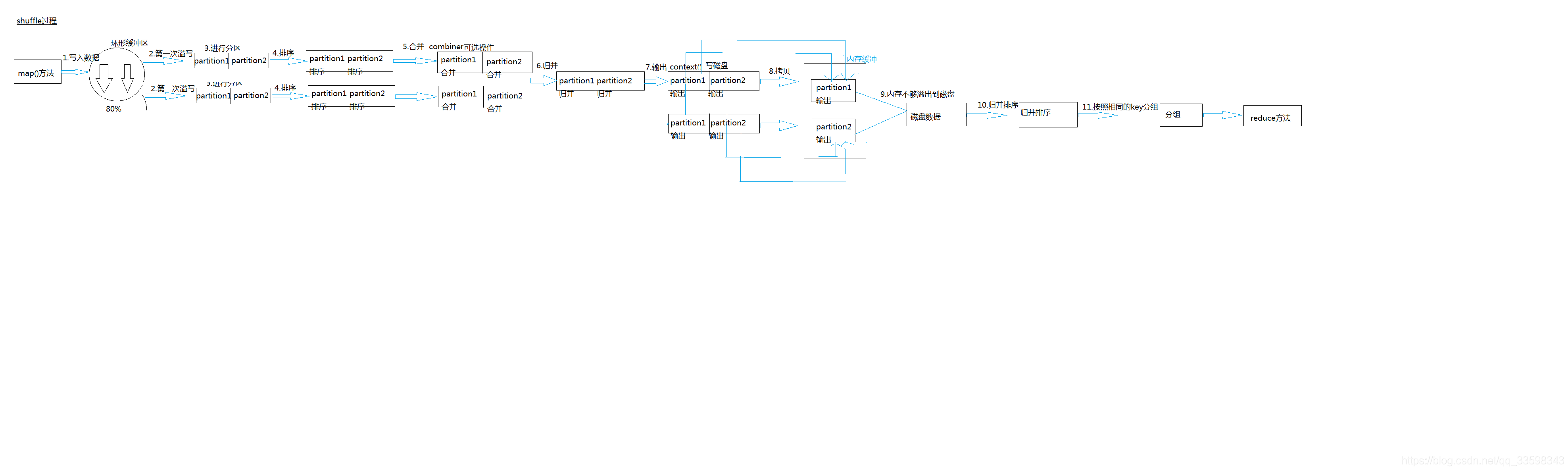
1.shuffle:map的输出作为reduce的输入的中间的过程
2.shuffle的阶段
1)由map()方法将key/vaule写到环形缓冲区当中
2)环形缓冲区默认为100MB,若达到阈值(80%)就会发生溢写,产生临时文件(将80MB的文件溢写,并且不影响向缓冲区写入数据的过程,这个过程是启动了单独的一个线程来做,如果map输出的数据量大,溢写可能会发生多次,最后,环形缓冲区里的数据会合并成一个文件进行溢写的操作)
3)溢写的文件经过默认的分区(partitioner)(有自定义的分区就用自定义的,没有就用默认的)和排序(sort)
4)Combiner:区内合并(),这里的合并是可选的,是对程序的一个优化,减少了磁盘IO的消耗,我们需要确保combine的输入和输出是一样的, 另外还要考虑本地的reduce对最终的结果是否有影响,比如wordcount,他在本地做累加对最终的结果是没有影响,可以使用combine; 但是计算平均数就不行了,主要这个过程有信息的丢失。
5)merge:归并,区与区合并,将相同分区的合并。
此时的归并是将所有spill文件中的相同partition合并到一起,并对各个partition中的数据再进行一次排序(sort)文件归并时,如果溢写文件数量超过参数min.num.spills.for.combine的值(默认为3)时,可以再次进行合并。
6)reducetask(从maptask磁盘读,如果map输出的分区文件小),这里是基于jvm的缓存机制,比map端的溢写过程灵活,先通过内存缓冲的方式先copy部分属于自己的数据,当超过阈值时,溢出到磁盘,map端的数据已经有序,reducetask其实就是为了把文件不断归并排序成一个输出文件给reduce执行
7)进行归并排序后(Map端是快速排序),按照相同的key进行分组
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
8)传给reduce()方法
可以在map端设置压缩,可以减少磁盘IO
分区排序Combiner分组都可以根据自身业务需求进行自定义,reducetaske的数量由分区决定,默认的分区数量为1,可以通过自定义来修改数量,在job里设置就可以。















 3747
3747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









