







声明:本帖子仅是用于学习用途,请勿与用于恶意破坏别人网站,本人不承担法律责任。
来继续学爬虫呀!
前言
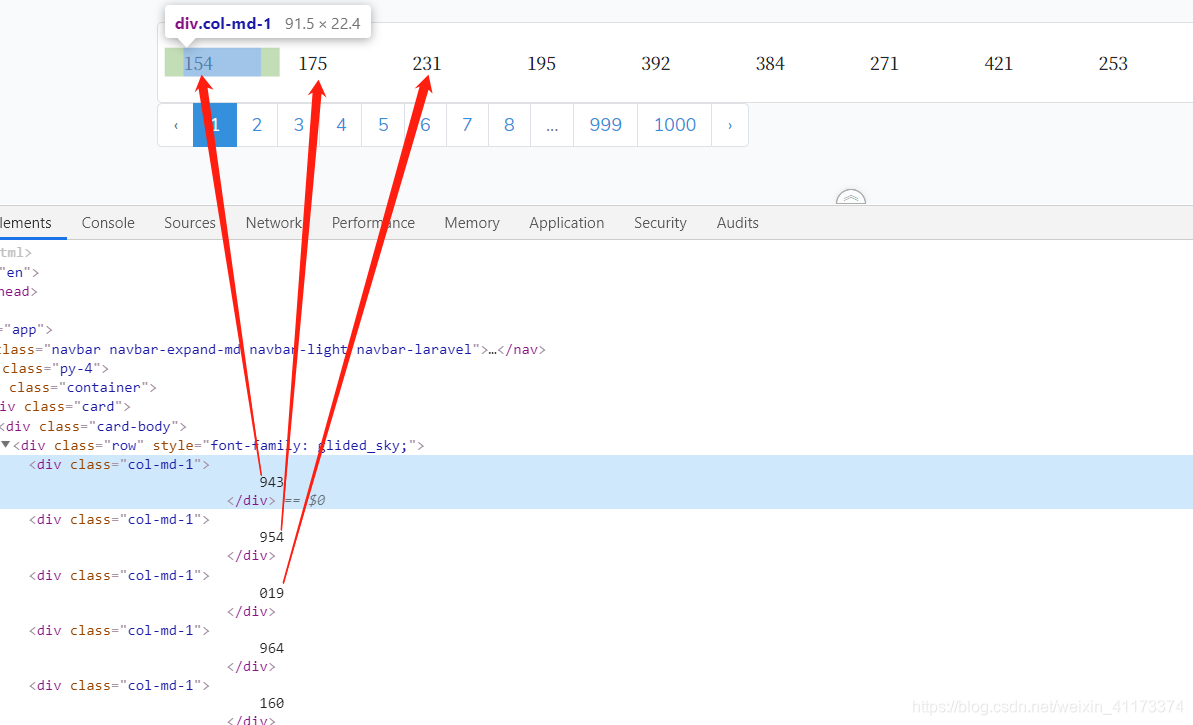
简单描述一下这种手段,html源码的数字跟页面展示的数字是不一致的!当时就一脸黑人问号,嗯???
经过分析,当前这种字体反爬机制是:通过获取指定链接的woff字体文件,然后根据html源码的数字
去woff字体文件里面查找真正的数字,讲到底就是一个映射关系/查找字典。如html源码是123,去woff文件里面
查找出来的是:623。好了,看到这里,你一定想说:废话讲那么多干嘛?赶紧上教程啊!!
那先来看一下大致流程呗:

分析目标网站页面(在这里我不打算贴出网站地址,请大家自己找网站练习),这里看到html源码和页面展示的数字是不一致的,如下图:
tips:
一开始不知道是怎么下手,只能谷歌搜索字体反爬,一搜果然很多说法,有说woff文件的、有说CSS的、还有说svg曲线啥的,
然后我就去查看Network里面的All,就发现关键字眼woff,就开始猜测可能是属于这种类型的反爬手段,接着开始干活。
混淆前字体:

混淆后的字体:
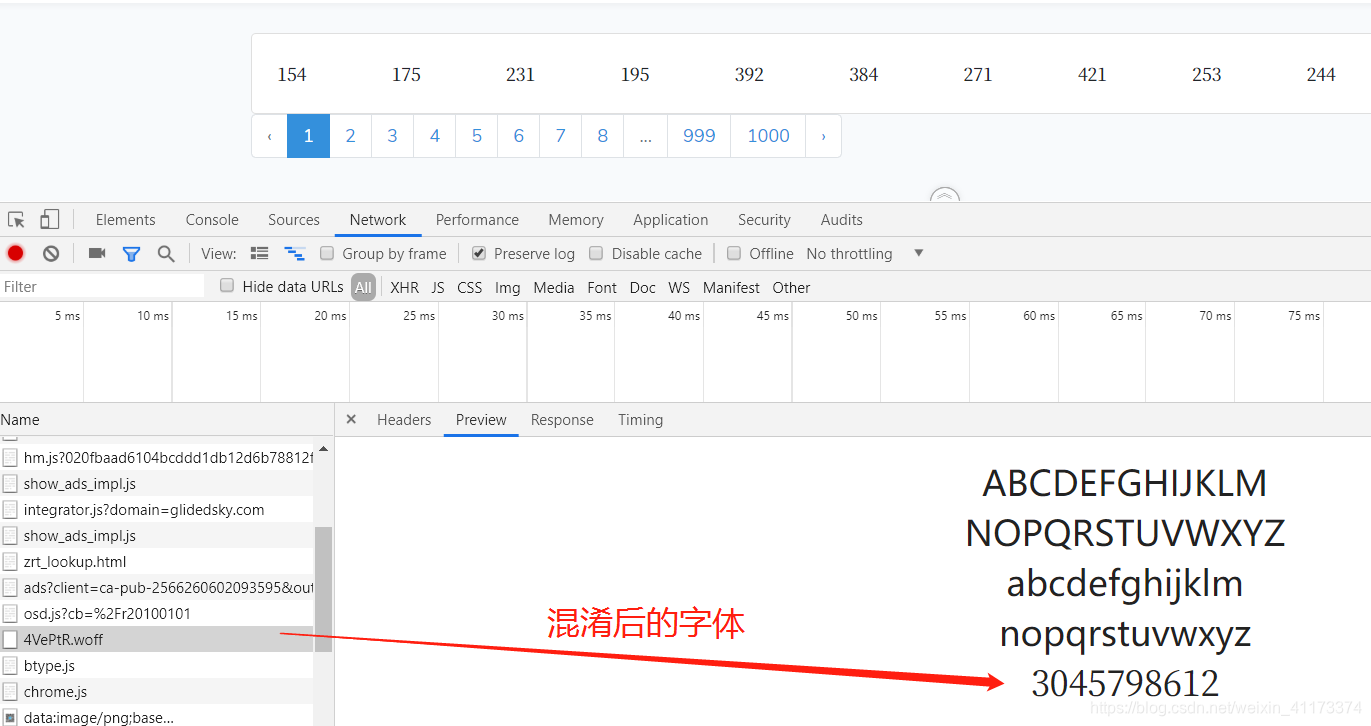
找了一会,发现.woff2文件和woff文件前后不一样,然后开始着手解决
如需下载woff文件,请点击这里, 提取码: ghnx
但是本地打不开woff字体文件,需要借助的软件是fontcreator,这个你自己去找一下,很多破解的
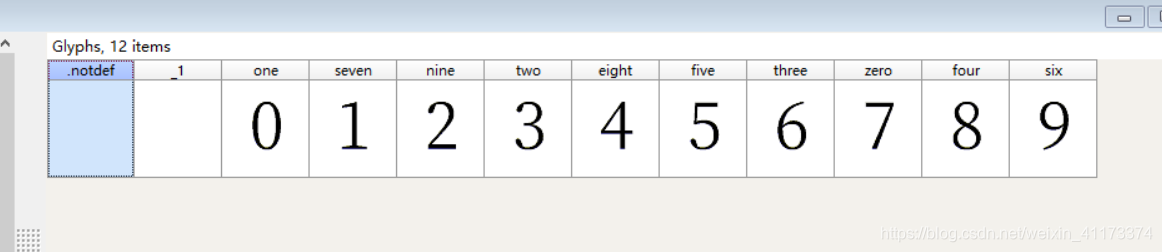
但是这好像看不出什么,然后我们接着需要从另外一方面下手,重点来了》将woff文件转换为xml文件
如下:
import os
import requests
from fontTools.ttLib import TTFont
base_dir = os 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









