







 本文详细介绍了如何使用Hadoop MapReduce实现WordCount程序。从创建Java项目,编写WordMapper和WordReducer,到打包成jar文件,然后在Linux环境中运行,包括上传输入文件,启动Hadoop集群,执行MapReduce任务,最终查看统计结果。
本文详细介绍了如何使用Hadoop MapReduce实现WordCount程序。从创建Java项目,编写WordMapper和WordReducer,到打包成jar文件,然后在Linux环境中运行,包括上传输入文件,启动Hadoop集群,执行MapReduce任务,最终查看统计结果。
打开eclipse,新建一个WordCount的java project工程,写WordMapper类继承于Mapper抽象类,覆写map函数,写WordReducer类继承于Reducer,覆写reduce函数,最后写一个场景调用类,调用WordMapper和Reducer类
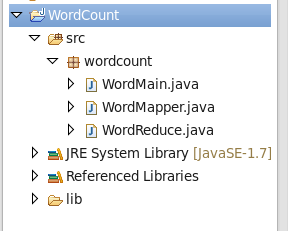
WordMapper类
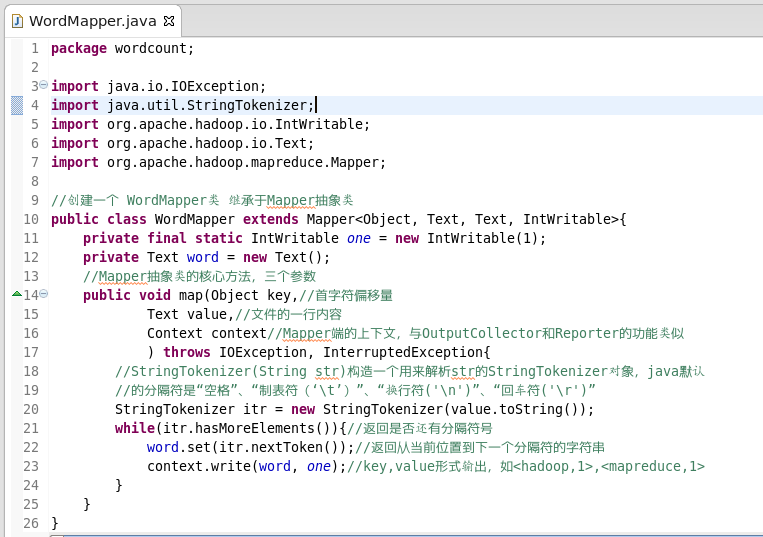
WordReduce类
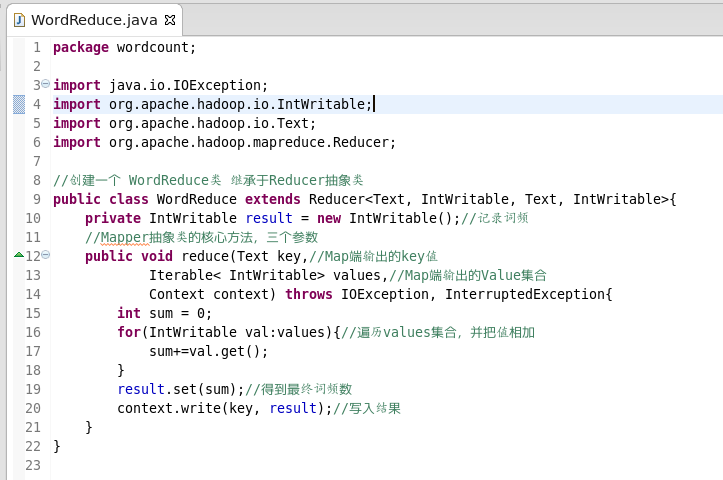
WordMain类

接下来就是导出jar包文件的步骤
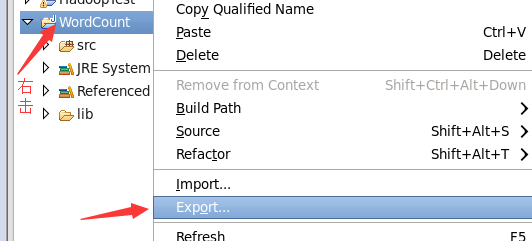
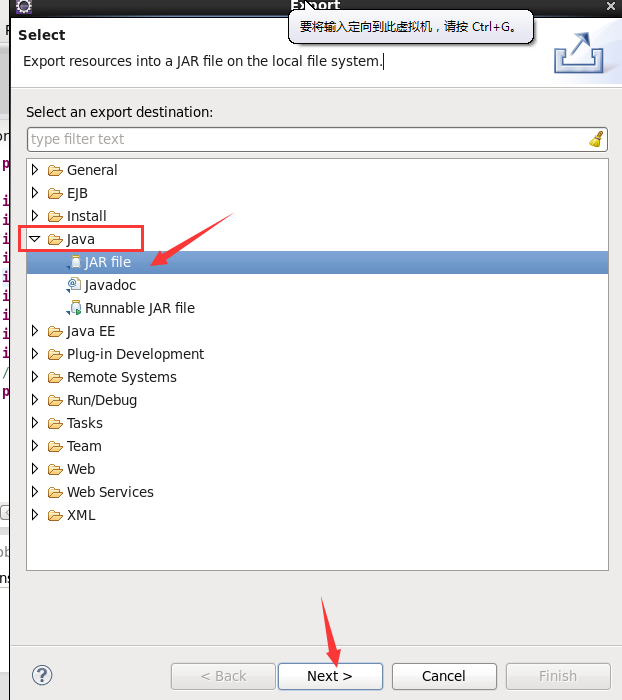
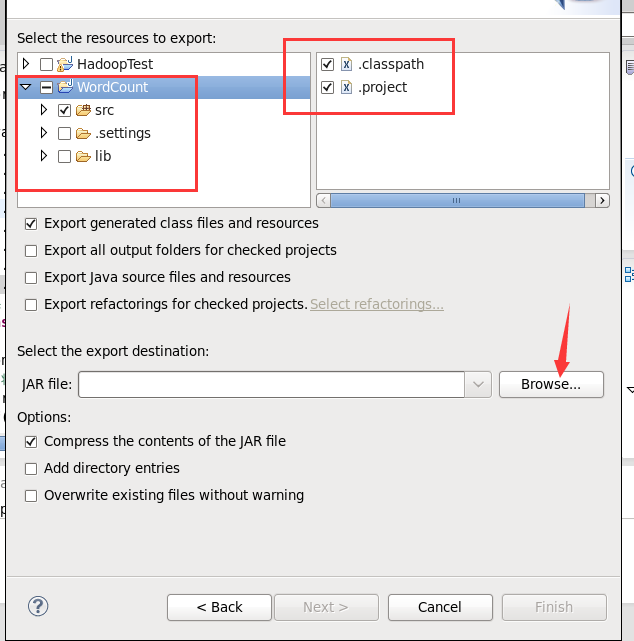
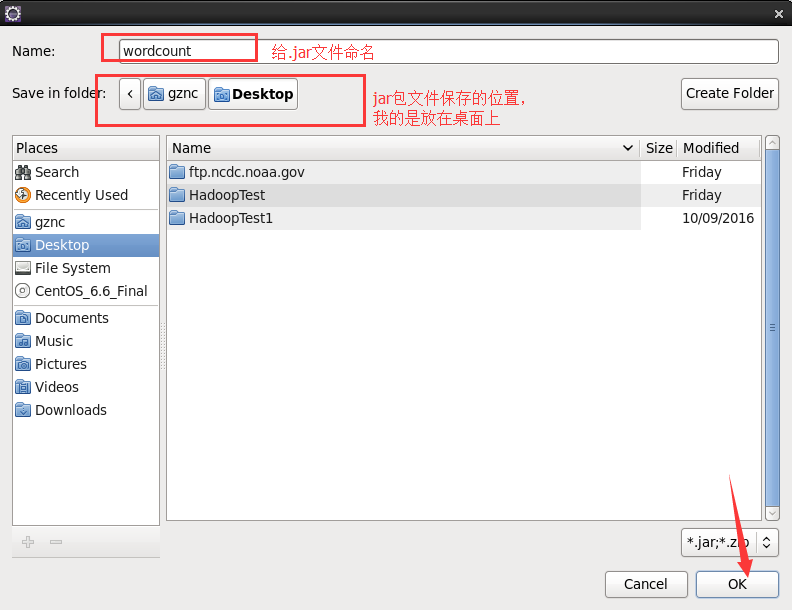
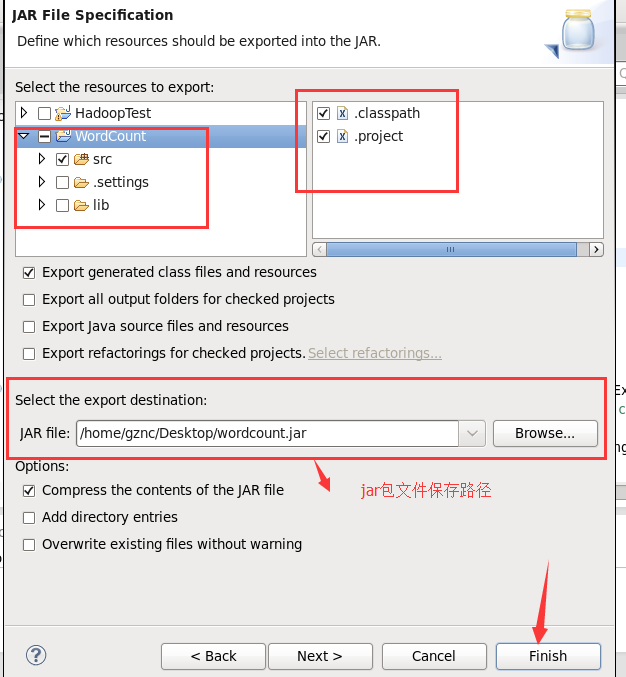
Linux桌面上就会出现wordcount.jar文件
准备好要测试的文件file1.txt,file2.txt,两个文件里面的内容是一些单词

启动hadoop集群,命令start-all.sh,创建文件输入路径:hadoop fs -mkdir /user/gznc/input将本地上的file1.txt和file2.txt文件上传到集群的输入文件中,有两种方法可以上传文件,第一种方法是命令:hdfs dfs /home/gznc/file1.txt /user/gznc/input,第一个是本地路径,第二个是集群路径。第二个文件类似。第二种方法是用eclipse写方法上传。注意路径可以变化,不一定要和我的一样

查看文件file1.txt和file2.txt是否已经上传到集群,命令:hadoop fs -ls /user/gznc/input
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









