







一、指令乱序执行
对于CPU性能有以下公式
处 理 器 性 能 = 主 频 ∗ I P C 处理器性能 = 主频 *IPC 处理器性能=主频∗IPC
由上述公式我们可以知道,提高CPU性能要么就提高主频,要么就提高IPC(每周期执行的指令数).提升IPC有两种做法,一个是增加单核并行的度,一个是加多几个核~
单核CPU增加并行度的主要方式是采用流水线设计。
早期一些采用非常简单的指令集的电脑是采用单周期设计的,取指、解码、执行、写回都是放在同一个拍(周期)内顺序完成此时的 CPI(每指令周期数,也可以说是并行度吧)基本上是 1,但是这样设计的效率很低:当取指的时候,其余工位都只能瞎瞪眼等开饭,这样的设计也被称作非流水线化执行。
流水线化则是实现各个工位不间断执行各自的任务,例如同样的四工位设计,指令拾取无需等待下一工位完成就进行下一条指令的拾取,其余工位亦然。
理想很丰满,现实很骨感,上述图示中的状态只是极为理想中的情况。流水线在运作过程中会遇到以下的问题:
RISC 指令集具备指令编码格式统一、指令都在一周期内完成等特点,在流水线设计设计上有得天独厚的优势。但是非等长不定周期的 CISC(例如 x86 的指令长度为 1 个字节到 17 个字节不等)想要达到上图中紧凑高效的流水线形式就比较困难了,在执行的过程中肯定会存在气泡(存在空闲的流水线工位)。
如果连续指令之间存在依赖关系(如 a=1,b=a)那么这两条指令不能使用流水线,必须等 a=1执行完毕后才能执行 b=a。在这里也产生了很大的一个气泡。
如果指令存在条件分支,那么CPU不知道要往哪里执行,那么流水线也要停掉,等条件分支的判断结果出来。大气泡~
为了解决上述的问题,工程师们设计了以下的技术:
乱序执行; 分支预测。
分支预测很简单。就是我不管你分支判断结果如何,我随意挑一个分支执行好了,挑错了就放弃之前计算的结果。这根本文主题关系不大,就不再探讨了。
乱序执行就是说把原来 有序执行的 指令列表,在保证执行结果一致的情况下 根据 指令依赖关系及指令执行周期 重新安排执行顺序。例如以下指令(a = 1;b=a;c=2;d=c)在CPU中就很可能被重排序成为以下的执行顺序(a=1;c=2;b=a;d=c;),这样的话,4条指令都可以高效的在流水线中运转了。
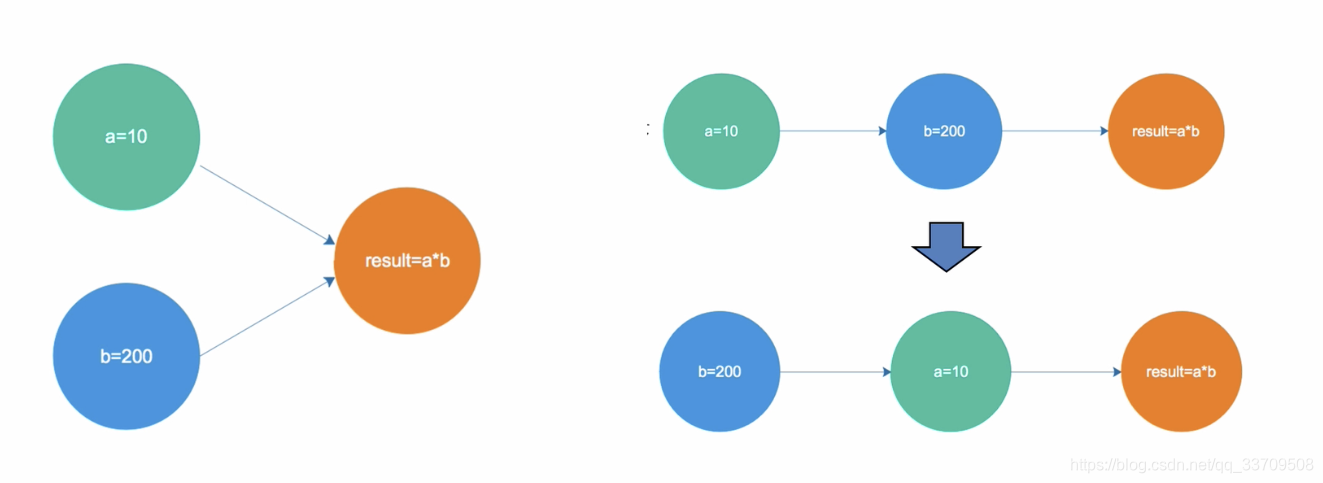
虽然乱序执行提高了CPU的执行效率,但是却带来了另外一个问题。就是在多核多线程环境中,若线程A执行(a = 1;b=a;c=2;d=c)优化成了(a=1;c=2;b=a;d=c;)的话,线程B看到a=1,c=2但b还没有被赋值的话,会觉得无法理解,因为B认为的A的执行顺序就应该只是(a = 1;b=a;c=2;d=c)而已。这个,是在多核CPU给多线程编程带来的的第一个问题。
二、CPU高速缓存
由于我们技术及资金的限制,我们电脑的存储通常由多级不同存储速度的设备构成。CPU的高速缓存在电脑里存取速度是最快的但也是最贵的,因此高速缓存只有几M或者几百K,内存较为便宜,因此内存可以去到几G,硬盘则可以多达T级别。
引入这样的分层设计,我们就可以通过 预判预读等形式将数据批量从较慢的设备中取出来,然后放到较快的设备中去,提高整体的效率了。
这样的分层设计甚至于,在CPU内部也存在,我们下面看下core i7的缓存结构图:
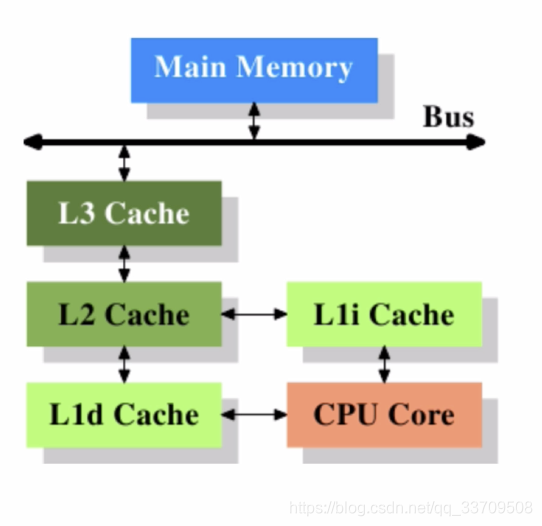
CORE I7内高速缓存分为3级,L1,L2,L3 。这些缓存中只有L3是共享的,L1,L2都是私有的,这里有多个私有的L1,L2意味着这里有可能存在着多个相同的数据的副本,若要对这些副本进行修改就存在着与分布式系统类似的同步的问题。好在,这里是同一个CPU,我们只需考虑CAP中的C即可,A和P都无需考虑。这是多核CPU给多线程编程带来的第二个挑战。
*:这里很容易联想到另外一个问题,为什么L1,L2不在多个核之间共享?这样就不存在数据同步的问题了?我翻了下维基百科上的资料,原因是L1如果制作成共享的形式,会导致与内核数据交互变慢(需要竞争读取写入设备资源,除非缓存的存取速度远高于CPU单核速度,完全可以支持多个核的写入读取需求),得不偿失。
多核CPU多级缓存一致性协议MESI
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱。这里就引出了一个一致性的协议MESI。
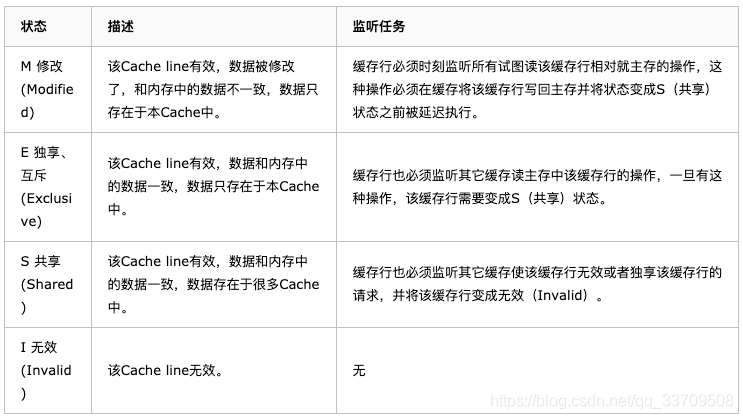
MESI协议缓存状态
MESI 是指4中状态的首字母。每个Cache line有4个状态,可用2个bit表示,它们分别是:
缓存行(Cache line):缓存存储数据的单元。
注意:
对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
从上面的意义看来E状态是一种投机性的优化:如果一个CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成invalid状态,而修改E状态的缓存不需要使用总线事务。
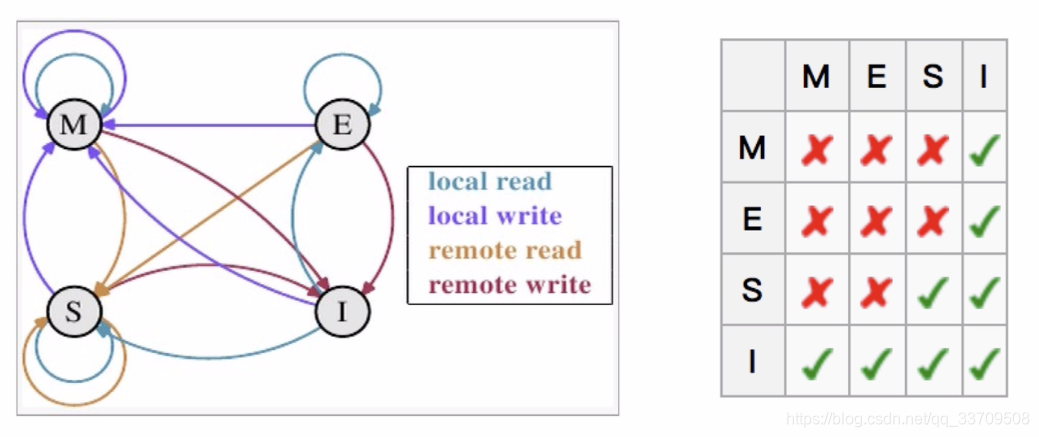
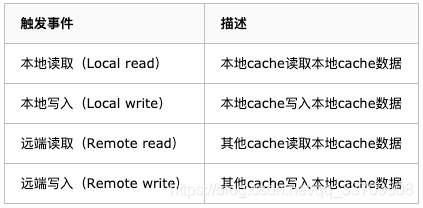
MESI优化和他们引入的问题
缓存的一致性消息传递是要时间的,这就使其切换时会产生延迟。当一个缓存被切换状态时其他缓存收到消息完成各自的切换并且发出回应消息这么一长串的时间中CPU都会等待所有缓存响应完成。可能出现的阻塞都会导致各种各样的性能问题和稳定性问题。
CPU切换状态阻塞解决-存储缓存(Store Bufferes)
比如你需要修改本地缓存中的一条信息,那么你必须将I(无效)状态通知到其他拥有该缓存数据的CPU缓存中,并且等待确认。等待确认的过程会阻塞处理器,这会降低处理器的性能。应为这个等待远远比一个指令的执行时间长的多。
Store Bufferes
为了避免这种CPU运算能力的浪费,Store Bufferes被引入使用。处理器把它想要写入到主存的值写到缓存,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时,数据才会最终被提交。
这么做有两个风险
Store Bufferes的风险
第一、就是处理器会尝试从存储缓存(Store buffer)中读取值,但它还没有进行提交。这个的解决方案称为Store Forwarding,它使得加载的时候,如果存储缓存中存在,则进行返回。
第二、保存什么时候会完成,这个并没有任何保证。















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











