






一、简介
布隆过滤器(Bloom Filter)是一种数据结构,用于快速检查一个元素是否属于某个集合中。它可以快速判断一个元素是否在一个大型集合中,且判断速度很快且不占用太多内存空间。
布隆过滤器的主要原理是使用一组哈希函数,将元素映射成一组位数组中的索引位置。当要检查一个元素是否在集合中时,将该元素进行哈希处理,然后查看哈希值对应的位数组的值是否为1。如果哈希值对应的位数组的值都为1,那么这个元素可能在集合中,否则这个元素肯定不在集合中。
由于哈希函数的映射可能会发生冲突,因此布隆过滤器可能会出现误判,即把不在集合中的元素判断为在集合中。但是,布隆过滤器不会漏判,即不会把在集合中的元素判断为不在集合中。
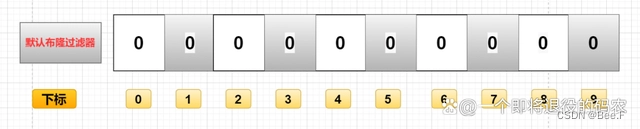
如何添加数据?
布隆过滤器的数据添加过程主要分为以下几个步骤:
- 创建一个位数组,初始化所有位为 0。
- 设定 k 个哈希函数。
- 对要添加的元素进行 k 次哈希操作,得到k个哈希值。
- 将位数组中这k个位置的值都设为 1。
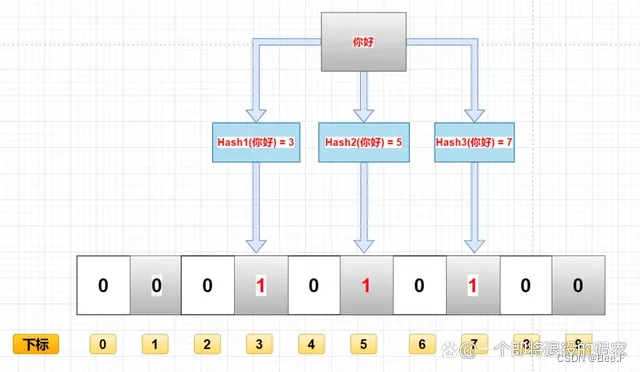
举个例子,假设要将字符串"hello world"添加到布隆过滤器中,该布隆过滤器使用3个哈希函数,位数组大小为 10,步骤如下:
- 创建一个大小为 10 的位数组,初始化所有位为0。
- 设定3个哈希函数,如下:
- 哈希函数1:将字符串转化为一个整数,然后将整数对 10 取余
- 哈希函数2:将字符串中的每个字符的 ASCII码 值相加,然后将和对 10 取余
- 哈希函数3:将字符串翻转,然后将翻转后的字符串转化为一个整数,然后将整数对10取余
- 对字符串"hello world"进行3次哈希操作,得到3个哈希值分别为2、5、8。
- 将位数组中 2、5、8 这 3 个位置的值都设为 1。
添加完数据后,当检查某个元素是否在布隆过滤器中时,只需要进行和添加数据相同的哈希函数操作,检查对应的位数组的值是否为 1 即可。如果所有哈希函数操作对应的位数组值都为 1,那么该元素可能在集合中,如果其中任何一个位数组值为 0,则该元素一定不在集合中。
如何查询数据?
布隆过滤器的数据查询过程主要分为以下几个步骤:
-
对要查询的元素进行 k 次哈希操作,得到k个哈希值。
-
查位数组中这 k 个位置的值是否都为1。
-
如果这 k 个位置的值都为1,则认为该元素可能在集合中;否则,认为该元素一定不在集合中。
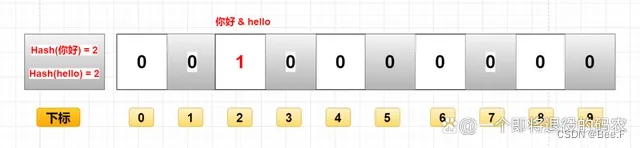
举个例子,假设布隆过滤器中已经添加了字符串"hello world",布隆过滤器使用3个哈希函数,位数组大小为 10,查询字符串"hello"是否在布隆过滤器中,步骤如下:
-
对字符串"hello"进行3次哈希操作,得到3个哈希值分别为2、5、8。
-
检查位数组中 2、5、8 这 3 个位置的值是否都为 1。
-
如果这 3 个位置的值都为1,则认为字符串"hello"可能在集合中。
由于布隆过滤器可能会出现误判,因此在实际应用中,需要根据具体的应用场景来确定误判率的可接受范围,并相应地设置哈希函数数量和位数组大小。同时,需要注意,布隆过滤器无法删除已添加的数据。
二、布隆过滤器优缺点
布隆过滤器的优点包括:
-
时间和空间效率高:布隆过滤器的时间复杂度和空间复杂度都是O(k),其中k为哈希函数的数量。因此,它可以在较小的空间内快速判断某个元素是否在集合中。
-
误判率低:布隆过滤器虽然可能出现误判,但是误判率可以通过调整哈希函数数量和位数组大小来控制,可以根据实际需求进行调整。
-
支持高并发:布隆过滤器支持并发查询和添加数据,可以在多线程环境下使用。
-
易于实现:布隆过滤器的实现比较简单,只需要实现几个哈希函数和一个位数组即可。
布隆过滤器的缺点包括:
-
无法删除已添加的数据:由于布隆过滤器的哈希函数不具有逆向性,所以无法删除已添加的数据。
-
误判率无法避免:由于布隆过滤器的设计原理,误判率无法避免。当哈希函数的数量不足或位数组的大小不够时,误判率可能会很高。
-
无法精确判断元素是否存在:由于布隆过滤器的设计原理,无法精确判断某个元素是否在集合中,只能判断它可能存在或一定不存在。
三、减少布隆过滤器的误判
布隆过滤器的误判率是根据哈希函数的数量和位数组大小来确定的。如果哈希函数的数量太少或者位数组太小,那么误判率会增加。反之,如果哈希函数的数量太多或者位数组太大,那么可能会导致空间浪费和查询效率降低。因此,在实际使用中,需要根据具体的应用场景来确定哈希函数数量和位数组大小,以达到误判率和空间利用率的平衡。
除了调整哈希函数数量和位数组大小之外,还可以采用以下方法来减少布隆过滤器的误判率:
-
使用多个布隆过滤器:将同一个元素添加到多个布隆过滤器中,查询时需要在所有布隆过滤器中查询。这种方法可以显著降低误判率,但是会增加存储空间和查询时间。
-
使用加密哈希函数:加密哈希函数可以使哈希值更难以预测,从而减少哈希冲突的概率。常见的加密哈希函数包括 MD5、SHA-1 等。
-
使用高质量的哈希函数:使用高质量的哈希函数可以减少哈希冲突的概率。常见的高质量哈希函数包括MurmurHash、CityHash 等。
-
对于数据量较小的情况,可以使用简单的线性查找代替布隆过滤器,这样可以避免误判率过高的问题。
需要注意的是,误判率是布隆过滤器的本质限制,无法完全避免。因此,在使用布隆过滤器时,需要根据实际需求来平衡误判率和空间利用率,同时采用多个布隆过滤器、使用高质量的哈希函数等方法来尽量减少误判率。
四、使用场景
1. 缓存系统
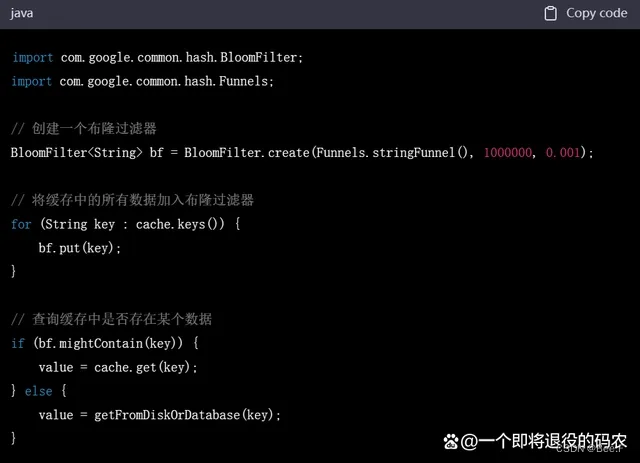
缓存系统是一个常用的场景,布隆过滤器可以用来判断某个数据是否在缓存中。在实际操作中,可以先将缓存中的所有数据放入布隆过滤器中,然后查询时先查询布隆过滤器。如果查询结果表明该数据不存在,就说明该数据不在缓存中,需要从磁盘或者数据库中获取。如果查询结果表明该数据存在,就可以直接从缓存中获取,无需进行磁盘或数据库的访问。下面是一个使用布隆过滤器进行缓存判断的 Java 代码示例:
2. 网络爬虫
网络爬虫是另一个常用的场景,布隆过滤器可以用来去重已经爬取过的 URL。在实际操作中,可以将已经访问过的 URL 放入布隆过滤器中。每当需要访问一个新的 URL 时,先查询布隆过滤器。如果查询结果表明该 URL 已经存在,就说明该页面已经被爬取过,可以忽略。如果查询结果表明该 URL 不存在,就说明该页面尚未被爬取过,需要进行访问。下面是一个使用布隆过滤器进行网络爬虫去重的 Java 代码示例:
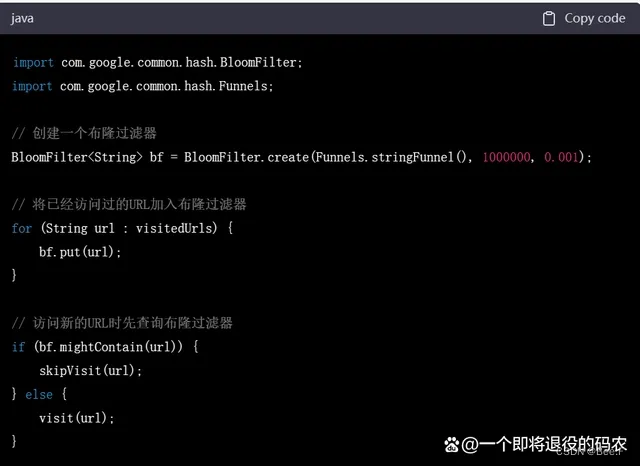
3. 数据库系统
数据库系统是另一个常用的场景,布隆过滤器可以用来加速数据库查询。在实际操作中,可以将数据库中的所有关键字放入布隆过滤器中。每当需要查询某个关键字时,先查询布隆过滤器。如果查询结果表明该关键字不存在,就可以直接返回查询结果为空,无需进行数据库的访问。如果查询结果表明该关键字存在,就需要进行数据库的访问,查询具体的数据。下面是一个使用布隆过滤器进行数据库查询加速的 Java 代码示例:
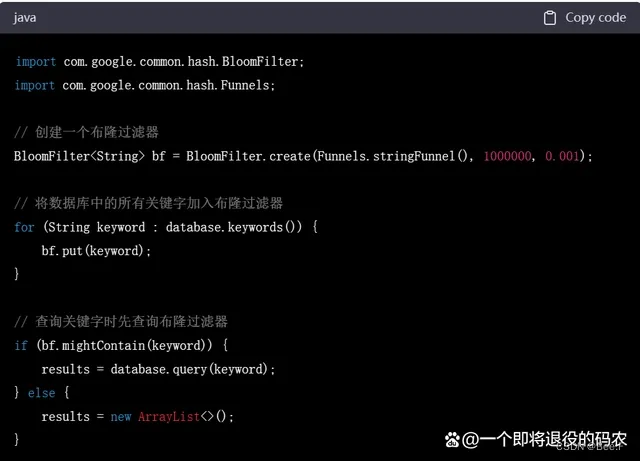
4. 分布式系统
分布式系统是另一个常用的场景,布隆过滤器可以用来快速地判断某个元素是否在分布式系统中。在实际操作中,每个节点都可以维护一个布隆过滤器。当需要查询某个元素是否在分布式系统中时,可以将查询请求发送到所有节点,并在每个节点上查询布隆过滤器。如果查询结果表明该元素存在于任意一个节点中,就可以直接返回查询结果为真,无需进行进一步的操作。如果查询结果表明该元素不存在于任何一个节点中,就可以直接返回查询结果为假,无需进行进一步的操作。下面是一个使用布隆过滤器进行分布式系统元素查询的 Java 代码示例:
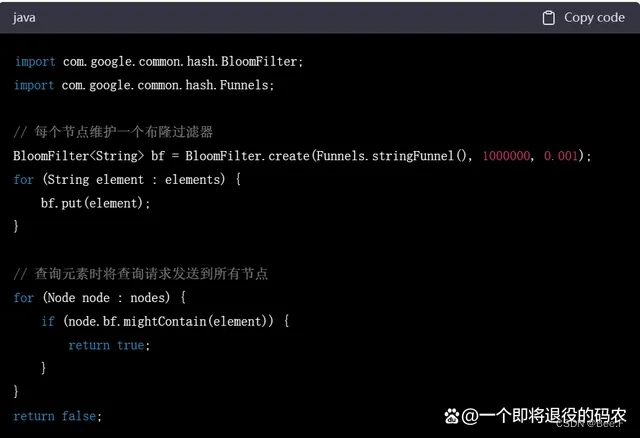
5.Redisson组件
Redis 实现布隆过滤器的底层就是通过 bitmap 这种数据结构,在 Java 中提供了一个客户端工具 Redisson 组件,它内置了布隆过滤器,可以让程序员非常简单直接地去设置布隆过滤器。
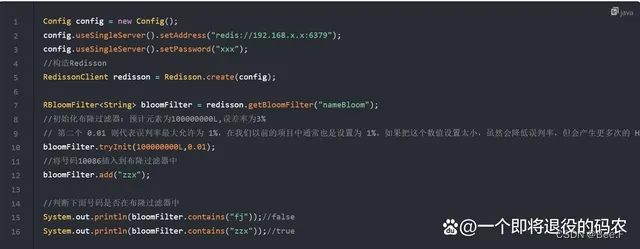
guava 工具包:

转载:https://baijiahao.baidu.com/s?id=1760676476679974031&wfr=spider&for=pc















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









