








注:version:elasticsearch-7.11.2
一.基本操作
es的文档命名格式:
PUT /{index}/{type}/{id}{
"field": "value",
...
}index:索引名。因共同的特性被分组到一起的文档集合,例如把所有产品存储在索引 /products 下,把所有交易信息存储在索引 /sales 下。
type:类型。它允许您在索引中对数据进行逻辑分区。
id:ID 是一个字符串,当它和 _index 以及 _type 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id ,要么让 Elasticsearch 帮你生成。
1.创建索引
PUT /developer
2.查询索引
GET /developer
3.删除索引
DELETE /developer

4.添加文档
PUT /developer/_doc/1
{
"name": "李雷",
"gender": "1",
"age": 18,
"address": "浙江省杭州市西湖区",
"remark": "是一个初级程序员"
}
PUT /developer/_doc/2
{
"name": "韩梅",
"gender": "0",
"age": 17,
"address": "安徽省合肥市蜀山区",
"remark": "是一个高级程序员",
"nickname": "大梅"
}
PUT /developer/_doc/3
{
"name": "李二狗",
"gender": "0",
"age": 17,
"address": "狗不理的地方"
}5.修改文档
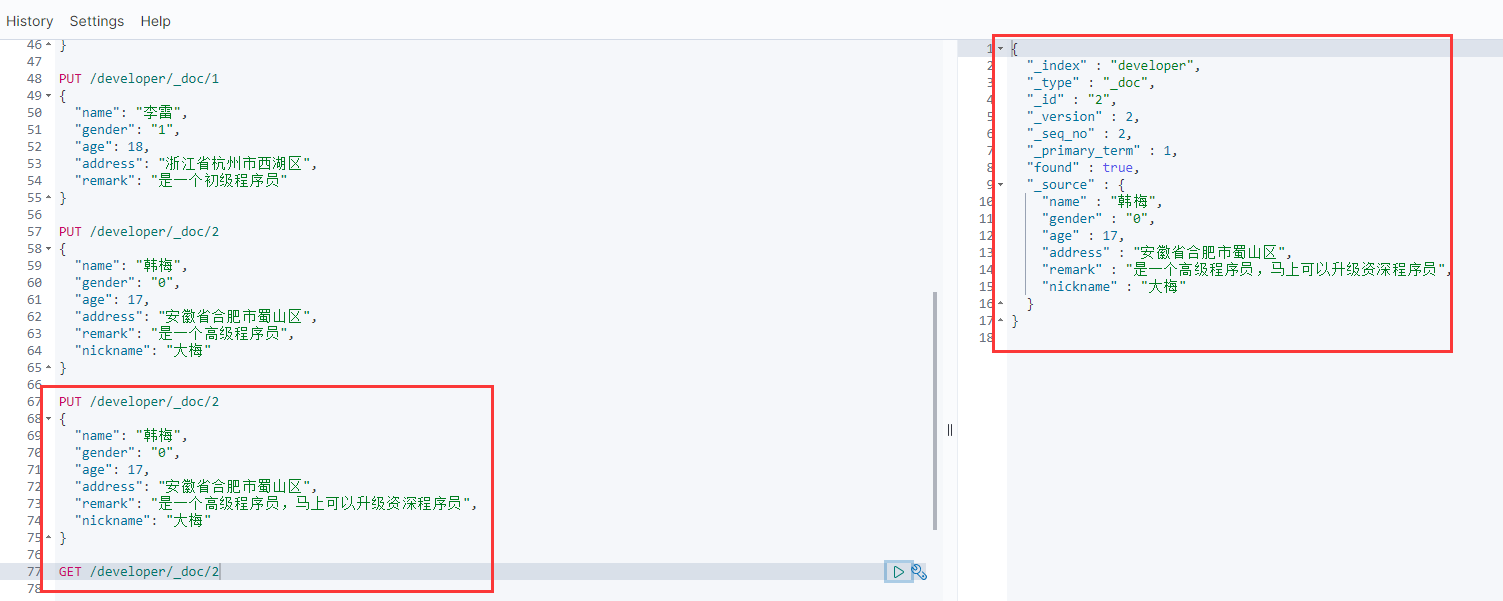
PUT /developer/_doc/2
{
"name": "韩梅",
"gender": "0",
"age": 17,
"address": "安徽省合肥市蜀山区",
"remark": "是一个高级程序员,马上可以升级资深程序员",
"nickname": "大梅"
}
注意:POST和PUT都能起到创建/更新的作用
1、需要注意的是PUT操作的是具体的文档,也就是要指定id才能操作,有id的时候更新文档,无id时创建文档;而POST是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新。
2、PUT只会将json数据都进行替换, POST只会更新相同字段的值。
3、PUT与DELETE都是幂等性操作, 即不论操作多少次, 结果都一样。
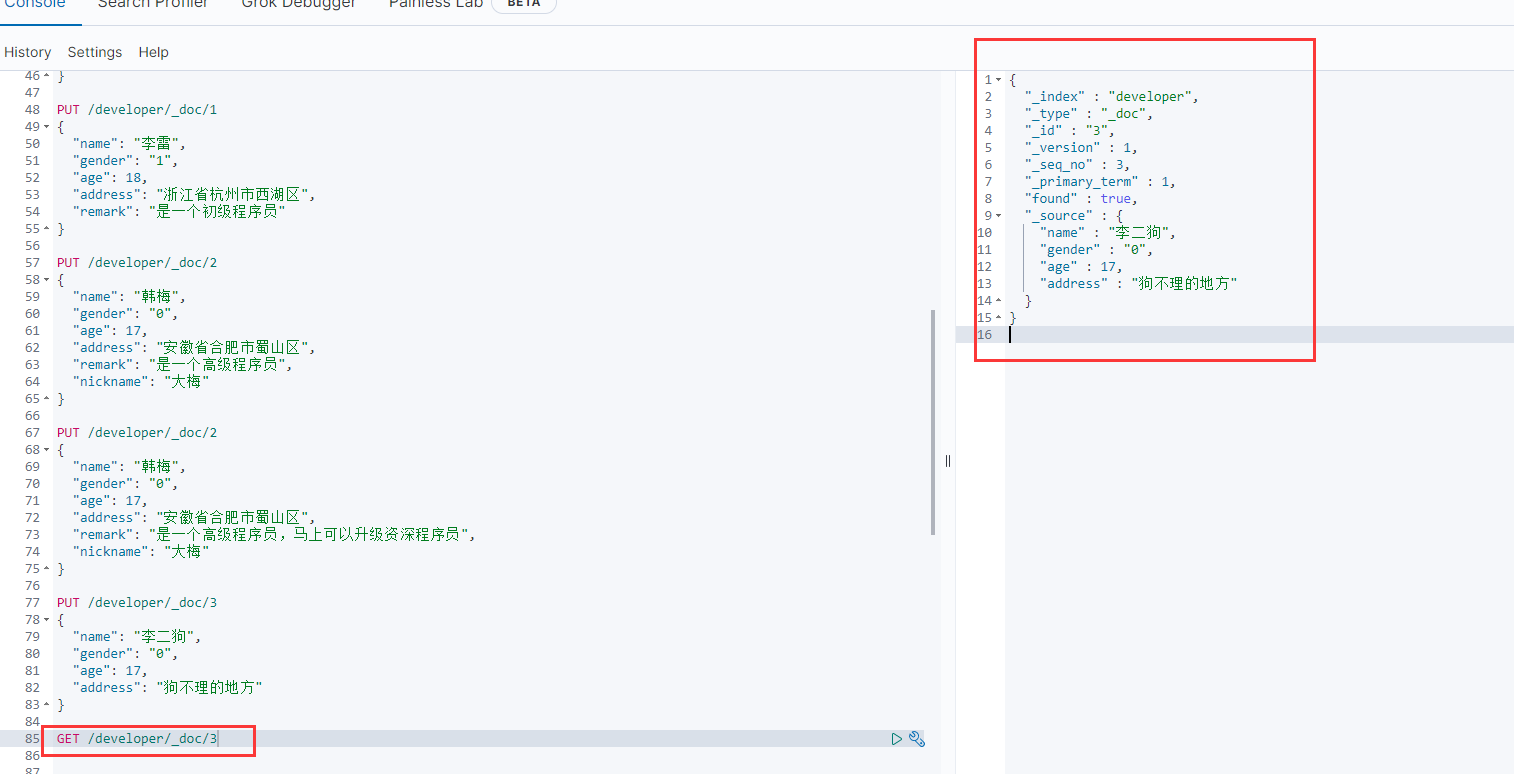
6.查询文档
GET /developer/_doc/3
7.删除文档
DELETE /developer/_doc/3
二.文档批量操作
1.批量查询 GET_mget
GET _mget
{
"docs": [
{
"_index": "developer",
"_type": "_doc",
"_id": 1
},
{
"_index": "developer",
"_type": "_doc",
"_id": 2
}
]
}
#或者在url中指定index
GET /developer/_mget
{
"docs": [
{
"_type": "_doc",
"_id": 1
},
{
"_type": "_doc",
"_id": 2
}
]
}
#或者在url中指定index和type
GET /developer/_doc/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 2
}
]
}
2.批量创建/修改 POST _bulk
批量对文档进行写操作是通过_bulk的API来实现的
- 请求方式:POST
- 请求地址:_bulk
- 请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
-
- 第一行参数为指定操作的类型及操作的对象(index,type和id)
- 第二行参数才是操作的数据
1).批量创建文档
POST _bulk
{"create":{"_index":"developer","_type":"_doc","_id":3}}
{"id":3,"name":"张三","gender":1,"remark":"初级程序员"}
{"create":{"_index":"developer","_type":"_doc","_id":4}}
{"id":4,"name":"李四","gender":1,"remark":"初级程序员"}或者这样写:
POST /developer/_bulk
{"create":{}}
{"id":5,"name":"王五","gender":1,"remark":"初级程序员"}
{"create":{}}
{"id":6,"name":"赵六","gender":1,"remark":"初级程序员"}
2).批量创建或全量替换index
POST _bulk
{"index":{"_index":"developer","_type":"_doc","_id":3}}
{"id":3,"name":"张三","gender":1,"remark":"初级程序员,平时表现不错"}
{"index":{"_index":"developer","_type":"_doc","_id":5}}
{"id":5,"name":"王五","gender":1,"remark":"初级程序员"}或者这样写:
POST /developer/_bulk
{"index":{}}
{"id":5,"name":"王五","gender":1,"remark":"资深软件工程师"}
{"index":{}}
{"id":6,"name":"赵六","gender":1,"remark":"资深软件工程师"}如果id存在就创建,如果id不存在就全量替换
3).批量修改
POST _bulk
{"update":{"_index":"developer","_type":"_doc","_id":3}}
{"doc":{"remark":"初级程序员,可以升级为中级程序员"}}
{"update":{"_index":"developer","_type":"_doc","_id":4}}
{"doc":{"remark":"高级程序员,4月升级资深"}}4).批量删除
POST _bulk
{"delete":{"_index":"developer","_type":"_doc","_id":3}}
{"delete":{"_index":"developer","_type":"_doc","_id":4}}
{"delete":{"_index":"developer","_type":"_doc","_id":5}}三.DSL语言高级查询
(DSL)Domain Specific Language,领域专用语言
dsl查询分单字段查询(叶子条件查询)和组合查询两种
1.无条件查询
GET developer/_doc/_search
{
"query":{
"match_all":{}
}
}2.单字段查询(叶子条件查询)
1).模糊匹配
模糊匹配主要是针对文本类型的字段,文本类型的字段会对内容进行分词,对查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据,模糊匹配主要通过match等参数来实现。
- match : 通过match关键词模糊匹配条件内容
- prefix : 前缀匹配
- regexp : 通过正则表达式来匹配数据
match匹配
#单个字段模糊匹配
GET developer/_doc/_search
{
"query":{
"match":{
"name": "李大雷"
}
}
}
#分页查询
POST /developer/_doc/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"name": "李大雷"
}
}
}
#多个字段模糊匹配
POST /developer/_doc/_search
{
"query": {
"multi_match": {
"query": "李员",
"fields": ["name","remark"]
}
}
}
#未指定字段模糊查询query_string,可以 AND 或者 OR。例如以下在所有字段李查找带“李”字和“程序员”关键字
POST /developer/_doc/_search
{
"query": {
"query_string": {
"query": "李 AND 程序员"
}
}
}
#指定字段模糊查询query_string,可以 AND 或者 OR。
POST /developer/_doc/_search
{
"query": {
"query_string": {
"query": "李 AND 程序员",
"fields": ["name","remark"]
}
}
}
#match_phrase 会分词查询,但是要求顺序一样
POST /developer/_doc/_search
{
"query": {
"match_phrase": {
"address": "合肥市"
}
}
}2).精确查询
term查询
term精确查询,会分词查询,但是顺序必须和查询条件一致才能匹配
POST /developer/_doc/_search
{
"query": {
"term": {
"age": 18
}
}
}range分页
范围查询 range
range:范围关键字
gte 大于等于
lte 小于等于
gt 大于
lt 小于
now 当前时间
POST /developer/_doc/_search
{
"query": {
"range": {
"age": {
"gte":18,
"lte":20
}
}
}
}
# 分页、输出字段、排序综合查询
POST /developer/_doc/_search
{
"query": {
"range": {
"age": {
"gte":17,
"lte":20
}
}
},
"from": 0,
"size": 2,
"_source": ["name", "age", "gender"],
"sort": {"age":"desc"}
}3.filter查询
filter查询的区别:
1.不参与分值计算
2.查询结果会缓存
所以filter效率会高点,缺点就是不参与分值
写法:在query和match中间加bool和filter
用例:
POST /developer/_doc/_search
{
"query": {
"bool": {
"filter": {
"match": {
"address": "杭州"
}
}
}
}
}
POST /developer/_doc/_search
{
"query": {
"bool": {
"filter": {
"term": {
"age": 18
}
}
}
}
}4.组合查询-使用bool
bool 查询也可以接受 must 、 must_not 和 should 参数下的多个查询语句。
一共两条数据
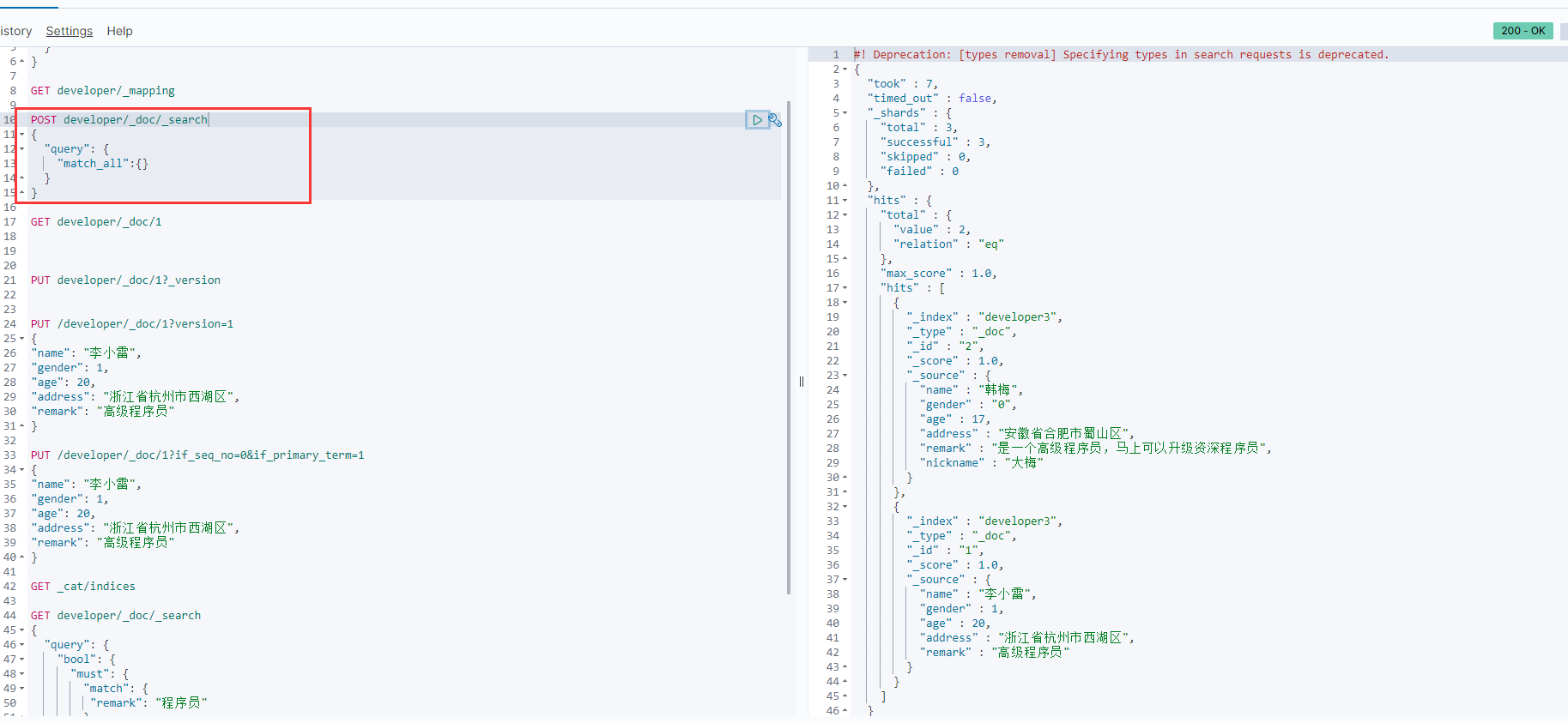
组合查询实例:
GET developer/_doc/_search
{
"query": {
"bool": {
"must": {
"match": {
"remark": "程序员"
}
},
"must_not": {
"match": {
"gender": 0
}
}
}
}
}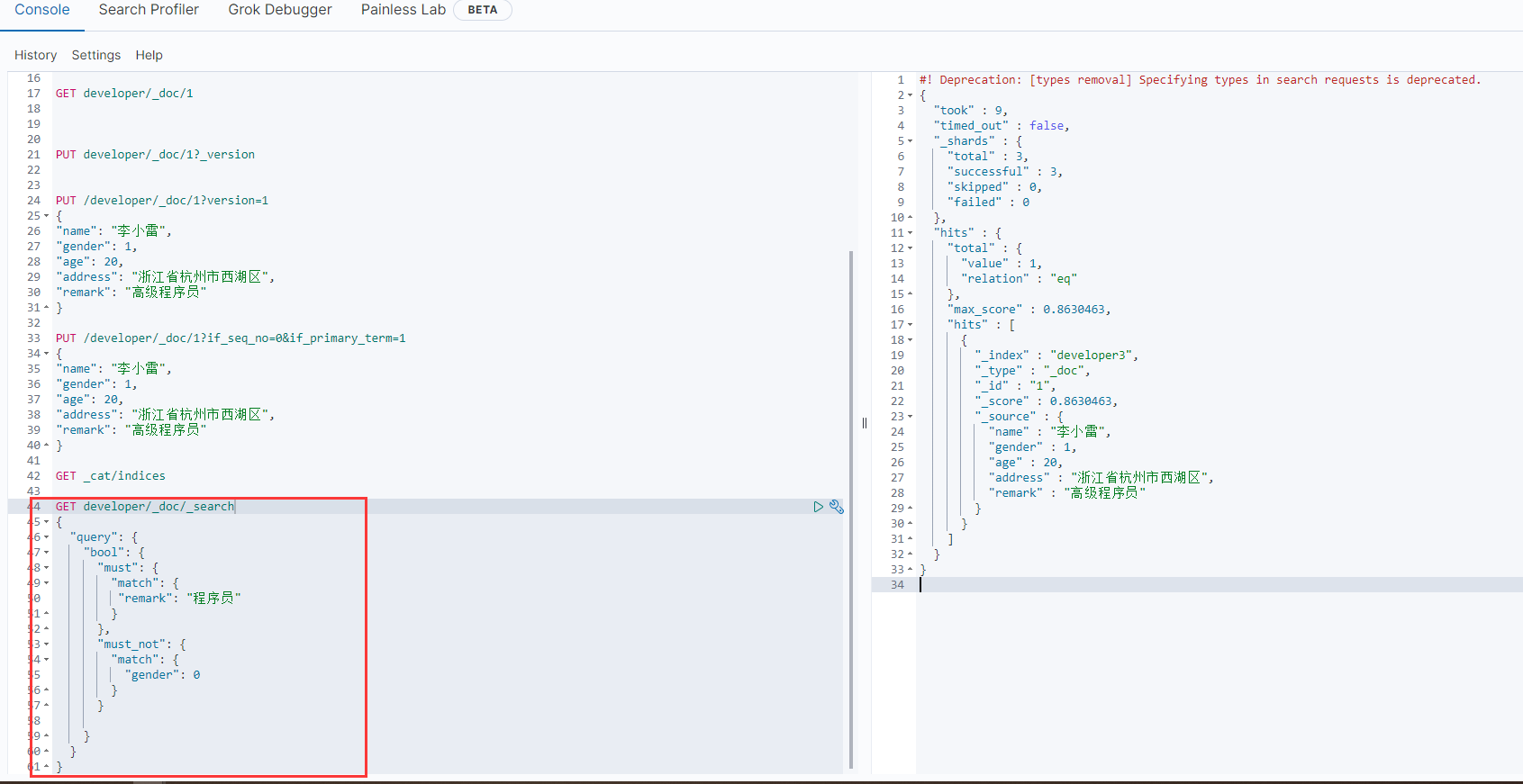
match的分词一定要包含,must_not的分词一定不能包含
以上实例,类似于sql:select * from developer t where t.remark like '%程序员%' and t.gender <> 0;
查找性别非女性程序员,结果查询出一个
GET developer/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"remark": "程序员"
}
},
{
"match": {
"address": "杭州"
}
}
],
"must_not": {
"match": {
"gender": 0
}
}
}
}
}以上实例可以匹配多个must条件
类似sql:select * from developer t where t.remark like '%程序员%' and t.address like '%杭州%' and t.gender <> 0;
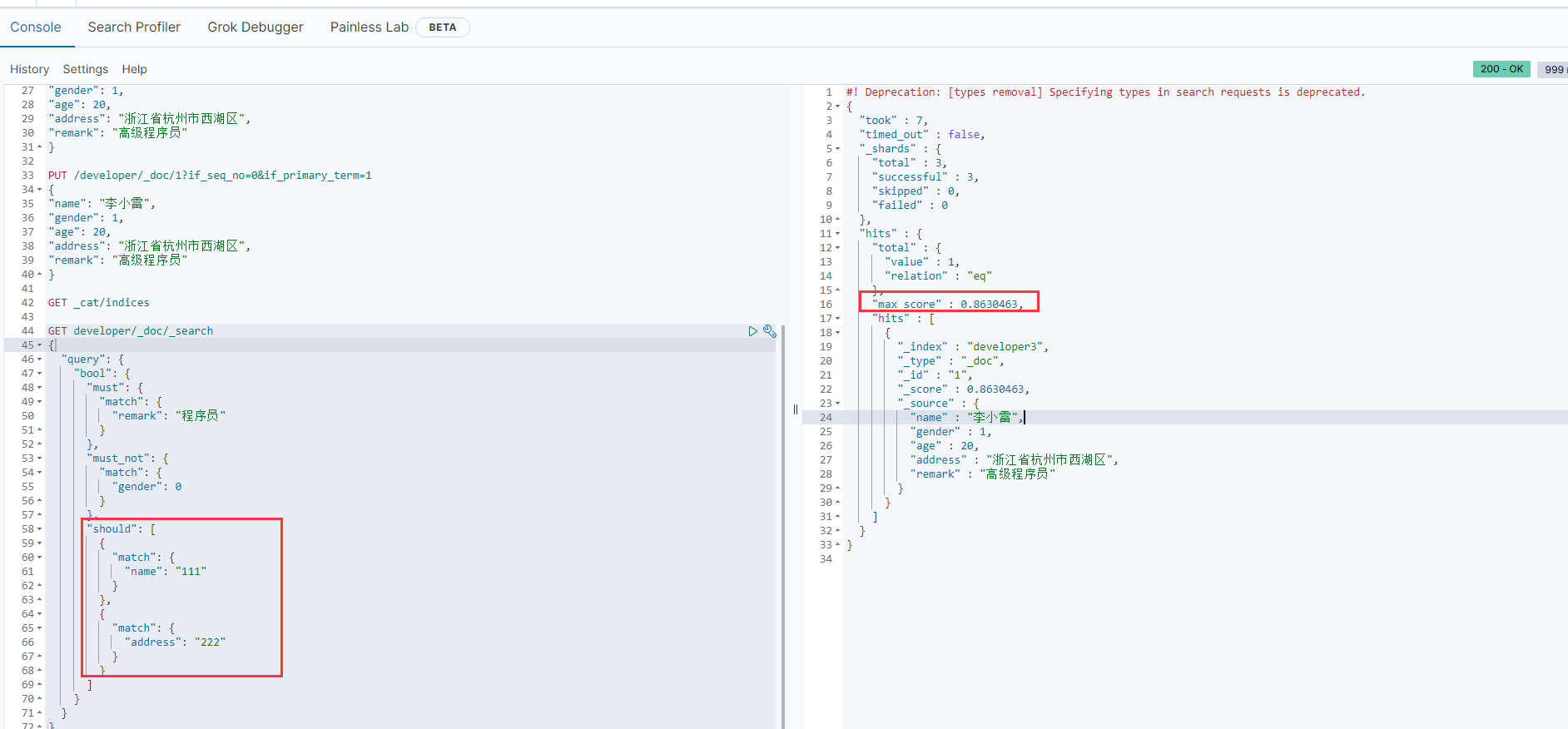
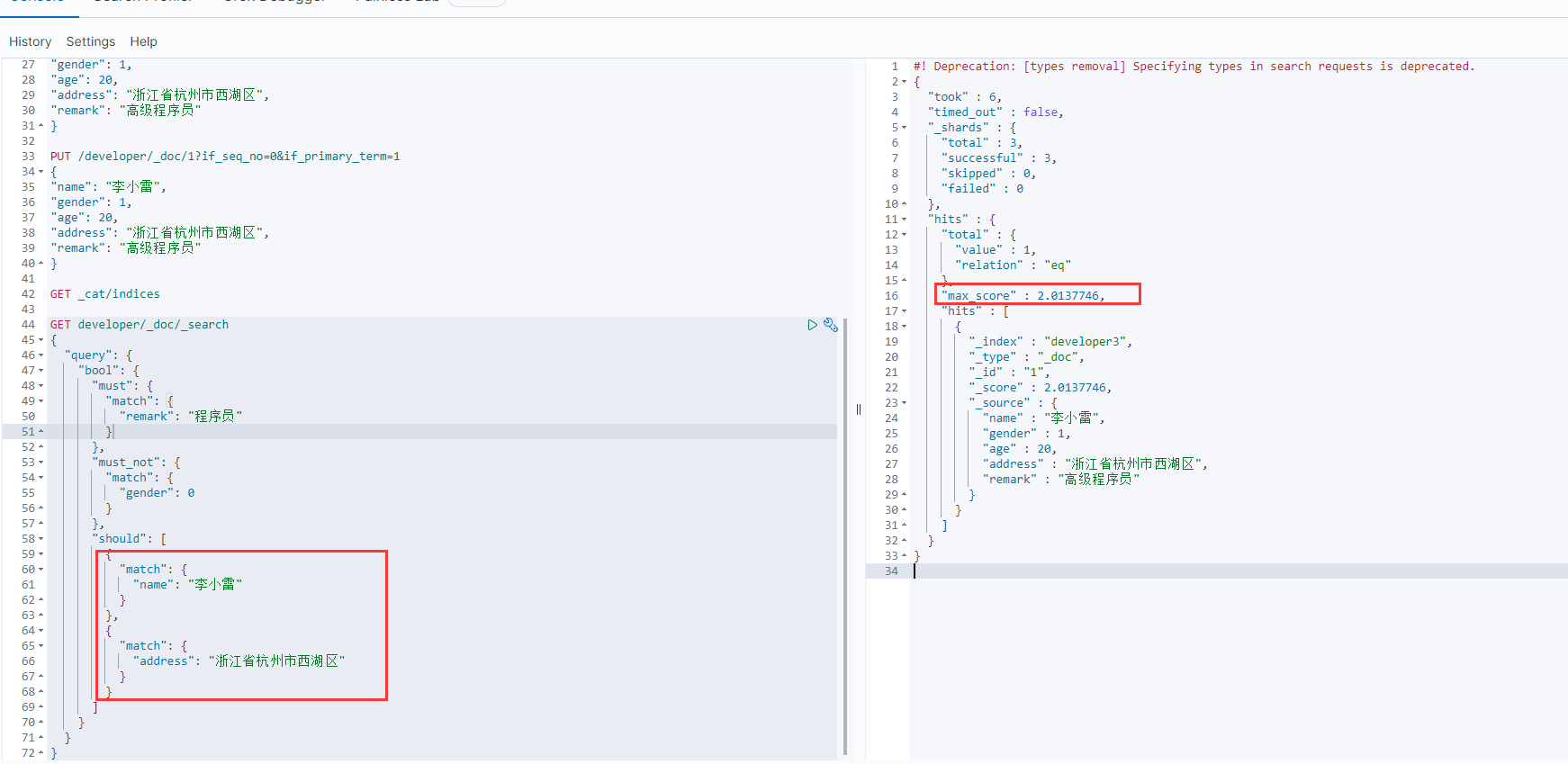
上面两张图测试结果:should全不匹配也能查询出结果,因为此处没有配置参数 minimum_should_match ,
此时should只影响到分值max_score,不影响查询出来的文档个数。
其他
1.测试的时候集群健康值:yellow
此例中使用单节点,es默认的主分片1个,副本1个。副本的作用是为了故障转移,平常主分片和副本不在同一个节点。本例中主分片和副本在同一节点,起不到故障转移的作用,so yellow。
解决方法:把副本数设置为0(限于本例测试环境,生产环境别这么搞)

2.关于_type
_type是es早期版本的设计缺陷。
在5.x以前的版本里边,一个index下面是支持多个type的,
在6.x的版本里改为一个index只支持一个type, type可以自定义。
7.x的版本所有的type默认为_doc(自定义type也能用,但是会提示不推荐)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









