









一、虚拟机的使用
首先对于Hadoop平台的,我们需要一个 vmware 工具———也就是虚拟机,对于Hadoop环境只需要建立一台主机就可,但是为了练习为多个平台节点搭建Hadoop环境,就不得不使用上VM虚拟机了。
1.安装Vmware虚拟机
对于 ubuntu 虚拟机的安装可鉴于
https://blog.csdn.net/qq_33762440/article/details/97114681
对于 windows 安装虚拟机可以自寻百度 安装低版本的 vmware 问题不大
2.在虚拟机上安装Centos 系统
安装完成 vmware 后,进行下一步操作
在虚拟机上安装 Centos 系统
为啥要选用安装 Centos 系统,而不干脆直接再安装一个 ubuntu 系统的虚拟机,去下载 Centos 系统包
因为 Centos 比较时候用来搭建服务器,因为 Centos 对于各种环境兼容性比较强
而 ubuntu 相对于 Centos 拥有更好的给使用者更好的页面交互使用,对于Hadoop更多的是基层的搭建
使用我们就需要在 vmware 虚拟机上安装 Centos 系统
打开 vmware 15 后会出现这样的一个窗口
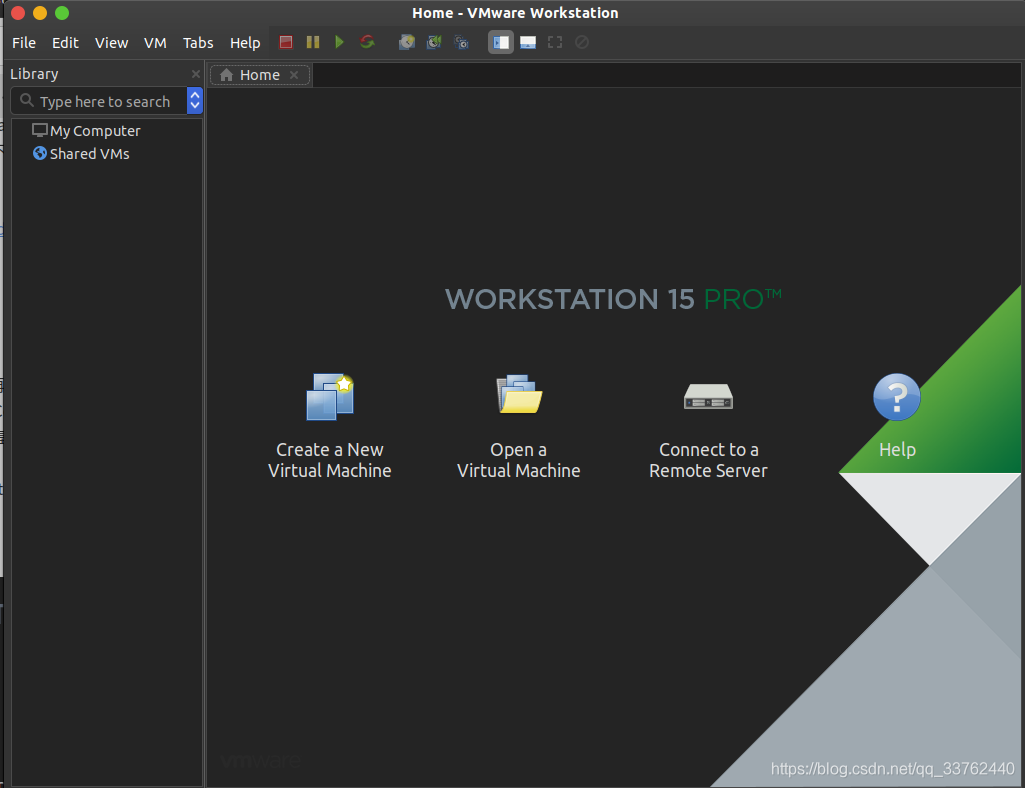
下面为典型安装与定制安装两种模式,定制安装顾名思义就是需要配置一些适合自己属性配置,对于定制安装可自行研究
这里我们选着典型安装,使用已经设置好了的属性配置
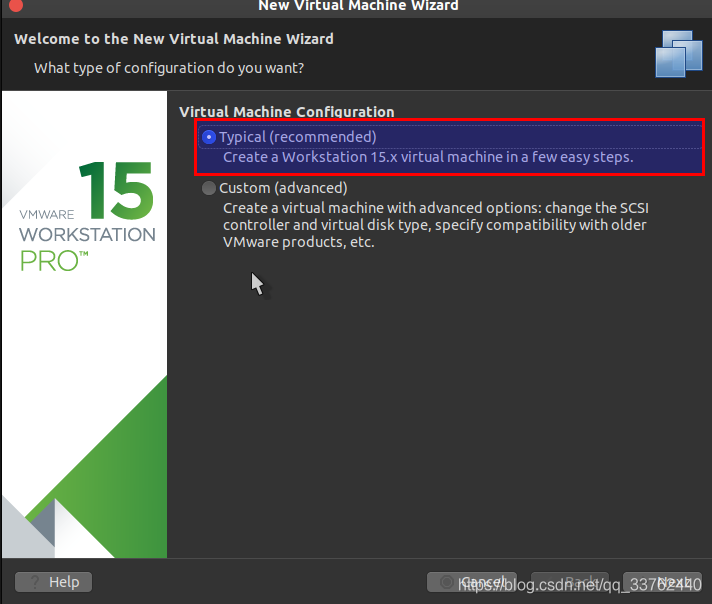
勾选后,选择右下角的 next 进行下一步
点击 Browse ,找到自己下载的 Centos 系统,选择 iso 包 ,也就是以 iso 为后缀的文件
填入后会出现 iso 所对于的版本信息,当没有出现的时候就说明系统包出现了问题,需要重新下载
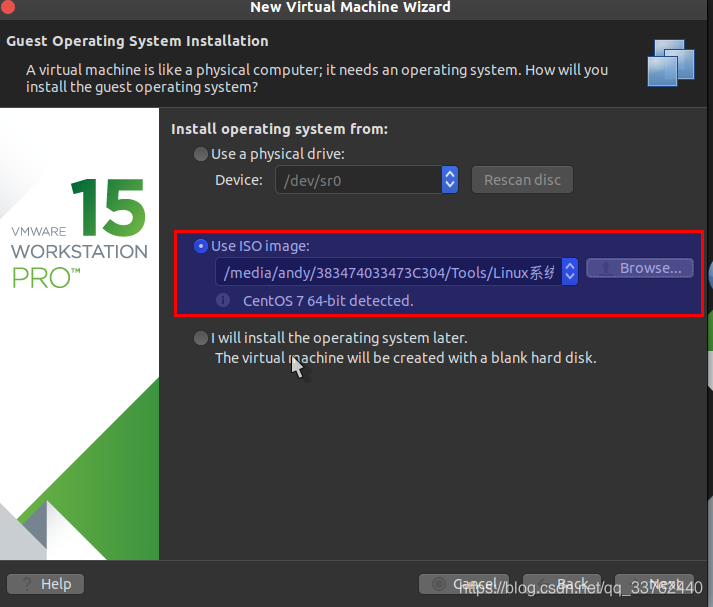
填入好后,我们再次点击 next 进行下一步
在此之后,不想对虚拟机创建系统有更多的了解,即可直接选着 next 直到 Finish 后完成 虚拟机对 Centos 系统的安装配置
直接跳至 Centos 系统的安装
这个界面就是对系统选择进行确认,一般保持默认不动
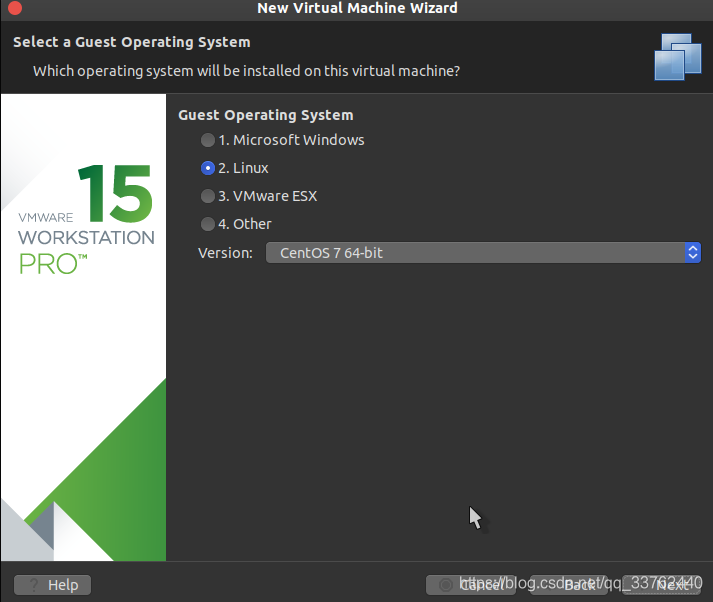
直接选择 next 进行下一步操作
在这里 Name 为虚拟机的名字,和变量是一样的意思,修改不修改都可以,不过为了后续操作更加便利,最好是改一下
然后下面的 Location 就是选着虚拟机的存放路径了,这个千万别改,改了就会出现找不到虚拟机,虚拟机受损的问题
如果要改的话,就要在虚拟机的默认配置中进行修改
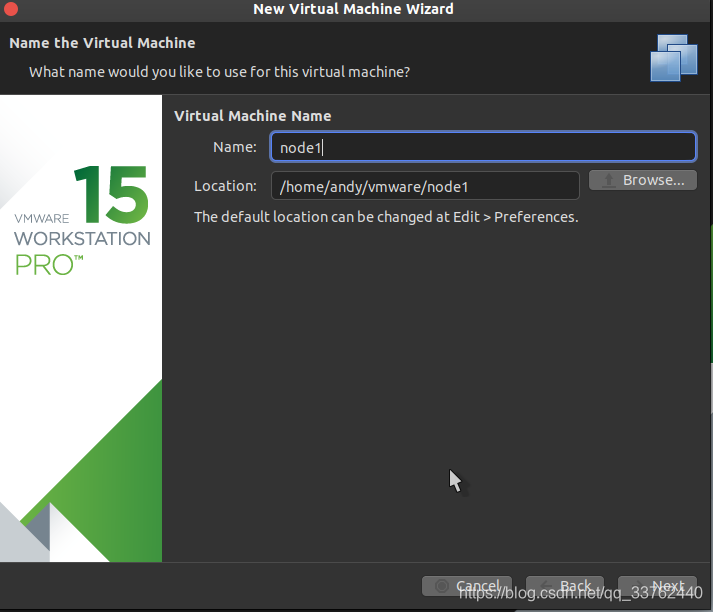
点击 next 进行下一步操作
在这里 Maximum disk size (in GB): 是对虚拟机的内存进行管理,一般设置是给予 20G 的大小作为这个系统的使用空间
下面两个
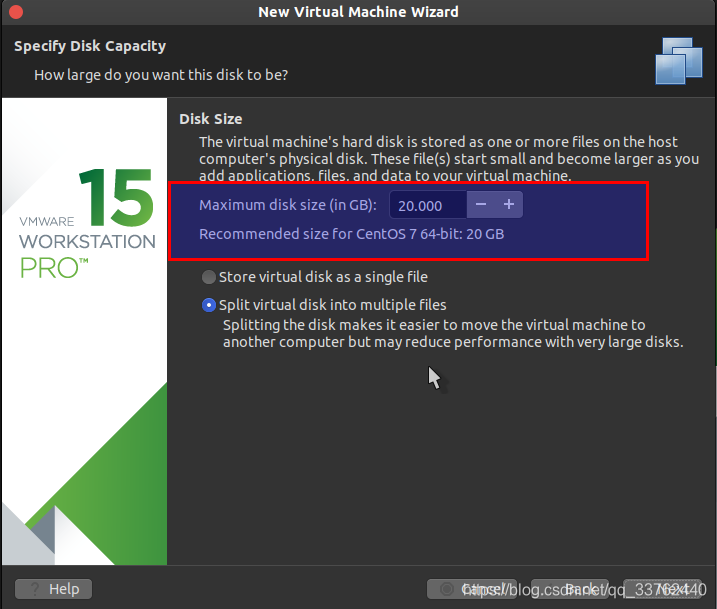
再次点击 next ,进入配置界面
该界面为虚拟机的配置信息,可以点击 Cusuomize Hardware 按钮进行修改,我们这里选择默认即可
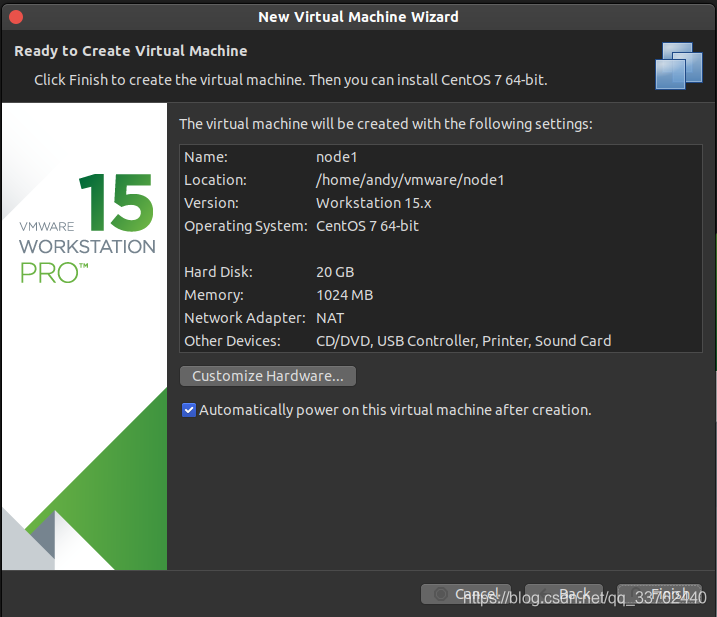
点击Finsh完成虚拟机配置,安装 Centos 系统
二、Centos 系统的安装
1.开始安装 Centos 系统
我们打开这个名为 node1 的虚拟机启动后到达这个界面,使用方向键选择 Install CentOS 7,回车确认
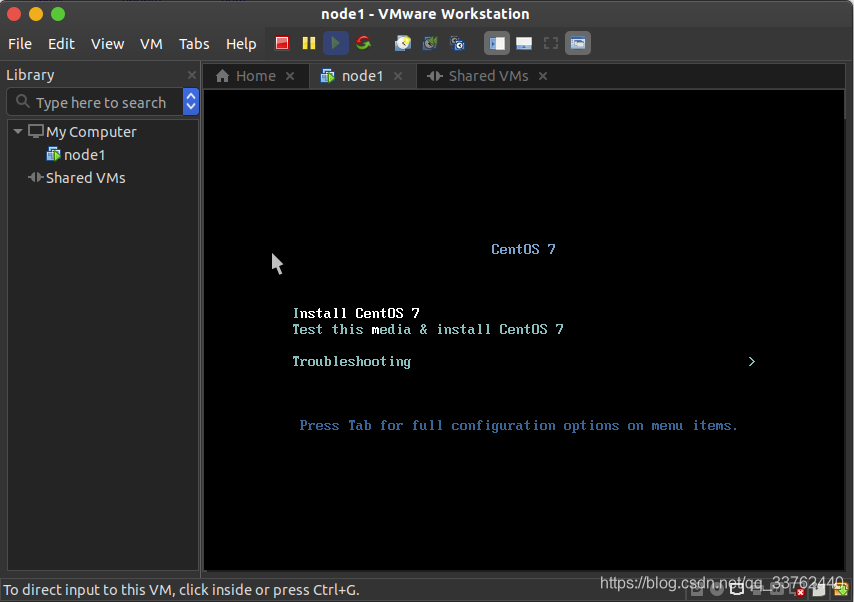
2.设置 Centos 7 系统语言
进入 Centos 7 的安装界面,为了方便使用,我们将语言设置为中文,点击右下角继续选择下一步操作
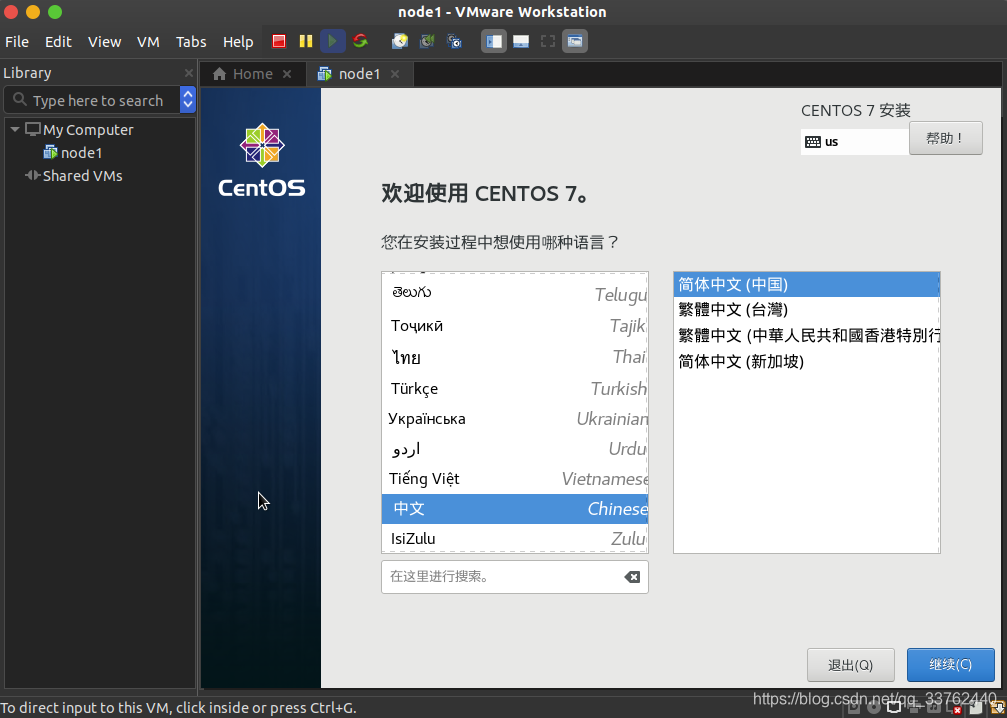
3.设置任务说明
我们要对 软件选择、安装位置、网络和主机名 这三个设置进行修改
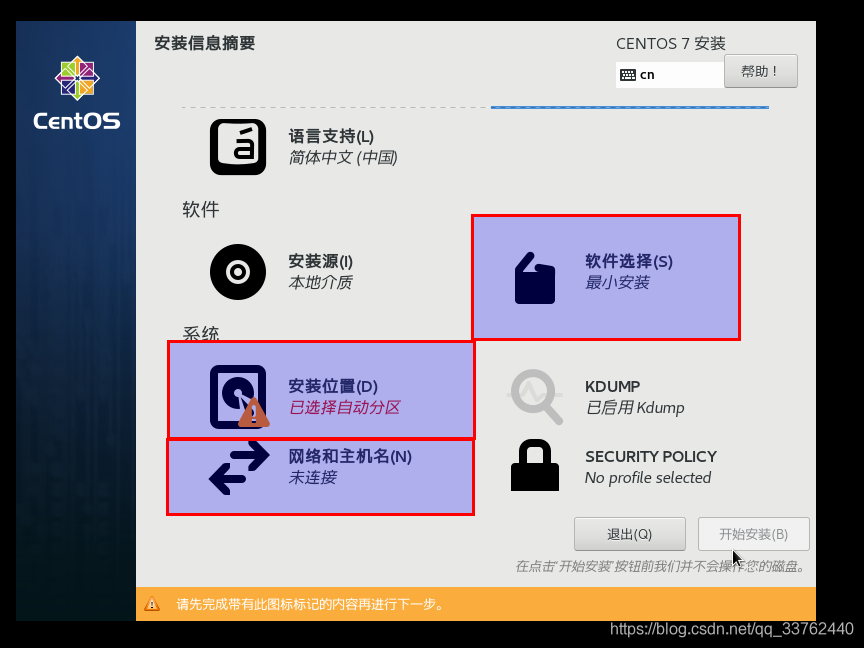
4.设置Centos 7 的 GNOME 桌面
首先我们看到软件设置,如果不需要安装桌面的话可以选择最小安装,这里我们选择安装一个 GNOME 桌面
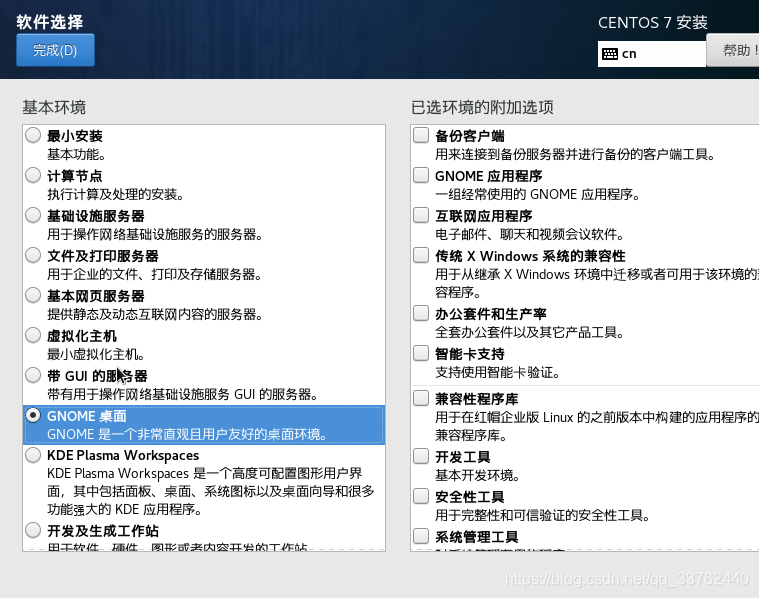
点击完成,回到之前的设置界面
5.分配系统空间
我们这次对安装位置进行修改,点击安装位置
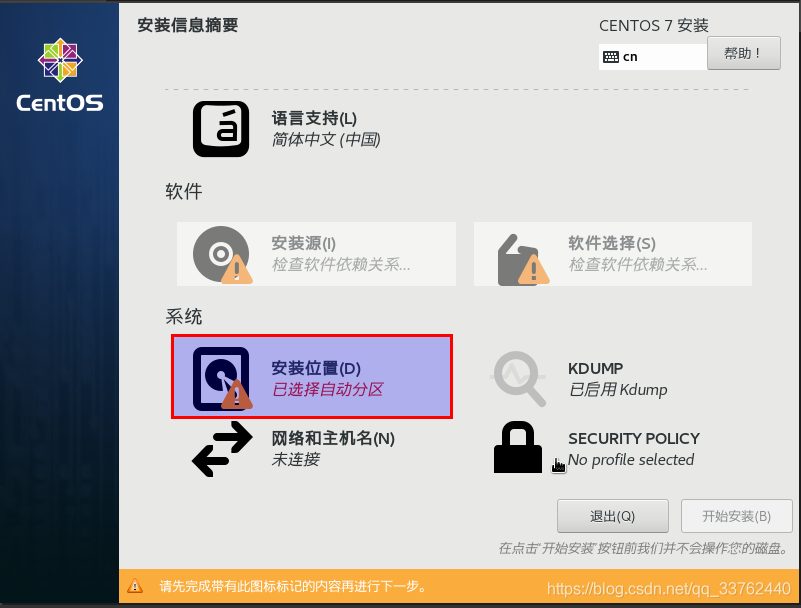
我们选择我要配置分区,然后点击完成,进入分区设置
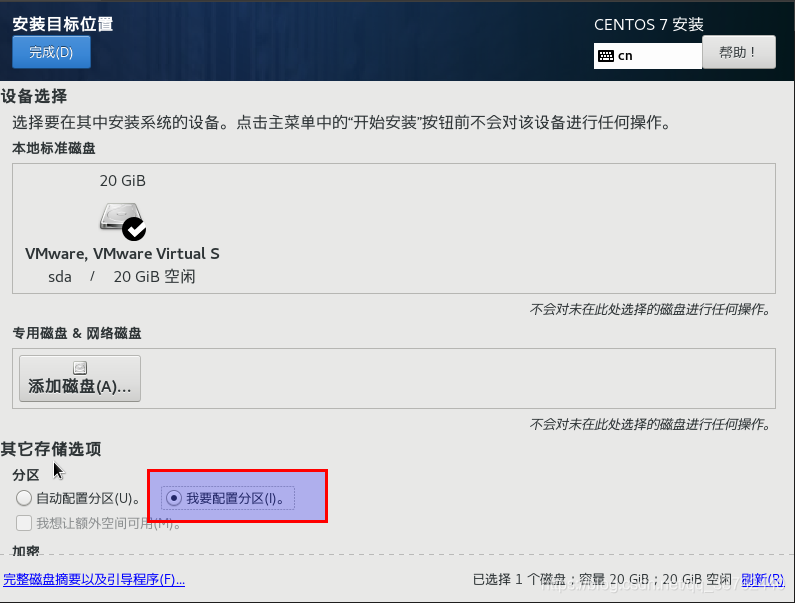
我们点击“+”号,对“/boot”“swap”“/”三个挂载点进行配置期望容量,分别设置为“1024” “2048”“空”(就是期望容量不填)
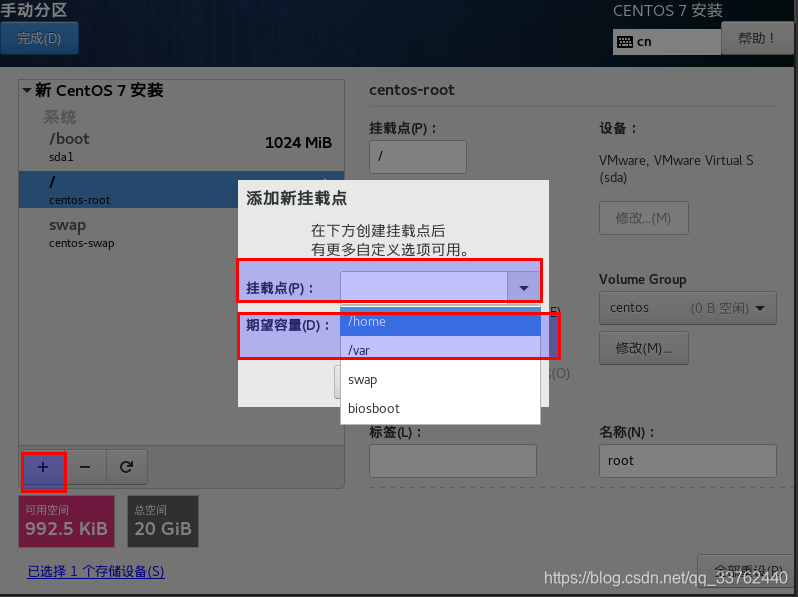
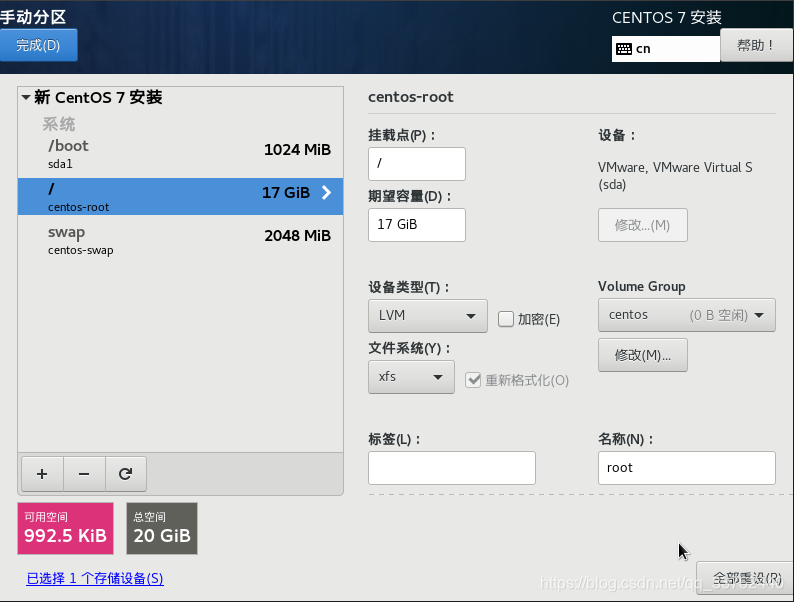
设置完成是图下的样子,点击完成,再点击接受更改,进行 Centos 最后一步配置
6.在安装界面设置 Centos 7 的网络与主机名
最后修改网络和主机名
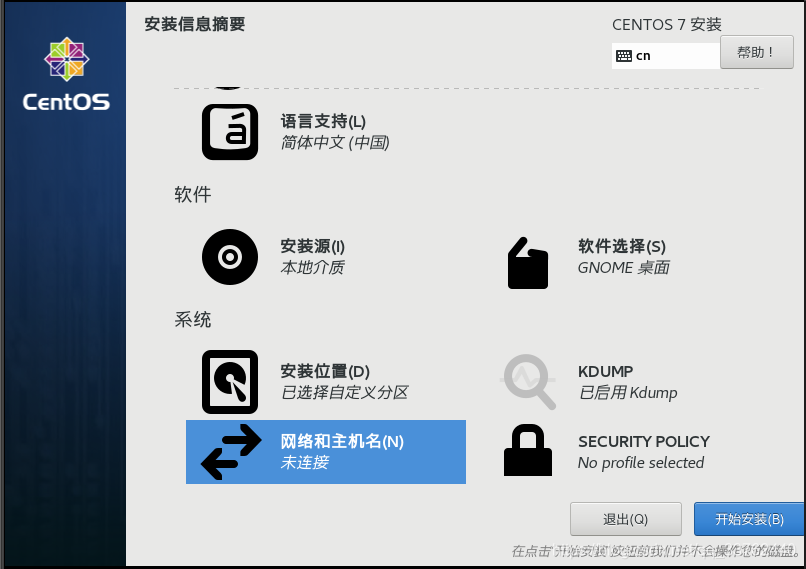
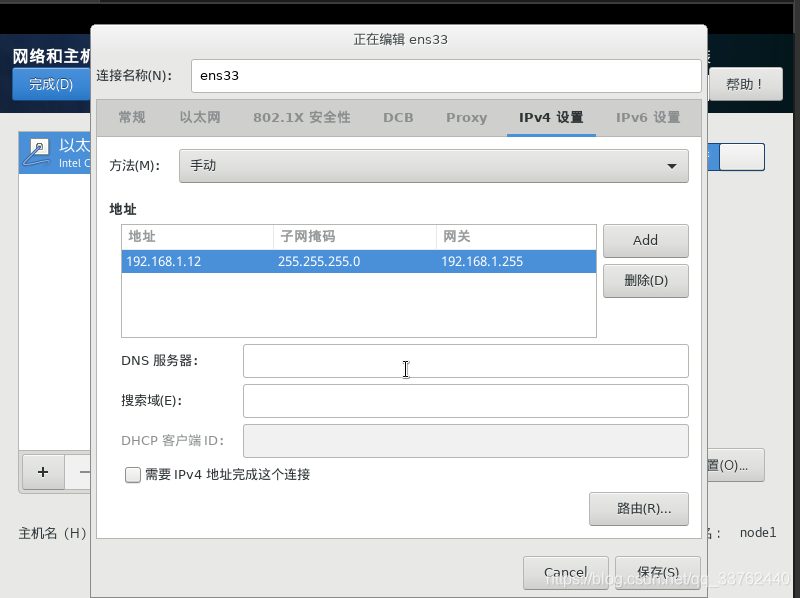
我们修改主机名为 node1 然后点击应用,直至右下角出现主机名为 node1 为设置完成,我们再将以太网打开,点击配置按钮

我们选择 ipv4 设置,修改方法为手动,设置为自己网络相同网段的 ip 地址即可,然后子网掩码一般为 255.255.255.0 ,然后网关为自己电脑相同的网关,设置完成后分别点击 保存,完成,开始安装
对于此步骤可参考
https://blog.csdn.net/qq_33762440/article/details/99350868
安装过程中设置一下 Root 密码即可,当密码过于简单的时候会提示是否继续使用该密码,再次点击完成即可设置成功,一般建议设置密码为 1
安装完成后重启,重启发现要同意许可证,同意即可,安装完成后会出现用户配置界面,不懂的尽量按默认配置来,无论配置什么信息,都对下面的内容没有任何影响
三、使用Centos 7 系统
Ubuntu 与 Centos 系统免秘钥配置一样,这里使用Ubuntu与Centos进行操作
1.配置 Ubuntu 系统与 Centos 系统免秘钥登录
对于Windows,就再重新创建一个名为 node2 的 Centos 系统,实行以下相同的操作即可
2.进行 Centos 对自己的免秘钥
打开 Centos 系统的终端
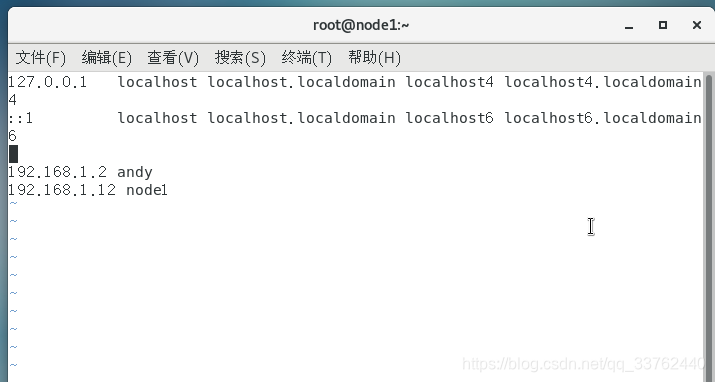
在终端中输入 vim /etc/hosts ,然后输入 i 进入编辑模式,并且在最后一段输入 自己的 ip 地址,以及计算机名
第一条是我 Ubuntu 的 ip,第二条是我们配置的 Centos 系统的 ip
填入好后,按上 ESC 键, " : " 两个键输入 wq 保存即可
完成 ip 修改后我们来实现一下本机的免秘钥
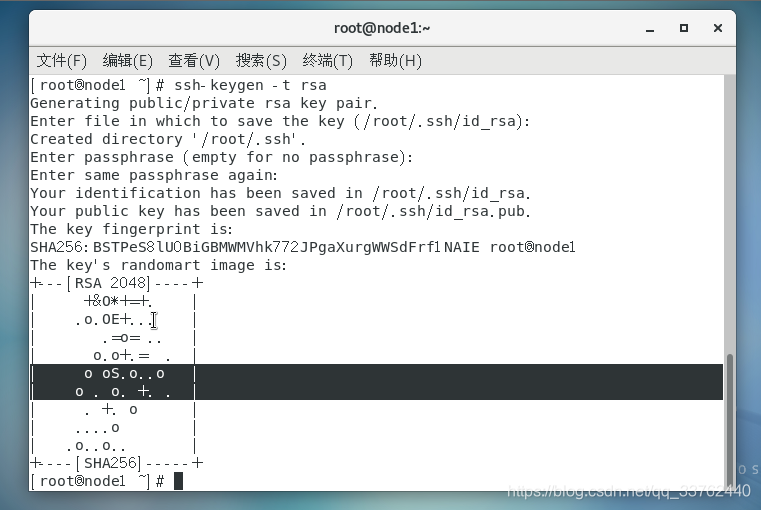
在终端输入 ssh -keygen -t rsa,然后一直回车直到出现类似 [root@node1 ~]# 结束就可以了(一共是按四下回车)
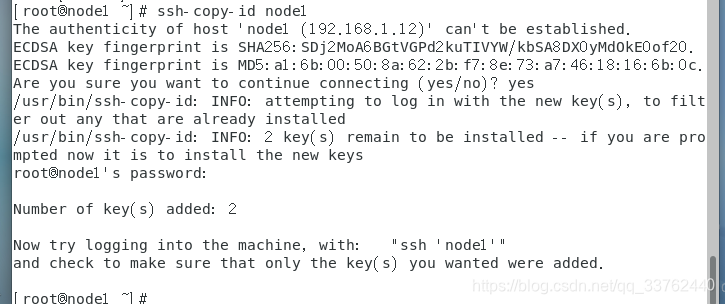
然后输入 ssh-copy-id node1,输入 yes,同意创建新的文件夹,再输入当前用户的密码就可以了
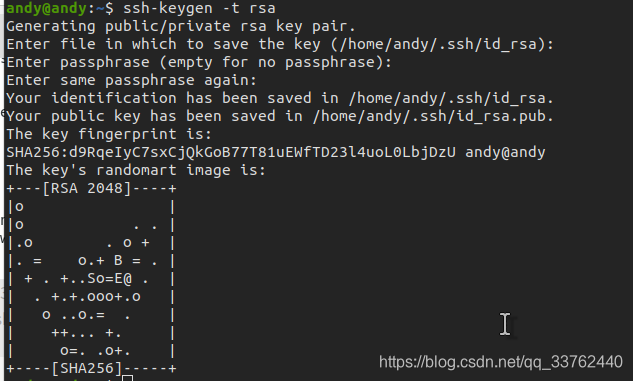
3.进行 Ubuntu 的免秘钥设置
与 Centos 系统相同的步骤
在终端输入 vim /etc/hosts,再最后一行添加以下 Ubuntu 与 Centos 的 ip 即可

完成配置后使用 ssh node1 指令控制 Centos 系统
成功样式

4.Windows 系统解决方法
一种是给 Windows 安装 SSH 工具
一种是在虚拟机再次安装一个虚拟机
对于第一种安装比较麻烦,不推荐使用
我们使用第二种方法,重新创建一个新的虚拟机,名为 node2 实现上面的重复操作就可以了,ip 要修改成不同的,不然无法达到远程控制的作用
5.使虚拟机达到相互免秘钥
Ubuntu 系统由于防火墙的原因无法使其他系统使用 ssh 访问,所以这里就实现以下 Ubuntu 系统切换为 Centos 系统的终端操作
我们在以上就做好了各个系统的免秘钥,以及 hosts 标记我们这里就可以了切换系统终端的操作
其实挺简单的,就是将其他系统上的秘钥拷贝到其他系统中就可以实现了,难点在于 SSH 指令这里,没学过或者没使用过,根本就不知道有这个使用的方法,我们下面介绍一下
| 指令 | 解释 |
|---|---|
| ssh root@主机名 [Linux系统指令] | 这是使用其他系统对当前系统操作 |
| scp 文件路径 root@主机名:文件路径 | 这是使用当前系统传送数据给其他系统 |
下面进行实践一下
选择主系统,当前我的主系统是在 Ubuntu 系统下,我们切换为 root 权限用户,进入 ssh 目录
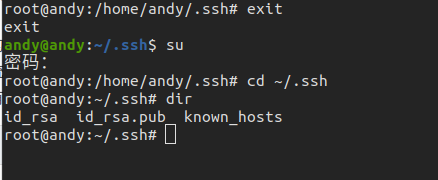
我们将 node1 上的免秘钥拷贝至 Ubuntu 的 authorized_keys 中
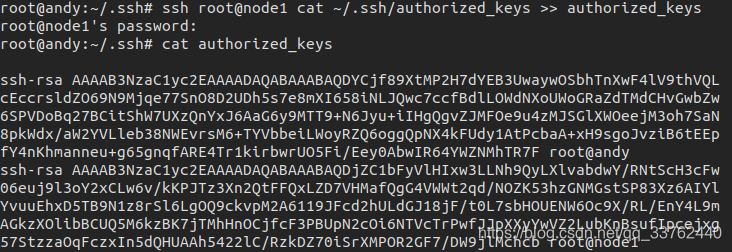
我们使用 scp 将文件传送给其他系统上

我们实验一下,切换至其他系统,如图没有输入密码,配置完成

对于两个 Centos 系统来说是一样的操作,就是将其中的秘钥相互传递,达到共享的操作即可
完成这一步呢,我们的基本环境算是搭建好了
四、Hadoop 平台搭建
以下部署均在 Centos 上部署,与 Ubuntu 系统部署相同
注意1:以下操作均在 root 用户下实现
注意2:这里平台搭建将下载的 tar 包全部放在 /usr/local/src/apk 中
注意3:防火墙为关闭状态(如果不知道如何关闭防火墙,在以下部署内容中为提到,使用请仔细阅读以下部署步骤)
这里给出集群配置中虚拟机简单配置,方便文章后面的阅读
| 主机IP | 主机名 | 系统 |
|---|---|---|
| 172.16.1.140 | node1 | Centos7 |
| 172.16.1.141 | node2 | Centos7 |
1.安装 jdk
对于 Centos 7 系统来讲,会自带一个 1.8 版本的 jdk,为了方便配置,我们首先要卸载自带的 jdk
在 Centos 7 系统的终端输入以下代码,卸载自带的jdk版本
rpm -qa|grep java|grep .x86_64 > java;for e in `cat java `;do rpm -e --nodeps $e;echo rpm -e --nodeps $e;done;rm -rf ./java
进入 /usr/local/src 目录下,解压我们拷贝的 jdk 资源包
cd /usr/local/src
解压 tar 资源包
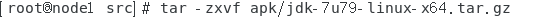
解压完成后,
系统环境变量是在 /etc/profile 文件下面修改
当前用户环境变量是在 /root/.bash_profile 文件下面修改
我们这里在 /etc/profile 里配置 jdk 环境变量
使用 vi 指令修改系统环境变量
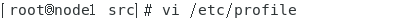
打开文件后,键入 i 键进入编辑模式,在最末尾位置添加如下配置

配置完成使用 esc 退出编辑模式,然后输入 : ,打开命令面板输入 wq 保存并退出文件
使用 source 指令,应用配置

输入 java -version 查看 jdk 版本信息

能查看到版本信息后,证明 jdk 配置完成
2.安装 Zookeeper
1).zookeeper单机部署
部署要求:使用的主机配有 jdk,zookeeper
在相同的目录下解压 zookeeper 的 tar 包

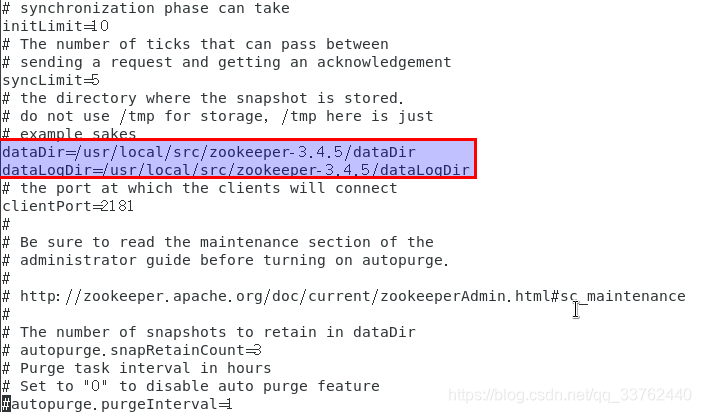
输入 mkdir /usr/local/src/zookeeper-3.4.5/dataDir;mkdir /usr/local/src/zookeeper-3.4.5/dataLogDir
分别创建存放数据信息的 dataDir 文件夹与存放日志信息的 dataLogDir
输入 echo 1 > /usr/local/src/zookeeper-3.4.5/dataDir/myid

将该主机的zookeeper ID设置为 1,相当于给 zookeeper 命名,设置 zookeeper 集群的时候需要用上

接下来在其他主机中的 zookeeper 进行同样的操作,但是 zookeeper 的 myid 要进行改变,范围为 1 ~ 255
完成后,我们修改 zookeeper 中的配置文件了
输入 cp /usr/local/src/zookeeper-3.4.5/conf/zoo_sample.cfg /usr/local/src/zookeeper-3.4.5/conf/zoo.cfg
输入vi /usr/local/src/zookeeper-3.4.5/conf/zoo.cfg修改配置文件信息
修改为如下所示:
保存文件,保存完成后进入到 zookeeper 的家目录,也就是 zookeeper-3.4.5 这个文件夹,使用指令
./bin/zkServer.sh start 启动 zookeeper
启动后,使用下面指令查看 zookeeper 是否启动成功
./bin/zkServer.sh status 查看 zookeeper 状态
启动成功后,显示如图模式为 standalone 单机模式
如果安装了 jdk 的话,可以在终端输入 jps 查看进程中是否存在 QuorumPeerMain 进程,出现的话就代表启动成功

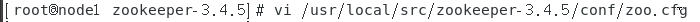



2).部署zookeeper集群分布
部署要求:使用的所有主机都配有 jdk,zookeeper
注意:启动前需要关闭防火墙,不然就会启动失败
命令: systemctl stop firewalld
相对于单机的zookeeper部署其他不变,直接修改配置文件信息
输入
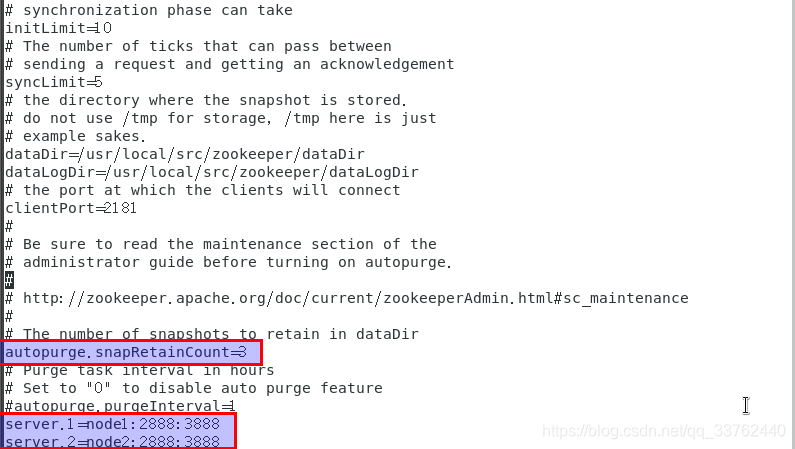
vi /usr/local/src/zookeeper-3.4.5/conf/zoo.cfg修改配置文件信息
修改为如下所示:
修改为如图所示,将node2上面的myid 修改为 2
echo 2 > ${ZOOKEEPER_HOME}/dataDir/myid
目的:将其他主机的 myid 修改,便于 zookeeper 识别集群中的信息
这里的 server 按照你主机集群上面所配置的信息的来配置
server.1为 myid 为 1 的zookeeper
server.2为 myid 为 2 的zookeeper
myid范围为 1~255
配置完成后保存文件
然后我们将 zookeeper 分别启动
我这里启动顺序为 node1,node2
出现在node1中的模式为 follower,副
出现在 node2 中的模式为 leader,主
出现上图两种模式即为完成 zookeeper 集群部署


3.安装 Hadoop
准备阶段
将 apk 文件夹中的 Hadoop tar包进行解压,获得一个完整的 Hadoop 包
我这里为了方便截图将解压过程抛空,使用 tar -zxvf apk/hadoop-2.6.0.tar.gz 指令即可

配置hadoop的环境变量
修改环境变量文件,在 jdk 环境变量后面加上就可以了
保存文件退出,输入source /etc/profile刷新配置文件信息
我们依次使用以下指令
进入 hadoop 主目录
cd hadoop-2.6.0 /
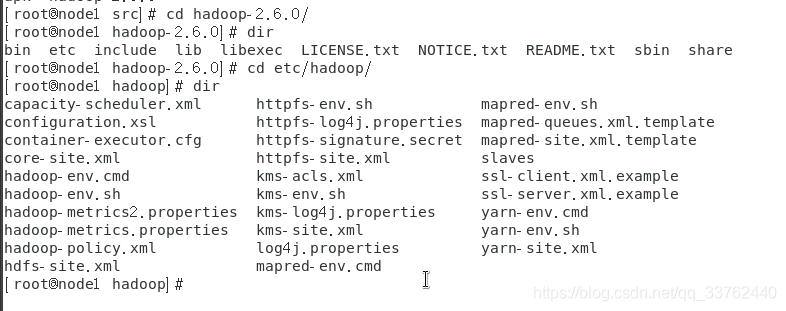
再进入 hadoop 的配置文件目录
cd etc/hadoop/
查看当前目录
dir
这个目录下的文件都是 hadoop 配置文件,在以下文件中,我们可以搭建不同作用的 hadoop
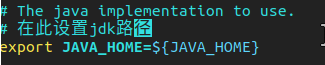
对hadoop-env.sh进行修改,找到 export JAVA_HOME=${JAVA_HOME},修改 ${JAVA_HOME} 为 jdk 路径
在这个文件夹中,主要对此处的4个文件进行修改,修改内容对于不同的 Hadoop 模式
core-site.xml
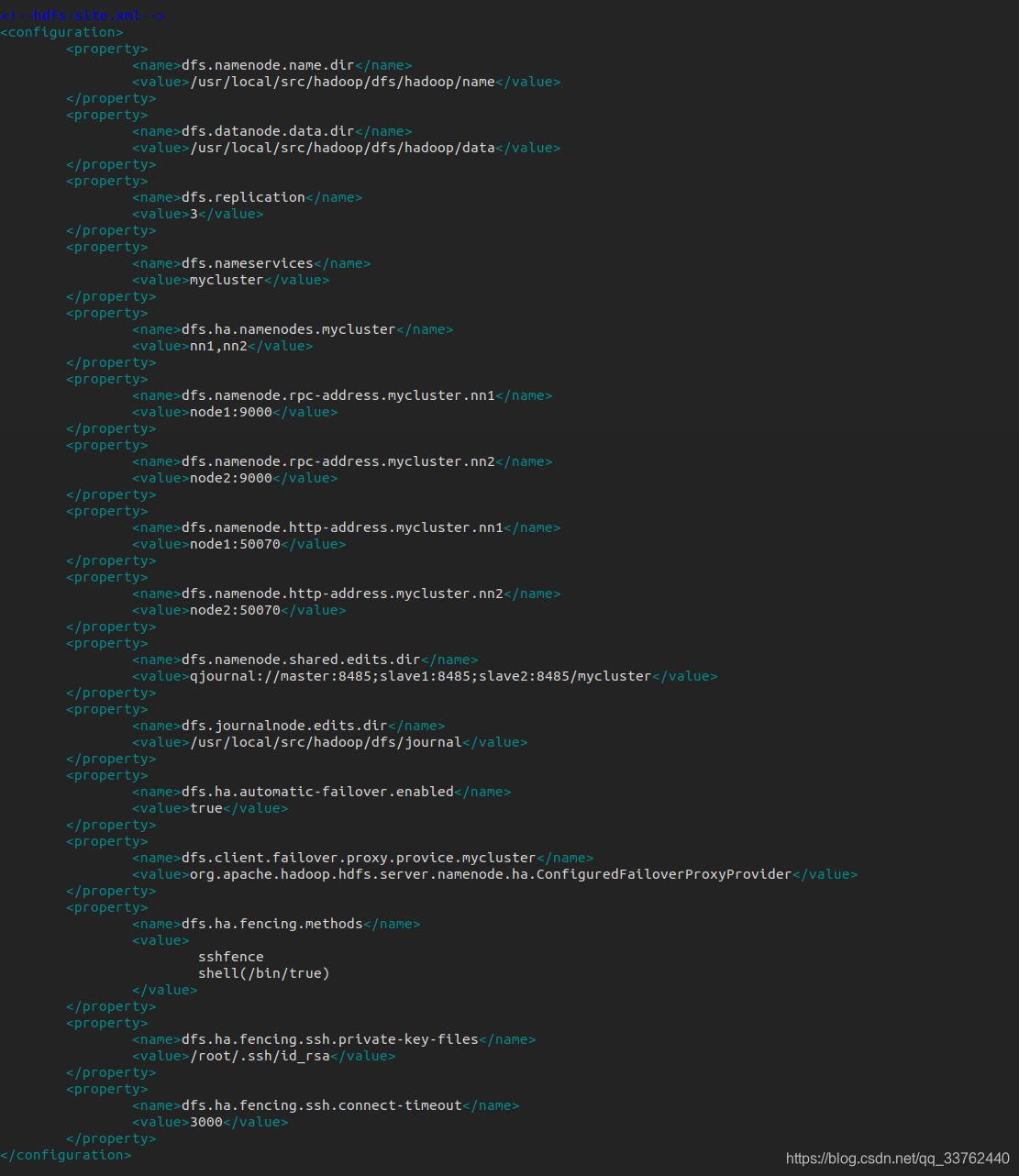
(hadoop配置文件)hdfs-site.xml
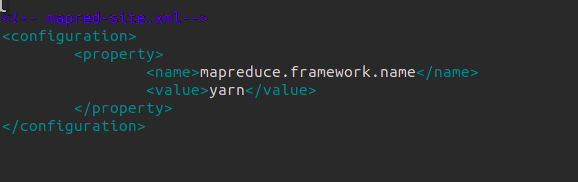
(hdfs配置文件)mapred-site.xml
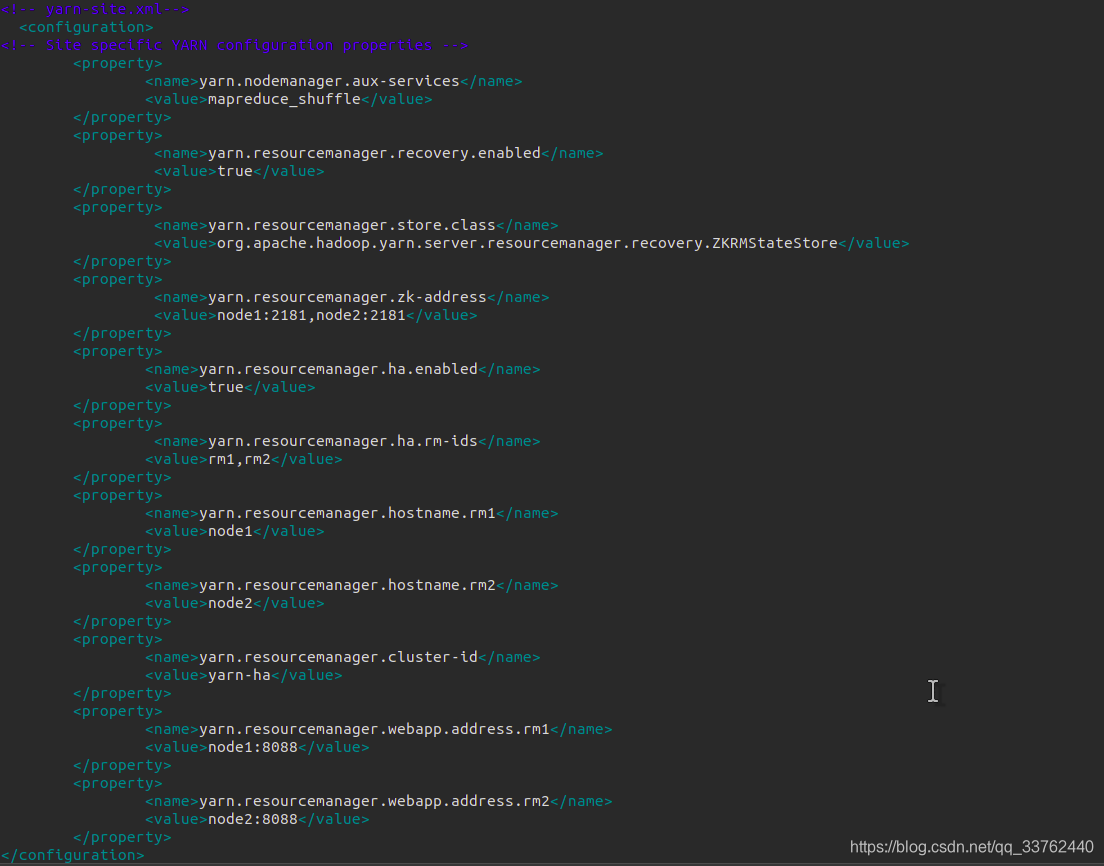
(目录中不存在mapred-site.xml文件,需要将mapred-site.xml.template复制为mapred-site.xml文件)yarn-site.xml
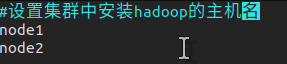
(Yarn的配置文件)slaves
(集群分布配置文件)

1).伪分布式 Hadoop 部署
部署要求:单台虚拟机配置 jdk ,hadoop
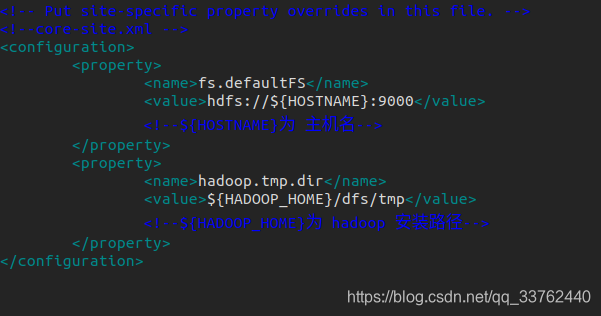
${HOSTNAME}: 位置填入主机名
${HADOOP_HOME}: 位置填入 hadoop 安装路径
core-site.xml
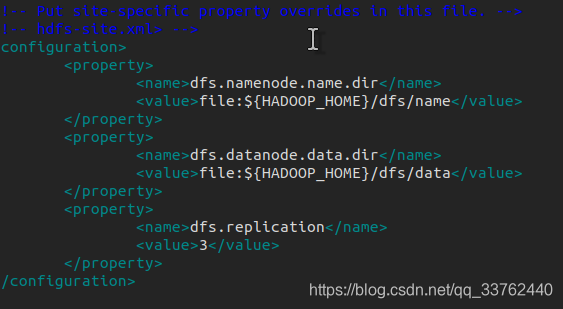
hdfs-site.xml
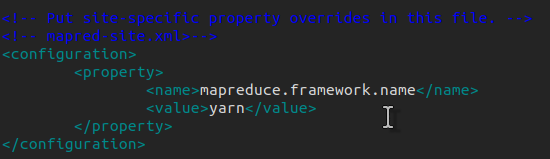
mapred-site.xml
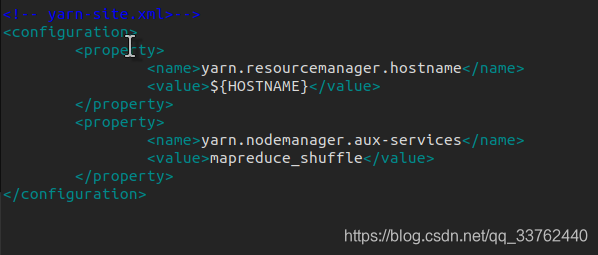
yarn-site.xml
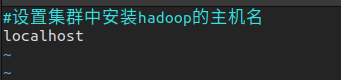
slaves,设置启动datanode进程的主机名
将文件修改完成后,启动hadoop,查看配置是否正确
首先初始化 namenode 数据, hdfs namenode -format
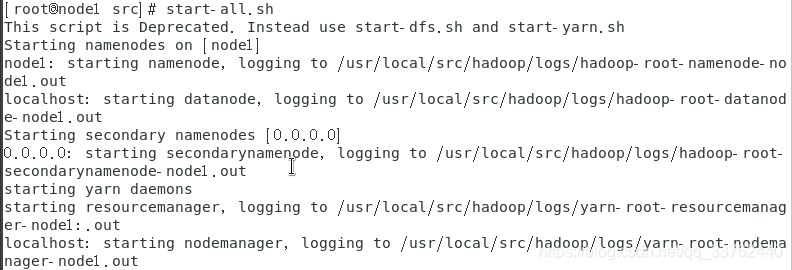
有错误信息就排除错误,没有错误信息,紧接着的就是启动 hadoop,hdfs-all.sh,或者hdfs-dfs.sh,hdfs-yarn.sh
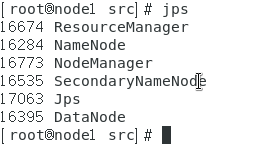
启动完成,使用 jps 可以查看到
NameNode
DataNode
SecondaryNameNode
JobTracker
TaskTracker
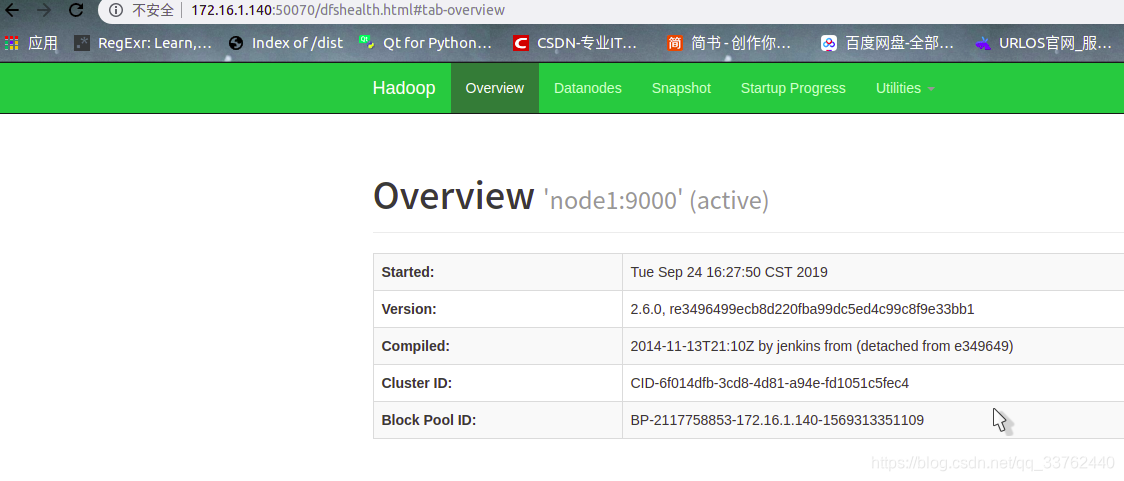
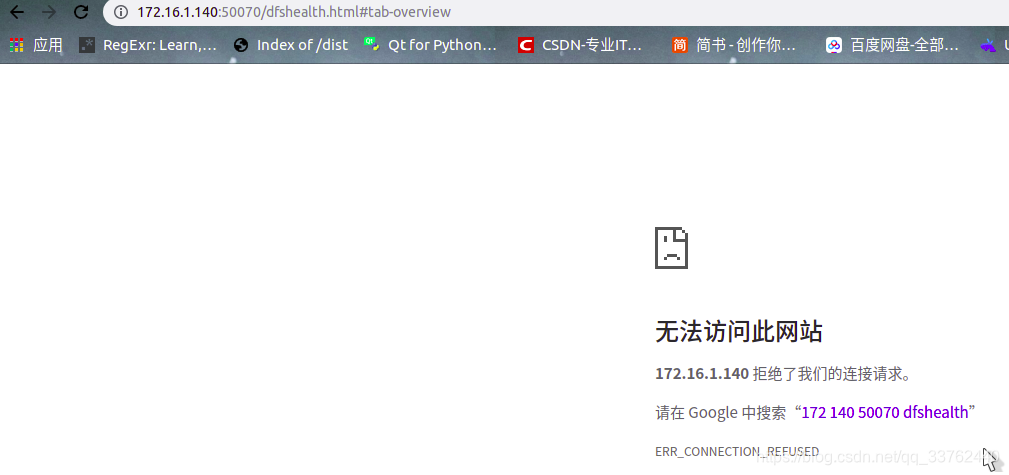
可用浏览器打开 node1 的 50070 端口与 8088 端口
2).完全分布式 Hadoop 部署
部署要求:多台虚拟机配置 jdk ,hadoop,各主机之间实现免秘钥、
完全分布式,就是在伪分布的基础上,添加多台主机,集成集群
除 slaves 文件,其他配置和伪分布一样
首先配置一台虚拟机中的 hadoop ,然后将配置好的 hadoop 拷贝到其他的虚拟机中
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves,设置启动datanode进程的主机名
配置完成后,初始化 hadoop,指令hdfs namenode -format
初始化数据完成后,将 hadoop 拷贝至其他虚拟机中
进入hadoop的家目录中,cd /usr/local/src/
输入指令scp -r ./hadoop root@node2:/usr/local/src/
这里的node2是第二台虚拟机
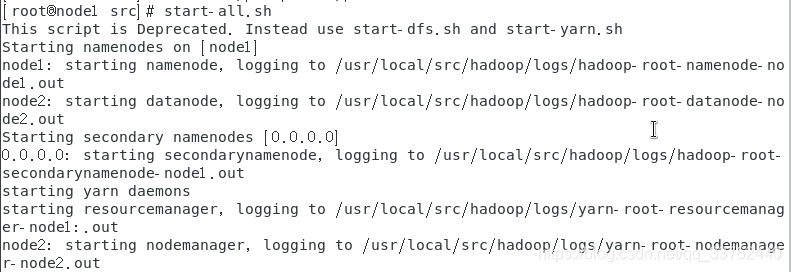
拷贝完成后,使用start-all.sh启动 hadoop
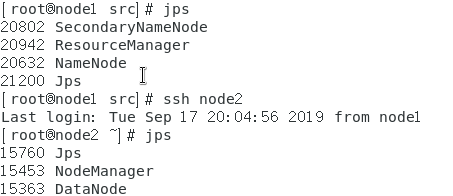
启动成功后,使用 jps 查看 node1 与 node2 两台虚拟机上的进程
发现 DataNode 与 NodeManager 出现在 node2 中,完成全分布 hadoop 配置
可用浏览器打开 node1 的 50070 端口与 8088 端口

3).高可用 Hadoop Ha 部署
部署要求:使用的所有主机都配有 jdk,zookeeper集群,并且开启zookeeper集群
配置一台虚拟机中的 hadoop ,然后将配置好的 hadoop 拷贝到其他的虚拟机中
配置如下:
在完全分布式hadoop集群上修改以下四个文件
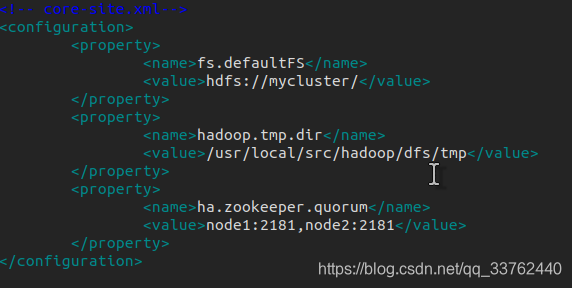
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
配置完成后,启动ha的hadoop
首先启动 journalnode
hadoop-daemons.sh start journalnode
hadoop-daemons.sh start journalnode启动所有集群中的 journalnode
如果不想全部启动可以改为hadoop-daemon.sh start journalnode启动当前虚拟机中 journalnode
hadoop-daemon.sh start journalnode启动所有集群中的 journalnode
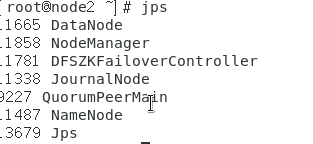
启动完成后输入 jps 可以看到 journalnode 进程在运行中
然后初始化 zookeeper 集群数据
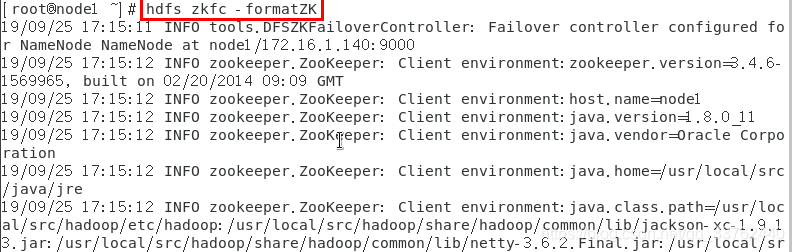
hdfs zkfc -formatZK
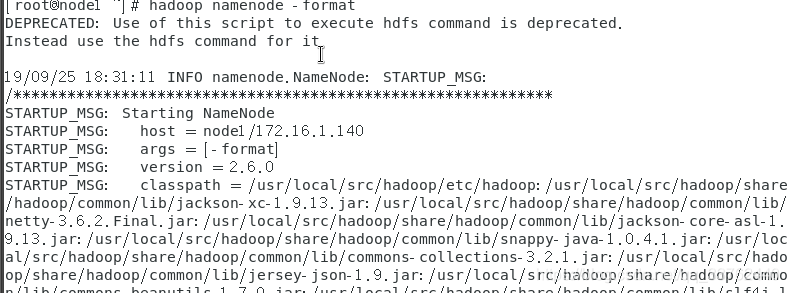
初始化完zookeeper后,初始化 hadoop ,指令hdfs namenode -format
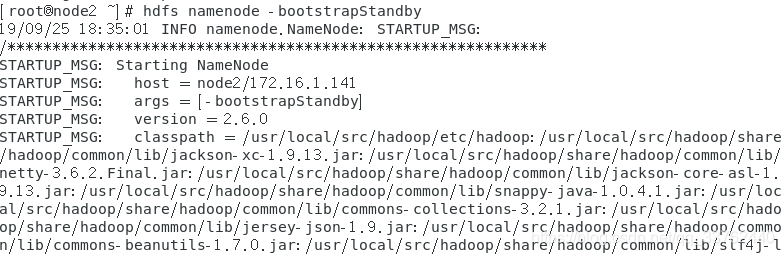
初始化完成后,切换到 node2 虚拟机上,输入指令,同步 node1 的 hadoop数据
hdfs namenode -bootstrapStandby
如果指令出现问题,可以直接将 node1 上的 dfs 文件(装namedir,datadir的文件夹)拷贝过来
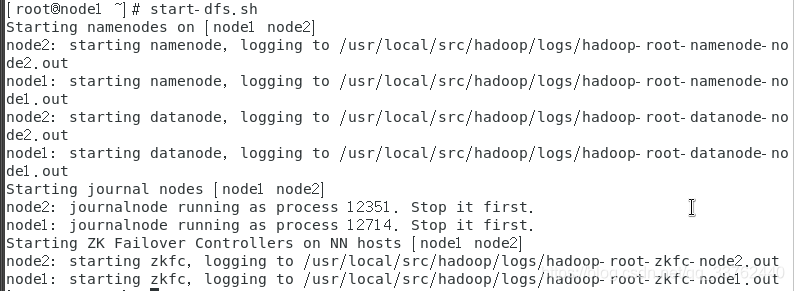
拷贝完成后,在虚拟机的 hdfs,start-dfs.sh
启动 yarn,start-yarn.sh
注意: 我这里创建了两台 master 虚拟机,所以把 yarn 启动在 master 虚拟机上,如果有 slave 虚拟机,就把 yarn 启动在 slave 虚拟机上
启动完成后 jps,会出现以下进程
注意: 正常的配置集群,会在slave中设置 slave 虚拟机 DataNode会出现在 slave 虚拟机中
kill -9 13330关闭 namenode 进程
13330 对应 jps 进程中 namenode 前面的数值
node1 的 jps
node2 的 jps
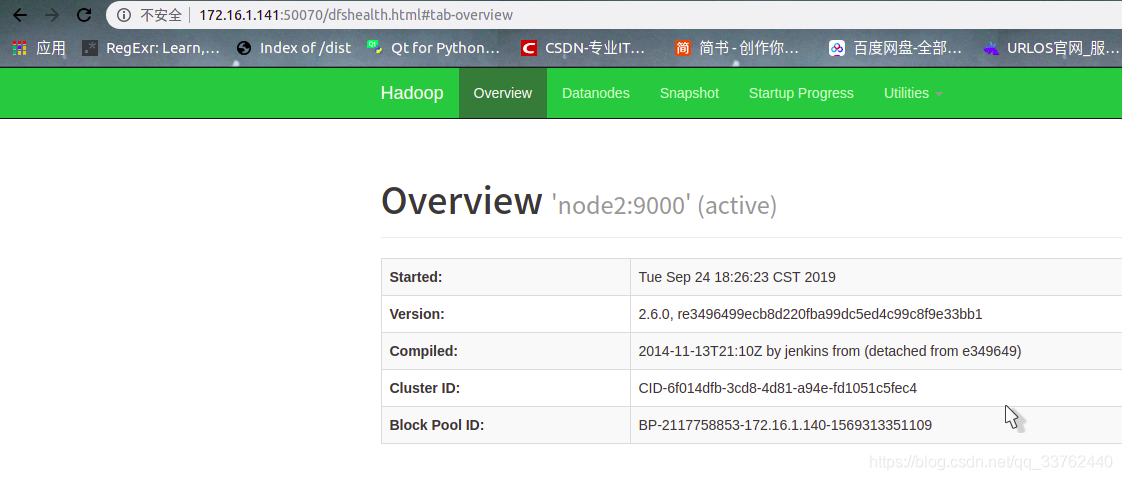
node1 的 50070 是活跃状态
node2 的 50070 是备用状态
关闭 node1 的 namenode 后:
这种就是 hadoop 的关键部分,在商业用途中,难免会出现 master 异常的情况,所以就需要一个备用的 master 的虚拟机来解决该问题
node2 的 50070 变为 活跃状态
完成安装 hadoop 高可用部署




4.安装 hive
部署要求:使用的主机配有 jdk,hadoop,mysql
centos 上的mysql安装 https://mp.csdn.net/mdeditor/101511633#
解压hive包
tar -zxvf apache-hive-1.1.0-bin.tar.gz
解压完成后重命名为 hive
mv hive-1.1.0 hive
或者
tar -zxvf apache-hive-1.1.0-bin.tar.gz -C hive
配置环境变量
vi /etc/profile
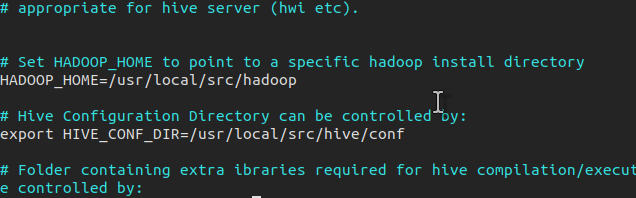
export HIVE_HOME=/usr/local/src/hive
export PATH=$PATH:$HIVE_HOME:
进入 hive目录中的 conf文件夹中,
拷贝 hive-env.sh.template 为 hive-env.sh
cp hive-env.sh.template hive-env.sh
拷贝 hive-default.sh.template 为 hive-site.sh
cp hive-default.xml.template hive-site.xml
修改 hive-env.sh 中为:
修改 hive-site.xml 中为:
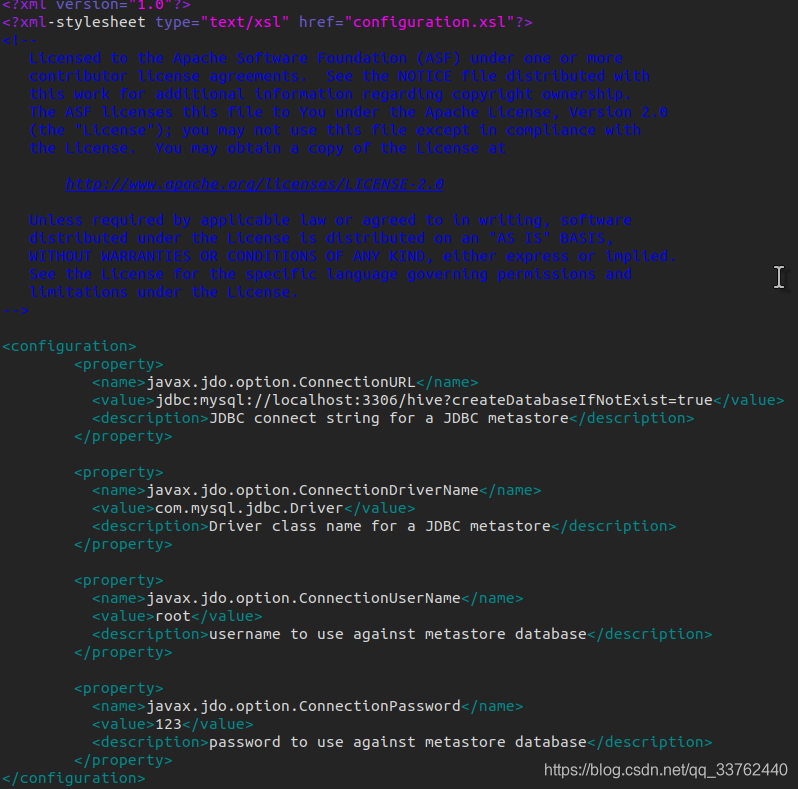
内容中对应
| name | value |
|---|---|
| javax.jdo.option.ConnectionURL | 连接的数据库 |
| javax.jdo.option.ConnectionDriverName | 数据库驱动方式 |
| javax.jdo.option.ConnectionUserName | 登录数据库的用户 |
| javax.jdo.option.ConnectionPassword | 登录数据库的密码 |
删除hadoop中的冲突包
rm -rf /usr/local/src/hadoop/share/hadoop/yarn/lib/jline-0.9.94.jar
找到自己电脑中的 mysql-connector-java-5.1.32.jar 驱动包,放入hive目录中 lib 包中
cp /hadoop/apk/mysql-connector-java-5.1.32.jar /usr/local/src/hive/lib/
在mysql中创建 hive 数据库
mysql >create database hive;
然后初始化 hive 的元数据
schematool -dbType mysql -initSchema
初始化会打印数据库连接的内容,注意对比,对比失败,请检查配置
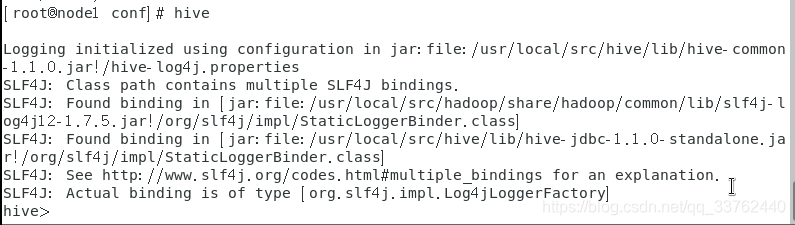
初始化数据完成后,启动 hive 完成部署
进入hive的bin目录下,输入hive,进入 hive 控制台,完成基础配置


错误解决
关于hive启动一遍后,重启主机进不去等问题
可以查看mysql数据库中对应的数据库是否被修改库权限,无法查看数据库中的表
对数据库权限进行修改
chown -R mysql:mysql /val/lib/mysql/hive
5.安装 sqoop
部署要求:使用的主机配有 jdk,hadoop,mysql,hive
解压sqoop包
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /usr/local/src/
设置环境变量
vi /etc/profile
export SQOOP_HOME=/usr/local/src/sqoop
export PATH=$PATH:$SQOOP_HOME/bin:
配置文件
修改 sqoop 目录下 conf 文件夹中的 sqoop-env.sh 文件
mv sqoop-env-template.sh sqoop-env.sh
放驱动
cp /hadoop/apk/mysql-connector-java-5.1.32.jar /usr/local/src/sqoop/lib/
查看是否安装完成
sqoop list-tables --connect jdbc:mysql://172.16.1.140:3306/hive --username root -P





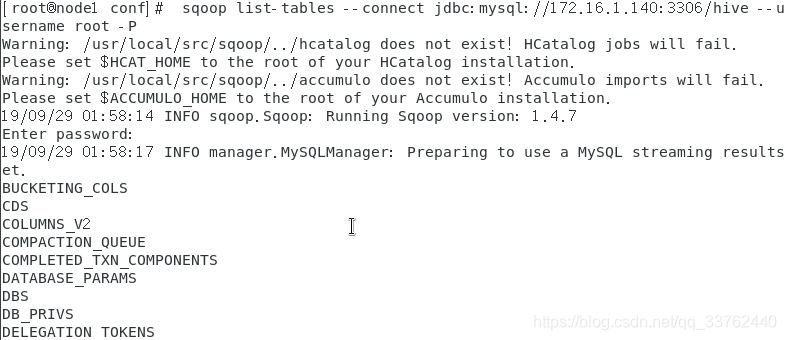
6.安装 spark
1).独立模式spark单机部署
部署要求:使用的主机配有 jdk
解压spark tar包
tar -zxvf /hadoop/apk/spark-2.0.0-bin-hadoop2.6.tgz -C /usr/local/src/
配置系统环境变量
修改 /etc/profile 文件
vi /etc/profile
向文件最后加入以下配置
export SPARK_HOME=/usr/local/src/spark
export PATH=$PATH:$SPARK_HOME/bin:
配置完成后,刷新配置
source /etc/profile
修改spark/conf 中的spark-env.sh
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
向文件中添加以下配置
export JAVA_HOME=/usr/local/src/java
export SPARK_MASTER_IP=node1
export SPARK_MASTER_PORT=7077
修改 slaves 文件内容
cp slaves.template slaves
vi slaves
设置 spark 启动在 node1 上
启动spark服务 Master 及 Worker
sbin/start-all.sh
使用 jps 命令查看启动进程
jps
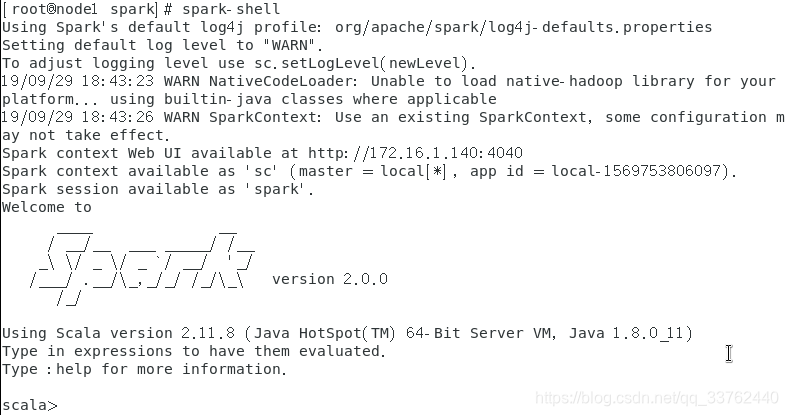
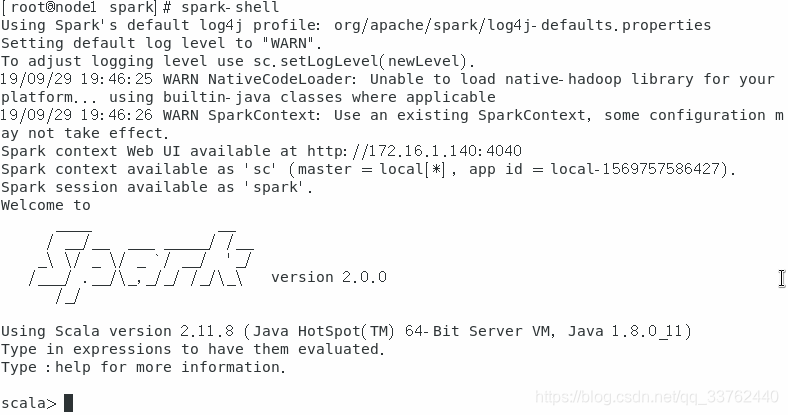
启动 spark-shell
spark-shell
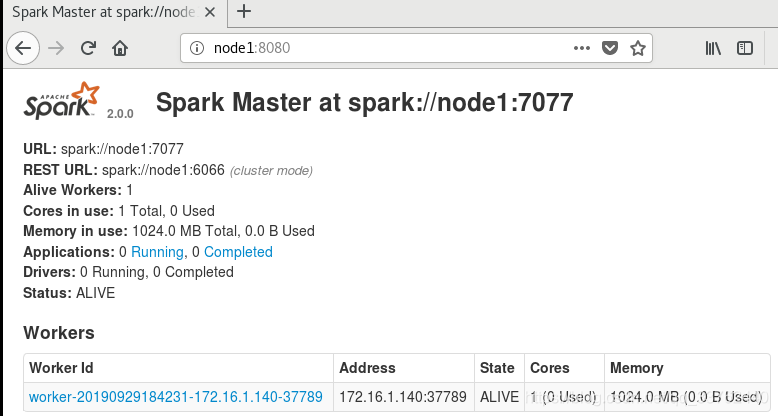
查看当前主机的8080端口的 spark 状态
完成配置






2).独立模式spark集群部署
部署要求:使用的所有主机都配有 jdk,spark
在独立模式的spark集群部署基础上修改slaves文件
解压spark tar包
tar -zxvf /hadoop/apk/spark-2.0.0-bin-hadoop2.6.tgz -C /usr/local/src/
配置系统环境变量
修改 /etc/profile 文件
vi /etc/profile
向文件最后加入以下配置
export SPARK_HOME=/usr/local/src/spark
export PATH=$PATH:$SPARK_HOME/bin:
配置完成后,刷新配置
source /etc/profile
修改spark/conf 中的spark-env.sh
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
向文件中添加以下配置
export JAVA_HOME=/usr/local/src/java
export SPARK_MASTER_IP=node1
export SPARK_MASTER_PORT=7077
修改 slaves 文件内容
cp slaves.template slaves
vi slaves
设置 spark 启动在 node1 上
将配置好的 spark 拷贝到其他主机中
scp -r /usr/local/src/spark root@node2:/usr/local/src/
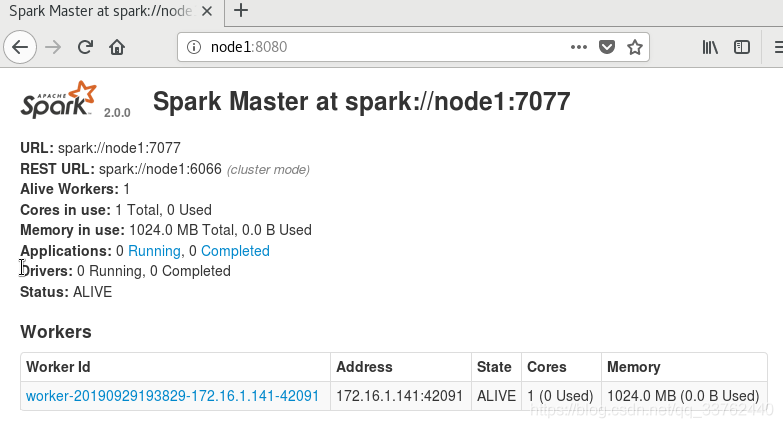
启动spark服务 Master 及 Worker
sbin/start-all.sh
使用 jps 命令查看启动进程
在node1主机上查看jps
在node2主机上查看jps
启动 spark-shell
spark-shell
查看当前主机的8080端口的 spark 状态
worker id启动在 node2 上
完成配置





文章配套组件包下载
链接: https://pan.baidu.com/s/1Ndk3846m3efXGe9rRe0Vkg 提取码: kubd














 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









