







给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。
示例 1:
输入:haystack = "hello", needle = "ll"
输出:2
示例 2:
输入:haystack = "aaaaa", needle = "bba"
输出:-1
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/implement-strstr
思路:此题典型应用 kmp 算法,解决字符串匹配问题。
字符串匹配问题题型:假设有两个字符串 A 与 B ,且 A 长度大于 B 长度,问字符串 B 是否为A的一个子串。
kmp 算法的原理实际上是优化了暴力求解算法。
回顾一下暴力求解算法,两个for循环,分别从A 与B的第一个字符A[ i ] 与 B[ j ]开始,依次比较,直到某 i 次循环中,B完全与A 中字符串吻合,则可以判断B是A的子串。
显然,这样中间会有太多次的无效匹配,效率低下。
如果我们能够相关办法,省掉其中的无效循环,那么就可以大大的提高效率。
盗个图,设图中的长字符串为A 串,短的为 B 串,已经匹配上的子串为C串。
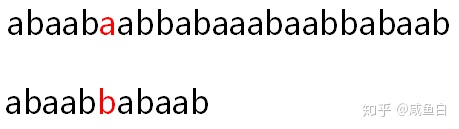
则可以看出,子串 abaab 的头两个字符组成的子串,与最后两个字符组成的子串是相同的。
则我们可以直接把B串向右平移两个位置,如下图所示。

这就是KMP的核心思想,省略无效循环比较。
这里介绍几个概念:
前缀、后缀、相同前缀后缀的最大长度(为表述方便,下文均用公共最大长指代),为了直观一点,我们直接举例:
abcdef的前缀:a、ab、abc、abcd、abcde(注意:abcdef不是前缀)
abcdef的后缀:f、ef、def、cdef、bcdef(注意:abcdef不是后缀)
abcdef的公共最大长:0(因为其前缀与后缀没有相同的)
ababa的前缀:a、ab、aba、abab
ababa的后缀:a、ba、aba、baba
ababa的公共最大长:3(因为他们的公共前缀后缀中最长的为aba,长度3)
我们可以容易的看出C串的公共最大长为2,所以我们可以直接把B串平移C串的C的长度 - 最大公共最大长个 位置。
若是我们能够求出B串中以每个位置的字符结尾的子串的最大公共最大长,那么每次我们遇到不匹配的字符时,都可以直接平移 公共最大长 个位置,再继续匹配。
设数组 K 的长度为 B的长度,其中K[ i ]表示以B [ i ] 结尾的子串的最大公共长,求解K有点费劲。但是,细心的我们能够发现 K[ i ] - 1 值表示以B [ i ] 结尾的子串的最大前缀中最后一个元素的下标。
所以,我们可以求解数组next,其中next[ i ] 表示以B [ i ] 结尾的子串的最大前缀中最后一个元素的下标。如果某个以B [ j ] 结尾的最大公共最大长为 0 ,则next[ j ] = -1。
容易得到:next[ 0 ] = -1
假设我们已经得到了next[ 0 ] 到next[ i-1 ]的值,现在求解next[ i ]。
kmp算法详解参考:如何更好地理解和掌握 KMP 算法? - 知乎
class Solution {
public int strStr(String haystack, String needle) {
if(needle.length() ==0) {
return 0;
}
if(haystack.length() == 0) {
return -1;
}
int[] next = new int[needle.length()]; // 存放needle 中以当前字符结尾所匹配的最大前缀中相同字符的位置,若是没有默认为-1
next[0] = -1; // 第一个字母无最大前缀,所以是-1
for(int i=1;i<needle.length();i++) {
int j = next[i-1];
// 找到以当前字符needle[i] 结尾的最大前缀的下标,若是找不到,令next[i] = -1;若是找到,next[i]=最大前缀的长度-1
while(true) {
if(needle.charAt(j+1)!=needle.charAt(i) && j>=0) {
j = next[j];
} else {
break;
}
}
if(needle.charAt(j+1)==needle.charAt(i)){
next[i] = j+1;
} else {
next[i] = -1;
}
}
printArray(next);
int i=0; // haystack 字符位置
int j=0; // needle
for(;i<haystack.length();i++) {
while (j>0 && needle.charAt(j) != haystack.charAt(i)){ //从字符串 needle 的下标 j 开始往前,直到 needle[j] == haystack[i] 或者 j==0 为止
j=next[j-1]+1; // 更新j的值为 以 needls[j] 的上一个字符needls[j-1]结尾的最大前缀结尾元素的下标 + 1
}
if(needle.charAt(j)==haystack.charAt(i)) {
j++;
} else {
if(j>0) {
j = next[j-1]+1;
}
}
if(j==needle.length()) {
break;
}
}
if(i<haystack.length()) {
return i-needle.length() + 1;
} else {
return -1;
}
}
}














 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









