






-
对jvm jre jdk的理解
- jvm 是java虚拟机(jvm主要由C语言编写),将java的.class程序解释为机器码,是java实现多平台运行的原因。
- jre是java运行时环境,包含jvm和jvm解释.class程序运行时的基础类库等。
- jdk是java开发工具包含jre和java编译器(java编译器将.java文件编译为.class文件)、java常用的类库等。
- 总结:jdk把通过编译器(javac.exe)将java文件编译为字节码文件,jvm将字节码通过解释器(java.exe)在jre是基础类库的支持下解释为机器码传达给cpu。
-
配置环境变量
- 通过java和javac命令判断是否配置成功
-
java的基本类型:
- 四类八种:byte、short、int、long、float、double、char、boolean。
-
计算机网络:
- 分层::国际标准:1物理层(硬件)2链路层(转换为机器码)3网络层(路由器)4协议层(TCP(数据发送有响应),UDP(只管发数据))5会话层(建立连接)6表现层(处理数据格式,不同系统间的数据差异)7应用层(http.https)
- TCP建立连接(三次握手)速度较慢,信息不丢失;UPD不需要建立连接只管发,速度较快,信息可能丢失
- 浏览器地址输入URL后的流程:DNS解析->TCP连接->http发送报文->服务器处理请求发送报文->浏览器渲染报文->连接结束
- java.net.Socke、java.net.ServerSocket、java.net.DatagramSocket
是java实现TCP/UDP协议的通信类 - https是在http基础上加了传输加密和身份认证的(SSL/TLS)协议,详细理解:https://blog.csdn.net/qq_33803292/article/details/122689593?spm=1001.2014.3001.5501
-
java容器:
- ArrayList底层数组,查询快增删慢;LinkedList底层链表,查询慢,增删快,Vector线程安全
- HashSet无序不重复,LinkedHashSet有序不重复
- HashMap键值无序不重复,TreeMap键值默认自然排序,可通过构造器传参(new Comparator()对象)自定义排序
- HashMap原理:1.8以前底层数组+链表,存元素的时候计算Key的hashcode值,其值不同时以数组的形式存储(数组扩容因子默认为0.75),相同时用数组元素作为链表头以链表的形式进行存储;1.8以后防止链表过长的影响,默认链表超过8就以红黑树的形式存储。(原理未完,待确认)
- ConcurrentHashMap线程安全,原理每个链表桶加锁
- HashSet原理:HashMap的key,value统一为PRESENT
- Iterator是一种设计模式,Iterable接口被Collection接口继承
-
线程
- 场景:某一工作将消耗很长时间,为了不阻塞主线程时;有大量请求等业务需要处理时;
- Thread类(实现了Runnable接口的run方法(线程的任务))有start方法(启动线程)。
- 获取线程的返回值:
- 主线程等待:如判断成员变量是否有值,如果没有,则当前线程循环
Thread.currentThread().sleep(100);
- 调用当前线程的jion()方法(此方法线程之间的并行执行变为串行执行)阻塞线程
- Callable接口的call()有返回值(通过FuterTask或线程池实现)
- 主线程等待:如判断成员变量是否有值,如果没有,则当前线程循环
- 线程六种的状态(Thread.State内部枚举)(
NEW、RUNNABLE、BLOCKED、WAITING、TIMED_WAITING、TERMINATED)
- JDK1.6以后 synchronized 锁升级:无锁——>偏向锁(同一线程反复访问被锁的操作)——>轻量级锁(不同线程不同时刻访问被锁的操作)——>重量级锁(不同线程同一时刻访问被锁的操作);新增锁消除(例如:编译时:在一个由synchronized 修饰的方法里只有stringbuffer连续append(因为该方法由synchronized 修饰)方法,就会消除内部的append的锁)、锁扩张(在一个循环里使用append方法的,就会扩张到只留内部锁)、自适应锁自旋等(在获取锁时,已有线程占用锁,不放弃cpu执行权,等待已获锁的线程释放锁,自旋次数由上次获取锁的状态决定)锁的操作。
- synchronized有类锁(静态同步方法和括号是类的同步方法块)和对象锁(普通同步方法和括号是对象的同步方法块)之分,若用对象锁,不同对象锁不同步。
- 线程并发解决思路
- 参考文章:公司新来一个同事,把优惠券系统设计的炉火纯青! - Java技术栈 - 博客园
- 总结:
- 用synchronized锁机制、:
- sql里面的事务,在sql执行前判断条件(如是否>0)
- 用redis的分布锁setnx命令或者RedissoneClient
-
反射和注解
- 反射是把java的类看成java.lang.class的对象,可以获取此对象的变量(对应的类java.lang.reflect.Field)、方法(对应的类java.lang.reflect.Method)、构造器(对应的类java.lang.reflect.Constructor)等
- 自定义注解的运用常和反射结合,reflect包的类常有getAnnotation方法,注解作用于类或变量或方法时,通过这些作用的的类的getAnnotation方法来获取对应的注解内容
- 反射的运用:jdbc加载数据库驱动、spring加载xml和Properties 配置文件的相关的实体类的字节码字符串
-
序列化
- 保存在内存中的各种对象的状态需要序列化如:写入磁盘或数据库、网络传送对象
- transient关键字可以使序列化对象的某一字段不被序列化如:password
- 实现Serializable接口即可序列化,最好显示定义serialVersionUID序列化的版本号
-
数据库
- 数据库的索引:存储结构:B+Tree(常用)、hash(快但有局限);索引类型:普通(normal)、唯一(unique)(可为空的不可重复)、Full Text(全文)、主键唯一(不可为空的不可重复)等;数据库存储引擎:InnoDB(常用,支持事务,默认行级锁)、MyISAM(适合查询频繁,无事务的,默认表级锁);联合索引遵循最左匹配原则。
- SQL优化:
- 查找慢sql:开启数据库慢日志查询和用explain执行看type字段为all(查全表)或index(查所有索引)则可能需要优化
- 优化:
- 让sql走索引;
- 避免全文搜索如select用*好
- 用别名节约解析时间
- 连续数字用between ..and..效率可能高于in
- sql优化的几种方法_青春微凉不离殇的博客-CSDN博客_sql优化
- 数据库的隔离级别(处理事务并发访问的问题):读未提交、读已提交、可重复d读、串行化分别更新丢失(不同事务对同一数据进行修改时的数据安全问题)、解决脏读(读到别的事务未提交或回滚的数据)、不可重复读(在同一事务内读到别的事务提交前后不一致的数据,当事务启动时,就不允许进行“修改操作(Update),是mysql的默认隔离级别)、幻读问题(如:其他事务新增删除时当前事务修改某一字段的条数)数据库事务的四种隔离级别 - 腾讯云开发者社区-腾讯云
- sql语法:where在gruop by前;having在group by后。
- 分表分库:原因:在数据量极大的时候,单表操作性能极低;案例示例:一共分200张表,用order表中的userId的字段取模,如userId%200=0、1、2....,在依据取模的值去分表或分库。
- 索引失效的场景
- 一些状态型的字段,用索引可能会失效甚至更慢
- 用like关键字,并以%通配符开始匹配字段,索引会失效
-
redis
- 认识:常用来做缓存的非关系型数据库,数据常存在内存,以KV键值对存在
- 场景:海量数据、短时间会反复查询的数据(可定时)如:验证不同登陆类型的uuid、单表查询的li_setting、滑块资源
- 数据类型:
- string(命令eg: set name "lilei" 、get name )
- hash(适合存储对象,命令eg:hmset lilei name "lilie" age "29" 、hget lilei age、hset lilei name "wanglei" )
- list(以栈形式存储,先进后出,命令 eg:lpush mylist "aaa"、lrang mylist 0 10)
- set(无序不重复,命令eg:sadd myset "aaa"、smembers myset )、
- sorted set(有序不重复、命令eg: zadd myzset 1 "aaa"、zrangebyscore myzset 0 10)
- 等等
- 分布式锁:
- 用setnx命令,表现为如果当前线程或客户端设置key的vlaue成功,别的线程就无法再进行设值;防止死锁可以设置过期时间,但是分步设置不满足锁的原子性,所以建议用命令: set key vlaue ex nx命令,在设置key的同时设置过期时间
- 引入Redission包
- 海量搜索以相同前缀的key(命令eg:keys k1*),数据太大引起卡顿时可以有类似分页原理的命令 scan(命令eg: scan 0 match k1* count 10)
- redis做异步队列:用list类型(命令eg:lpush mylist "aaa"生产消息、lpop mylist 消费消息)、或用pub/sub主题订阅模式(命令eg:subscribe mytopic 订阅消息,publish mytopic “aaa”发布消息)
- 持久化(可解决突然退出数据丢失问题:
- RDB(redis database)redis时加载redis.conf配置信息里持久化的策略,可用sava或者bgsave重新生成dump.rdb
- AOF(append only file)另外读取aof文件,保持数据较安全,原理:备份除读指令以外的更新数据的操作,
- RDB+AOF方式
- 雪崩:大量数据本来有缓存,但是缓存过期或者缓存宕机后有大量的请求直接请求了数据库,导致数据库宕机。解决方案:让缓存时间分散或一些数据不设置过期时间,将热点数据分布在不同的redis。
- 穿透:列如恶意访问大量缓存里没有的数据,如id=负值,跳过缓存走数据库,导致系统崩溃。解决方案:查询没有就存储该数据到缓存中设置为null并设置过期时间
- 击穿:某个Key的访问非常频繁,在失效瞬间涌入大量请求,导致系统或者数据库堵塞。解决方案:让它不过期或者设置互斥锁(互斥锁参考:Redis缓存击穿解决方案之互斥锁_wl_Honest的博客-CSDN博客_redis互斥锁)。
- 雪崩 、穿透、击穿参考文章:什么是 redis 的雪崩、穿透和击穿? - myseries - 博客园
- 查询速度快(每秒查询十万+):
- 基于内存
- 数据结构简单
- 主线程为单线程(避免上下文切换和锁竞争),可多核启动多线程
- 多路I/O复用,避免阻塞
- pipeline:可以一次性发送多条命令给服务端,服务端依次处理完完毕后,通过一条响应一次性将结果返回
- 主从同步(redis集群的特点):
- 将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
- 全量过程:从节点发送同步请求----主节点执行bgsave指令备份rdb文件并把后续的数据(写命令)记录到主节点缓存中----从节点同步主节点的rdb文件----从节点同步主节点缓存中的数据(写命令)
- 增量过程:主节点接受用户命令时保存在aop文件,判断是否需要进行从节点同步,若需要就发送给从节点
- 同步时主节点发生故障怎么办,这时就可以开启哨兵机制
- 哨兵
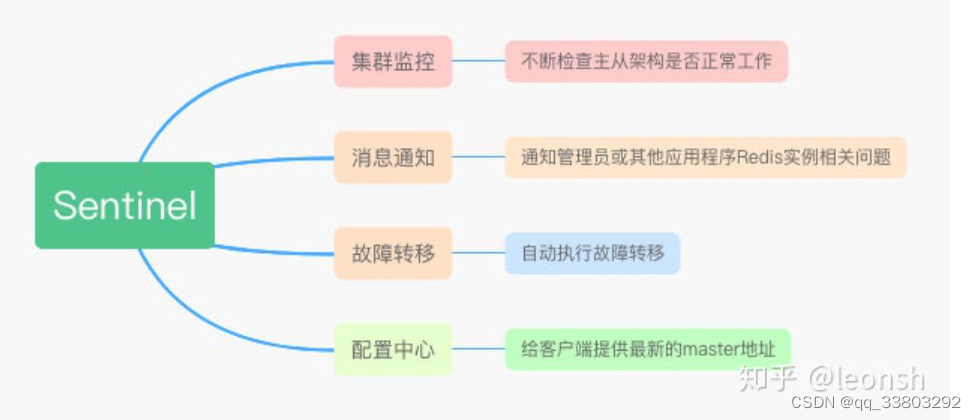
- 集群
- redis集群中分片查找海量数据:取key的hash值对节点数进行取模进行查找
- 思考,其中一个节点宕机时,一些key值取不到,可以考虑找与该值最近的的一个节点。
-
linux
- shell命令:
- 查找特定的文件名:用find / -name "文件名"
- 管道操作符| :将|前面命令的输出作为|后面命令的输入
- 查找指定文件的包含的内容:grep(筛选日志)
- 对文件内容做统计:awk
- 批量替换文本内容:sed(Stream editor)
- shell命令:
- spring框架
- IOC(Inversion of Control)控制反转:
- 定义:在IOC出现以前,java的对象大多是new的方式出现,使得后面的代码非常依赖前面的代码,前面的代码稍作修改就容易有连锁反应的修改;IOC出现以后:将前面的类注入到后面的类,需要修改前面的类时,不影响后面的类
- 依赖注入的方式:
- Setter、Constructor、Anotation、Interface
- 理解:????
- AOP(Aspect Oriented Programming):面向切面
- 不影响原有功能的前提下进行增强或减弱
- 好处之一:可以在项目中把业务代码和通用功能(日志、事务)代码分离开
- IOC(Inversion of Control)控制反转:
- jvm
- jvm架构图

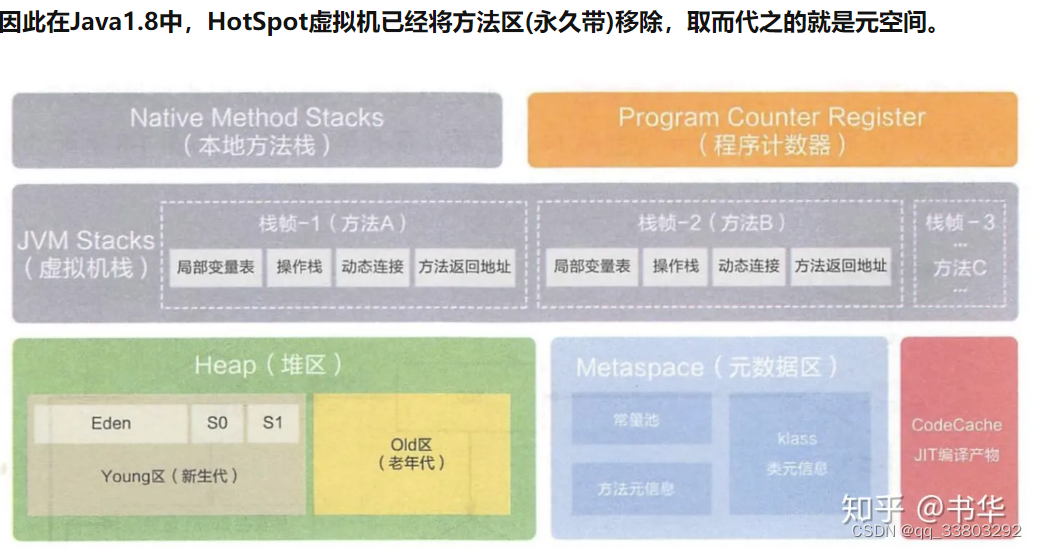
- Java方法区与元空间 - 知乎
- 解读jvm如何加载字节码: class loader加载字节码到Runtime data area(jvm内存)再调用native Interface去调用由C或者C++的底层代码
- 线程私有:程序计数器(字节码的行号)、虚拟机栈(注意:递归方法层数太深可能抛出异常)、本地方法栈
- 线程共有:元空间(jdk1.8出现替代了永久代存放class的相关信息,使用本机内存(??))、java堆(字符串常量池从永久代移动到堆)
- 类加载(看有道笔记)
- 定义:类加载是把字节码加载到内存的过程,需要加载类的时候才去classpath(或其他途径)去加载。
- 分类:类加载器有启动类加载器(Extension ClassLoader),加载如jdk里面的类;有应用类加载器(App ClassLoader)加载业务逻辑的类,也可自定义加载器(Custom ClassLoader)(可加载一些不在常规路径下的类)。
- 原理:类加载为保证类实例化的唯一,采用父类双亲委派机制,可通过看源码得知有一个核心的方法loadClass(),主要实现:加载一个类的时候要看父类是否被加载,如果父类加载过则通过父类加载子类,如果没有被加载则向上继续查看。
- protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class<?> c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { if (parent != null) { c = parent.loadClass(name, false); } //如果父类加载,则通过父类加载子类 else { c = findBootstrapClassOrNull(name); } }//如果父类未加载,则加载父类 catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } }
- javap命令:JDK自带的反汇编器,可以查看java编译器为我们生成的字节码
- jvm三大性能调优参数:
- -Xss:堆能达到的最大值
- -Xmx:堆的初始值
- -Xms:每个线程虚拟机栈(堆栈)大小
- jvm三大性能调优参数:
- jvm架构图
-
dao层框架:
-
MyBatis-Plus和Spring Data JPA的区别:
-
就目前的使用来讲,常规业务的需要完成功能的两种框架都支持,
-
JPA只需要dao继承JPA的两个接口(JpaRepository和JpaSpecificationExecutor)即可,而MyBatis-Plus需要业务层去继承IService和ServiceImpl,并且还有dao层的mapper接口的处理
-
MyBatis-Plus有很好的代码生成器支持、JPA有很好的自动生成表结构处理
-
-
-
数据结构
-
二叉树:一个父节点有两个子节点,左子树比根节点小,右子树比根节点大,有可能失衡,导致一边的节点很长,于是就有平衡二叉树
-
平衡二叉树:当节点失衡时,会旋转根节点,使得任何节点的两个子树的高度最大差为1
-
B+Tree非叶子节点只存储键值,叶子节点存储键和data数据
-
java后端

于 2022-06-24 11:55:46 首次发布














 8713
8713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









