






概述
线下业务到线上化的过程中,业务本身的复杂性,业务场景的多变性,对系统的设计提出了更高的要求,为了满足业务的要求,我们不断的对系统的设计进行改良,由单体应用按照垂直维度拆分成多个子系统,子系统内又拆分成多个微服务,由此系统之间和服务之间的调用变得越来越复杂。系统之间的通讯方式有多种, 而消息队列作为其中的一种,有其不可替代的作用,本文将和大家一块学习下消息队列的产生过程,基本组成,以及一种常用的消息队列rabbitmq。
文章目录
提示:以下是本篇文章正文内容,下面案例可供参考
一、消息队列怎么产生的
1. 系统间调用的方式
-
数据库
多个系统同时对同一个表进行读写,比如A系统写入数据表订单表,B系统启动定时任务,定时扫描订单表是否有新增或者更新数据,如果有则做相应的处理。优点:都是和数据库直接交互,系统间解耦。
缺点: 定时扫描,异步处理,处理不及时
大流量下数据库压力大
需要多个系统访问同一个数据库,不安全 -
共享文件
多个系统同时对一个文件进行读写,比如系统A写入文件数据之后,通知系统B来读取文件。比如Spring Cloud Config实现。优点:都是和文件交互,系统间解耦。
缺点:A系统修改了文件,通知系统B处理,实现复杂。 -
分布式缓存
多个系统对分布式缓存(redis)进行操作,比如系统A将数据写入redis,系统B定时的从redis读取到数据,并进行操作。优点:直接和redis操作,系统间解耦。
缺点:redis基于内存的,单条数据大小和总的数据大小有限制
异步处理,数据处理不及时 -
接口调用==
系统之间通过http方式或者rpc调用。优点:同步调用,能立刻返回结果
调用简单,很多框架提供了很好的支持
缺点:耗时的调用,调用时间较长,对客户端不友好。
系统之间紧耦合,上游系统会做的很重,需要循环通知各个系统,增加或者去掉下游系统,上游系统需要同步修改。
有对数据库增删改耗时较长的大接口,QPS大量增加会对数据库造成很大的压力,进而影响系统的稳定性。
综上:4种通讯方式都有各自的优缺点,但是无法同时满足以下几个场景:
- 缓冲大流量
- 大事务调用,异步处理,减少客户端等待时间,增加系统QPS
- 上游系统由主动通知各个下游系统,变为下游系统主动去关注上游系统的变化,系统间解耦。
那么我们来看下,下面要讲的消息队列是如何解决这些问题的。
2. 消息队列的发展过程
2.1 简单的队列
我们先看下一个简单的队列主要包括三个部分:
- 头指针
- 尾指针
- 节点
队列根据底层的实现分为链式队列和循环数组队列,
链式队列节点: 节点数据和指针2部分。
顺序队列节点: 节点数据。
队列分为链式队列和顺序队列,具体实现如下
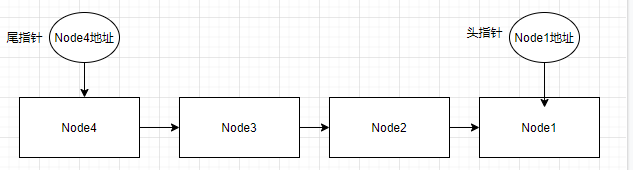
处理数据要求有先后顺序,先到的数据先处理,后到的数据后处理,所以有了队列这种数据结构。
二、消息队列基本构成
1. broker
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.生产者
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
3.消费者
三. RabbitMQ介绍
四. 消息队列在实际场景中碰到的问题汇总
为什么使用消息队列啊?消息队列有什么优点和缺点啊?kafka、activemq、rabbitmq、rocketmq都有什么优点和缺点啊?
如何保证消息队列的高可用啊?
如何保证消息不被重复消费啊(如何进行消息队列的幂等性问题)?
如何保证消息的可靠性传输(如何处理消息丢失的问题)?
如何保证消息的顺序性?
如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
如果让你写一个消息队列,该如何进行架构设计啊?说一下你的思路.
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 1867
1867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









