







关系数据库(2)
文章目录
1. 专门的关系运算
- 选择
- 投影
- 连接
- 除运算
2. 选择
-
在关系R中选择满足给定条件的所有元组(选择行)
-
表达式
- t代表元组
- F代表一个公式
- 基本形式:X1θY1
- θ表示比较运算符:>,<,>=…
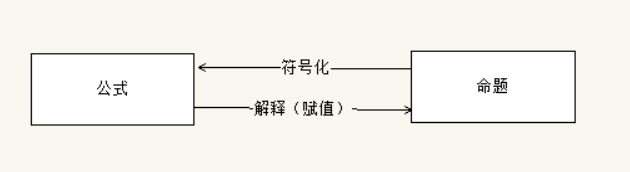
- F(t)代表一个命题:可以判读真假的表达式
- 公式与命题之间的关系

示例:使用关系代数实现选择
- Student表

- 选择语法

- 结果

3. 投影
-
从关系R中选择出若干属性列组成新的关系(选择列)
-
记作

-
A为R中的属性列
-
注意点
- 投影之后不仅取消了原关系中某些列,还可能取消原关系中的某些元组,因为取消了某些列后,可能出现重复的行
示例
- Student表

- 投影语法

- 投影结果
- 取消了重复的元组

4. 连接
设有关系R,S,R上有属性组A,B,S上有属性组B
-
F连接:多个θ连接(笛卡儿积+选择)
- θ连接:两个关系的笛卡儿积中选取属性间满足一定条件的元组
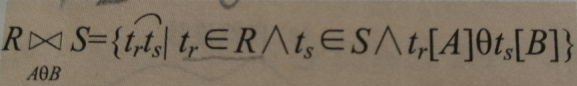
- 等值连接:θ为’='的连接运算,从关系R和关系S中选取A,B属性值相等的那些元组
-
自然连接(笛卡儿积+选择+投影)
- 特殊的等值连接
- 要求进行比较的分量是同名的属性组并在结果中把重复的列去除
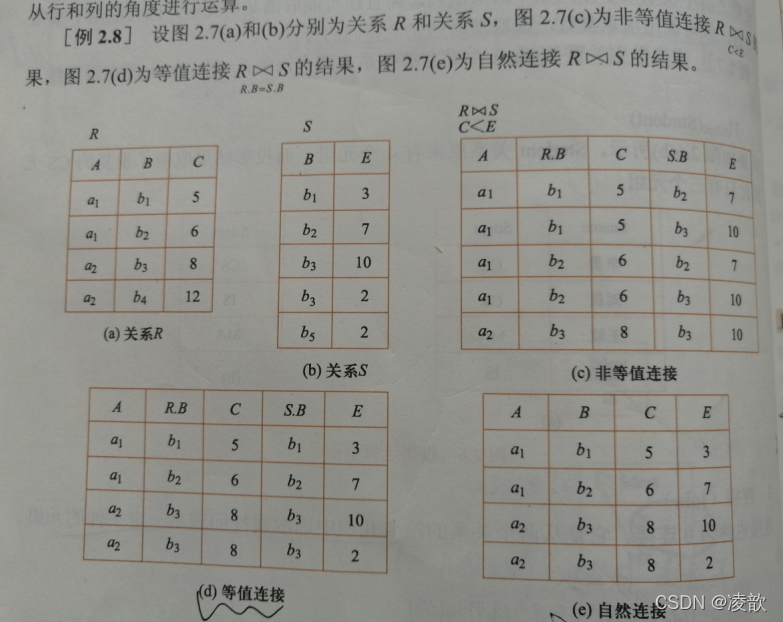
示例
5.除运算
5.1 象集
- 在关系R(X,Z)中,X,Z为属性组
- 象集表示X的的取值为x时的元组在Z上分量的集合
- 通俗理解:某一属性X的所有其他属性
示例
- 关系R

- 取值的象集
- x1在R中的象集{Z1,Z2,Z3}
- x2在R中的象集{Z2,Z3}
- x3在R中的象集{Z1,Z3}
5.2 除运算
- 设关系R除以关系S的结果为关系T,则T包含所有在R但不在S中的属性及其值,且T的元组与S的元组的所有组合都在R中
用象集定义除法
- 给定关系R(X,Y),S(Y,Z),其中X,Y,Z为属性组,R中的Y与S中的Y可以有不同的属性名,但Y来自同一个域
- 通俗理解:R除S得到一个新关系,这个**关系中X的取值满足在R关系对应取值的象集包含关系S在Y上投影的集合**
示例

6.用5种基本运算表示除运算
- 设有关系R(X,Y),S(Y,Z)
最终结果
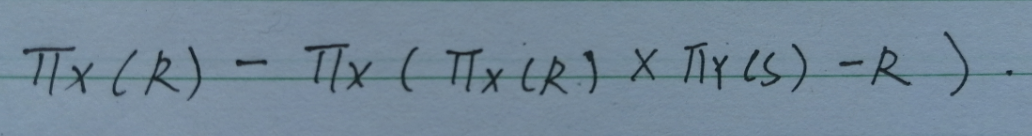
- 下面这张图片表示在X列上的投影

分步过程
- 使R中X的每个分量x的象集都包含关系S在Y上的投影

-
减去实际的R(如果**某个X的取值的元组记录完全被减去了,说明这个X取值,包含S在Y上的投影集,包含在除法的结果中**)
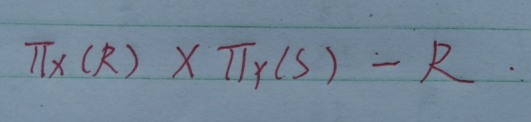
-
在2步骤中得到的结果集,把**结果集在X上投影(这些X的取值就是没有完全包含S在Y上的投影集**,不包含在除法结果中)

- 对**实际的R(最初的R)在X上投影(包含所有的X)-步骤3的投影(这些X没有完全包含S在Y上的投影集)**,得到的结果就是完全包含S在Y上的投影集的X的取值的集合

示例
-
选出选了1,3课程学生的学号
- R/S
-
关系R :SC学生选课表
| 学号Sno(X) | 课程号Cno(Y) |
|---|---|
| 021 | 1 |
| 021 | 2 |
| 021 | 3 |
| 022 | 2 |
| 022 | 3 |
- 关系S
| 课程号Cno(Y) | 课程名Cname(Z) |
|---|---|
| 1 | 离散数学 |
| 3 | 数据库 |
第一步(笛卡儿积)
- 得到一个笛卡尔积(假设所有学生都选了),注意投影会去除重复的元组(见上文)
| X | Y |
|---|---|
| 021 | 1 |
| 021 | 3 |
| 022 | 1 |
| 022 | 3 |
第二步(差)
- 减去实际的R(差运算)
| X | Y |
|---|---|
| 022 | 1 |
第三步(投影)
- 在第二步的结果基础上对X投影
X集合={022}
第四步(投影,差)
- 对最初的关系R在X上投影(所有学生),减去第三步得到的集合(这些学生没有完全包含要求的课程)
{021,022}-{022}={021}
{021} 就是既选择了1,又选择了3课程的学生














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









