







背景: 最近在学习五笔,但是对于一个小白来说,在面对大量的汉字的情况下,没办法知道一个个字怎么用五笔打出来,几个就算了,但成百上千个,总不能一个个去查吧,那一天时间都花在了查上,为了方便去记忆学习,就写了个Python程序来对汉字进行批量的转换,再慢慢的去学习。
目的: 将word中的字,转换成excel文件,包含源字、五笔简码,即使word中有上万个字,也仅需几秒完成所有汉字的转换,达到一劳永逸的结果。
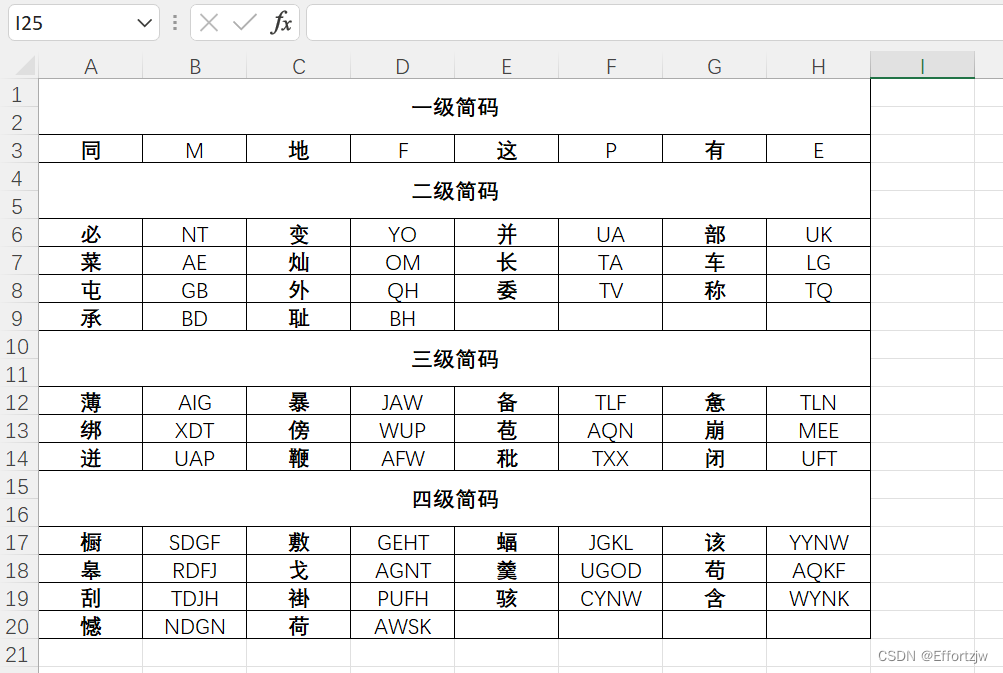
最终效果:

使用到的Python库:
pywubi -> 将汉字转换为五笔
docx -> 处理word文件
openpyxl -> 处理Excel文件
安装:
pip3 install pywubi
pip3 install docx
pip3 install openpyxl
五笔示例:
from pywubi import wubi
print(wubi('我'))
>>>['trnt']
# 返回汉字的所有可能的五笔编码
print(wubi('我',multicode=True))
>>>[['trnt', 'trn', 'q']]
有了以上的示例,那就简单了,想要最简码,只需要处理下所有可能的五笔编码,取最短结果,然后读取Word文件,输出Excel文件,格式再美化一下即可。
源码:
from pywubi import wubi
import time
import docx
import os
import openpyxl
start_time = time.time()
# 处理文字最简码
def hanToWuBi(str):
l = len(str[0][0])
ans = str[0][0]
for s in str[0]:
if len(s) < l:
l = len(s)
ans = [s, len(s)] #最简码、长度
return ans
file=docx.Document('字库.docx')
d_ziku = {}
for i in file.paragraphs: # 读取Wold中的文字
txt = i.text
for t in txt: # 遍历转换
d_ziku[t] = [hanToWuBi(wubi(t,multicode=True))[0].upper(),hanToWuBi(wubi(t,multicode=True))[1]]
d_wubi_1 = {} # 一级简码字典
d_wubi_2 = {} # 二级简码字典
d_wubi_3 = {} # 三级简码字典
d_wubi_4 = {} # 四级简码字典
for key in d_ziku.keys():
if d_ziku[key][1] == 1:
d_wubi_1[key] = d_ziku[key][0]
elif d_ziku[key][1] == 2:
d_wubi_2[key] = d_ziku[key][0]
elif d_ziku[key][1] == 3:
d_wubi_3[key] = d_ziku[key][0]
elif d_ziku[key][1] == 4:
d_wubi_4[key] = d_ziku[key][0]
arr = []
v = []
indexArr = 1
for key in d_wubi_1.keys():
if indexArr % 4 != 0: #4个一行
v = v + [key,d_wubi_1[key]]
indexArr += 1
else:
v = v + [key, d_wubi_1[key]]
arr.append(v)
indexArr = 1
v = []
arr.append(v)
arr.append(['','','','','','','',''])
indexArr = 1
v = []
for key in d_wubi_2.keys():
if indexArr % 4 != 0:
v = v + [key,d_wubi_2[key]]
indexArr += 1
else:
v = v + [key, d_wubi_2[key]]
arr.append(v)
indexArr = 1
v = []
arr.append(v)
arr.append(['','','','','','','',''])
v = []
indexArr = 1
for key in d_wubi_3.keys():
if indexArr % 4 != 0:
v = v + [key,d_wubi_3[key]]
indexArr += 1
else:
v = v + [key, d_wubi_3[key]]
arr.append(v)
indexArr = 1
v = []
arr.append(v)
arr.append(['','','','','','','',''])
v = []
indexArr = 1
for key in d_wubi_4.keys():
if indexArr % 4 != 0:
v = v + [key,d_wubi_4[key]]
indexArr += 1
else:
v = v + [key, d_wubi_4[key]]
arr.append(v)
indexArr = 1
v = []
arr.append(v)
arr.append(['','','','','','','',''])
# 将结果输出到Excel中
wb = openpyxl.load_workbook('字库.xlsx',data_only=True)
ws = wb.worksheets[0]
for x in arr:
ws.append(x)
wb.save('字库结果-排序版.xlsx')
end_time = time.time()
all_time = end_time - start_time
print('共执行:%s 秒' % all_time)















 5315
5315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









