








BinGo: Cross-Architecture Cross-OS Binary Search [FSE 2016]
Mahinthan Chandramohan, Nanyang Technological University, Singapore
Yinxing Xue∗, Nanyang Technological University, Singapore
Zhengzi Xu, Nanyang Technological University, Singapore
Yang Liu, Nanyang Technological University, Singapore
Chia Yuan Cho, DSO National Laboratories, Singapore
Tan Hee Beng Kuan, Nanyang Technological University, Singapore
二进制代码搜索近年来因其在抄袭检测、恶意软件检测、软件漏洞审计等方面的应用而受到广泛关注。然而,开发一个有效的二进制代码搜索工具是具有挑战性的,因为不同的编译器、体系结构和操作系统导致二进制代码的巨大语法和结构差异。在本文中,我们提出了BINGO,一个可扩展的和健壮的二进制搜索引擎,支持各种架构和操作系统。关键贡献是选择性内联技术,通过内联相关库和用户定义函数来捕获完整的函数语义。此外,还提出了体系结构和操作系统中立函数滤波方法,以显著减少不相关的目标函数。此外,我们引入长度可变的部分跟踪,以程序结构不可知的方式对二进制函数建模。实验结果表明,即使存在程序结构失真,BINGO也能以可扩展的方式跨体系结构和操作系统边界找到语义相似的函数。使用BINGO,我们还在Adobe PDF Reader (COTS二进制文件)中发现了一个零日漏洞。
一句话 - BinGo: 应用选择性内联技术捕获函数的完整语义和引入长度可变的部分跟踪对二进制函数进行建模,完成跨架构和操作系统的二进制函数搜索任务。
导论
Motivation
近年来,二进制代码搜索因其在软件工程和安全领域的重要应用而备受关注,如软件抄袭检测[28]、逆向工程[8]、语义恢复[25]、恶意软件检测[30]以及在各种源代码不可用的软件组件(如遗留应用程序)中的bug(脆弱)代码识别[31,11]。我们甚至可以通过匹配开源软件中的已知漏洞来搜索专有二进制文件中的零日漏洞。
传统的源代码搜索依赖于对源代码某些表示形式的相似性分析,例如基于令牌[24]、抽象语法树(AST)[22]或程序依赖图(PDG)[18]的方法。所有这些表示都捕获了程序的结构信息,并为源代码搜索提供了准确的结果。然而,由于许多因素(例如,体系结构和操作系统的选择、编译器类型、优化级别甚至混淆技术)以及高级程序信息的有限可用性,二进制代码搜索更具挑战性。这些因素对汇编指令及其在编译后的二进制可执行文件中的最终布局有很大的影响。
在文献中,已经提出了各种方法来使用静态或动态分析来检测相似的二进制代码。静态分析依赖于二进制文件的语法和结构信息,特别是控制流结构(即函数内基本块的组织)来执行匹配。例如,TRACY[11]是一种基于语法的函数匹配技术,通过分解使用相似性;COP[28]是一种抄袭检测工具,将程序语义与基于最长公共子序列的模糊匹配结合起来;[31]是一种漏洞匹配工具,通过漏洞签名的不变量支持跨架构分析。
最近,discovervre[37]被提议以一种可伸缩的方式在跨体系结构的二进制文件中查找错误,其中它使用两个过滤器(数值和结构)快速定位与签名函数相似的函数。除了静态分析,动态方法在运行时检查程序的输入输出不变量或中间值,以检查二进制程序的等价性。例如,BLEX[16]是最新的动态函数匹配工具,它使用在匹配过程中在函数执行期间获得的几个语义特征(例如,从程序堆中读取(写入)的值)。
为了更好地理解现有的方法,我们确定了精确而可扩展的跨体系结构和跨操作系统二进制搜索工具所需的三个属性:
(1) 能够适应由于体系结构、操作系统和编译器差异而引入的语法和结构差异
(2) 通过考虑完整的函数语义来提高精确性
(3) 可扩展到大尺寸的现实世界二进制文件
不幸的是,现有的技术都不能实现上述所有所需的特性。静态方法使用的结构信息,如基本块结构和定长tracelet, 不满足属性(1)。大多数静态分析技术不能满足属性(2),因为它们在匹配过程中忽略了相关库和用户自定义函数调用的语义。最后,可伸缩性的属性(3)是语义二进制匹配的真正挑战,COP花费了半天时间才能在firefox中找到目标函数签名。
本文提出了一个名为BINGO的二进制搜索引擎,它通过组合一组关键技术来执行语义匹配,以解决上述挑战。给定一个二进制函数,BINGO首先内联相关库和用户定义函数以获取函数的完整语义(对于属性2),然后使用架构和操作系统中立过滤技术(对于属性3)列出候选目标函数,最后从候选目标函数中提取长度变化的部分跟踪作为函数模型(对于属性1),并使用机器学习技术进行函数相似度匹配。为了提高方法的可伸缩性,我们提出了一种架构和操作系统中立的过滤技术,通过列出二进制语义匹配的候选目标函数来缩小搜索空间。接下来,为了克服由于基本块结构扭曲而产生的挑战,我们通过长度变量部分跟踪生成对底层程序结构不可知的函数模型。为此,对于每个函数,提取长度为1到k的部分跟踪,以形成函数模型,使其表示不同粒度级别的函数。在这里,我们还采取措施,尽量减少不可行的路径和编译器特定代码在计算函数相似度得分时的影响。
Contributions
(1) 提出了一种选择性内联算法来捕获二进制函数的完整语义
(2) 引入了架构和操作系统中立的函数过滤过程,有助于缩小目标函数搜索空间
(3) 利用长度可变的部分跟踪来在不同粒度级别上建模函数,与底层程序结构相独立
(4) 通过实验证明,BINGO优于最先进的二进制函数匹配工具,并报告了从Adobe PDF Reader中发现的零日漏洞
Challenges
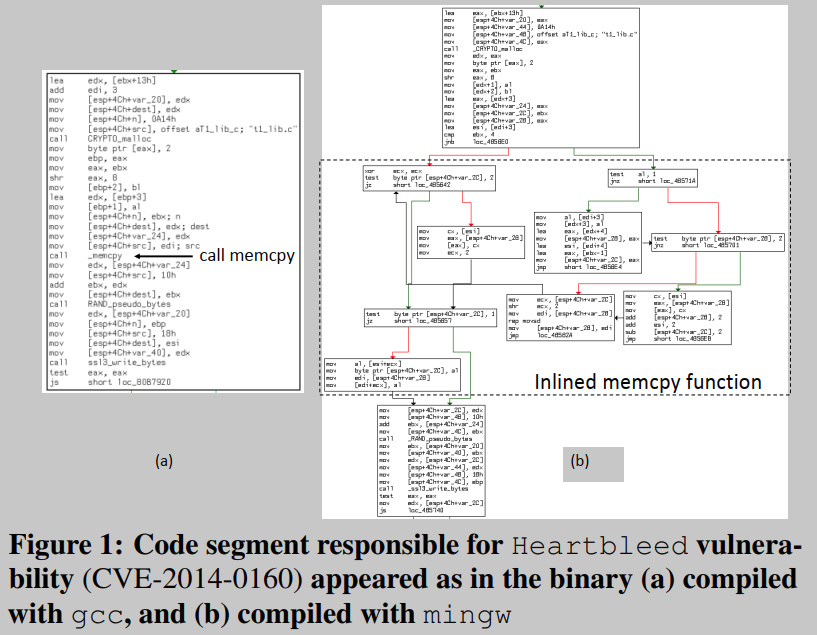
相同的源代码在编译后可能具有不同的基本块结构。以臭名昭著的“心脏出血”漏洞(CVE-2014-0160)为例,图1(a)和图1(b)分别显示了用gcc和mingw编译的同一源代码的基本块结构。显然,这两个二进制代码段没有相同的基本块结构——在gcc中,易受攻击的代码被表示为单个基本块;使用mingw,表示为几个基本块。详细检查表明,在mingw版本中,库函数memcpy是内联的;而在gcc中则不是。这两种二进制代码之间巨大的语法和程序结构差异给现有的二进制代码搜索工具带来了最大的挑战。
挑战主要由三个方面:
(C1) 使用程序结构属性的挑战:现有方法假设基本块结构在不同二进制之间维持不变,在此基础上,将签名函数在基本块级提取的语义特征与目标函数提取的语义特征进行两两比较,不过实际上这个假设不适用现实场景。
(C2) 覆盖完整函数语义的挑战:大多数现有的静态技术都是孤立地考虑函数的,也就是说,被调用方函数的语义并不被视为调用方语义的一部分。这导致了部分语义问题,特别是当程序员将最常用的代码段作为一个独立的函数或实现她自己版本的标准C库函数时。为了解决这个问题,可以盲目内联所有被调用函数(例如所有用户定义的函数都内联)。不幸的是,这种方法在实践中并不适用,主要原因有两个:(1)大量内联可能导致代码大小爆炸,这不能扩展到现实的二进制分析,以及(2)并非所有的被调用函数在功能方面都与调用函数密切相关。
(C3) 在现实世界的大型二进制文件中进行可伸缩搜索的挑战:一般来说,基于语法的技术是可伸缩的。但是,正如前面所讨论的,它们在跨架构分析中失败了。为了解决这个问题,基于语义的技术是首选,但是,提取语义特征会带来很大的开销,而且不可扩展。因此,为了促进可伸缩的语义匹配,需要一个高效的、与体系结构、操作系统和编译器无关的函数过滤步骤。但是现有方法只考虑过滤器的效率,比如只考虑基本块数目作为过滤的标准,虽然可以加快过滤速度,但这个做法在跨架构和操作系统条件下并不健壮。
方法
Overview
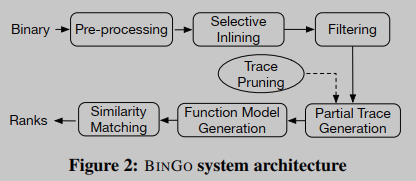
BINGO的工作流程如图2所示。首先,给定一个签名函数,BINGO将对二进制文件进行预处理,即从函数中分解和构建CFG,以进行进一步分析。接下来,对于每个函数,在目标二进制文件中,密切相关的库和其他用户定义的函数被标识和内联。然后,从这些内联的目标函数中,使用三个过滤器(考虑程序语义的不同方面)筛选出与签名函数相似的候选函数列表。接下来,从签名和入围的目标函数中,生成长度变化的部分跟踪,然后将其分组形成函数模型。在部分跟踪生成阶段,进行跟踪剪枝,从分析中去除不相关和不可行的部分跟踪。然后,从函数模型中提取语义特征,用于语义相似性匹配。最后,根据获得的相似度分数,BINGO按顺序返回语义上与签名函数相似的目标函数。
总之,为了解决指令的语法差异,我们将低级汇编指令提升为相应的中间表示(IR),以方便跨架构分析。为了缓和C1(例如,图1中签名函数中的单个基本块与目标函数中的多个基本块匹配),我们借用了TRACY[11]中使用的tracelet的思想。与原来使用固定长度的跟踪不同,我们使用长度可变的部分跟踪。接下来,为了克服C2(例如,是否内联图1(a)中的memcpy),我们提出了一种选择性内联策略,以在所需的上下文语义和内联造成的开销之间取得平衡。最后,为了解决C3问题,我们采用了三个过滤器,考虑语义的不同方面来识别相似的函数。
SELECTIVE INLINING
内联是一种编译器技术,用于优化二进制文件的最大速度和/或最小大小。本节介绍的选择性内联技术,与编译过程相比,它具有不同的目标和策略。
为了内联相关函数,我们使用函数调用模式来指导内联决策。基于我们的研究,我们确定了六种常见的调用模式,并在图3中进行了总结。图3中的传入(传出)边表示对函数的传入(传出)调用。在这里,我们详细阐述这六种模式如下。

案例1:图3(a)描述了被研究的调用方函数对标准C库函数的直接调用。
案例2:图3(b)描述了调用者和UD(用户定义的)被调用者函数f之间的递归关系。
案例3:图3©描述了效用函数的常见模式,例如UD的被调用方函数f被许多其他UD函数调用,而f调用几个库函数和极少数(或零)UD函数。这表明f的行为是一个实用函数(utility function),因为f有一些其他函数通常需要的语义,因此f很可能是需要内联的。
案例4:图3(d)中的UD的被调用函数f是3©的变体,其中它有几个对库函数的调用,而对其他UD函数的调用为零。
案例5:在图3(e)中,UD的被调用函数f是3(d)的变体,它只调用库函数。
案例6:图3(f)描述了一个调度器函数的场景,其中UD函数f由许多其他UD函数调用(即传入调用),f本身调用许多其他UD和库函数。在这种情况下,f似乎是一个没有太多唯一语义的分派器函数,因此,在大多数情况下,不是内联的。
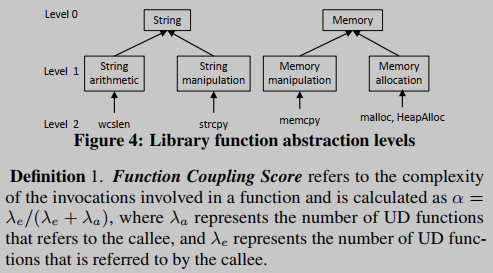
为了确定要内联的常用函数(即实用函数)的情况,我们借用了软件质量和体系结构恢复社区的耦合概念。在软件度量中,两个软件包之间的耦合是通过它们之间的依赖关系来度量的,例如,软件包不稳定性度量[29]。在这项工作中,类似地,我们通过函数耦合得分来衡量函数耦合。α值越低,被调用对象就越可能内联。其基本原理是,低功能耦合得分意味着功能的高度独立性——成为效用函数的可能性很高。

算法1给出了所提出的选择性内联过程。首先,如果被调用者是选定的库函数之一(例如,在情况1中,memcpy和strlen),它将直接内联到调用者中(第3-5行),其余的库函数将被忽略。接下来对于其他用户自定义(user-defined,UD)的函数f,调用f函数的其他UD函数表示为 I u f I_u^f Iuf;而被f调用的库函数和UD函数在第8-9行分别被标识为 O l f O^f_l Olf和 O u f O_u^f Ouf。只调用终止类型的库函数的f不内联(第11-12行,这里的条件判断是否等价于只调用中止类型的库函数有待考究)。最后,对于其余的被调用函数,计算函数耦合得分,如果它低于某个阈值t,则被调用函数内联(第13-24行)。这个递归过程继续进行,直到所有相关函数都被分析完毕。
FUNCTION FILTERING
为了处理现实二进制文件中大量的目标函数,有效的过滤过程可以在昂贵的匹配步骤之前删除不相关的目标函数。BINGO利用三种类型的过滤器,从特定的过滤器(细粒度的)到最一般的过滤器(粗粒度的),来列出候选目标函数。
过滤器1:库函数调用
过滤器2:库调用操作类型,即匹配库调用的抽象功能。比如“String arithmetic”,“String manipulation”,“Memory manipulation”,“Memory allocation”
过滤器3:签名和目标函数之间的指令类型相似性,在Intel和ARM架构下,指令分别被分为14种和8种指令类型。例如,mov指令映射到数据移动指令类型,而push映射到堆栈操作。

过滤算法 过滤器1是特定的,与操作系统相关。过滤器2和3是通用的、跨操作系统和跨架构的。过滤过程如算法2所示。在第7行、第9行和第11行,我们使用Jaccard距离来衡量签名和目标函数之间的相似性,即它们在相同的库调用、库调用操作类型和指令类型中的相似性。按照从最具体的滤波器到一般滤波器逐一应用滤波器的设计,设置权重(w1 > w2 > w3 > 0)到由Filter 1到Filter 3得到的相似度。在第12行,我们根据三个过滤器上的总体相似性对候选函数进行排序(在第10行计算)。最后,在第13行,我们得到排序结果的前N个,并将它们用于函数模型匹配。
SCALABLE FUNCTION MATCHING
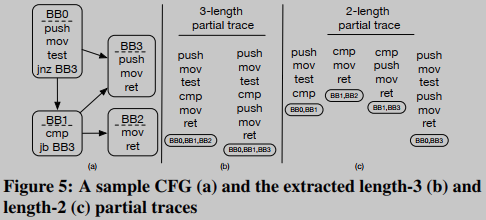
在BINGO中,相似性匹配是在函数和/或子函数级别的粒度上完成的。提出的由长度变化的部分跟踪组成的函数模型,与以基本块为中心的函数模型相比,在比较粒度方面更灵活。论文的部分迹提取是基于David等人[11]提出的技术。这里使用一个示例解释结果(有关部分跟踪提取的更多信息,请参阅[11])。图5描述了一个函数的CFG样本和提取的长度-2和长度-3部分跟踪。可以观察到原始的控制流指令(jnb和jb)被省略了,因为执行流已经确定。
从每个部分跟踪中提取一组符号公式(称为符号表达式),它们捕获执行部分跟踪对机器状态的影响。一般性地,机器状态可以用一个三元组来描述
X
=
⟨
mem
,
reg
,
flag
⟩
\mathcal{X}=\langle\text { mem }, \text { reg }, \text { flag }\rangle
X=⟨ mem , reg , flag ⟩,在执行部分跟踪的前后的机器状态可以设为前置状态
X
\mathcal{X}
X和后置状态
X
′
\mathcal{X}'
X′,而符号表达式用来捕获前置后置状态之间关系。
为了度量签名和目标函数之间的相似性,可以使用约束求解器(如Z3)来计算从签名和目标函数中提取的符号表达式之间的语义等价性。但是约束求解代价太高不适用于大规模搜索,为了解决可伸缩性问题,在[31]中应用了机器学习技术。具体来说,输入/输出(或I/O)样本是从符号表达式中随机生成的,并将其输入到机器学习模块中以查找语义相似的函数。这里,I/O示例是通过为前置状态变量分配具体值,并为符号表达式中的后置状态变量获取相应的输出值来生成的。不过随机生成I/O样本的缺点之一是符号表达式之间的依赖关系被忽略了。
为此,我们使用Z3约束求解器来生成I/O样本。通过Z3生成I/O样本比用它来证明两个符号表达式的等价性更具可扩展性——I/O样本的生成是每个部分跟踪的一次性工作,而等价性检查在每次比较时都会进行约束求解。
在BINGO中,作者采用了两种跟踪剪枝方法来降低结果中的噪声,并加快匹配过程。BINGO是一个基于静态分析的工具,因此,在实践中很难(甚至不可能)识别所有不可行的部分痕迹。
(1) BINGO利用约束求解器修剪明显的不可行的部分痕迹。如果约束求解器无法为前状态变量和后状态变量找到适当的具体值,则相关的部分跟踪被认为是不可行的。
(2) 从部分跟踪中识别并删除编译器特定的代码。一些优化选项会让编译器在编译二进制时加入很多与源代码逻辑无关的代码,比如一些安全机制的代码。直接从部分跟踪中删除一些代码可能会导致不正确的语义特征,因为这些特征对底层代码语义非常敏感。为此,我们提出了一种保守的方法来解决这个问题,方法是将编译器特定的代码泛化到一些模式中,并系统地修剪包含这些模式的部分跟踪。也就是说,如果编译器特定的代码模式占了代码的大部分(50%或更多),我们就只删除部分跟踪本身,而不是从部分跟踪中删除编译器特定的代码(这很容易出错)。
BINGO利用长度变化的部分跟踪来建模函数。从每个函数中生成三种不同长度的部分跟踪(即k = 1,2,3),它们共同构成了函数模型。以图7中signature (
M
s
i
g
M_{sig}
Msig)和target (
M
t
a
r
M_{tar}
Mtar)函数为例,生成的函数模型如下:
M
sig
:
{
⟨
1
⟩
,
⟨
2
⟩
,
…
,
⟨
1
,
2
⟩
,
⟨
2
,
5
⟩
,
…
,
⟨
1
,
2
,
4
⟩
,
⟨
2
,
4
,
7
⟩
,
…
}
M
tar
:
{
⟨
c
⟩
,
⟨
b
⟩
,
…
,
⟨
a
,
b
⟩
,
⟨
b
,
c
⟩
,
…
,
⟨
a
,
b
,
c
⟩
,
⟨
b
,
c
,
f
⟩
,
…
}
\mathcal{M}_{\text {sig }}:\{\langle 1\rangle,\langle 2\rangle, \ldots,\langle 1,2\rangle,\langle 2,5\rangle, \ldots,\langle 1,2,4\rangle,\langle 2,4,7\rangle, \ldots\} \\ \mathcal{M}_{\text {tar }}:\{\langle\mathrm{c}\rangle,\langle\mathrm{b}\rangle, \ldots,\langle a, b\rangle,\langle\mathrm{b}, \mathrm{c}\rangle, \ldots,\langle a, b, c\rangle,\langle\mathrm{b}, \mathrm{c}, \mathrm{f}\rangle, \ldots\}
Msig :{⟨1⟩,⟨2⟩,…,⟨1,2⟩,⟨2,5⟩,…,⟨1,2,4⟩,⟨2,4,7⟩,…}Mtar :{⟨c⟩,⟨b⟩,…,⟨a,b⟩,⟨b,c⟩,…,⟨a,b,c⟩,⟨b,c,f⟩,…}
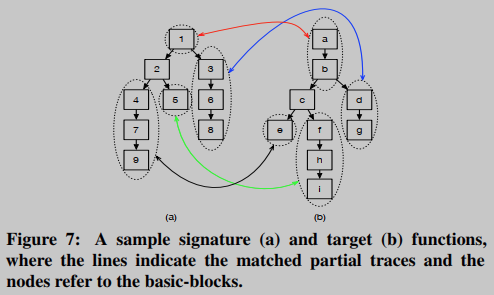
匹配模式则有4种,不同长度跟踪之间的匹配;长1的跟踪和长n跟踪之间的匹配;长n与长1跟踪之间的匹配;基本块之间的匹配

BINGO中,执行所有上述4种类型的函数匹配,以覆盖由于体系结构、操作系统和编译器差异而引起的所有可能的基本块结构差异。最后,将函数模型视为一个部分跟踪的集合,用Jaccard包容相似性来衡量两个不同函数模型之间的相似性得分,定义如下:
s
i
m
(
M
sig
,
M
tar
)
=
M
sig
⋂
M
tar
M
sig
sim(\mathcal{M}_{\text {sig }},\mathcal{M}_{\text {tar}}) = \frac{\mathcal{M}_{\text {sig }} \bigcap \mathcal{M}_{\text {tar}}}{\mathcal{M}_{\text {sig }}}
sim(Msig ,Mtar)=Msig Msig ⋂Mtar
实验
IMPLEMENTATION
在BINGO中,使用IDA Pro来分解并从二进制文件中的函数生成cfg。使用IDA Pro插件从函数CFGs生成部分跟踪,其中它们有三种不同的长度(长度1、2和3)。最后,为了提取语义特征,类似于[31]和[28],将低级汇编指令提升到架构和操作系统独立的中间语言REIL[14]。最初的实验,在选择性内联算法(算法1)中,将函数耦合得分α设置为0.01。同样,在算法2中,过滤器权重w1(用于过滤器1)、w2(用于过滤器2)和w3(用于过滤器3)分别设置为1.0、0.8和0.5。所有的实验都是在一台配有Intel Core i7-4702MQ@2.2GHz和32GB DDR3-RAM的机器上进行的。
通过实验,我们的目标是回答四个研究问题(RQ),分为三个主要主题,即鲁棒性(RQ1和RQ2),应用(RQ3)和可伸缩性(RQ4):

在RQ1中,我们评估了选择性内联算法以证明其有效性。在RQ2中,我们将BINGO与BINDIFF[17]和TRACY[11]进行了比较,间接地展示了在建模函数中使用长度变化部分跟踪的优点。在RQ3中,我们评估了BINGO在寻找现实世界漏洞方面的表现,并将其与discovervre[37]和[31]进行了比较。最后,在RQ4中,我们通过所提出的函数滤波来演示BINGO的性能。
Robustness
BINGO的鲁棒性在于(1)匹配语义等价函数,(2)匹配语义相似函数。RQ1属于标准一,因为我们的目标是将二进制A中的所有函数匹配到二进制B中的所有函数,其中它们都来自相同的源代码(即,在源代码级别上语法相同),但使用不同的编译器和代码优化选项为不同的体系结构编译。RQ2更侧重于在不同源代码的二进制文件中寻找语义相似的函数(即,即使在源代码级别上具有不同的编程风格和编码约定,语法也不同)。通过回答RQ1和RQ2,我们评估了BINGO作为一个搜索引擎有多好,它可以找到不共享源代码但执行语义相似操作的野生二进制可执行文件。
第一个实验是将为一种架构(即x86 32位、x86 64位和ARM)编译的coreutils二进制文件中的所有函数与为另一种架构编译的二进制文件中语义等效的函数进行匹配。考虑到coreutils二进制文件相对较小,每个二进制文件大约有250个函数(平均),我们使用包含2410个函数的BusyBox (v1.21.1)进行第二个实验。我们观察到,得到的结果与coreutils binaries的结果具有可比性——在BusyBox中,平均41.3%的函数排名第一,而coreutils binaries在16个实验中的排名为35%,如图8所示。这比[31]为BusyBox实现的精度提高了27.5%。
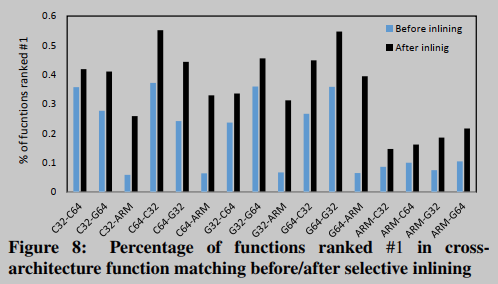
选择性内联显著提高了整体匹配精度,平均提高了150%。特别是,当使用ARM架构作为目标时,选择性内联将总体匹配精度平均提高了400%。表1总结了每个体系结构内联的功能总数。我们注意到,为ARM编译的coreutils包含更多的函数(在103个二进制文件中包含27,820个),而为x86 32位(平均为24,397)和x86 64位(平均为24,136)编译的coreutils。从表1的第二行可以看出,ARM中BINGO选择性内联的函数比x86 32位和64位架构分别多61%和82%。在ARM二进制文件中,大量的函数表明编译器内联不像在其他两种架构中那样频繁发生。因此,需要我们的选择性内联技术来捕获完整的函数语义,从而提高匹配精度。
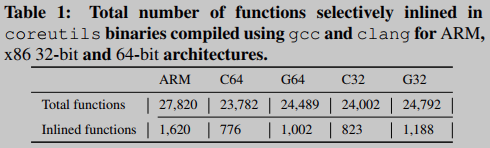
表3总结了针对x86 32位架构的不同编译器(gcc和clang)、不同优化级别(O0、O1、O2和O3)的BINGO所获得的结果。在这里,表的每一行和每一列分别表示用于编译签名函数和目标函数的编译器(包括优化级别)。有趣的是,我们发现无论编译器类型如何,使用高代码优化级别(即O2和O3)编译的二进制文件之间的匹配比没有进行代码优化的二进制文件(即O0)之间的匹配产生更好的结果。也就是说,代码优化级别高,即使使用不同的编译器,二进制代码也会相似,而不进行优化,编译器对二进制代码的影响就非常明显。
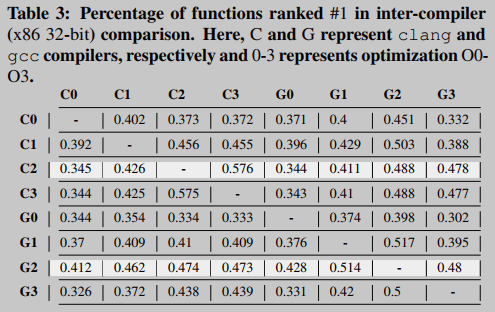
此外,我们在同一编译器的不同版本(gcc v4.8.3 vs. gcc v4.6)上重复了实验,表2总结了结果(适用于x86 32位体系结构)。正如预期的那样,当签名函数和目标函数具有相同的优化级别时,精度最高,但当签名函数以优化级别O1编译时,在这种情况下,以优化级别O2编译的目标函数具有更好的精度。

选择性内联将交叉编译器分析的平均匹配精度提高了约140%。当二进制文件的优化级别是O0而不是O3时,许多函数都是内联的。特别是,平均而言,优化级别O0内联了1473个函数(包括gcc和clang),而优化级别O3只有831个。
第二个实验,用开源和闭源二进制文件进行。在本次实验中,选择Windows mscvrt作为获取搜索查询的二进制文件(闭源),Linux libc作为搜索的目标二进制文件(开源)。在进行这项实验时,我们面临着获得基本真相(ground truth)的挑战。理想情况下,对于msvcrt中的每个函数,我们希望在libc中确定相应的语义相似的函数,这样我们就可以忠实地计算BINGO。为了减少通过人工分析获得基本真相的偏差,我们依赖于官方文档中提供的函数名称和高级描述,例如,msvcrt中的strcpy函数与libc中的strcpy(或其变体)匹配。此外,同一函数的几种变体被归为一类。
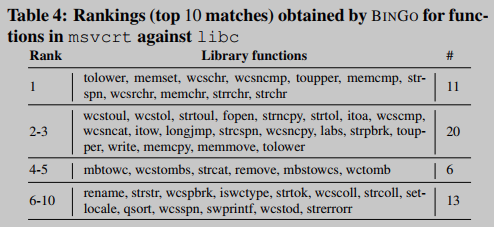
总的来说,我们在msvcrt中为60个标准C库函数构建了ground truth,表4总结了BINGO获得的结果。其中,11项功能(18.3%)排名第一,约51.7%的功能排名在前5位以内,83.3%的功能排名在前10位以内。结果证明了BINGO在识别不共享代码库但语义相似的函数时的鲁棒性。
Applications
第三个实验,利用BINGO来执行漏洞外推,给定一个已知的脆弱代码,称为漏洞签名,使用BINGO,我们试图在目标二进制文件中找到语义相似的脆弱代码段。然而,很少有证据表明使用这种技术来寻找现实世界中的漏洞。原因之一可能是这些工具无法处理大型复杂二进制文件。由于程序结构不可知的函数建模和有效的过滤,BINGO能够处理大型二进制文件。因此,我们评估了我们的工具在寻找现实世界漏洞时的实用性。
Zero-day Vulnerability (CVE-2016-0933) Found:BinGo在adobepdf Reader中使用的一个3D库中发现了一个零日漏洞。在最新版本的adobepdf Reader的一个未指定组件中发现了一个网络可利用的堆内存损坏漏洞。此漏洞的根本原因是缺乏缓冲区大小验证,从而允许未经身份验证的攻击者以较低的访问复杂性执行任意代码。我们使用之前已知的漏洞作为签名,其中签名函数由100多个基本块组成。使用BINGO对库中已知的脆弱函数和所有其他“未知”函数进行建模,然后使用已知的脆弱函数模型作为签名,搜索语义相似的函数。BINGO在疑似3D库中返回了“潜在的”脆弱函数(排名第1)。最后经过人工检测确定了0day vulnerability。
为了评估BINGO是否能够发现跨平台漏洞,我们重复了[31]中报告的两个实验。第一个是libpurple漏洞(CVE-2013-6484),该漏洞出现在Windows应用程序(Pidgin)和Mac OSX (Adium)中的对应程序中。据报道,在[31]中,在不手动制作漏洞签名的情况下,从Windows匹配到Mac OSX,反之亦然,分别达到了排名第165位和第33位。在BINGO中,我们在这两种情况下都获得了排名第一。由于我们的过滤算法中使用了过滤器2(即库调用抽象技术),我们确定了四个库调用(即“字符串操作”:strlcpy,“时间”:time,“输入/输出”:ioctl和“internet地址操作”:inet_ntoa),它们在操作系统中匹配易受攻击的函数。
Scalability
第四个实验验证了BINGO的可扩展性。coretutils二进制文件筛选候选目标函数只需要几毫秒的时间。例如,在跨架构分析中,比较为一种架构编译的整个coreutils套件(总共103个二进制文件,每个二进制文件平均包含250个函数)平均需要91.8毫秒,而在跨编译器分析中则减少到68.6毫秒。经过过滤,对于coreutils二进制中的每个签名函数,在跨架构分析中平均有21个目标函数入围,在跨编译器分析中进一步减少到13个函数。对于像BusyBox这样的大型二进制文件(大约3250个函数,39179个基本块),过滤目标函数平均需要6.16秒,对于每个签名函数,只有不到40个目标函数入围。同样,对于openssl中的SSL/Heartbleed漏洞搜索(大约5700个函数,超过60K基本块),过滤过程需要12.24秒,只有53个函数入围。
BINGO的主要开销是部分跟踪生成和语义特征提取操作。例如,从2611个libc函数中提取语义特征需要4469秒——从一个libc函数中提取语义特征平均需要1.7秒,而从1220个msvcrt函数中提取语义特征只需要1123秒(平均每个函数0.9秒)。利用我们的过滤技术,语义特征提取这一耗时的步骤不再适用于二进制文件中的所有函数。在实际应用中,语义特征提取是一个一次性的工作,易于并行化。
Threats to Validity
选择性内联的主要限制是不能内联间接调用(即间接调用)的函数。然而,这种限制并不是BINGO特有的,而是所有基于静态分析技术的固有问题。早在2005年,人们就已经发现了这个问题并提出了解决方案,例如VSA(值集分析)[4]。但是,我们没有将VSA合并到BINGO中,因为它涉及到重量级的程序分析,这可能会导致沉重的性能成本。
总结
Related Works
二进制相似度分析
Saebjornsen等人[35]是二进制代码搜索的先驱之一,他们提出了一个二进制代码克隆检测框架,该框架利用了基于函数建模技术的规范化语法(即规范化操作数)。Jang等人[20]提出使用n-gram模型来获得二进制文件的复杂族系,并对指令助记符进行规范化。基于n-gram特征,通过检查对称距离来完成代码搜索。在相似度检验中考虑了二进制控制流图。[7]旨在通过CFG匹配方法从可执行文件中检测受感染的病毒。[27]提出了一种基于图元的恶意软件识别方法,该方法生成CFG的连通k子图,并应用图元着色来检测恶意软件样本和可疑样本之间的公共子图。此外,[34]和[33]也采用了CFG来恢复编译者甚至作者的信息。Tracelet[11]用于捕获执行序列的语法相似性,便于查找相似函数。与我们的工作并行,Kam1n0[13]被提出来解决汇编函数的高效子图搜索问题。不幸的是,上述基于语法的二进制相似性匹配技术在跨体系结构分析中失败了。
基于值的等价性检查
不管源代码是否可用,都可以利用输入-输出(I/O)和中间值来识别语义克隆。Jiang et al.[23]将语义克隆的检测问题视为一个测试问题。他们使用随机测试,然后根据I/O样本对代码片段进行聚类。[36]提供了一种比较x86无循环代码段以测试转换正确性的方法。等价性检查是基于所选的输入、输出和执行完成时机器的状态。注意[23][36]中不考虑中间值。然而,中间值被用来缓解在二进制代码中识别I/O变量的问题。在[21]中,Jhi等人陈述了某些特定中间值的重要性,这些值在同一算法的各种实现中是不可避免的,因此有资格成为指纹识别的良好候选者。根据这一假设,提出了抄袭检测[40]和程序[41]匹配执行历史的研究。
基于差异的等价性检查
BINDIFF[17]构建两个二进制文件的CFG,然后采用启发式方法对两个CFG进行规范化和匹配。本质上,BINDIFF解决了NP-hard图同构问题(匹配CFG)。BINHUNT[19]是一个扩展BINDIFF的工具,它在以下两个方面对二进制差异进行了增强:将匹配CFG视为最大公共诱导子图同构问题,并应用符号执行和定理证明来验证两个基本代码块的等价性。为了解决CFG的非子图匹配问题,BINSLAYER[6]将CFG匹配问题建模为二分图匹配问题。对于这些工具,编译器优化选项可能会改变CFG的结构,从而导致基于图的匹配失败。最近,BLEX[15]被提出来容忍这种优化和混淆差异。基本上,BLEX借用了[23]的思想,用相同的输入执行两个给定二进制文件的函数,并比较输出行为。
基于二进制分析的漏洞检测
动态分析面临两个方面的挑战:设置执行环境的困难,以及阻止大规模检测的可伸缩性问题。据Zaddach等人[39]指出,这些动态方法还远远不能实际应用于高度定制的硬件,如移动设备或嵌入式设备。因此,这些方法很难进行跨体系结构的错误检测。为了解决这个问题,Pewny等人[31]和discover[37]提出了一种静态分析技术,旨在检测针对不同架构编译的同一程序的多个版本中的漏洞。不幸的是,由于严重依赖函数CFG结构,他们的方法很适合于查找同一程序的克隆,但不适用于查找来自完全不同源代码库的应用程序之间的语义二进制克隆。
References
[6] M. Bourquin, A. King, and E. Robbins. Binslayer: accurate comparison of binary executables. In Proceedings of the 2nd
ACM SIGPLAN Program Protection and Reverse Engineering Workshop 2013, PPREW@POPL 2013, January 26, 2013,
Rome, Italy, pages 4:1–4:10, 2013.
[7] D. Bruschi, L. Martignoni, and M. Monga. Detecting selfmutating malware using control-flow graph matching. In Detection of Intrusions and Malware & Vulnerability Assessment, Third International Conference, DIMVA 2006, Berlin, Germany, July 13-14, 2006, Proceedings, pages 129–143, 2006.
[8] J. Caballero, N. M. Johnson, S. McCamant, and D. Song. Binary code extraction and interface identification for security applications. Technical report, DTIC Document, 2009.
[11] Y. David and E. Yahav. Tracelet-based code search in executables. In ACM SIGPLAN Conference on Programming
Language Design and Implementation, PLDI ’14, Edinburgh, United Kingdom - June 09 - 11, 2014, page 37, 2014.
[13] S. H. Ding, B. C. Fung, and P. Charland. Kam1n0: Mapreducebased assembly clone search for reverse engineering. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD. ACM,
2016.
[14] T. Dullien and S. Porst. Reil: A platform-independent intermediate representation of disassembled code for static code
analysis. Proceeding of CanSecWest, 2009.
[15] M. Egele, M. Woo, P. Chapman, and D. Brumley. Blanket execution: Dynamic similarity testing for program binaries and components. In Proceedings of the 23rd USENIX Security Symposium, San Diego, CA, USA, August 20-22, 2014., pages
303–317, 2014.
[16] M. Egele, M. Woo, P. Chapman, and D. Brumley. Blanket execution: Dynamic similarity testing for program binaries and components. In USENIX Security Symposium, 2014.
[17] H. Flake. Structural comparison of executable objects. In Detection of Intrusions and Malware & Vulnerability Assessment, GI SIG SIDAR Workshop, DIMVA 2004, Dortmund, Germany, July 6.7, 2004, Proceedings, pages 161–173, 2004.
[18] M. Gabel, L. Jiang, and Z. Su. Scalable detection of semantic clones. In 30th International Conference on Software Engineering (ICSE 2008), Leipzig, Germany, May 10-18, 2008, pages 321–330, 2008
[19] D. Gao, M. K. Reiter, and D. X. Song. Binhunt: Automatically finding semantic differences in binary programs. In Information and Communications Security, 10th International Conference, ICICS 2008, Birmingham, UK, October 20-22, 2008, Proceedings, pages 238–255, 2008.
[21] Y. Jhi, X. Wang, X. Jia, S. Zhu, P. Liu, and D. Wu. Valuebased program characterization and its application to software
plagiarism detection. In Proceedings of the 33rd International Conference on Software Engineering, ICSE 2011, Waikiki, Honolulu , HI, USA, May 21-28, 2011, pages 756–765, 2011.
[22] L. Jiang, G. Misherghi, Z. Su, and S. Glondu. DECKARD: scalable and accurate tree-based detection of code clones. In
29th International Conference on Software Engineering (ICSE 2007), Minneapolis, MN, USA, May 20-26, 2007, pages 96–
105, 2007.
[23] L. Jiang and Z. Su. Automatic mining of functionally equivalent code fragments via random testing. In Proceedings of the
Eighteenth International Symposium on Software Testing and Analysis, ISSTA 2009, Chicago, IL, USA, July 19-23, 2009, pages 81–92, 2009.
[24] T. Kamiya, S. Kusumoto, and K. Inoue. Ccfinder: A multilinguistic token-based code clone detection system for large
scale source code. IEEE Trans. Software Eng., 28(7):654–670, 2002.
[25] D. Kim, W. N. Sumner, X. Zhang, D. Xu, and H. Agrawal. Reuse-oriented reverse engineering of functional components
from x86 binaries. In Proceedings of the 36th International Conference on Software Engineering, pages 1128–1139. ACM, 2014.
[27] C. Krügel, E. Kirda, D. Mutz, W. K. Robertson, and G. Vigna. Polymorphic worm detection using structural information
of executables. In Recent Advances in Intrusion Detection, 8th International Symposium, RAID 2005, Seattle, WA, USA,
September 7-9, 2005, Revised Papers, pages 207–226, 2005.
[28] L. Luo, J. Ming, D. Wu, P. Liu, and S. Zhu. Semantics-based obfuscation-resilient binary code similarity comparison with
applications to software plagiarism detection. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, pages 389–400. ACM, 2014.
[29] R. C. Martin. Agile software development: principles, patterns, and practices. Prentice Hall PTR, 2003.
[30] J. Ming, D. Xu, and D. Wu. Memoized semantics-based binary diffing with application to malware lineage inference.
In ICT Systems Security and Privacy Protection, pages 416–430. Springer, 2015.
[31] J. Pewny, B. Garmany, R. Gawlik, C. Rossow, and T. Holz. Cross-architecture bug search in binary executables. In 2015
IEEE Symposium on Security and Privacy, SP 2015, San Jose, CA, USA, May 17-21, 2015, pages 709–724, 2015.
[33] N. E. Rosenblum, B. P. Miller, and X. Zhu. Extracting compiler provenance from program binaries. In Proceedings of the 9th ACM SIGPLAN-SIGSOFT Workshop on Program Analysis for Software Tools and Engineering, PASTE’10, Toronto, Ontario, Canada, June 5-6, 2010, pages 21–28, 2010
[34] N. E. Rosenblum, X. Zhu, and B. P. Miller. Who wrote this code? identifying the authors of program binaries. In Computer Security - ESORICS 2011 - 16th European Symposium on Research in Computer Security, Leuven, Belgium, September 12-14, 2011. Proceedings, pages 172–189, 2011.
[35] A. Sæbjørnsen, J. Willcock, T. Panas, D. Quinlan, and Z. Su. Detecting code clones in binary executables. In Proceedings
of the eighteenth international symposium on Software testing and analysis, pages 117–128. ACM, 2009.
[36] E. Schkufza, R. Sharma, and A. Aiken. Stochastic superoptimization. In Architectural Support for Programming Languages and Operating Systems, ASPLOS ’13, Houston, TX, USA - March 16 - 20, 2013, pages 305–316, 2013.
[37] E. Sebastian, Y. Khaled, and G.-P. Elmar. discovre: Efficient cross-architecture identification of bugs in binary code. In
In Proceedings of the 23nd Network and Distributed System Security Symposium. NDSS, 2016.
[39] J. Zaddach, L. Bruno, A. Francillon, and D. Balzarotti. AVATAR: A framework to support dynamic security analysis of embedded systems’ firmwares. In 21st Annual Network and Distributed System Security Symposium, NDSS 2014, San
Diego, California, USA, February 23-26, 2014, 2014.
Insights
(1) 可以参考选择性内联方法确保函数语义完整性
(2) 利用部分跟踪来捕获函数语义特征,作为函数的嵌入
(3) 基于值得等价性检查已经涵盖了I/O样本和中间值识别函数的方法。
(4) 基于差异的等价性检查将函数匹配问题转换为CFG图的图同构/最大公共诱导子图同构/二分图匹配问题,BinHunt已经应用符号执行和定理证明方法来检测基本块的等价性。
(5) 动态分析的方法受限于执行环境的困难,难以胜任跨架构的二进制搜索任务,要么解决执行环境设置问题,要么就只能使用静态分析方法。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









