1、引入POM相关包
<properties>
<poi.version>4.1.2</poi.version>
</properties>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>${poi.version}</version>
</dependency>
2、代码编写
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.poifs.filesystem.DirectoryEntry;
import org.apache.poi.poifs.filesystem.POIFSFileSystem;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.FileOutputStream;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.io.*;
import java.util.*;
public class World {
/**
* Html转Word
* @author zsj
*/
public static MultipartFile htmlToWord(String html, String filePath) throws Exception {
// 1.生成文件名称
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
String fileName = filePath+"/"+"LangChain" + sdf.format(new Date())+".doc";
// 返回MyltipartFile类
MultipartFile multipartFile = null;
if (StringUtils.isNotEmpty(html)) {
if (StringUtils.isNotEmpty(html)) {
// 生成临时文件(doc)
try {
// 生成doc格式的word文档,需要手动改为docx
byte by[] = html.getBytes("UTF-8");
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(by);
POIFSFileSystem poifsFileSystem = new POIFSFileSystem();
DirectoryEntry directoryEntry = poifsFileSystem.getRoot();
directoryEntry.createDocument("WordDocument", byteArrayInputStream);
// 临时文件夹
// 临时文件夹
String sqlFilePath = "I:\\supply-link\\工作" + File.separator + "patrolReport" + File.separator + "temp_" + UUID.randomUUID();
File directory = new File(sqlFilePath);
if (!directory.exists()) {
directory.mkdirs();
}
// 文件路径
String fileUrl = filePath + File.separator + "招标公告详情.doc";
// 保存doc文档
FileOutputStream outputStream = new FileOutputStream(fileUrl);
poifsFileSystem.writeFilesystem(outputStream);
byteArrayInputStream.close();
outputStream.close();
File file = new File(fileUrl);
} catch (Exception e) {
e.printStackTrace();
}
}
}
return multipartFile;
}
public static void main(String[] args) {
String htmlUrl = "***"; // 替换为你要解析的HTML页面的URL
try {
// 解析HTML
Document doc = Jsoup.connect(htmlUrl).get();
String htmlSection = doc.select(".Content").html();
//String html =World.html ;
String filePath="I:\\supply-link\\工作";
htmlToWord(htmlSection, filePath);
} catch (Exception e) {
e.printStackTrace();
}
}
}
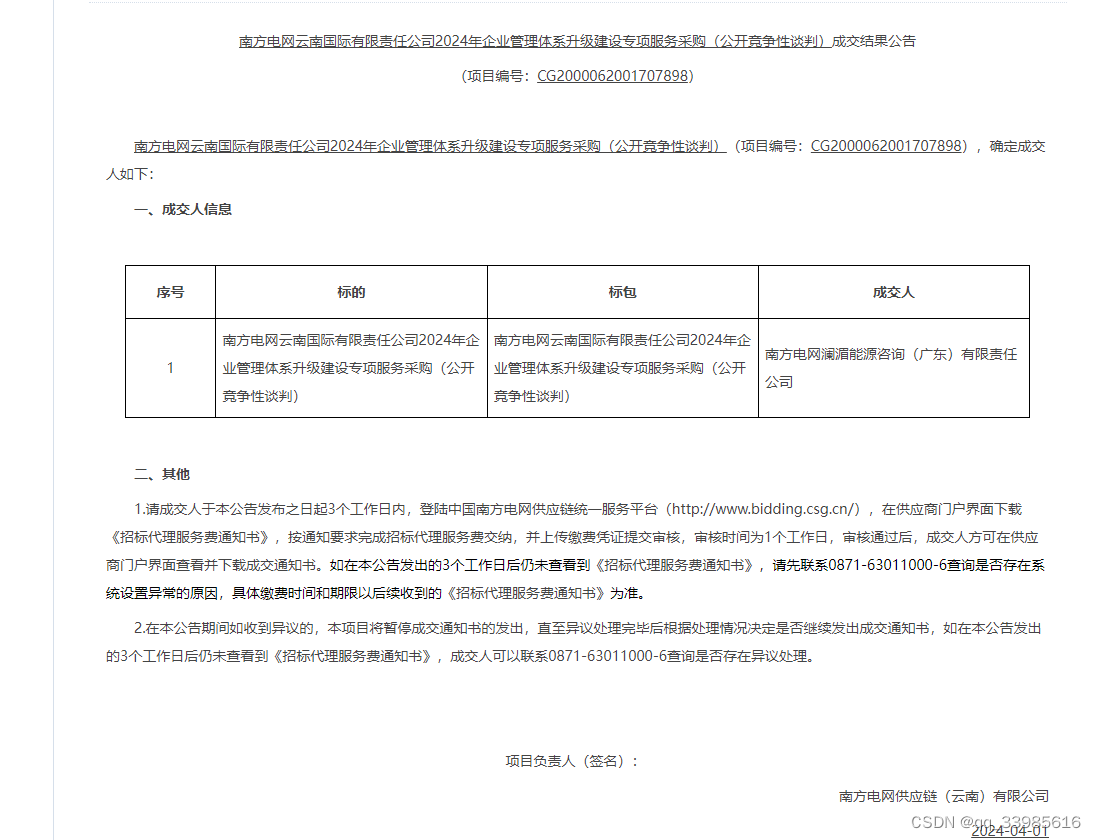
3、页面效果
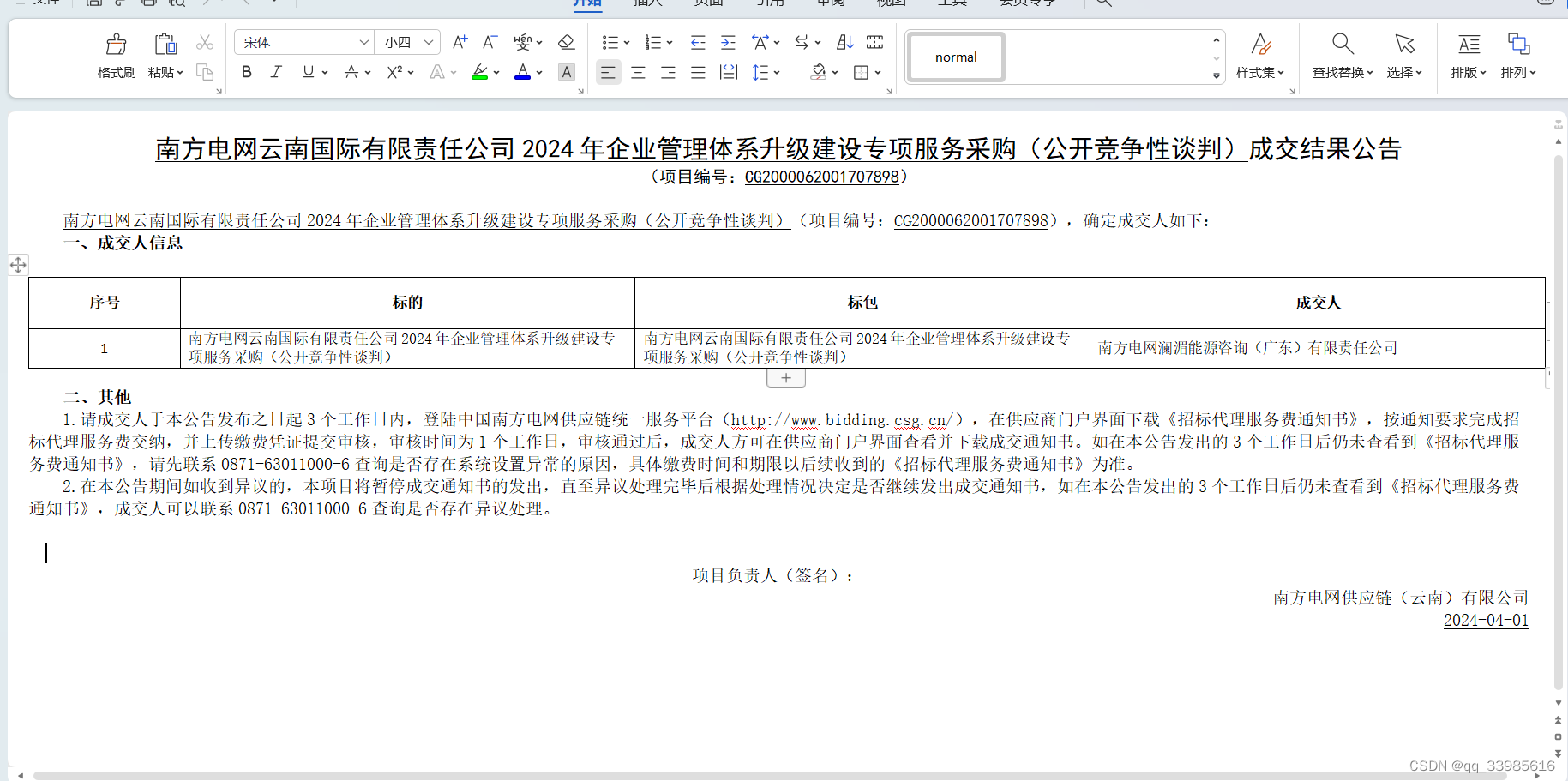
3、word成品效果























 2378
2378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









