









1、创建表并且插入数据
create table `test` (
`id` int (11),
`name` varchar (765),
`address` varchar (765)
);
insert into `test` (`id`, `name`, `address`) values('1','aa','cc');
insert into `test` (`id`, `name`, `address`) values('2','aa','cc');
insert into `test` (`id`, `name`, `address`) values('3','aa','cc');
insert into `test` (`id`, `name`, `address`) values('4','bb','cc');
insert into `test` (`id`, `name`, `address`) values('5','bb','cc');
insert into `test` (`id`, `name`, `address`) values('6','a','1');
insert into `test` (`id`, `name`, `address`) values('7','b','2');
2、根据name和address作为重复数据的字段条件
SELECT `name`,`address`,COUNT(*) AS '重复条数'
FROM `test`
GROUP BY `name`,`address`
HAVING COUNT(*)>1
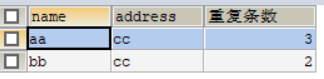
HAVING COUNT(*)>1 分组后将组内数据条数大于1的筛选出来
3、获取到重复数据的id集合
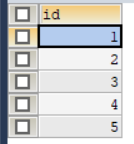
SELECT id FROM `test` a
WHERE (a.`name`,a.`address`)
IN (
SELECT `name`,`address` FROM `test`
GROUP BY `name`,`address`
HAVING COUNT(*)>1
)
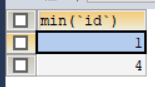
4、从分组中取出每一组数据的一个最大或者最小id(最大、最小id对于聚合函数中的max和min)
SELECT MIN(`id`)
FROM `test`
GROUP BY `name`,`address`
HAVING COUNT(*)>1
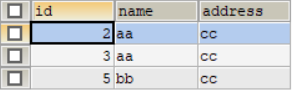
5、查询出需要删除的数据
思路:表中数据的id属于重复字段中的id,但是又不是(最小和最大id),得到的id就是需要删除的数据
SELECT * FROM `test` WHERE `id`
IN (SELECT id FROM `test` a WHERE (a.`name`,a.`address`)
IN (SELECT `name`,`address` FROM `test`
GROUP BY `name`,`address` HAVING COUNT(*)>1))
AND `id` NOT IN (SELECT MIN(`id`) FROM `test`GROUP BY `name`,`address` HAVING COUNT(*)>1)
6、将得到的数据进行删除
这里需要将得到的数据做为另一张表进行条件删除
DELETE FROM `test` WHERE `id` IN (
SELECT `id` FROM(
SELECT * FROM `test` WHERE `id`
IN (
SELECT id FROM `test` a WHERE (a.`name`,a.`address`) IN
(SELECT `name`,`address` FROM `test`
GROUP BY `name`,`address` HAVING COUNT(*)>1)
)
AND `id` NOT IN (
SELECT MIN(`id`) FROM `test`GROUP BY `name`,`address` HAVING COUNT(*)>1)
)
AS a
)















 3390
3390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









