







 AP算法是一种适用于高维、多类数据的快速聚类方法,通过吸引度和归属度矩阵实现。在scikit-learn中,可以通过设置参数如damping和convergence_iter来使用AffinityPropagation类进行聚类。fit方法用于训练,predict方法用于预测,结果包括聚类中心的位置。
AP算法是一种适用于高维、多类数据的快速聚类方法,通过吸引度和归属度矩阵实现。在scikit-learn中,可以通过设置参数如damping和convergence_iter来使用AffinityPropagation类进行聚类。fit方法用于训练,predict方法用于预测,结果包括聚类中心的位置。
Affinity Propagation Clustering(简称AP算法)是2007提出的,当时发表在Science上《single-exemplar-based》。特别适合高维、多类数据快速聚类,相比传统的聚类算法,从聚类性能和效率方面都有大幅度的提升。
首先介绍一下算法原理。
首先引入两个概念,吸引度和归属度矩阵
吸引度(responsibility)矩阵R:其中r(i,k)描述了数据对象k适合作为数据对象i的聚类中心的程度,表示的是从i到k的消息;
归属度(availability)矩阵A:其中a(i,k)描述了数据对象i选择数据对象k作为其据聚类中心的适合程度,表示从k到i的消息。
Step1:算法初始,这两个矩阵均初始化为0矩阵。
Step2:更新吸引度矩阵
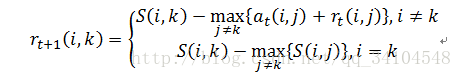
Step3:更新归属度矩阵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









