







QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving
摘要
量化技术能够加速大规模语言模型(LMM)的预测。在INT8量化方法之上,研究者们正积极探索更低精度的技术,如INT4量化。然而,目前的INT4量化算法尚未实现对GPU中加速器内部重要运算(weight和KV全盘逐段)的低负载表现。我们发现,有关如何提高LMM服务效率的问题核心在于对GPU上进行操作时处理速度与通道数密切相关。因此,我们开发了QoQ量化算法,其中W4A8KV4指的是 4-bit weight、8-bit activation和4-bit KV cash;它还能将整个系统预测速度提高了1.2倍(比TensorRT提高了一倍),1.4倍(比Llama-3提高了两倍)在A100上。由于QServe可以将整个系统的预测速度再提高 2.4倍(TensorRT仅是一倍),我们发现L40S GPU中对比性能更好;同时通过使用QServe可以将LMM服务成本降低3倍。因此,实证研究表明 QoQ量化算法在极大地提高了 LLM 的预测速度。
论文摘要:
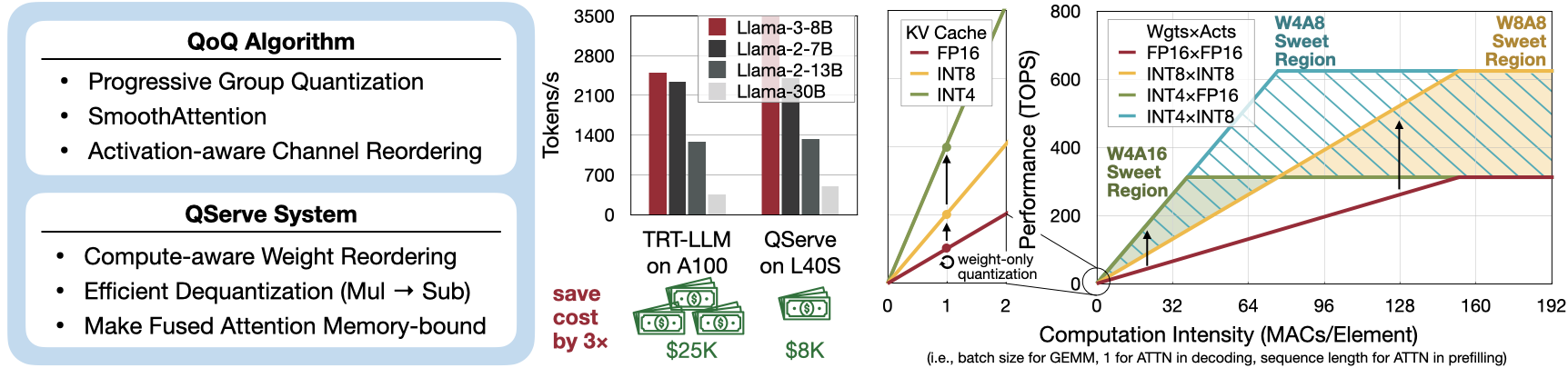
亮点
针对小批量和大批量数据进行的高效LLM推理
将SmoothQuant和AWQ的优点结合起来
比较着重于在A100上的TensorRT-L40框架性能与更经济实用的GPU L40产品,这些是具有成本效益的GPU设计
四位元缓存内容压缩算法
编码开源化了
结论
我们对QServe W4A8KV4的量化器性能在常用的主流LLM中进行了广泛测试,发现其从精度方面优于已有的W4A4或者W4A8解决方案。同时QServe提供了业界领先的LLM服务效率。
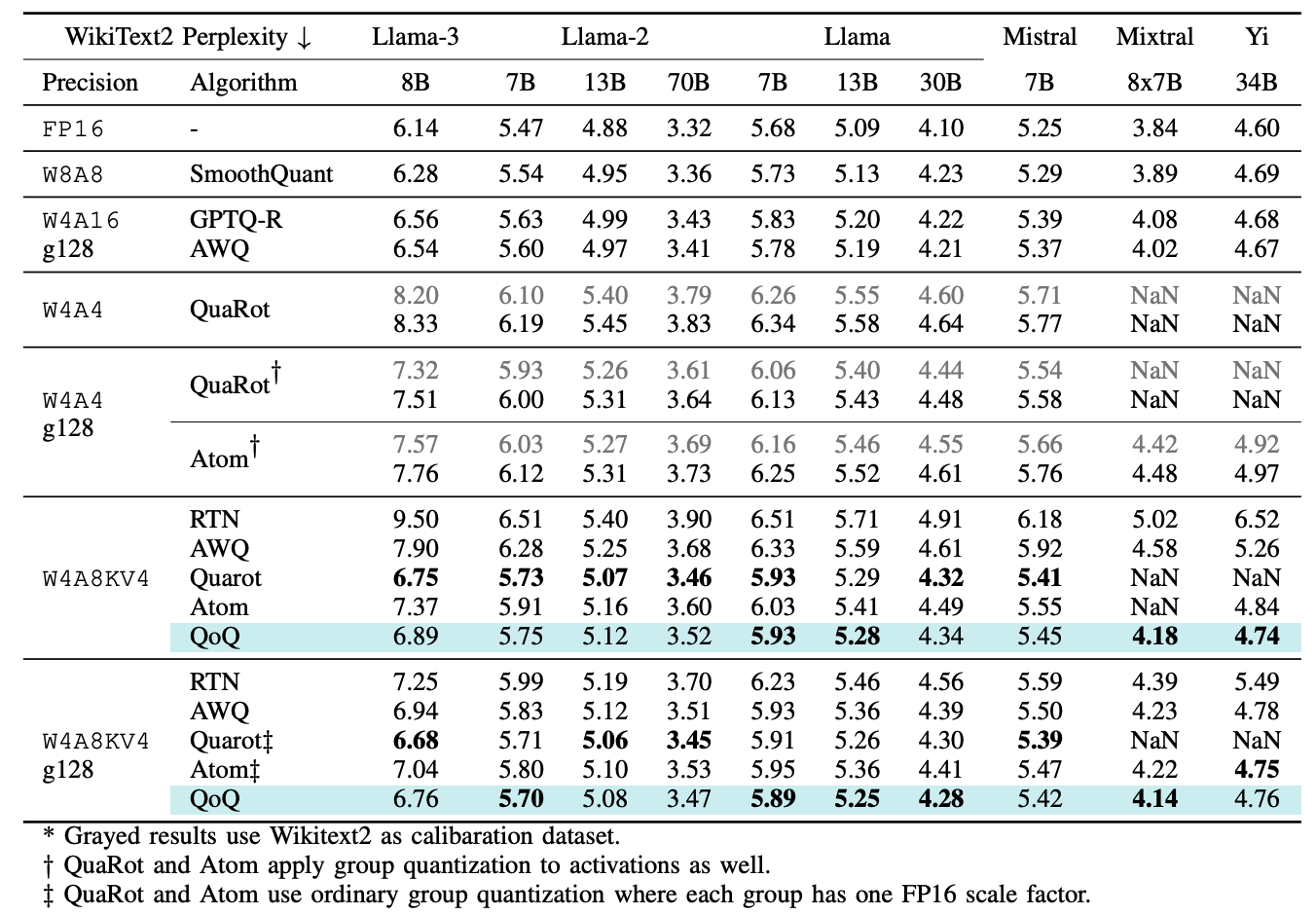
准确性评估
下面是使用了2048个序列长度进行评估的WikiText2搜索结果紧密性值,其数值越小越好。
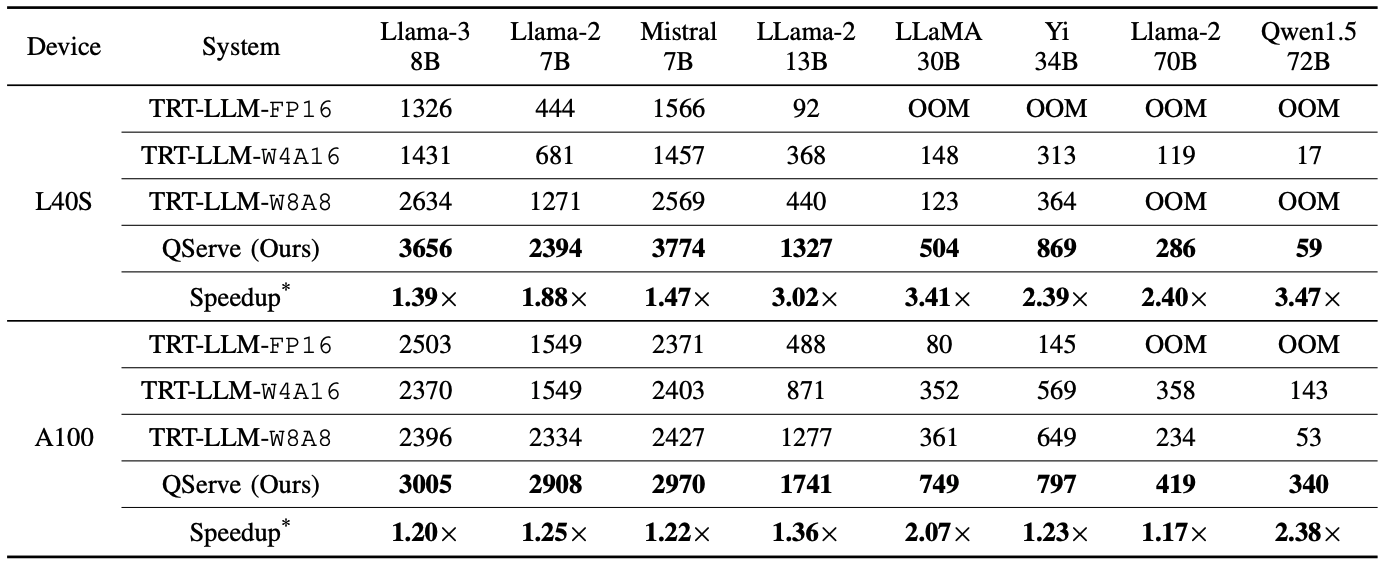
效率指标
在使用大型语言模型(Llama-3和Qwen1.5)以及A100 GPU上执行的评估中,QServe能够实现更高效率、并比领先行业解决方案(TensorRT-LLM)在处理Llama-3和Qwen1.5语言模型时提供的性能有所超越,其中在处理 Llama-3 8B 大规模语言模型时增加了1.2~1.4x高的吞吐量(TensorRT-LLM为1.097)。对 Qwen1.5 64B 大型语言模型来说,其处理效率是 TensorRT-LLM A100 GPU上表现的两倍多(2.4~3.5x)。与之比较而言,QServe在 L40S 和TensorRT-LLM A100 GPU上处理相同规模语言模型时均能提供更高的性能(领先行业解决方案为每个样本),有效地将了服务大型语言模型成本从目前的10%左右下降到约3倍。
标准配置:计算性能较高的NVIDIA GPU,输入语料长度为1024个字节,输出生成长度为512个字节。对支持并行注意力模式的系统,我们将其中一项功能开启。在效率测试中关闭了空投算法。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











