







引言
在上篇博文中,我们学习了 [bx+si] 的灵活寻址形式,由此讲解了汇编中的多重循环实现。那么本篇博文中,我们将继续学习灵活寻址其他实现形式。
本次学习从一道编程案例开始学起。
编程示例如下:
assume cs:code,ds:data
data segment
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends题目:编程实现将data段中每个单词的前四个字母改为大写字母。
题目分析
首先我们观察给出的每行数据中,前三位的数据不再是字母,也就意味着我们在进行大小写转换时,需要避开前三位,转换从第4位开始,即下标3。那么我们可以将行偏移 bx 设置为3,即从第4位数据开始访问,列偏移 si 设置为0,这样我们就只访问到每行中的单词前4个字母,然后对其进行大写转换即可。
编程实现
编写代码如下:
assume cs:code,ds:data,ss:stack
data segment
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start:
mov ax,data
mov ds,ax ; 设置数据段
mov bx,3 ; 设置行起始偏移为3
mov cx,6 ; 设置外层循环为6次
s:
push cx ; 将当前外层循环数入栈
mov cx,4 ; 设置内层循环为4次
mov si,0 ; 设置列起始偏移为0
s1:
mov al,ds:[bx+si] ; 取 bx+si 下的字节数据到al寄存器中
and al,5FH ; 将al寄存器中的数据与5FH进行且运算,将结果放到al寄存器中
mov ds:[bx+si],al ; 将al寄存器中的数据放到 bx+si 字节单元下
add si,1 ; 列偏移加1,移到下一个字节单元
loop s1 ; 判断内层循环是否结束
pop cx ; 将外层循环数出栈,放到CX寄存器内
add bx,16 ; 行偏移加16,移到下一行
loop s ; 判断外层循环是否结束
mov ax,4c00H
int 21H
code ends
end start由于我们初始化将bx偏移位置设置为3,且每一行的长度都是16行,那么bx加上16后,所处的偏移位置是第二行的下标3处,这样就保证了第二行起始位置是英文单词。
我们将上述代码编译连接后,在Debug内进行运行调试,观察执行情况:
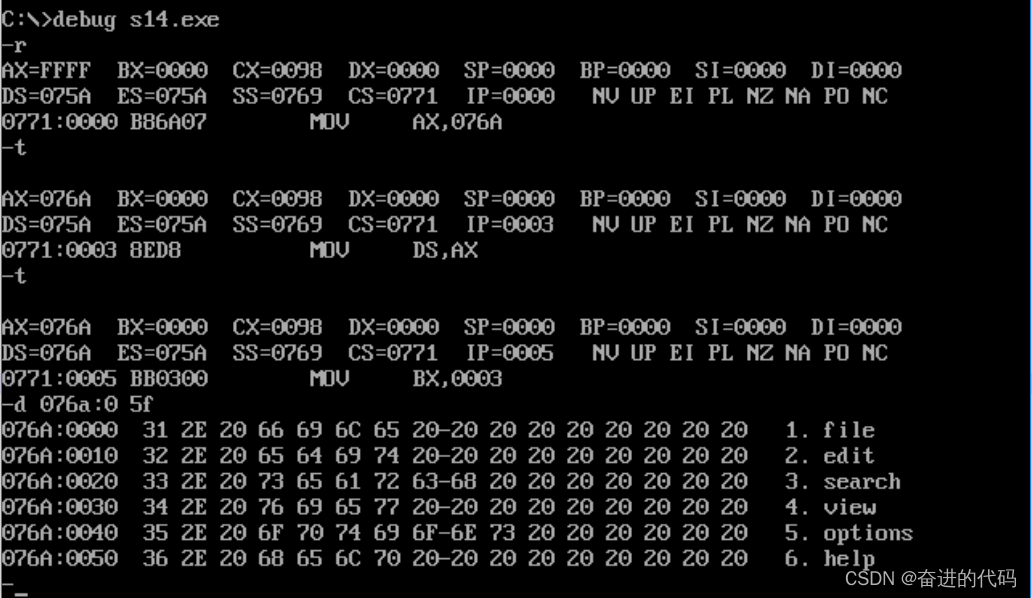
首先我们设置完数据段后,使用d命令查看当前数据段中的数据如上图,接下来我们使用t命令加p命令,结束双层循环后,查看此时数据段中的数据如下图:

可以看到,我们编码实现了题目要求,将每行中每个单词的前4个字母转换成了大写。
疑问
看到这里你可能会存在疑问,在上述编码实现中,我们使用的是 [bx+si] 形式来做的,该形式是上篇博文中的所学内容,那么本篇博文中我们是要学习新的寻址形式的,既然 [bx+si] 已经可以解决问题,还学什么新寻址呢?
其实不尽然,[bx+si] 虽然已经功能强大,但是在某些情况下,还是会面临着局限性。比如,我们将上述题目中的数据做出以下修改:
assume cs:code,ds:data
data segment
db '1. file '
db 'edit '
db '3. search '
db '4. view '
db 'options '
db '6. help '
data ends题目:编程实现将data段中每个单词的前四个字母改为大写字母。
观察题目你就会发现,给出的数据中每一行并不在是一个统一的格式,其中第2行、第5行数据,与其他四行数据格式并不相同。那么此时我们使用 [bx+si] 是否还可行呢?答案是当然不行了!
如果使用 [bx+si] 寻址形式,bx的起始偏移位置就是一大难题,如果设置bx起始偏移为0的话,那么第一行、三行、四行、六行的寻址将会发生错误,毕竟它们的起始位置并不是英文字母。当然我们可以通过判断0偏移处的字节数据是否是一个字母来解决这样的问题,但是我们目前还没有学习到判断,所以就需要另外的方式来处理。
使用 [bx+si+idata]
[bx+si+idata] 也是表示一个内存单元,那么该内存单元的偏移地址为:bx中的值加上si中的值再加上一个自然数idata。
指令:mov ax,[bx+si+idata]表示为:
将段地址为DS,偏移地址为 bx 中的值加上 si 中的值 再加上一个自然数 idata下的字单元数据,送入寄存器AX中。
数学化描述为:(ax) = ((ds)*16+(bx)+(si)+idata)
由于 idata 是一个固定的自然数,无法在程序运行中改变,所以 [bx+si+idata] 的寻址方式相比较 [bx+si] 的寻址方式,灵活程度并未大幅度提升。那这里你可能就要疑问了,既然灵活程度上提升不大,那为什么还要再增加一个这样的寻址呢?它的意义在什么地方?
我们知道遍历一个类二维数组的内存空间,我们使用 bx 来定位每行数据的起始地址,通过si自增,来使用 si 来遍历每行中的每列数据。那么增加的自然数 idata ,则相当于定位了列的起始地址。
示例1
就拿本篇博文开头的编程示例来说。
data segment
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends我们观察发现,每一行中,第4列开始才是英文字母,在示例中我们通过设置行的起始位置bx为3来完成了寻址。这里使用 [bx+si+idata] 来做,行的起始位置bx为0保持不变,设置列的起始位置为3,即 idata 为3,那么我们照样可以完成寻址。
代码只需改动几处:
assume cs:code,ds:data,ss:stack
data segment
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start:
mov ax,data
mov ds,ax
mov bx,0 ; 设置行的起始偏移为0
mov cx,6
s:
push cx
mov cx,4
mov si,0
s1:
mov al,ds:[bx+si+3] ; 偏移再加上3,确定列的起始偏移
and al,5FH
mov ds:[bx+si+3],al
add si,1
loop s1
pop cx
add bx,16
loop s
mov ax,4c00H
int 21H
code ends
end start该代码和上面的代码改动处就在于,首先我们将bx的值重新归0,即行的起始位置回归0;然后将 [bx+si] 改为 [bx+si+idata],其中 idata 即列的起始位置,我们设置为3,这样在寻址时就会从每行中的第四列开始,确定寻到的数据为英文字母。
我们将上述代码编译连接后,在debug中运行调试,使用d命令查看结果:

可以看到我们将前四个英文字母变成了大写,使用 [bx+si+idata] 寻址完成了要求结果。
思考
在上述示例中,我们虽然明白了 [bx+si+idata] 的使用,但是还是存在一丝疑惑,那就是 idata 似乎并没有为寻址提供了多少便利,尤其是在本篇开头的示例中,我们直接使用 [bx+si] 的寻址方式照样完成,idata 成为了可有可无的存在。那么存在 [bx+si+idata] 它到底是为了什么?
首先这里说明,在 [bx+si+idata] 寻址方式中,idata的主要功能是定位二维数组中每行中的寻址起始位置。例如上述实例中,每行的数据需要从第3位开始,所以idata值便设置为3即可。
你会反驳说这个起始位3,我们可以设置si起始为3或者去设置bx,不需要再来一个idata来凑热闹呀~当然,如果你面临的是上述的示例,你完全可以这样做没问题,只是不符合编程规范而已。
注意,汇编语言虽然是低级语言,它也是有自己的编程规范的,对于内存访问场景,规范要求应该尽量使 bx 寄存器、si 寄存器、di 寄存器等一些值初始为0,而不要赋值一个非0的初始值。
为什么要有这样的规范呢?那是因为寄存器初始值为0符合绝大多数的访问内存场景要求,如果你对此很疑惑,证明你在汇编的开发上比较少。下面,我们通过一个示例,将深入的理解 [bx+si+idata] 的使用场景,领略为何有如此规范的用意!
示例2
data segment
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends编程实现将上述数据段中的,提取每行英文单词的前四个英文字母,将其转换大写后按照每行的排列顺序,写到内存起始地址20000H下。
根据题目思考,首先转换英文大小写我们已经很熟悉了,如何将转换后的数据按行写到新的地址下似乎有点难度。如果使用 [bx+si] 的寻址方式,很明显我们需要设置bx的初始值或者si的初始值为3才能正确寻址到源数据进行处理。但是这样,在写入目的地址的时候却变得很不合理,因为目的地址的起始偏移为0,如果bx的初始值或者si的初始值为3,这样将会导致无法正确写入目的地址。
根据我们的逻辑,源数据的处理和写入目的地址,是在同一个循环下进行,也就是说,寻址源地址和寻址目的地址是要使用相同的偏移地址。因为要求写入的目的地址的起始偏移位置是0,那么就意味着源地址起始偏移也是0才行,这样才保证了两边数据访问的一致性。所以,在该示例中,肯定不能将bx的初始值或者si的初始值设置为3,它俩初始值只能为0!你总不可能说在处理完源数据后,再修改一次bx、si的值来保证写入目的地址正确,这样做只会增加逻辑复杂度,同时降低程序的运行效率!
既然如此,显然使用 [bx+si] 的寻址方式是不符合要求了~使用 [bx+si+idata] 才是解决之道!
编程实现代码如下:
assume cs:code,ds:data,ss:stack
data segment
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start:
mov ax,data
mov ds,ax
mov ax,2000H
mov es,ax ; 设置es段地址为2000H,做为目的地址的段地址
mov bx,0 ; 因为目的地址的起始偏移位置为0,所以bx初始为0
mov cx,6
s:
push cx
mov cx,4
mov si,0 ; 设置每行的起始偏移为0
s1:
mov al,ds:[bx+si+3] ; 使用[bx+si+idata]寻址,设置每行的起始位置为3
and al,5FH
mov es:[bx+si],al ; 写入目的地址,偏移为bx+si
add si,1
loop s1
pop cx
add bx,16
loop s
mov ax,4c00H
int 21H
code ends
end start我们看上述编程实现,其中关键的地方是,我们在寻址源数据的时候,通过 [bx+si+idata] 的形式设置每行的起始位置,这样保证了bx和si初始值为0,在数据写入目的地址时,就可以直接使用bx和si来做为目的地址的偏移地址,确保数据正确写入指定位置。
我们将上述代码编译连接后,在debug中运行调试,使用d命令查看地址2000H:0H~2000H:5FH的数据:
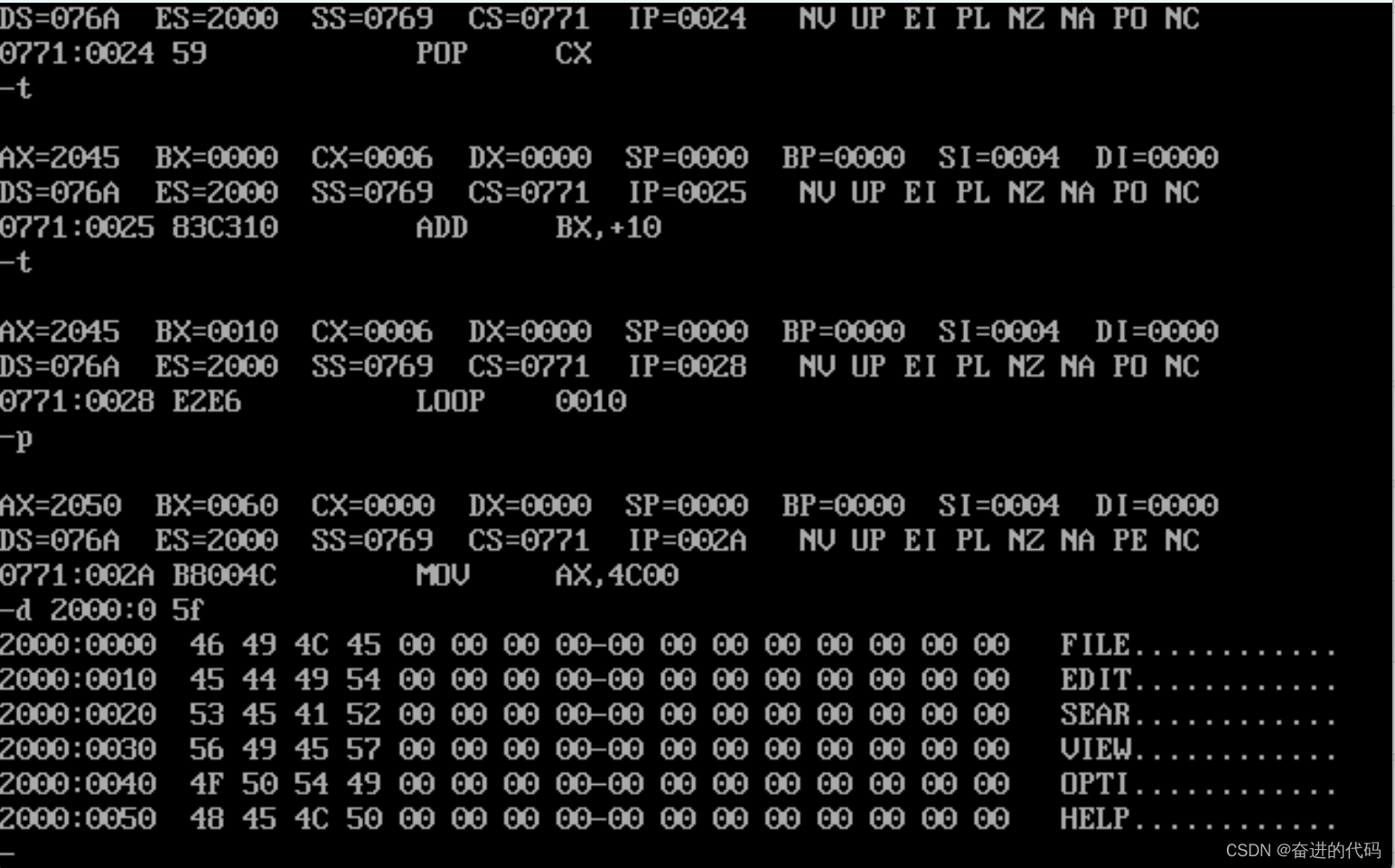
可以看到我们成功将每行英文单词的前四个因为字母转换大写后,将其按照每行的排列顺序写到了指定目的地址下。
总结
[bx+si+idata] 的寻址方式,灵活性体现在:
它通过一个自然数idata来指定在二维数组的寻址中每行的起始位置,使bx、si\di 寄存器无需赋值一个非零初始值,这样保证了在数据复制场景中,源地址和目的地址的偏移地址一致性,提高了内存访问效率。
通过示例2中的编程展示,相信你已经意识到了 [bx+si+idata] 存在的意义,后面在面临复杂的访问内存场景,亦能做到选择适合的寻址方式来处理。
本篇结束语
在本篇博文中,我们学习了一个全新的灵活寻址方式:[bx+si+idata],了解了idata在其的作用和含义,通过具体的示例分析和与 [bx+si] 寻址方式的对比,深入刨析了 [bx+si+idata] 寻址方式的意义所在。
截止到现在,我们已经学习了众多灵活寻址方式,有[bx]、[bx+idata]、[bx+si]、[bx+si+idata] 等等,那么在下篇博文中,我们将对这些寻址方式做一个归纳总结,来加深我们的印象。
感谢围观,转发分享请标明出处,谢谢!















 2521
2521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









