







1.SQL TRACE
1.1SQL跟踪流程
1.1.1开启跟踪
alter session set sql_trace true1.1.2运行需要跟踪的SQL语句
select /*+ no_index(tb test_bitmap_n1 )*/
count(*)
from test_bitmap tb
where 1 = 1
and age between 18 and 22
and sex = 'M'1.1.3关闭跟踪
alter session set sql_trace false如果不关闭跟踪,那么后续该session的操作都会写入跟踪文件中
1.1.4查询跟踪文件所在路径
select * from v$diag_info di where di.name='Diag Trace'
(如果下面的查询不一致,以diag_info表为准)
也可以使用
select value
from v$parameter
where name = 'user_dump_dest';
1.1.5查询跟踪文件名
我们进入到跟踪文件所在目录下,执行ls -alt查找最新修改的文件

怎么判断这个文件是由当前会话产生的呢?
执行下列查询语句
select spid, s.sid, s.serial#, p.username, p.program
from v$process p, v$session s
where p.ADDR = s.PADDR
and s.SID = (select sid from v$mystat where rownum = 1)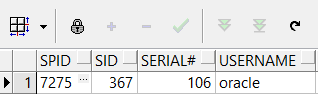
文件VIS_ora_7275.trc就是我们产生的跟踪文件
当然我们可以直接使用下面SQL
select b.username,
a.SPID,
b.SID,
b.SERIAL#,
c.value || '\' || lower(d.value) || '_ora_' ||
to_char(a.spid, 'fm00000') || '.trc' "TRACE_FILE"
from v$process a, v$session b, v$parameter c, v$parameter d
where a.addr = b.paddr
and c.name = 'user_dump_dest'
and d.name = 'db_name'
and b.username is not null;
第一行SPID=7275所在路径对应解析文件,如果你不确定SPID为7275的就是我们打开的session,我们可以使用
select userenv('sid') from dual; 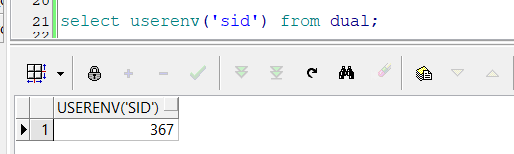
通过请求ID找到trace文件
SELECT a.request_id,
d.sid,
d.serial#,
d.osuser,
d.process,
c.spid,
d.inst_id,
(SELECT c.value || '\' || lower(d.value) || '_ora_' ||
to_char(a.spid, 'fm00000') || '.trc' "TRACE_FILE"
FROM v$process a, v$session b, v$parameter c, v$parameter d
WHERE a.addr = b.paddr
AND c.name = 'user_dump_dest'
AND d.name = 'db_name'
AND b.username IS NOT NULL
AND b.sid = d.sid) trace_file,
(SELECT (SELECT VALUE FROM v$diag_info di WHERE di.name = 'Diag Trace') || '\' ||
lower(d.value) || '_ora_' || to_char(a.spid, 'fm00000') ||
'.trc' "TRACE_FILE"
FROM v$process a, v$session b, v$parameter c, v$parameter d
WHERE a.addr = b.paddr
AND c.name = 'user_dump_dest'
AND d.name = 'db_name'
AND b.username IS NOT NULL
AND b.sid = d.sid) trace_file
FROM apps.fnd_concurrent_requests a,
apps.fnd_concurrent_processes b,
gv$process c,
gv$session d
WHERE a.controlling_manager = b.concurrent_process_id
AND c.pid = b.oracle_process_id
AND b.session_id = d.audsid
AND a.request_id = xxxxxx
2022-4-18更新
不管是通过request_id找到trace文件,还是通过session_id找到trace文件,最终我们都是需要PROCESS_ID,可以是fnd_concurrent_requests.ORACLE_PROCESS_ID,也可以是v$process.SPID。
所以最简单的,可以这样查出来PROCESS_ID
SELECT fcr.oracle_session_id, --这个并不是我们熟悉的sid,而是v$session.audsid,也等于fnd_concurrent_processes.session_id
fcr.oracle_process_id ,--对应trace file文件名
fcp.session_id--这个同oracle_session_id
FROM fnd_concurrent_requests fcr, fnd_concurrent_processes fcp
WHERE request_id = 204728991
AND fcr.controlling_manager = fcp.concurrent_process_id ORACLE_SESSION_ID ORACLE_PROCESS_ID SESSION_ID
1 672618080 82652 672618080
也可以按照上面的,和v$session表关联,下面出现的GV$SESSION考虑到了RAC的情况
SELECT a.request_id,
d.sid session_id,
d.serial#,
d.osuser,
d.process,
c.spid AS os_process_id,--对应我们的oracle_process_id
d.audsid
FROM apps.fnd_concurrent_requests a,
apps.fnd_concurrent_processes b,
gv$process c,
gv$session d
WHERE a.controlling_manager = b.concurrent_process_id
AND c.pid = b.oracle_process_id
AND b.session_id = d.audsid
AND a.request_id = 204728991;这是我们拿到了SID,就能这样查询了
SELECT b.username,
a.spid, --同oracle_process_id 或者v$process.pid
b.sid,
b.serial#,
c.value || '\' || lower(d.value) || '_ora_' ||
to_char(a.spid, 'fm00000') || '.trc' "TRACE_FILE"
FROM v$process a, v$session b, v$parameter c, v$parameter d
WHERE a.addr = b.paddr
AND c.name = 'user_dump_dest'
AND d.name = 'db_name'
AND b.username IS NOT NULL
AND b.sid = 2503这里有一个问题,就是user_dump_dest不一定准确,可能 还是得这样查询
select * from v$diag_info di where di.name='Diag Trace'
1.1.6解析语法
tkprof tracefile output_file [sort=parameters] [print=number] [explain=username/password] [wait=yes|no] [aggregate=yes|no] [insert=filename] [sys=yes|no] [table=schema.table] [record=filename] [width=number]
给一个例子
tkprof VIS_ora_7275.trc VIS_ora_7275_1.prf sys=no sort=(fchela,fchcpu)
tkprof 是一个命令,我们需要查询环境变量,看看tkprof在哪个路径下能被识别,如果你直接在当前路径下执行,会提示
-bash: tkprof: command not found
我们执行一个命令,系统首先会去path查找该命令所在磁盘的位置,去该位置执行该命令。如果找不到,再去当前目录下找,如果也找不到,就会报错:-bash: xxxxx: command not found
我们先找到这个tkprof到底在哪
因为有得文件会加上前缀./进行隐藏,因此我们用正则表达式去匹配
find / -iregex '.*tkprof' 
我们可以自己添加tkprof到我们的path路径里
编辑/etc/profile或者~/.bashrc
前者对应所有的用户,是系统级的环境变量,需要重启服务器,后者适用当前用户,也不需要重启。
我们试一试后面这种
vi ~/.bashrc打开文件

最后面加上export PATH命令,等号后面是我们刚才查找到的路径
编辑完后ESC然后:wq保存退出。
我们再执行一下source ~/.bashrc使之生效
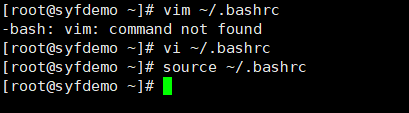
我们切换到跟踪文件所在路径,执行一下tkprof命令

这是怎么一回事?我们看看PATH环境变量

原来是路径写错了,我们重新编辑一下,把/tkprof删掉,这个是文件,不是目录


成功产生解析文件
当然不用那么麻烦,我们可以直接使用applmgr或者oracle用户,因为trace目录所有者为oracle,建议用oracle用户操作

也是吻合的
具体如何编辑环境变量参考如何在Linux中修改环境变量PATH
1.1.7打开解析文件

成功找到了我们的当前会话执行的SQL
可以看到总共有78次读操作,77次是磁盘读
1.1.8产生其它session的跟踪文件
如果是非当前session,我们怎么样得到跟踪文件呢?
首先必须要有需要跟踪会话的sid和serial#,为了测试我新开了一个窗口,当前的sid和serial#如下

开启和关闭跟踪代码如下
begin
DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION(359,737,true);
--DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION(359,737,false);
end;
去trace路径下查看,发现生成了tra文件
1.1.9分析tra文件
tkprof命令见TLPROF Analysis
tkprof 命令行选项
tkprof提供了许多有用的命令行选项,这些选项为DBA提供了附加功能。
·print-仅列出第一行在输出文件中的SQL语句。 如果未指定任何内容,将列出所有语句。 当列表需要限于“ Top n ”语句时,请使用此选项。 与排序选项结合使用时,此功能很有用,以按CPU,磁盘读取或解析等方式启用前n条语句。
·aggregate -如果选择“是”,则tkprof 将合并来自同一SQL语句的多个用户执行的统计信息。 如果为“否”,则每次执行该语句时都会列出统计信息。
·insert-创建一个文件,该文件将统计信息加载到数据库中的表中以进行进一步处理。 如果要对 tkprof输出执行任何高级分析,请选择此选项。
·sys-启用或禁用由SYS用户执行的SQL语句(包括递归SQL语句)的包含。 默认为启用。
·table -在解释计划使用命令(如果指定)为Oracle到负载数据暂时到Oracle表。 用户必须为计划表指定架构和表名。 如果该表存在,则将删除所有行,否则tkprof将创建该表并使用它。
·record -创建具有指定文件名的SQL脚本,该文件名包含跟踪文件中的所有非递归SQL语句。 对于想要将SQL语句记录在单独文件中的DBA,这是可以使用的选项。 在前面的示例中, Allsql.sql 文件的内容包括:
alter session set sql_trace=true ;
select * from employee where emp_id = 87933 ;
alter session set sql_trace=false ;
·explain -对跟踪文件中的每个语句执行一个解释计划,并显示输出。 与tkprof结合使用时,解释计划的用处 不如单独使用时有用。 解释计划提供了预测的优化器执行路径,而无需实际执行该语句。tkprof 向您显示语句执行后的实际执行路径和统计信息。此外,鉴于数据库环境中的依赖关系和更改,针对捕获和保存的SQL语句运行Explain Plan总是有问题的。
·sort -排序由标准的跟踪文件中的SQL语句被视为最重要的由DBA。 使用此选项,DBA可以在文件顶部查看消耗最多资源的SQL语句,而不是在整个文件内容中搜索性能不佳的人。 以下是可用于排序的数据元素:
·prscnt- 解析SQL的次数。
·prscpu- 解析所花费的CPU时间。
·prsela- 解析SQL所花费的时间。
·prsdsk- 解析所需的物理读取数。
·prsmis- 解析所需的一致块读取数。
·prscu- 解析所需的当前块读取数。
·execnt- 执行SQL语句的次数。
·execpu- 执行SQL所花费的CPU时间。
·exeela- 执行SQL所花费的时间。
·exedsk- 执行期间的物理读取数。
·exeqry- 执行期间一致的块读取数。
·execu- 执行期间当前读取的块数。
·exerow- 执行期间处理的行数。
·exemis- 执行期间库高速缓存未命中的数量。
·fchcnt- 执行的访存次数。
·fchcpu- 提取行所花费的CPU时间。
·fchela- 读取行所花费的时间。
·fchdsk-访存 期间读取的物理磁盘数。
·fchqry-访存 期间读取的一致块数。
·fchcu-访存 期间读取的当前块数。
·fchrow- 为查询获取的行数。
存在许多排序选项,但是某些选项比其他选项更有用。 在使用tkprof格式化跟踪输出时,Execnt,execpu,exedsk和prscnt是最有用的排序参数,因为它们更能指示大多数SQL性能问题。执行次数最能说明性能问题,因此应该冒顶。对于使用最多CPU- execpu的SQL语句,尤其如此 。该prscnt 参数非常重要,因为它显示了解析大部分,通常不使用绑定变量的结果的SQL语句。
1.2DBMS_MONITOR
DBMS_MONITOR程序包可以跟踪用户和服务
我们可以像DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION一样传入sid和serial#,也可以传入用户标识符,跟踪用户
1.2.1基于会话
还是用之前查询session的sql
select spid,
s.sid,
s.serial#,
s.username,
s.client_identifier,
p.username,
p.program
from v$process p, v$session s
where p.addr = s.paddr
and s.sid = (select sid from v$mystat where rownum = 1)

系统管理员账户执行下列程序开启跟踪
begin
dbms_monitor.session_trace_enable(351,1067,true,false);
end;关闭跟踪
begin
dbms_monitor.session_trace_disable(351,1067);
end;前两个参数分别为sid和serial#
1.2.2.基于用户
为当前用户设置标识符,比如我设置为123
begin
dbms_monitor.session_trace_enable(351,1067,true,false);
end;这时我们再查询上面的SQL

接着跟踪该标识符,管理员用户下执行
begin
dbms_monitor.client_id_trace_enable('123');
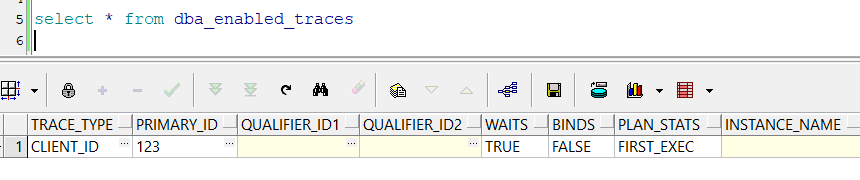
end;查看跟踪是否打开
select * from dba_enabled_traces
关闭跟踪
begin
dbms_monitor.client_id_trace_disable('123');
end;我们发现,打开跟踪后,服务器trace目录下并没有产生trc文件,需要使用trcsess进行合并输出
trcsess
- [output=output_file_name]
- [session=session_id]
- [clientid=client_id]
- [service=service_name]
- [action=action_name]
- [module=module_name]
- [trace_files]
- output指定生成输出的文件。如果未指定此选项,则将标准输出用作输出。
- session合并指定会话的跟踪信息。会话ID是会话索引和会话序列号的组合。
- clientid合并给定客户端ID的跟踪信息。
- service合并给定服务名称的跟踪信息。
- action合并给定操作名称的跟踪信息。
- module合并给定模块名称的跟踪信息。
- trace_files是所有跟踪文件名的列表,用空格分隔,trcsess将在其中查找跟踪信息。通配符*可用于指定跟踪文件名。如果未指定跟踪文件,trcsess将检查当前目录中的所有文件。
我们来使用trcsess合并一下文件
合并过程出现了错误,这个有时间再解决吧

1.3SPM
spm(sql计划管理)
(1)开启SQL添加到计划基线
alter session set optimizer_capture_sql_plan_baselines =true;(2)执行SQL语句
需要多次执行,执行一次没有效果
select * from emp where job='PRESIDENT'(3)关闭添加
alter session set optimizer_capture_sql_plan_baselines =false;(4)查表
select ENABLED, -- 指示计划基准是已启用(YES)还是已禁用(NO)
ACCEPTED, -- 表示计划基线是否被接受(YES)否(NO)
FIXED -- 指示计划基准是否固定(YES)(NO)
from dba_sql_plan_baselines spb;表完整字段如下
SIGNATURE NUMBER NOT NULL 从规范化的SQL文本生成的唯一SQL标识符
SQL_HANDLE VARCHAR2(30) NOT NULL 字符串形式的唯一SQL标识符作为搜索关键字
SQL_TEXT CLOB NOT NULL 未规范化的SQL文本
PLAN_NAME VARCHAR2(30) NOT NULL 字符串形式的唯一计划标识符作为搜索关键字
CREATOR VARCHAR2(30) 创建计划基准的用户
ORIGIN VARCHAR2(14) 计划基准的创建方式:
PARSING_SCHEMA_NAME VARCHAR2(30) 解析模式的名称
DESCRIPTION VARCHAR2(500) 为计划基准提供的文字描述
VERSION VARCHAR2(64) 计划基准创建时的数据库版本
CREATED TIMESTAMP(6) NOT NULL 创建计划基准的时间戳记
LAST_MODIFIED TIMESTAMP(6) 计划基线上次修改的时间戳
LAST_EXECUTED TIMESTAMP(6) 计划基线上次执行的时间戳
LAST_VERIFIED TIMESTAMP(6) 计划基线上次验证的时间戳
ENABLED VARCHAR2(3) 指示计划基准是已启用(YES)还是已禁用(NO)
ACCEPTED VARCHAR2(3) 表示计划基线是否被接受(YES)否(NO)
FIXED VARCHAR2(3) 指示计划基准是否固定(YES)(NO)
AUTOPURGE VARCHAR2(3) 表示是否自动清除了计划基准YES(NO)
OPTIMIZER_COST NUMBER 创建计划基准时的优化程序成本
MODULE VARCHAR2(48) 应用模块名称
ACTION VARCHAR2(32) 申请行动禁用对存储在SQL Management Base中的SQL计划基准
EXECUTIONS NUMBER 创建计划基准时的执行次数
ELAPSED_TIME NUMBER 制定计划基准时经过的总时间
CPU_TIME NUMBER 创建计划基准时的总CPU时间
BUFFER_GETS NUMBER 在创建计划基准时获得的总缓冲区
DISK_READS NUMBER 创建计划基准时的总磁盘读取
DIRECT_WRITES NUMBER 创建计划基准时的直接写总数
ROWS_PROCESSED NUMBER 创建计划基准时处理的总行数
FETCHES NUMBER 创建计划基准时的访存总数
END_OF_FETCH_COUNT NUMBER 创建计划基准时的完整访存总数
(4)增加索引后重复1-3步骤
create index emp_n1 on emp(job);
(5)禁用SQL计划基准
不知道为什么要禁用掉
OPTIMIZER_USE_SQL_PLAN_BASELINES启用或禁用对存储在SQL Management Base中的SQL计划基准的使用。启用后,优化器将为正在编译的SQL语句查找SQL计划基线。如果在SQL Management Base中找到了一个,则优化器将对每个基准计划进行成本估算,并选择成本最低的方案。
alter system set OPTIMIZER_USE_SQL_PLAN_BASELINES=false;
(6)查看执行计划
explain plan for
select * from emp where job='PRESIDENT'select * from table(dbms_xplan.display(null,null,'BASIC'));
这里需要更新一下plan_table表,否则会报错
ERROR: an uncaught error in function display has happened; please contact Oracle support
Please provide also a DMP file of the used plan table PLAN_TABLE
ORA-00904: "OTHER_TAG": invalid identifier
原有的plan_table
create table PLAN_TABLE
(
statement_id VARCHAR2(30),
timestamp DATE,
remarks VARCHAR2(80),
operation VARCHAR2(30),
options VARCHAR2(30),
object_node VARCHAR2(128),
object_owner VARCHAR2(30),
object_name VARCHAR2(30),
object_instance NUMBER(38),
object_type VARCHAR2(30),
search_columns NUMBER(38),
id NUMBER(38),
parent_id NUMBER(38),
position NUMBER(38),
other LONG
)
tablespace APPS_TS_TX_DATA
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 128K
next 128K
minextents 1
maxextents unlimited
pctincrease 0
)
nologging;更新为
create table PLAN_TABLE (
statement_id varchar2(30),
plan_id number,
timestamp date,
remarks varchar2(4000),
operation varchar2(30),
options varchar2(255),
object_node varchar2(128),
object_owner varchar2(30),
object_name varchar2(30),
object_alias varchar2(65),
object_instance numeric,
object_type varchar2(30),
optimizer varchar2(255),
search_columns number,
id numeric,
parent_id numeric,
depth numeric,
position numeric,
cost numeric,
cardinality numeric,
bytes numeric,
other_tag varchar2(255),
partition_start varchar2(255),
partition_stop varchar2(255),
partition_id numeric,
other long,
distribution varchar2(30),
cpu_cost numeric,
io_cost numeric,
temp_space numeric,
access_predicates varchar2(4000),
filter_predicates varchar2(4000),
projection varchar2(4000),
time numeric,
qblock_name varchar2(30),
other_xml clob
)tablespace APPS_TS_TX_DATA
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 128K
next 128K
minextents 1
maxextents unlimited
pctincrease 0
)
nologging;
表plan_table的sql文件放在$ORACLE_HOME/rdbms/admin的utlxplan.sql里
dbms_xplan.display结果如下
Plan hash value: 3324114979
----------------------------------------------
| Id | Operation | Name |
----------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP |
| 2 | INDEX RANGE SCAN | EMP_N1 |
----------------------------------------------
(7)启用计划基准计划
启用后重复(6)
alter system set OPTIMIZER_USE_SQL_PLAN_BASELINES=true;
explain plan for
select * from emp where job='PRESIDENT';
select * from table(dbms_xplan.display(null,null,'BASIC'));
仍然得到的是索引范围扫描
我们查询SPB表

第三行显示未接受,但是执行计划仍旧走了索引,这个问题就很奇怪了,先留着。
(8)修改计划未已接受
管理员下执行
declare
report clob;
begin
report := dbms_spm.evolve_sql_plan_baseline(sql_handle => 'SYS_SQL_598f2cc79b517fc1');
dbms_output.put_line(report);
end;
或者管理员给APPS赋权,这个语句功能需要验证
GRANT ADMINISTER SQL MANAGEMENT OBJECT to apps;否者报错ORA-38171: Insufficient privileges for SQL management object operation
输出结果如下

查查SPM

ACCEPTED变为YES
(9)固定计划
固定计划优先级最高,如果多条计划基线,将性能最好的固定住。
declare
l_plans_altered PLS_INTEGER;
begin
l_plans_altered := DBMS_SPM.alter_sql_plan_baseline(sql_handle => 'SYS_SQL_598f2cc79b517fc1',
plan_name => NULL,
attribute_name => 'fixed',
attribute_value => 'YES');
end;
















 2724
2724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









