







基本概念
MYSQL8.0支持窗口函数(Window Function),也称分析函数。窗口函数与组分聚合函数类似,但是每一行数据都会生成一个结果。如果我们将mysql与pandas中的DataFrame做类比学习的话他们的对应关系如下:
- SQL分组聚合函数对应 => df.groupby([‘分组字段’])[‘目标’].agg()/apply()
- SQL开窗函数对应 => df.groupby([‘分组字段’])[‘目标’].transform()
所以以下函数:SUM/AVG/COUNT/MAX/MIN等既能做聚合函数又能做窗口函数,可称聚合窗口函数。
如果对pandas的DataFrame中agg()/apply()/transform()这三个方法比较清楚的小伙伴,下面学习开窗函数会特别简单。

窗口函数表达式
function(args)over(
partition by …
order by… [desc]
frame
)
- partition by:按照指定字段进行分区,两个分区由边界分隔,开窗函数在不同的分区内分别执行,在跨越分区边界时重新初始化。
- order by:按照指定字段进行排序,开窗函数将按照排序后的记录顺序进行编号。可以和partition
by子句配合使用,也可以单独使用。 - frame:当前分区的一个子集,用来定义子集的规则,通常用来作为滑动窗口使用。
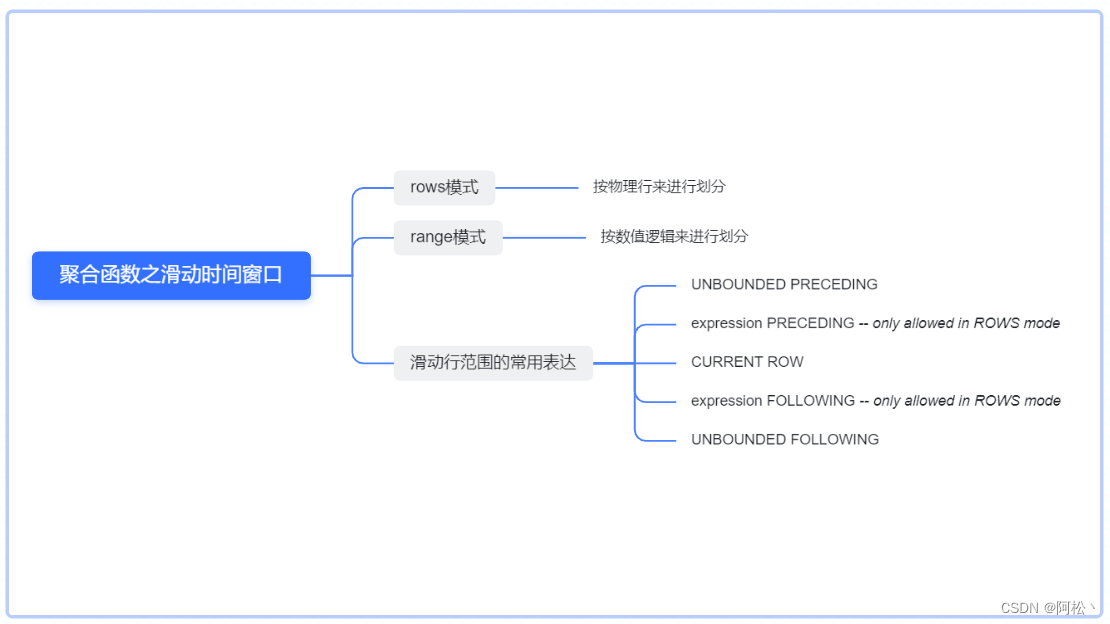
对于滑动窗口的范围指定,通常使用rows between frame_start and frame_end 语法来表示行范围,frame_start 和 frame_end 可以支持如下关键字,来确定不同的动态行记录:
- current row 边界是当前行,一般和其他范围关键字一起使用
- unbounded preceding 边界是分区中的第一行
- unbounded following 边界是分区中的最后一行
- expr preceding 边界是当前行减去expr的值
- expr following 边界是当前行加上expr的值
窗口函数之-排序函数
- row_number() :序号不重复,序号连续
- dense_rank() :序号可以重复,序号连续
- rank() :序号可以重复,序号不连续
分数排序leetcode178题 【不分组排序 】
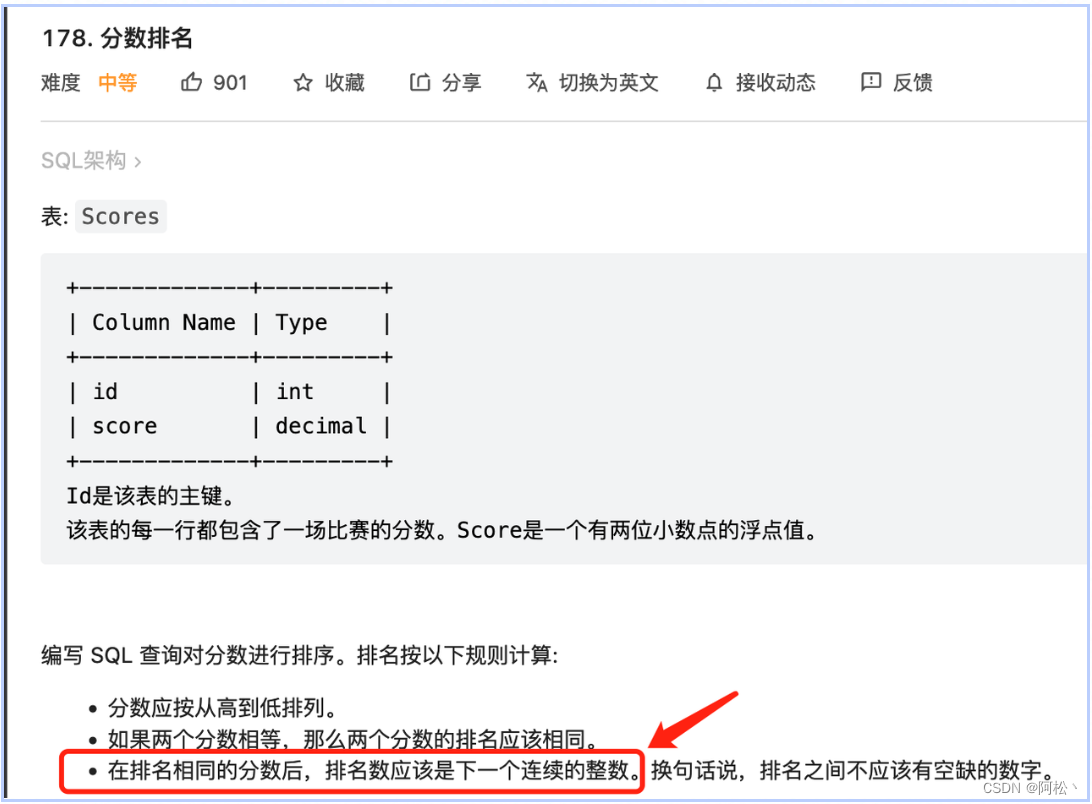
select
score,
dense_rank() over(order by score desc) as 'rank'
from
Scores
部门工资最高员工leetcode184题【分组排序】
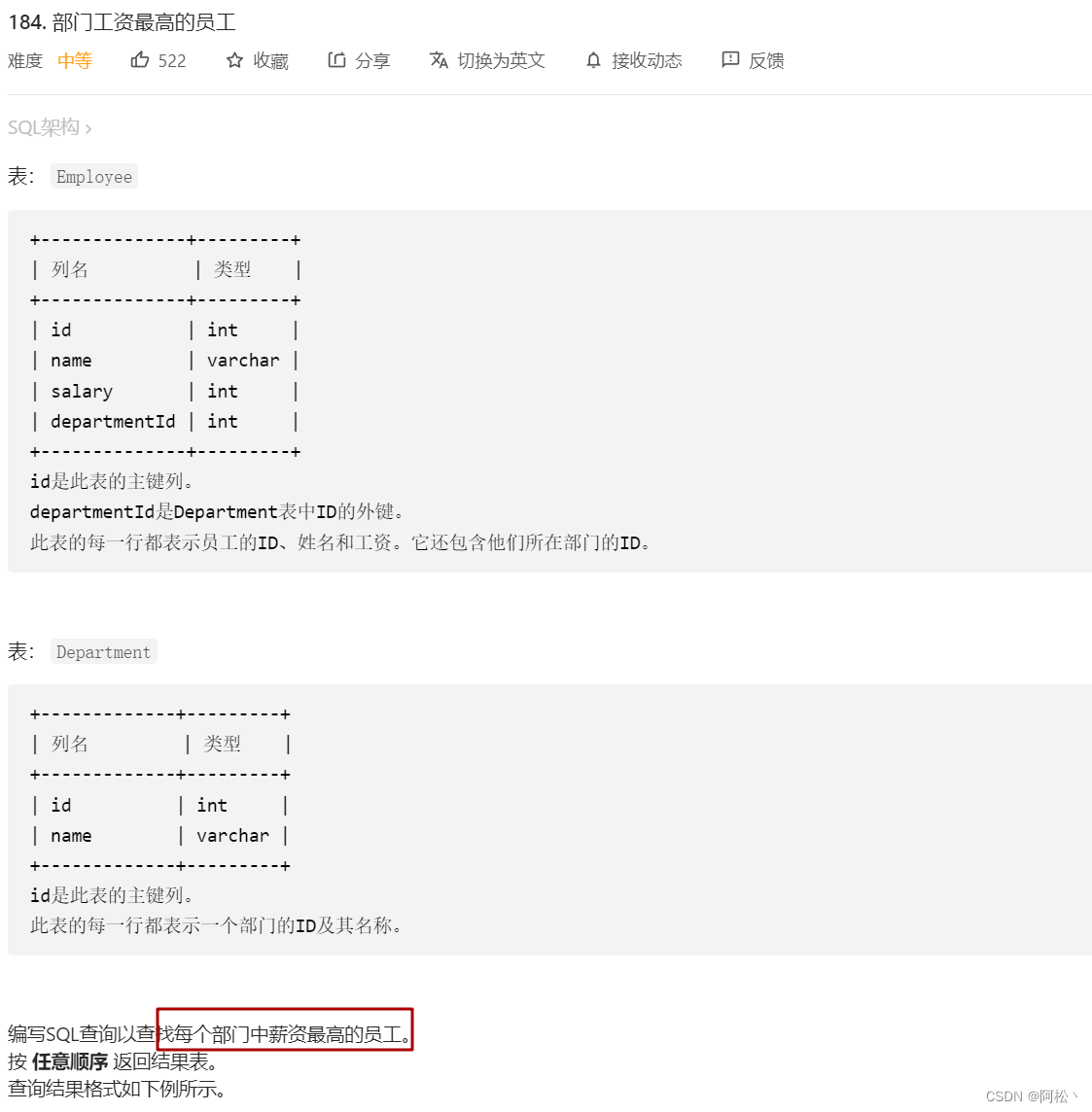
select
Department,
Employee,
Salary
from
#----------将下面看作一个表----------
(select
b.name as Department,
a.name as Employee,
Salary,
rank() over(partition by departmentID order by salary desc) as salary_rank
from
Employee a
join
Department b
on
a.departmentID = b.id) t
#----------用dense_rank()效果一样------------
where
salary_rank=1
窗口函数之-滑动窗口
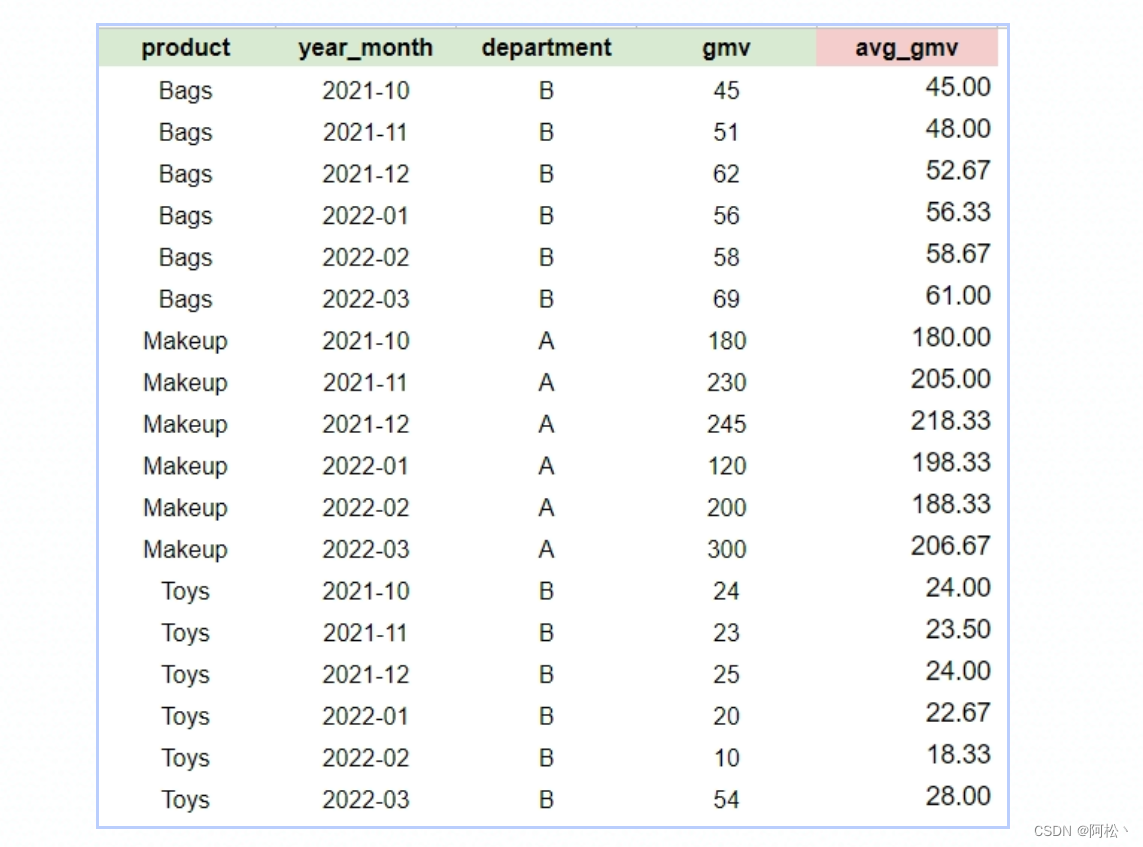
实战演练:
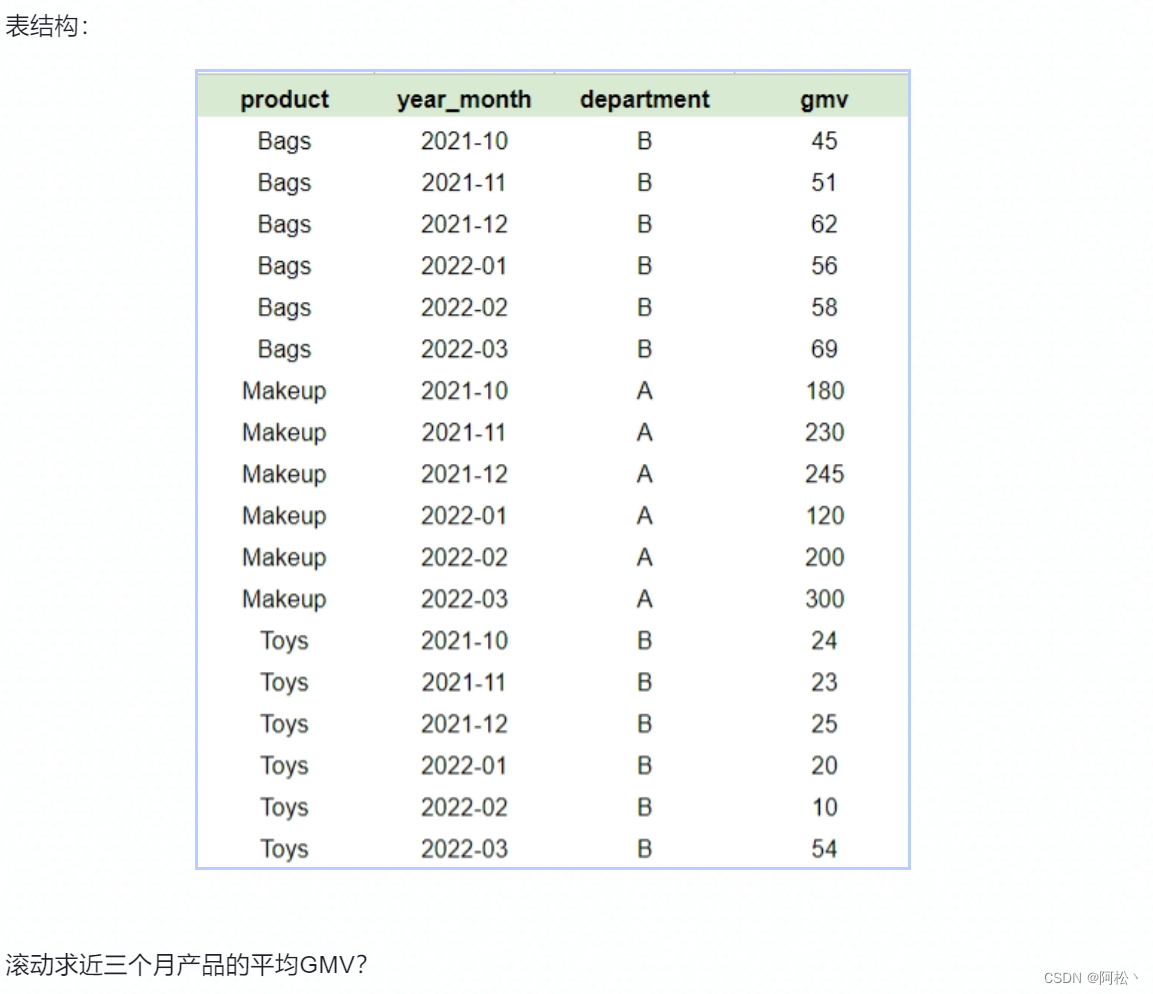
select
product,
year_month,
gmv,
avg(gmv) over (partition by department, product order by year_month rows 2 preceding) as avg_gmv
from
product
输出结果:
滚动求从上架到本月平均GMV?
select
product,
year_month,
gmv,
avg(gmv) over (partition by department, product order by year_month) as avg_gmv
from
product
等价与:
select
product,
year_month,
gmv,
avg(gmv) over (partition by department, product order by year_month rows unbounded preceding) as avg_gmv
from
product
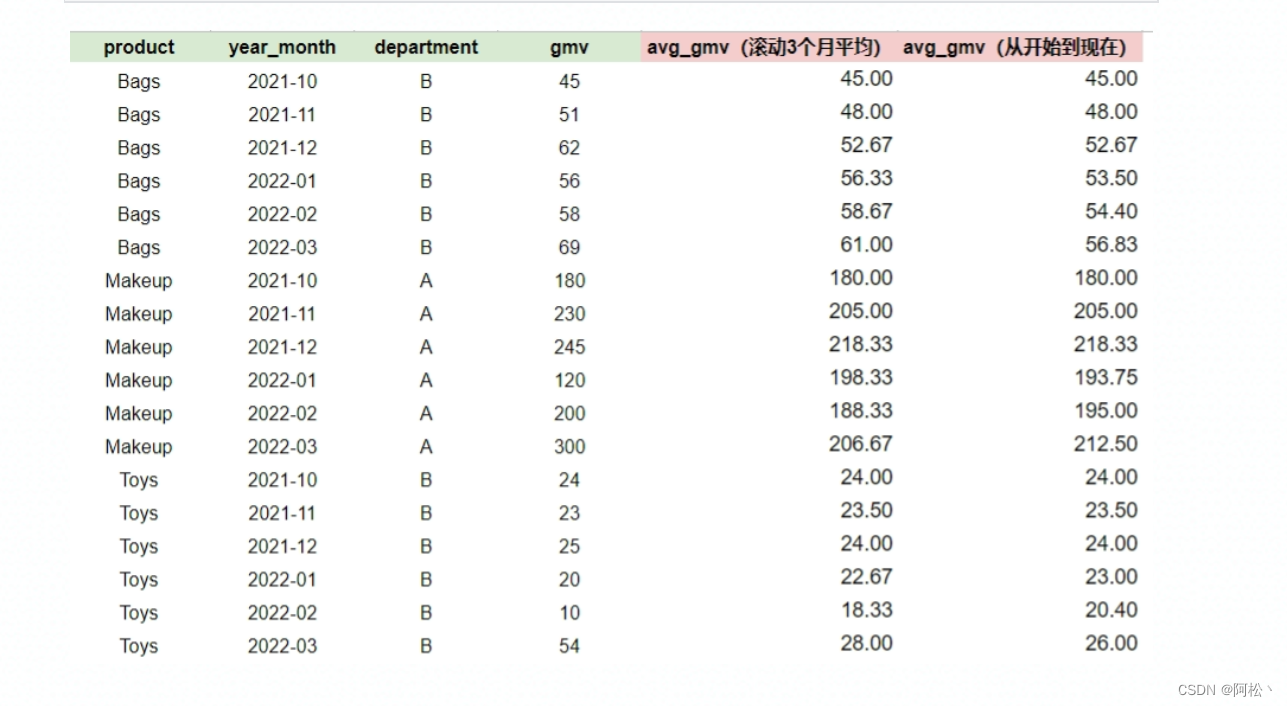
注意:若需要求组内所有数据的平均:
select
product,
year_month,
gmv,
avg(gmv) over (partition by department, product) as avg_gmv
from
product
窗口函数之-前后函数
应用:求同比增长、环比增长
- lead(expression,n):返回当前行的后n行 => shift(-n) 数据超前n阶,与之对齐的就是后n行的数据
- lag(expression,n):返回当前行的前n行=> shift(n)数据滞后n阶,与之对齐的就是前n行的数据
参数解析:
expression:作用的字段
n:阶数
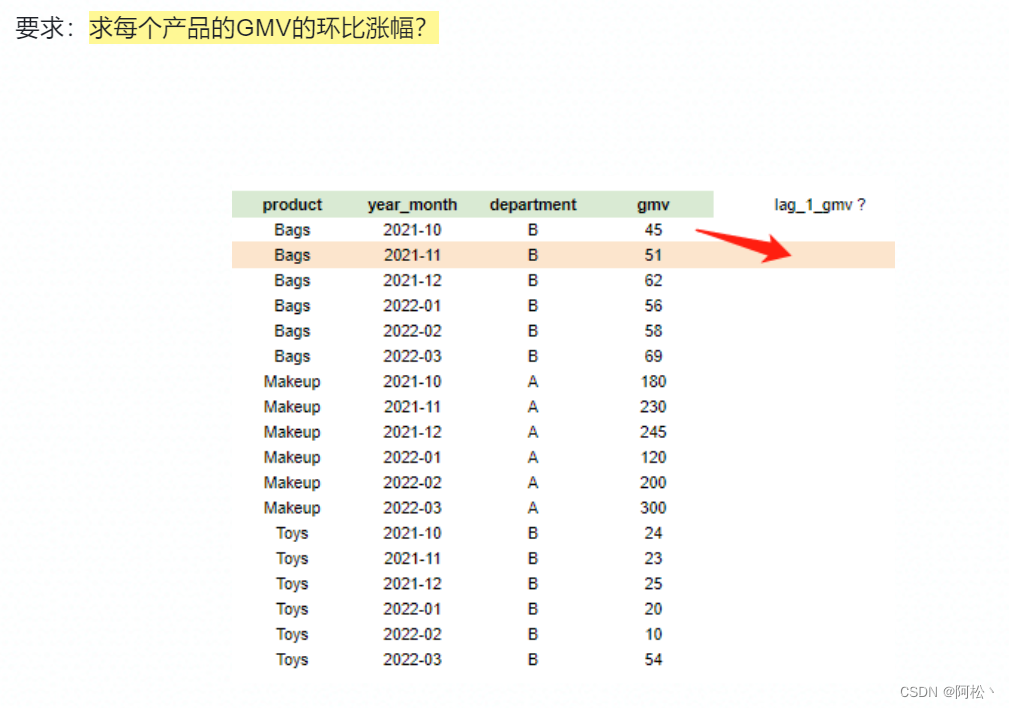
select
product,
year_month,
department,
gmv,
lag(gmv,1) over (partition by department, product order by year_month) as lag_gmv,
cast(gmv as double) / lag(gmv,1) over (partition by department, product order by year_month) - 1 as growth_rate
from product
简化写法:
select
product,
year_month,
department,
gmv,
lag(gmv,1) over w as lag_gmv,
cast(gmv as double) / lag(gmv,1) over w - 1 as growth_rate
from product
WINDOW w as (partition by department, product order by year_month)
注意:cast(gmv as double)是将gmv转化为double类型。

问题:
日期不连续怎么办?
可以通过join万年历解决。
窗口函数求top 10%
- percent_rank():公式 =(分组内当前的rank值-1)/(分组内总行数-1)
- cume_dist():公式 =(分组内当前的rank值 )/( 分组内总行数)
对求解出的结果做限制result<=0.1即可得到前10%
- ntile(n)
功能:(相当于排序后分桶 / 百分位分桶)
将排序分区划分特定数量的组;对应每一行,ntile(n)函数返回一个桶号,表示当前行所属的组。
求top10%:去ntile(n)中的n=10分桶后得到组号为1的即为前10%。

















 4963
4963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











