







第四章 用亲和性分析方法推荐电影
基于《python数据挖掘入门与实践》这一书的学习笔记,其中数据集和源码可以去图灵社区下载。
一、Apriori算法
Apriori算法是一种用于关联规则挖掘(Association rule mining)的代表性算法,关联规则挖掘是数据挖掘中的一个非常重要的研究方向,也是一个由来已久的话题,它的主要任务就是设法发现事物之间的内在联系。
两个知识点:关联规则和频繁项集
关联规则第一章已经有相关介绍,主要涉及到支持度和置信度的概念。
项集是项的集合。包含K个项的集合就是K项集。如果项集的相对支持度满足预定义的最小支持度阈值,则是频繁项集。
关联规则挖掘任务分解为如下两个主要的子任务:
1.频繁项集产生:其目标是发现满足最小支持度阈值的所有项集,这些项集称作频繁项集(frequent itemset)。
2.规则的产生:其目标是从上一步发现的频繁项集中提取所有高置信度的规则,这些规则称作强规则(strong rule)。
二、算法实现
1、数据集
import pandas as pd
ratings_filename = "ml-100k/u.data"
all_ratings = pd.read_csv(ratings_filename, delimiter="\t", header=None, names = ["UserID", "MovieID", "Rating", "Datetime"])
all_ratings["Datetime"] = pd.to_datetime(all_ratings['Datetime'],unit='s')#时间格式转换
all_ratings[:5]

很显然矩阵是稀疏的,不是每个人都会对其中的电影进行打分。数据集中有1000名用户和1700部电影。
2、实现
那么怎么判断用户是否喜欢某一部电影呢?当一个用户对该电影评分大于3分(满分为5分)时,表示喜欢。
# 创建一个新特征Favorable
all_ratings["Favorable"] = all_ratings["Rating"] > 3
all_ratings[10:15]

# 取前面200个用户的数据
ratings = all_ratings[all_ratings['UserID'].isin(range(200))]
# 选择用户喜欢的电影
favorable_ratings = ratings[ratings["Favorable"]]
favorable_ratings[:5]
# 给用户分组,以确定各个用户喜欢哪些电影
#字典中k:userId,v:电影集合 favorable_ratings.groupby("UserID")["MovieID"]为series
favorable_reviews_by_users = dict((k, frozenset(v.values)) for k, v in favorable_ratings.groupby("UserID")["MovieID"])#frozenset不可变
# 统计每部电影的喜欢程度
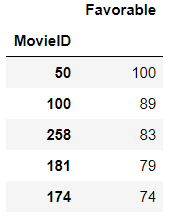
num_favorable_by_movie = ratings[["MovieID", "Favorable"]].groupby("MovieID").sum()
num_favorable_by_movie.sort_values("Favorable", ascending=False)[:5]#最受欢迎的五部电影
#画出过程图就能明白了
from collections import defaultdict
#定义一个函数,实现算法第二、三步:用现有的频繁项集生成备选集,判断是否频繁
def find_frequent_itemsets(favorable_reviews_by_users, k_1_itemsets, min_support):#输入:用户喜欢的电影(字典),初代频繁项集,支持度
counts = defaultdict(int)
#遍历用户和他们打分的数据(喜欢的电影)
for user, reviews in favorable_reviews_by_users.items():
#遍历项集,判断他们是否是当前评分项集的子集
for itemset in k_1_itemsets: #itemset为电影ID集合
if itemset.issubset(reviews): #如果是子集,则表明用户喜欢的列表里已经存在了
for other_reviewed_movie in reviews - itemset:#遍历那些非子集(打过分却没有出现在项集里的电影)
current_superset = itemset | frozenset((other_reviewed_movie,))#取并集
counts[current_superset] += 1 #键:集合 值:计数(支持度)
return dict([(itemset, frequency) for itemset, frequency in counts.items() if frequency >= min_support])
import sys
frequent_itemsets = {} # 键:项集长度 值:频繁项集(字典结构,键:包含电影ID的集合,值:支持度)
min_support = 50 #预设最小支持度
# k=1,项集长度为1,算法第一步,为每一部电影生成只包含自己的项集,判断是否频繁
frequent_itemsets[1] = dict((frozenset((movie_id,)), row["Favorable"])
for movie_id, row in num_favorable_by_movie.iterrows()
if row["Favorable"] > min_support)
print("有{}部电影超过{}支持度".format(len(frequent_itemsets[1]), min_support))
sys.stdout.flush()
for k in range(2, 20):
cur_frequent_itemsets = find_frequent_itemsets(favorable_reviews_by_users, frequent_itemsets[k-1],
min_support)
if len(cur_frequent_itemsets) == 0:
print("没有找到新的频繁项集长度为{}的集合".format(k))
sys.stdout.flush()
break
else:
print("找到了繁项集{}长度为{}".format(len(cur_frequent_itemsets), k))
#print(cur_frequent_itemsets)
sys.stdout.flush()
frequent_itemsets[k] = cur_frequent_itemsets
del frequent_itemsets[1]
print("一共{0}个频繁项集".format(sum(len(itemsets) for itemsets in frequent_itemsets.values())))
有16部电影超过50支持度
找到了繁项集93长度为2
找到了繁项集295长度为3
找到了繁项集593长度为4
找到了繁项集785长度为5
找到了繁项集677长度为6
找到了繁项集373长度为7
找到了繁项集126长度为8
找到了繁项集24长度为9
找到了繁项集2长度为10
没有找到新的频繁项集长度为11的集合
一共2968个频繁项集
三、抽取关联规则
频繁项集是一组达到最小支持度的项目,而关联规则由前提和结论组成。
规则:如果用户喜欢前提中的所有电影,那么他们也会喜欢结论中的电影。
# 每个项集生成一个规则
candidate_rules = []
#遍历不同长度的频繁项集,为每个项集生成规则
for itemset_length, itemset_counts in frequent_itemsets.items():
for itemset in itemset_counts.keys():
#遍历频繁项集中的每一部电影,把它作为结论。项集中的其他电影作为前提,用前提和结论组成备选规则。
for conclusion in itemset:
premise = itemset - set((conclusion,))#前提
candidate_rules.append((premise, conclusion))
print("一共有{}个备选规则 ".format(len(candidate_rules)))
一共有15285个备选规则
# 用两个字典,存储规则应验(正例)和规则不适用(反例)的次数
correct_counts = defaultdict(int)
incorrect_counts = defaultdict(int)
for user, reviews in favorable_reviews_by_users.items():
for candidate_rule in candidate_rules:#遍历每条规则
premise, conclusion = candidate_rule
if premise.issubset(reviews): #前提对用户是否适应
if conclusion in reviews: #结论对用户是否适应
correct_counts[candidate_rule] += 1
else:
incorrect_counts[candidate_rule] += 1
rule_confidence = {candidate_rule: correct_counts[candidate_rule] / float(correct_counts[candidate_rule] + incorrect_counts[candidate_rule])
for candidate_rule in candidate_rules}
# 最小置信度
min_confidence = 0.9
# 挑出置信度大于0.9的置信度
rule_confidence = {rule: confidence for rule, confidence in rule_confidence.items() if confidence > min_confidence}
#置信度字典排序
from operator import itemgetter
sorted_confidence = sorted(rule_confidence.items(), key=itemgetter(1), reverse=True)
for index in range(5):
print("规则 #{0}".format(index + 1))
(premise, conclusion) = sorted_confidence[index][0]
print("规则: 如果一个人喜欢{0},也会喜欢{1}".format(premise, conclusion))
print(" - 置信度: {0:.3f}".format(rule_confidence[(premise, conclusion)]))
print("")
规则 #1
规则: 如果一个人喜欢frozenset({98, 181}),也会喜欢50
- 置信度: 1.000
规则 #2
规则: 如果一个人喜欢frozenset({172, 79}),也会喜欢174
- 置信度: 1.000
规则 #3
规则: 如果一个人喜欢frozenset({258, 172}),也会喜欢174
- 置信度: 1.000
规则 #4
规则: 如果一个人喜欢frozenset({1, 181, 7}),也会喜欢50
- 置信度: 1.000
规则 #5
规则: 如果一个人喜欢frozenset({1, 172, 7}),也会喜欢174
- 置信度: 1.000















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









