








(1)IDEA 编写代码
批处理WordCount
package com.vip.wc
import org.apache.flink.api.scala._
// 批处理代码
object WordCount {
def main(args: Array[String]): Unit = {
// 创建一个批处理的执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 从文件中读取数据
val inputPath = "F:\\BigData\\Flink\\src\\main\\resources\\hello.txt"
val inputDataSet = env.readTextFile(inputPath)
// 分词之后做count
val wordCountDataSet = inputDataSet.flatMap(_.split(" "))
.map( (_, 1) )
.groupBy(0) //对第0个进行group
.sum(1) //对第一个进行求和
// 打印输出
wordCountDataSet.print()
}
}
流处理
package com.vip.wc
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 从传入参数中获取端口
val params = ParameterTool.fromArgs(args)
val host: String = params.get("host")
val port: Int = params.getInt("port")
// 创建一个流处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 接收socket数据流
val textDataStream = env.socketTextStream(host, port)
// 逐一读取数据,分词之后进行wordcount
val wordCountDataStream = textDataStream.flatMap(_.split("\\s"))
.filter(_.nonEmpty)
.map( (_, 1) )
.keyBy(0)
.sum(1)
// 打印输出 .setParallelism(1)为并行执行的线程数
wordCountDataStream.print().setParallelism(1)
// 执行任务
env.execute("stream word count")
}
}
配置参数:


然后在linux系统,启动一个7777端口
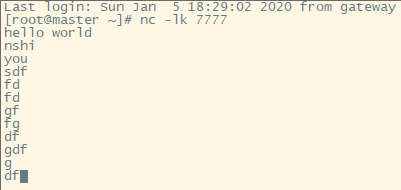
运行结果
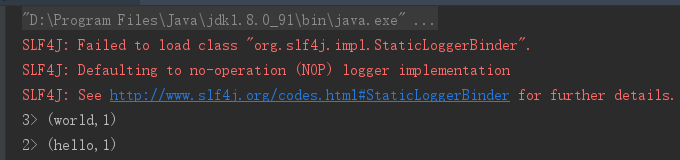

2> 这些数字代表本地并行执行的线程,默认并行度为4。
可以通过 wordCountDataStream.print().setParallelism(1)
设置。
(2)图形界面提交至集群的flink
下载解压flink压缩包即可
在flink-l.7.2 输入:./bin/start-cluster.sh
在Windows浏览:http://192.168.142.100:8081

将上诉写的代码进行打包


完成后查看运行结果

在centos中 继续输入单词
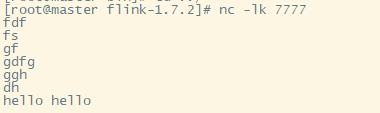
查看结果

(2)命令行提交提交
修改
taskmanager.numberOfTaskSlots: 3
taskmanager.numberOfTaskSlots为并发执行能力
[root@master flink-1.7.2]# ./bin/flink run -c com.vip.wc.StreamWordCount -p 2 /home/hadoop/flink-1.7.2/jars/Flink_Test-1.0-SNAPSHOT-jar-with-dependencies.jar --host 192.168.142.100 --port 7777















 4554
4554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









