JVM DVM
JVM:java虚拟机,主要用于PC、服务器端(PCU性能好,内存大)
DVM:dalvik虚拟机,主要用于对硬件没有那么高要求的客户端
转自:http://blog.csdn.net/x356982611/article/details/21983267
Dalvik VM (DVM) 与Java VM (JVM)的区别
Dalvik虚拟机是Google等厂商合作开发的Android移动设备平台的核心组成部分之一。它可以支持已转换为.dex(即Dalvik Executable)格式的Java应用程序的运行,.dex格式是专为Dalvik设计的一种压缩格式,适合内存和处理器速度有限的系统。(dx 是一套工具,可以将 Java .class 转换成 .dex 格式. 一个dex档通常会有多个.class。由于dex有时必须进行最佳化,会使档案大小增加1-4倍,以ODEX结尾。)
1、Dalvik 和标准 Java 虚拟机(JVM)的首要差别
Dalvik 基于寄存器,而 JVM 基于栈。基于寄存器的虚拟机对于更大的程序来说,在它们编译的时候,花费的时间更短。 JVM字节码中,局部变量会被放入局部变量表中,继而被压入堆栈供操作码进行运算,当然JVM也可以只使用堆栈而不显式地将局部变量存入变量表中。Dalvik字节码中,局部变量会被赋给65536个可用的寄存器中的任何一个,Dalvik指令直接操作这些寄存器,而不是访问堆栈中的元素。
2、Dalvik 和 Java 字节码的区别
VM字节码由.class文件组成,每个文件一个class。JVM在运行的时候为每一个类装载字节码。相反的,Dalvik程序只包含一个.dex文件,这个文件包含了程序中所有的类。Java编译器创建了JVM字节码之后,Dalvik的dx编译器删除.class文件,重新把它们编译成Dalvik字节码,然后把它们写进一个.dex文件中。这个过程包括翻译、重构、解释程序的基本元素(常量池、类定义、数据段)。常量池描述了所有的常量,包括引用、方法名、数值常量等。类定义包括了访问标志、类名等基本信息。数据段中包含各种被VM执行的函数代码以及类和函数的相关信息(例如DVM所需要的寄存器数量、局部变量表、操作数堆栈大小),还有实例变量。
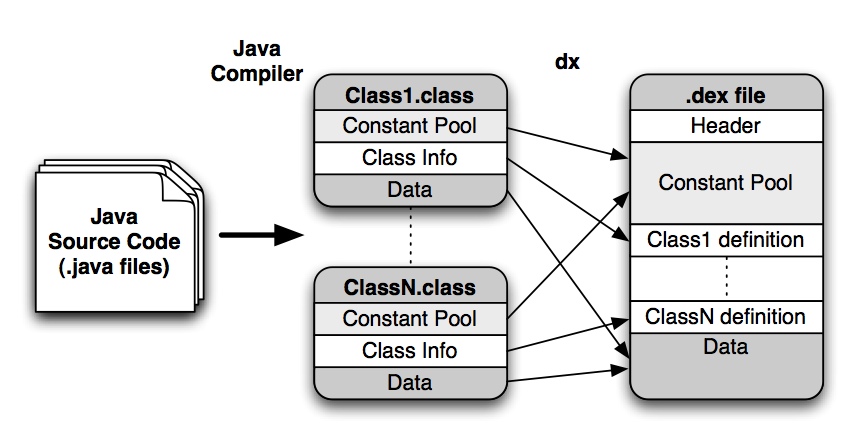
3、Dalvik 和 Java SDK的SDK不同。
4、Dalvik 和 Java 运行环境的区别
Dalvik 经过优化,允许在有限的内存中同时运行多个虚拟机的实例,并且每一个Dalvik 应用作为一个独立的Linux 进程执行。独立的进程可以防止在虚拟机崩溃的时候所有程序都被关闭。
Dalvik虚拟机在android2.2之后使用JIT (Just-In-Time)技术,与传统JVM的JIT并不完全相同,
Dalvik虚拟机有自己的 bytecode,并非使用 Java bytecode。
还有以下几点:
1、Dalvik主要是完成对象生命周期管理,堆栈管理,线程管理,安全和异常管理,以及垃圾回收等等重要功能。
2、Dalvik负责进程隔离和线程管理,每一个Android应用在底层都会对应一个独立的Dalvik虚拟机实例,其代码在虚拟机的解释下得以执行。
3、不同于Java虚拟机运行java字节码,Dalvik虚拟机运行的是其专有的文件格式Dex。
4、dex文件格式可以减少整体文件尺寸,提高I/O操作的类查找速度。
5、odex是为了在运行过程中进一步提高性能,对dex文件的进一步优化。
6、所有的Android应用的线程都对应一个Linux线程,虚拟机因而可以更多的依赖操作系统的线程调度和管理机制。
7、有一个特殊的虚拟机进程Zygote,他是虚拟机实例的孵化器。它在系统启动的时候就会产生,它会完成虚拟机的初始化、库的加载、预制类库和初始化的操作。如果系统需要一个新的虚拟机实例,它会迅速复制自身,以最快的速度提供给系统。对于一些只读的系统库,所有虚拟机实例都和Zygote共享一块内存区域。
转自:http://book.51cto.com/art/201504/472751.htm
寄存器架构与栈式架构之间的区别
《Java虚拟机精讲》第8章剖析HotSpot的架构模型与执行引擎,本章笔者详细地讲解了局部变量表、操作数栈、动态链接以及方法返回值等栈帧的几个组成结构后,又为大家详细地比较了基于寄存器架构和栈式架构的虚拟机在设计和实现上的区别。本节为大家介绍寄存器架构与栈式架构之间的区别。
AD:51CTO 网+ 第十二期沙龙:大话数据之美_如何用数据驱动用户体验
8.2.2 寄存器架构与栈式架构之间的区别
在8.2节中,笔者只是简单地介绍了关于寄存器架构和栈式架构之间的区别。当然仅凭栈式架构在设计和实现上更加简单这一个理由还不足以让JVM的设计者们动心,那么笔者接下来将会从方方面面来阐述这两种架构之间的区别,让大家更加深刻地理解基于栈式架构所带来的好处和栈式架构的优点。
指令集不同
其实寄存器架构和栈式架构之间最本质的区别还是二者之间使用的指令集不同,在8.2.1节中笔者曾为大家讲解过什么是本地机器指令,指令通常由操作码和操作数两部分构成,操作码决定了指令需要执行什么样的功能,而操作数则指定了需要参与运算的操作数,以及从哪里获取操作数、将运算结果存储在哪个位置(寄存器还是栈中)等。那么根据指令操作方式的不同,我们便可以将指令划分为零地址指令、一地址指令、二地址指令和三地址指令等n地址指令,在此大家需要注意,由于n是一个自然数,因此也就意味着指令集可以是任意的n地址。在大部分情况下,基于寄存器架构的指令集往往都以一地址指令、二地址指令和三地址指为主,而基于栈式架构的指令集却是以零地址指令为主。
那么不同的地址指令之间到底存在什么区别呢?以三地址指令为例,在一个简单的二元运算操作中,三地址指令正好可以指定2个数据源和1个存储目标,这样必然能够非常灵活地将二元运算和赋值操作组合在一起。如下所示:
代码8-4 三地址指令的表示形式
- op dest, src1, src2
很明显,如果是使用三地址指令去执行一项二元运算操作的确非常灵活。相反如果使用基于栈式架构的零地址指令去执行一项二元运算时,又会如何呢?就以代码8-2为例,其中的“iadd”指令并没有任何参数,甚至连数据源都没有办法进行指定,那么零指令地址究竟有什么用呢?其实零地址指令意味着数据源和存储目标都是隐含参数,其实现就是依赖于一种被称之为栈的数据结构。首先会由“bipush”指令将数值15从byte类型转换为int类型后压入操作数栈的栈顶(对于byte、short和char类型的值在入栈之前,会被转换为int类型),当成功入栈之后,“istore_1”指令便会负责将栈顶元素出栈并存储在局部变量表中访问索引为1的Slot上。接下来再次执行“bipush”指令将数值8压入栈顶后,通过“istore_2”指令将栈顶元素出栈并存储在局部变量表中访问索引为2的Slot上。“iload_1”和“iload_2”指令会负责将局部变量表中访问索引为1和2的Slot上的数值15和8重新压入操作数栈的栈顶,紧接着“iadd”指令便会将这2个数值出栈执行加法运算后再将运算结果重新压入栈顶,“istore_3”指令会将运算结果出栈并存储在局部变量表中访问索引为3的Slot上。
既然大家都已经知道字节码文件中的指令集设计就是基于零地址指令的,那么使用零地址指令会有什么好处呢?其实零地址指令相比其他形式的指令会显得更加紧凑,因为在一个字节码文件中,除了处理2个表跳转的指令外,其他都是按照8位字节进行对齐的,操作码可以只占一个字节大小,这就意味着将会有更多的空间用于存储其他指令。因此在空间紧缺的环境中,使用零地址指令的设计将会是不错的选择。当然有利就必然会有弊,零地址指令尽管拥有良好的紧凑性,但是它完成一个操作却往往需要比二地址指令或三地址指令花费更多的出栈和入栈指令。比如在x86平台中的CPU指令集就是基于二地址指令的,如果完成一项类似的运算操作,二地址指令只需花费2条指令即可。
基于栈式架构的优点
设计和实现更简单,适用于资源受限的系统;
避开了寄存器的分配难题;
指令集更加紧凑。
如果虚拟机选用了基于栈的架构,不仅在架构的设计和实现上会更加简单,而且更适用于资源受限的系统。所谓资源受限,通常情况下大都是指一些CPU运算效率低下、内存较小的嵌入式设备(比如机顶盒、打印机等)。如果大家细心的话,在阅读本章的前面几个小节中的内容后应该会对基于栈式架构的指令执行方式非常熟悉了。简单来说,每当调用一个新方法的时候,一个与当前方法相对应的当前栈帧也就随之被创建出来,栈帧伴随着方法的调用而创建,伴随着方法的执行结束而销毁,那么每一个方法从调用到执行结束的过程,就对应着Java栈中一个栈帧从入栈到出栈的过程。并且如果是方法内部需要执行运算时,无非就是对操作数栈中的栈顶元素频繁地执行入栈和出栈操作而已。
由于基于栈式架构的零地址指令的执行方式仅仅只是对栈顶元素操作,所以在设计上根本就不需要考虑寄存器的分配问题,因此大幅度简化了虚拟机在架构设计上的复杂度。我们都知道字节码是Java程序实现跨平台运行的基石,但最终字节码指令仍然需要被装载进JVM内部由执行引擎负责将其解释/编译为对应平台上的机器指令执行,因此基于寄存器架构的JVM自然会丧失掉Java程序与生俱来的跨平台优势,这是因为在一些寄存器较少或是寄存器不规律的平台中(典型的CISC处理器的通用寄存器数量很少,例如32位的x86就只有8个32位通用寄存器(如果不算EBP和ESP那就是6个,现在一般都算上);典型的RISC处理器的各种寄存器数量多一些,例如ARM有16个32位通用寄存器,Sun的SPARC在一个寄存器窗口里则有24个通用寄存器(8 in,8 local,8 out)),仍然需要保证Java程序能够正常顺利地运行下去,这几乎是不现实的。在此大家需要注意,尽管Google公司研发的Dalvik是一款根据ARM平台而设计的基于寄存器架构实现的虚拟机,但是从严格意义上来说,Dalvik却并没有完全按照Java虚拟机规范来进行设计和实现,并且它运行的也不是传统意义上的字节码文件,而是Android平台专属的dex文件。
除了设计和实现更加简单,以及避开了寄存器的分配难题等优点外,基于栈式架构的虚拟机还有一个优点之前也已经提到过了,那就是前端编译器所生成的字节码指令相对来说更加紧凑。这是因为在基于零地址指令的字节码文件中,除了处理2个表跳转的指令外,其他都是按照8位字节进行对齐的,操作码可以只占一个字节大小,这就意味着将会有更多的空间用于存储其他指令。而基于寄存器架构的Dalvik虚拟机所执行的字节码指令内部却是采用16位双字节的方式进行设计的。
基于寄存器架构的优点
性能优秀和执行高效;
花费更少的指令去完成一项操作。
综合来看,基于栈式架构的零地址指令设计更适用于通用的虚拟机(比如HotSpot),但实际上基于寄存器架构的虚拟机性能却显得更加高效。引用RednaxelaFX在博文《虚拟机随谈一》[① 博文地址:http://rednaxelafx.iteye.com/blog/492667。]中的一段描述,尽管基于寄存器架构的虚拟机所使用的零地址指令更加紧凑,但是完成一项操作的时候必然需要花费更多的入栈和出栈指令,这同时也意味着将需要更多的指令分派(instruction dispatch)次数和内存读/写次数。由于访问内存是执行速度的一个重要瓶颈,二地址指令或三地址指令虽然每条指令占的空间较多,但总体来说可以用更少的指令去完成一项操作,指令分派与内存读/写次数相对来说也都更少。






















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









