




Elasticsearch(简称ES)是一个分布式、高扩展、实时的、RESTful风格搜索与数据分析引擎,基于Apache Lucene构建,广泛应用于大数据领域的全文检索、日志分析、实时监控等场景。
由Elastic公司开发,使用Java编写,遵循Apache License开源协议。
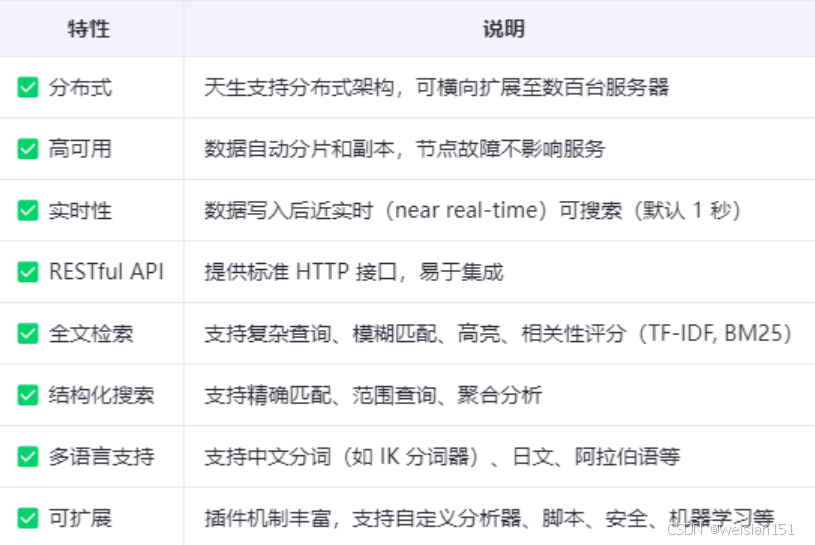
1、基本概念
1、核心特点
- 分布式搜索引擎:通过多节点集群处理海量数据,支持水平扩展。
- 实时分析系统:数据写入后几乎立即可检索和分析(近实时,NRT)。
- 文档存储:以JSON格式存储数据,每个文档是独立的可索引单元。
2、核心概念
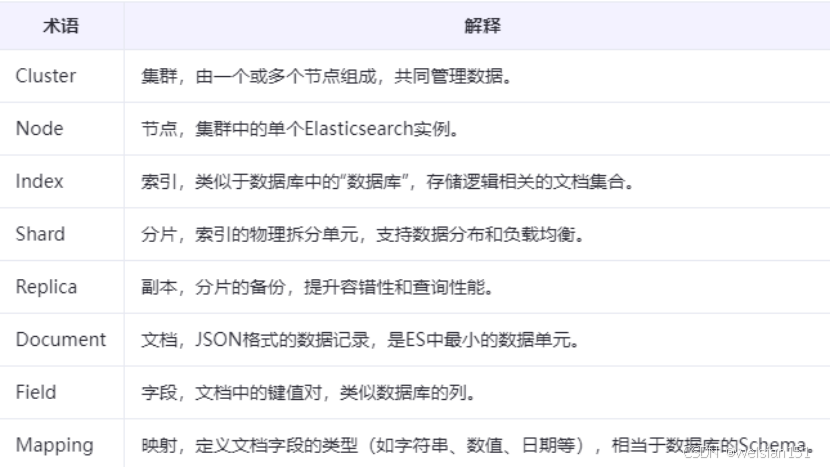
2、核心功能
1、分布式实时文件存储
- 每个字段均被索引并可搜索,支持大规模数据存储。
- 数据自动分片(Sharding)和副本(Replication),实现高可用和负载均衡。
2、全文搜索
- 基于倒排索引(Inverted Index):将文档中的关键词映射到包含该词的文档列表。
- 支持复杂查询,如模糊搜索、短语匹配、布尔查询等。
3、实时数据分析
- 提供聚合功能(Aggregation),支持统计、分组、趋势分析等。
- 例如:统计某日志系统中的错误类型分布、用户行为分析。
4、水平扩展
- 支持动态扩容,集群可扩展至数百节点,处理PB级数据。
5、多租户与安全性
- 支持多索引隔离,可为不同用户或应用分配独立索引。
- 内置权限控制(如基于角色的访问控制)、SSL/TLS加密、Kerberos认证等安全特性。
3、应用场景
1、搜索引擎
- 网站/APP搜索:如电商商品搜索、新闻检索。
- 文档检索:企业内部文档库、知识库的全文搜索。
2、日志与监控
- 日志分析:结合Logstash和Kibana(ELK Stack),实时分析服务器日志、错误追踪。
- 监控系统:收集并分析服务器指标(如CPU、内存)、网络流量,实时告警。
3、商业智能
- 用户行为分析:分析用户点击、购买行为,优化产品推荐。
- 市场趋势分析:整合多源数据(如社交媒体、销售数据),辅助决策。
4、地理信息系统
- 支持地理空间数据索引,如地图服务中的位置搜索、距离排序。
5、实时应用
- 实时推荐:根据用户实时行为动态调整推荐内容。
- 物联网数据:处理传感器实时上报的海量数据。
4、架构与原理
1、架构图
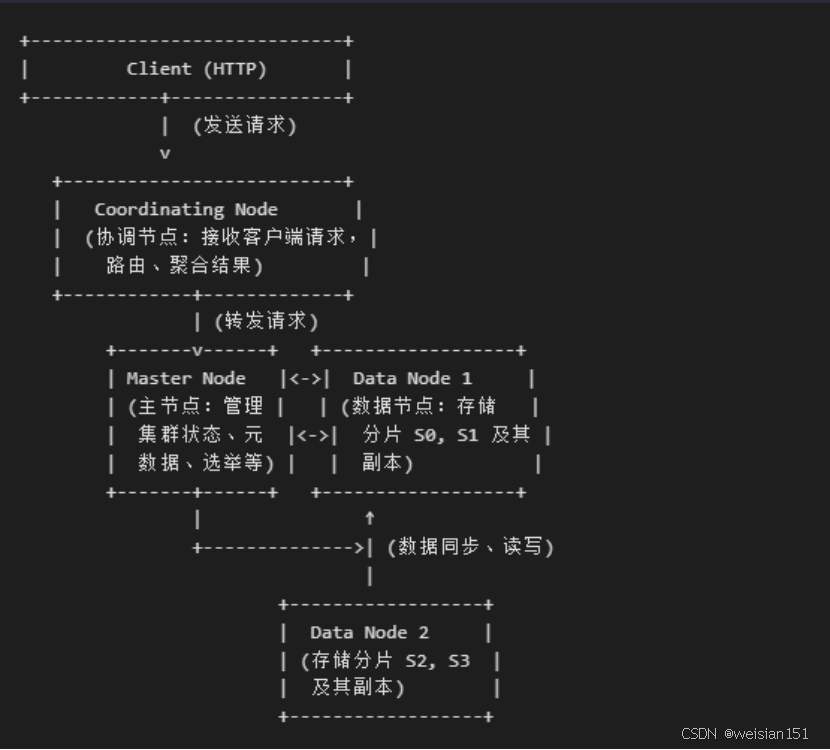
2、分布式架构
节点类型:
- 数据节点(Data Node):存储分片数据,执行CRUD(创建、读取、更新、删除)操作。
- 主节点(Master Node):管理集群元数据(如节点加入/退出、索引创建)。
- 协调节点(Client Node):接收请求并转发到目标节点,不存储数据。
节点角色说明:

分片策略:
- 主分片(Primary Shard):数据写入的起点。
- 副本分片(Replica Shard):主分片的拷贝,提供容错性和读性能。
3、倒排索引
- 原理:将文档拆分为词条(Term),建立“词条→文档列表”的映射表。
- 示例:
- 文档1:“Hello Elasticsearch” → 拆分为词条[“Hello”, “Elasticsearch”]。
- 倒排索引:
Hello → [文档1]
Elasticsearch → [文档1]
4、分布式协调
- Zen Discovery:节点自动发现机制,选举主节点并维护集群状态。
- 分片分配:通过权重算法(如索引平衡因子、分片平衡因子)动态调整分片分布。
5、数据写入流程
1、客户端发送请求到任意节点(协调节点)。
2、协调节点根据文档ID计算目标分片(分片 = hash(文档ID) % 主分片数)。
3、数据写入主分片,主分片同步到副本分片。
4、确认写入成功后返回响应。
6、数据查询流程
1、客户端发送查询请求。
2、协调节点将查询广播到所有相关分片(主分片或副本分片)。
3、各分片本地执行查询并返回结果。
4、协调节点合并结果,排序后返回最终结果。
数据流示例:(一次搜索请求)
(1)、客户端发送搜索请求 → Coordinating Node
(2)、协调节点查询集群状态(由 Master Node 管理)确定相关分片位置
(3)、请求被并行转发到包含目标分片的 Data Node 1 和 Data Node 2
(4)、数据节点执行本地搜索,返回结果给协调节点
(5)、协调节点聚合结果,返回最终响应给客户端
5、RESTFUL API使用示例
1、创建索引
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"title": { "type": "text" },
"price": { "type": "float" },
"created": { "type": "date" }
}
}
}
2、插入文档
POST /my_index/_doc/1
{
"title": "Elasticsearch 入门",
"price": 59.9,
"created": "2025-08-19"
}
3、搜索文档
GET /my_index/_search
{
"query": {
"match": {
"title": "elasticsearch"
}
}
}
4、聚合分析
GET /my_index/_search
{
"aggs": {
"avg_price": {
"avg": { "field": "price" }
}
}
}
6、优势与挑战
优势:
- 高性能:倒排索引和分布式架构支持毫秒级响应。
- 易扩展:动态扩容,支持PB级数据。
- 实时性:数据写入后1秒内可检索。
- 灵活性:支持结构化、半结构化和非结构化数据。
- 开放生态:与大数据、云原生、K8s集成良好
挑战:
- 资源消耗:内存和磁盘占用较高,需合理配置JVM参数。
- 复杂性:集群管理和调优(如分片数量、副本数)需要经验。
- 不适合事务型操作:不是数据库替代品。
- 数据一致性:默认为最终一致性,对强一致性场景需权衡。
7、使用建议
- 在生产环境中,建议将 Master Node 与 Data Node 角色分离,避免主节点负载过高导致集群不稳定。
- 合理设置分片数:避免过多分片(每个节点建议< 1000个分片)
- 使用别名(Alias):便于索引滚动更新(如logs-write, logs-read)
- 冷热架构:热节点用SSD,冷节点用HDD
- 定期清理旧数据:使用ILM(Index Lifecycle Management)
- 启用慢查询日志:定位性能瓶颈
- 备份快照:定期备份到S3、HDFS等
8、生态系统(ELK Stack)
Elasticsearch 通常与其他工具配合使用,构成 Elastic Stack(原 ELK Stack)

工作流程:
数据源(日志文件/指标数据)→ File Beats → Logstash(处理)→ Elasticsearch(存储)→ Kibana(可视化)
9、实际案例
- GitHub:使用ES索引和搜索超过800万代码仓库。
- Docker Hub:使容器镜像库可搜索。
- Netflix:实时监控和分析流媒体服务日志。
- 电商系统:商品搜索、用户行为分析、推荐系统。
10、部署与优化
部署方式:
- 本地部署:单节点或多节点集群。
- 云服务:AWS Elasticsearch Service、Azure HDInsight、华为云ES服务。
优化建议:
- 分片设计:合理设置分片数量(避免过多分片增加开销)。
- 副本策略:根据查询负载调整副本数。
- JVM调优:分配足够堆内存(通常不超过31GB)。
- 索引策略:使用时间序列索引(如日志场景),定期合并分段(Force Merge)。
11、总结
Elasticsearch以其分布式架构、实时搜索、灵活的数据模型和丰富的生态系统,成为大数据领域不可或缺的工具。无论是日志分析、搜索引擎还是实时监控,ES都能提供高效、可扩展的解决方案。然而,其复杂性和资源消耗也要求开发者具备一定的运维和调优能力。随着云原生和实时分析需求的增长,Elasticsearch的应用场景将持续扩展。Elasticsearch是当前最流行的分布式搜索与分析引擎,特别适合:需要快速搜索 + 复杂分析 + 实时响应的场景。结合Kibana可视化,Beats/Logstash数据采集,构成了强大的可观测性平台(Observability)和搜索平台。
向阳前行,Dare To Be!!!

















 9338
9338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









