




 本文介绍了如何使用Python3爬取百度图片搜索的动态加载图片。在JavaScript渲染后,通过抓包发现acjson请求,该请求包含图片URL信息。随着滚动条的移动,页面以30张图片为单位加载新的JSON数据。通过分析请求参数,特别是pn字段的递增规律,可以实现完整图片的爬取。然而,这种方法只能获取到小图,要获取全尺寸图片还需进一步处理。
本文介绍了如何使用Python3爬取百度图片搜索的动态加载图片。在JavaScript渲染后,通过抓包发现acjson请求,该请求包含图片URL信息。随着滚动条的移动,页面以30张图片为单位加载新的JSON数据。通过分析请求参数,特别是pn字段的递增规律,可以实现完整图片的爬取。然而,这种方法只能获取到小图,要获取全尺寸图片还需进一步处理。
百度图片的网页是一个动态页面,它的网页原始数据是没有图片的,通过运行 JavaScript ,把图片数据插入到网页的 html 标签里,所以在原始数据里是没有图片的,它只在运行时加载和渲染,得通过抓包的方式来爬取。
打开百度图片搜索 吉娃娃 关键字,然后 F12 打开开发者工具 Network -> XHR -> Preview ,向下滑动滚动条到一定程度时会出现 acjson?tn=resultijson_com$ipn=rj$ct=20132659..... 这样的请求,这是条 json 数据,点开 data ,可以看到里面有 0-29 ,共 30 条数据,每一条都对应一张图片。
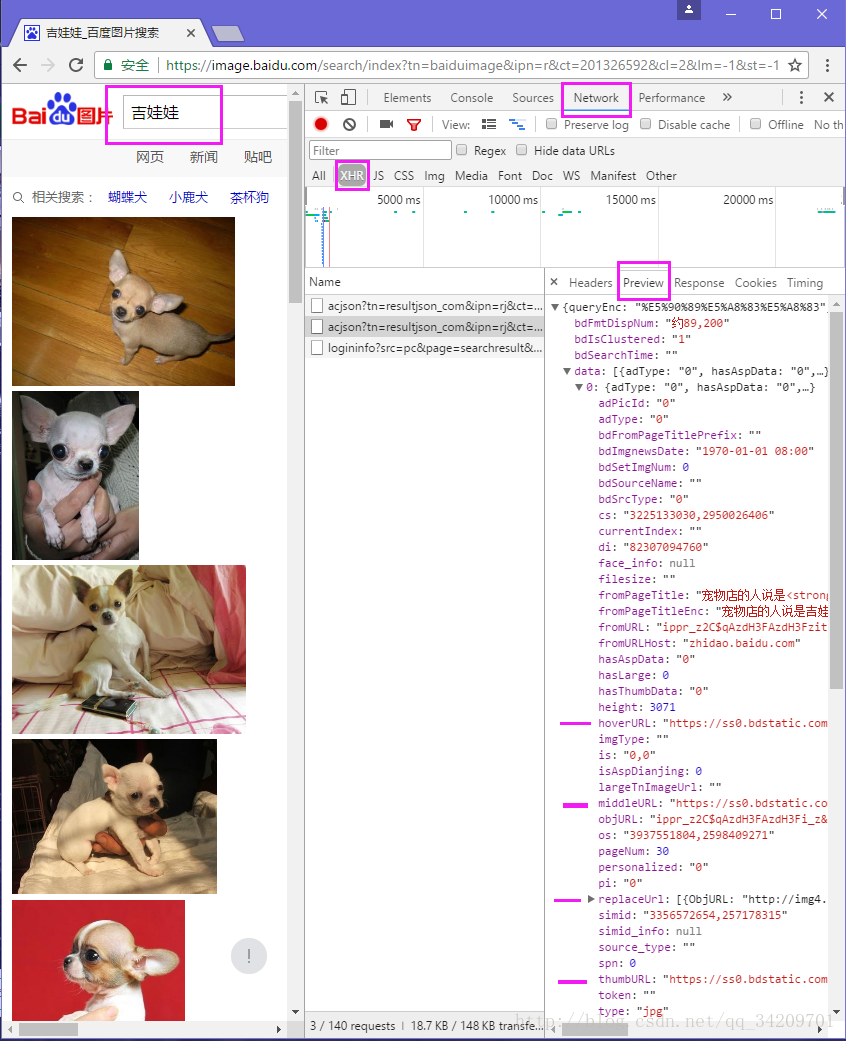
百度图片刚开始只加载了 30 张图片,滑动滚动条时,页面会动态加载 1 条 json 数据,每条 json 数据里面包含了30 条信息,信息里面包含了图片的 URL ,JavaScript 会将这些 URL 解析并显示出来。滚动条滚动到底时重复这一操作。
观察 Headers 下 Query String Parameters 里的 pn 字段,第一条 json 数据为 30 ,第二条 json 数据为 60 ,它是以 30 为步长递增。再看 queryWord 和 word ,这两个就是前面输入的关键字。其它的字段都保持不变的状态。不过最后一行是什么鬼?乱入。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











