







计算机的在cpu的发展主要是分为两个方向
1.多核,利用多线程或者多进程来并行加速。
2.批处理,在单核领域通过单指令对多数据同时进行操作来提升效率,其具体表现为如今的SIMD指令。
本文主要讲解一下第二种提升性能的方向,如何在C/C++里使用SIMD优化代码。
选择机器支持的指令
我们首先查看一下机器支持哪些指令集。
linux:cat /proc/cpuinfo |grep flags
mac: sysctl -a | grep machdep.cpu.features
从时间发展来看,SIMD指令主要经过MMX(64位)->SSE(128位)->AVX(256位)->AVX512(512位)。
如今一些比较新的机型都是支持AVX512操作,本人的电脑环境还不支持AVX512,所以退而求其次,后面的代码全部都基于AVX2.0来写的。
AVX2.0使用例子和性能比较
我们有几种方式去使用SIMD指令。
1.内嵌汇编语言。学习成本高,难以理解且出错几率大。但理论上性能最好。
2.使用内置的函数操作。学习成本较低,容易理解。理论上性能不如直接内嵌汇编。
3.使用一些封装好的向量类,比如intel的dev或者是开源的VCL。
从本人的视角看,用内置的函数操作是比较好上手学习的一种方式,所以本文主要是教大家使用Intrinsics function去写出向量化的代码。
注意
1.使用AVX2.0的内置函数需要在加编译选项-mavx2 否则编译不过。
2.部分指令需要内存地址对齐按一定位数对齐,否则会出现segment fault。(本文使用的样例里全部采用32位地址对齐)
3.以下的全部测试都没有打开编译器优化选项,因为逻辑不是很复杂,如果开了编译优化到-O2的话,下面的代码很可能两者的性能是一致的。
寄存器
i表示interger,整数类型,比如__m256i表示存的是整型256位,可以存4个64位int,或者是8个32位int都可以。
无后缀默认表示float,浮点型。比如__m256,其他同上。
d表示double,双精度浮点,比如__m256d,其他同上。
读写内存指令
_mm256_stream_load_si256:从一个内存地址load256个位的整数到寄存器。
_mm256_maskstore_epi32:将寄存器的值mask后写到目标地址。
#include <iostream>
#include <cstring>
#include <sys/time.h>
#include <string>
#include <unordered_map>
#include <list>
#include <vector>
#include <queue>
#include <functional>
#include <cstdlib>
#include <sstream>
#include <unordered_set>
#include <time.h>
#include <type_traits>
#include <cmath>
#include <algorithm>
#include <vector>
#include <array>
#include <unordered_set>
#include <string_view>
#include <chrono>
#include <immintrin.h>
__attribute__ ((aligned (32))) int a[10000005];
__attribute__ ((aligned (32))) int b[10000005];
void test_avx_speed() {
auto start_time = std::chrono::steady_clock::now();
int mask[8];
memset(mask, 0xFFFFFFFF, sizeof(mask));
__m256i mm_mask = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(mask));
for (int i = 0; i < 10000000; i += 8) {
__m256i mm_reg = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(a + i));
_mm256_maskstore_epi32(b + i, mm_mask, mm_reg);
}
// for (int i = 0; i < 16; i++) {
// printf("%d\n", b[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_avx_speed cost=%u\n", latency_ms);
}
void test_normal_speed() {
auto start_time = std::chrono::steady_clock::now();
for (int i = 0; i < 10000000; i++) {
b[i] = a[i];
}
// for (int i = 0; i < 16; i++) {
// printf("%d\n", b[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_normal_speed cost=%u\n", latency_ms);
}
void test_avx() {
int c[8] = {1, 2, 3, 4, 5, 6, 7, 8};
int mask[8];
memset(mask, 0xFFFFFFFF, sizeof(mask));
__m256i mm_mask = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(mask));
__m256i mm_reg = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(c));
int d[8];
_mm256_maskstore_epi32(d, mm_mask, mm_reg);
for (int i = 0; i < 8; i++) {
printf("%d", d[i]);
}
}
int main() {
memset(a, 0x3f, sizeof(a));
// test_avx_speed();
test_normal_speed();
}
执行结果如下:
这里简单测试了一下把a地址的值拷贝到b地址的性能。可以看到使用了AVX2.0的速度接近快了一倍。然后我又试了一下如果用c++的vector的话会怎么样。
#include <iostream>
#include <cstring>
#include <sys/time.h>
#include <string>
#include <unordered_map>
#include <list>
#include <vector>
#include <queue>
#include <functional>
#include <cstdlib>
#include <sstream>
#include <unordered_set>
#include <time.h>
#include <type_traits>
#include <cmath>
#include <algorithm>
#include <vector>
#include <array>
#include <unordered_set>
#include <string_view>
#include <chrono>
#include <immintrin.h>
// __attribute__ ((aligned (32))) int a[10000005];
// __attribute__ ((aligned (32))) int b[10000005];
void test_avx_speed() {
std::vector<int> a, b;
a.resize(10000000, 1);
auto start_time = std::chrono::steady_clock::now();
b.resize(10000000, 1);
int mask[8];
memset(mask, 0xFFFFFFFF, sizeof(mask));
__m256i mm_mask = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(mask));
for (int i = 0; i < 10000000; i += 8) {
__m256i mm_reg = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(&a[i]));
_mm256_maskstore_epi32(&b[i], mm_mask, mm_reg);
}
// for (int i = 0; i < 16; i++) {
// printf("%d\n", b[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_avx_speed cost=%u\n", latency_ms);
}
void test_normal_speed() {
std::vector<int> a, b;
a.resize(10000000, 1);
auto start_time = std::chrono::steady_clock::now();
// b.reserve(10000000);
b.resize(10000000, 0);
// for (const auto value : a) {
// b.emplace_back(value);
// }
for (int i = 0; i < 10000000; i++) {
b[i] = a[i];
}
// for (int i = 0; i < 16; i++) {
// printf("%d\n", b[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_normal_speed cost=%u\n", latency_ms);
}
void test_avx() {
int c[8] = {1, 2, 3, 4, 5, 6, 7, 8};
int mask[8];
memset(mask, 0xFFFFFFFF, sizeof(mask));
__m256i mm_mask = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(mask));
__m256i mm_reg = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(c));
int d[8];
_mm256_maskstore_epi32(d, mm_mask, mm_reg);
for (int i = 0; i < 8; i++) {
printf("%d", d[i]);
}
}
int main() {
// memset(a, 0x3f, sizeof(a));
test_avx_speed();
test_normal_speed();
}

可以看到和纯c的性能差距太多,两者本身的差距也和纯c的差距是一致的。但是目前来看如果用了vector的话可能这样优化性能提升不大。
算数运算
加法
_mm256_add_epi32:将两个寄存器的值相加,操作单位是32位的int。
#include <iostream>
#include <cstring>
#include <sys/time.h>
#include <string>
#include <unordered_map>
#include <list>
#include <vector>
#include <queue>
#include <functional>
#include <cstdlib>
#include <sstream>
#include <unordered_set>
#include <time.h>
#include <type_traits>
#include <cmath>
#include <algorithm>
#include <vector>
#include <array>
#include <unordered_set>
#include <string_view>
#include <chrono>
#include <immintrin.h>
__attribute__ ((aligned (32))) int a[10000005];
__attribute__ ((aligned (32))) int b[10000005];
__attribute__ ((aligned (32))) int c[10000005];
void test_avx_speed() {
auto start_time = std::chrono::steady_clock::now();
int mask[8];
memset(mask, 0xFFFFFFFF, sizeof(mask));
__m256i mm_mask = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(mask));
for (int i = 0; i < 10000000; i += 8) {
__m256i mm_reg1 = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(a + i));
__m256i mm_reg2 = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(b + i));
__m256i mm_reg3 = _mm256_add_epi32 (mm_reg1, mm_reg2);
_mm256_maskstore_epi32(c + i, mm_mask, mm_reg3);
}
// for (int i = 0; i < 30; i++) {
// printf("%d\n", c[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_avx_speed cost=%u\n", latency_ms);
}
void test_normal_speed() {
auto start_time = std::chrono::steady_clock::now();
for (int i = 0; i < 10000000; i++) {
c[i] = a[i] + b[i];
}
// for (int i = 0; i < 30; i++) {
// printf("%d\n", c[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_normal_speed cost=%u\n", latency_ms);
}
int main() {
// memset(a, 0x3f, sizeof(a));
for (int i = 0; i < 1000000; i++) {
a[i] = i % 10;
b[i] = i % 20;
}
test_avx_speed();
// test_normal_speed();
}

性能小部分提升。
剩下的减法,乘法,除法同上。改一下相应的算数函数即可。
_mm256_sub_epi32:将两个寄存器相减,操作单位是32位int。
_mm256_mul_epi32:将两个寄存器想乘,操作单位是32位int。
不知道是处于什么考量,我在文档里的avx2.0里没找到除法,avx里也只找到了浮点数除法。也就是看上去向量操作是没有提供整数除法的。
#include <iostream>
#include <cstring>
#include <sys/time.h>
#include <string>
#include <unordered_map>
#include <list>
#include <vector>
#include <queue>
#include <functional>
#include <cstdlib>
#include <sstream>
#include <unordered_set>
#include <time.h>
#include <type_traits>
#include <cmath>
#include <algorithm>
#include <vector>
#include <array>
#include <unordered_set>
#include <string_view>
#include <chrono>
#include <immintrin.h>
__attribute__ ((aligned (32))) int a[10000005];
__attribute__ ((aligned (32))) int b[10000005];
__attribute__ ((aligned (32))) int c[10000005];
void test_avx_speed() {
auto start_time = std::chrono::steady_clock::now();
int mask[8];
memset(mask, 0xFFFFFFFF, sizeof(mask));
__m256i mm_mask = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(mask));
for (int i = 0; i < 10000000; i += 8) {
__m256i mm_reg1 = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(a + i));
__m256i mm_reg2 = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(b + i));
__m256i mm_reg3 = _mm256_sub_epi32(mm_reg1, mm_reg2);
_mm256_maskstore_epi32(c + i, mm_mask, mm_reg3);
}
// for (int i = 0; i < 30; i++) {
// printf("%d\n", c[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_avx_speed cost=%u\n", latency_ms);
}
void test_normal_speed() {
auto start_time = std::chrono::steady_clock::now();
for (int i = 0; i < 10000000; i++) {
c[i] = a[i] - b[i];
}
// for (int i = 0; i < 30; i++) {
// printf("%d\n", c[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_normal_speed cost=%u\n", latency_ms);
}
int main() {
// memset(a, 0x3f, sizeof(a));
for (int i = 0; i < 1000000; i++) {
a[i] = i % 10;
b[i] = i % 20;
}
test_avx_speed();
// test_normal_speed();
}
比较操作
_mm256_cmpeq_epi32 :比较两个u32,相等则返回0xFFFFFFFF,否则返回0。
#include <iostream>
#include <cstring>
#include <sys/time.h>
#include <string>
#include <unordered_map>
#include <list>
#include <vector>
#include <queue>
#include <functional>
#include <cstdlib>
#include <sstream>
#include <unordered_set>
#include <time.h>
#include <type_traits>
#include <cmath>
#include <algorithm>
#include <vector>
#include <array>
#include <unordered_set>
#include <string_view>
#include <chrono>
#include <immintrin.h>
__attribute__ ((aligned (32))) int a[10000005];
__attribute__ ((aligned (32))) int b[10000005];
__attribute__ ((aligned (32))) int c[10000005];
void test_avx_speed() {
auto start_time = std::chrono::steady_clock::now();
int mask[8];
memset(mask, 0xFFFFFFFF, sizeof(mask));
__m256i mm_mask = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(mask));
for (int i = 0; i < 10000000; i += 8) {
__m256i mm_reg1 = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(a + i));
__m256i mm_reg2 = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(b + i));
// __m256i mm_reg3 = _mm256_cmpgt_epi32(mm_reg1, mm_reg2);
__m256i mm_reg3 = _mm256_cmpgt_epi32(mm_reg2, mm_reg1);
_mm256_maskstore_epi32(c + i, mm_mask, mm_reg3);
}
// for (int i = 0; i < 30; i++) {
// printf("%d\n", c[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_avx_speed cost=%u\n", latency_ms);
}
void test_normal_speed() {
auto start_time = std::chrono::steady_clock::now();
for (int i = 0; i < 10000000; i++) {
if (a[i] < b[i]) {
c[i] = 0xFFFFFFFF;
} else {
c[i] = 0;
}
}
// for (int i = 0; i < 30; i++) {
// printf("%d\n", c[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_normal_speed cost=%u\n", latency_ms);
}
int main() {
// memset(a, 0x3f, sizeof(a));
for (int i = 0; i < 1000000; i++) {
a[i] = i % 10;
b[i] = i % 20;
}
test_avx_speed();
// test_normal_speed();
}
![]()
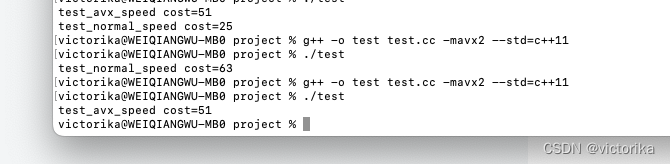
虽然结论和上面一样是会快一点,但是实际上这里可以发现,我们的normal代码其实是可以优化,比如说如果a[i] >= b[i]时我们不做赋值操作,那么效率是下面那个会更高,这里其实可以得出一个结论是说读写内存的开销远比直接操作寄存器的开销要大。
位运算
__m256i _mm256_and_si256 :&操作
__m256i _mm256_andnot_si256:!操作
__m256i _mm256_or_si256 :|操作
__m256i _mm256_xor_si256:^操作
拿个异或操作举个例子。
#include <iostream>
#include <cstring>
#include <sys/time.h>
#include <string>
#include <unordered_map>
#include <list>
#include <vector>
#include <queue>
#include <functional>
#include <cstdlib>
#include <sstream>
#include <unordered_set>
#include <time.h>
#include <type_traits>
#include <cmath>
#include <algorithm>
#include <vector>
#include <array>
#include <unordered_set>
#include <string_view>
#include <chrono>
#include <immintrin.h>
__attribute__ ((aligned (32))) int a[10000005];
__attribute__ ((aligned (32))) int b[10000005];
__attribute__ ((aligned (32))) int c[10000005];
void test_avx_speed() {
auto start_time = std::chrono::steady_clock::now();
int mask[8];
memset(mask, 0xFFFFFFFF, sizeof(mask));
__m256i mm_mask = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(mask));
for (int i = 0; i < 10000000; i += 8) {
__m256i mm_reg1 = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(a + i));
__m256i mm_reg2 = _mm256_stream_load_si256(reinterpret_cast<__m256i const*>(b + i));
__m256i mm_reg3 = _mm256_xor_si256(mm_reg1, mm_reg2);
_mm256_maskstore_epi32(c + i, mm_mask, mm_reg3);
}
// for (int i = 0; i < 30; i++) {
// printf("%d\n", c[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_avx_speed cost=%u\n", latency_ms);
}
void test_normal_speed() {
auto start_time = std::chrono::steady_clock::now();
for (int i = 0; i < 10000000; i++) {
c[i] = a[i] ^ b[i];
}
// for (int i = 0; i < 30; i++) {
// printf("%d\n", c[i]);
// }
auto end_time = std::chrono::steady_clock::now();
uint32_t latency_ms = std::chrono::duration<double, std::milli>(end_time - start_time).count();
printf("test_normal_speed cost=%u\n", latency_ms);
}
int main() {
// memset(a, 0x3f, sizeof(a));
for (int i = 0; i < 1000000; i++) {
a[i] = i % 10;
b[i] = i % 20;
}
test_avx_speed();
// test_normal_speed();
}

结论相同。
还有很多其他的指令,有需要请自行查询文档,我这里只举一些简单的例子给大家。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









