 容器与Kubernetes解析
容器与Kubernetes解析





深入理解容器镜像
Linux容器最基础的两种技术:Namespace和Cgroups
容器的本质是一种特殊的进程
Namespace的作用是”隔离“,它让应用进程只能看到该Namespace内的”世界“;
Cgroups的作用是”限制“
Docker项目最核心的原理是为待创建的用户进程:
- 启动Linux Namespace 配置
- 设置指定的Cgroups参数
- 切换进程的根目录(Change Root)
对于同一台机器上的所有容器,都共享宿主机操作系统的内核
容器相比虚拟机的主要缺陷之一:虚拟机有模拟出来的硬件机器充当沙盒
Docker在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量的rootfs,这种想法利用的是联合文件系统(union file system)所提供的能力。ufs最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。
docker存储驱动对比及适用场景:

Linux容器文件系统rootfs组成(从上到下)
可读写层
init层
只读层
可读写层:在没有写入文件之前,这个目录是空的。而一旦在容器中做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。但如果想做的操作是删除只读层里的一个文件呢?这个删除操作实际上是在可读写层创建一个名叫.wh.filename 的文件。这样,当这两个层被联合挂载之后,foo文件就会被.wh.foo.filename 的文件”遮挡“起来,”消失“了。whileout的形象翻译就是”白障“的意思,挡住了原来的文件。所以,可读写层的作用就是专门用来存放你修改rootfs后产生的增量,无论是增、删、改都放在这里。而当我们使用完了这个被修改过的可读写层,并上传到Docker Hub上,供其他人使用;而上传上去的镜像的只读层的内容不会有任何变化,这就是增量rootfs的好处。
init层: 一个以”-init“结尾的层,加载只读层和读写层之间。Init层是Docker项目单独生生成的一个内部层,用来存放/etc/hosts , /etc/resolv.conf等信息。因为用户需要在启动容器的时候写入一些指定的值比如hostname,所以就需要在可读写层对它们进行修改,可是这些修改往往只对当前的容器有效,我们并不希望执行docker commit时,把这些信息连同可读写层一起提交。
只读层:对应的是底层操作系统的5层
docker exec的实现原理:一个进程可以选择加入某个进程已有的Namespace当中,从而达到“进入”这个进程所在容器的目的。(利用系统调用setns())
使用联合文件系统,在容器里对镜像的rootfs所作的任何修改,都会被操作系统复制到这个可读写层,然后再修改。即(Copy-on-Write)
容器技术使用了rootfs机制和Mount Namespace构建除了一个同宿主机完全隔离开来的文件系统环境。
一个docker容器的全景图:
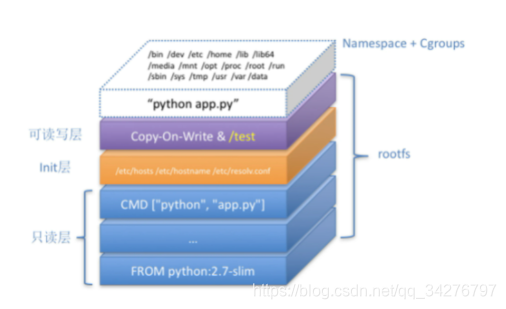
总结:容器镜像rootfs只是一个操作系统的所有文件和目录,并不包含内核,而传统的虚拟机的镜像大多是一个磁盘的快照。
Kubernetes的本质
一个“容器”实际上是一个由Linux Namespace 、Linux Cgroups和rootfs三种技术构建出来的进程的隔离环境。
一个运行的Linux容器:
- 一组联合挂载在/var/lib/docker/aufs/mnt上的rootfs,这一部分称为“容器镜像”(Container Image),是容器的静态视图;
- 一个由Namespace+Cgroups构成的隔离环境,这一部分称为“容器运行时”(Container Runtime),是容器的动态视图;
Google公开的技技术设施栈:
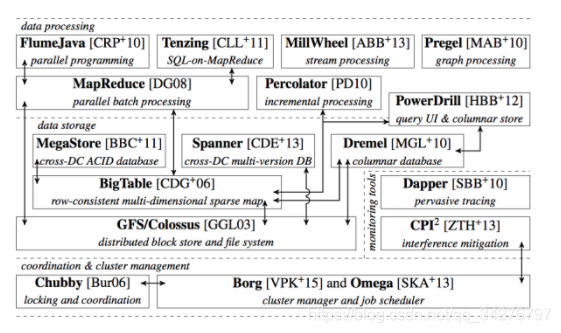
Kubernetes项目着重解决的问题是:运行在大规模集群中的各种任务之间,实际上存在各种各样的关系。这些关系的处理, 才是作业编排管理系统最困难的地方;
容器的本质只是一个进程而已
Kubernetes项目核心功能“全景图”
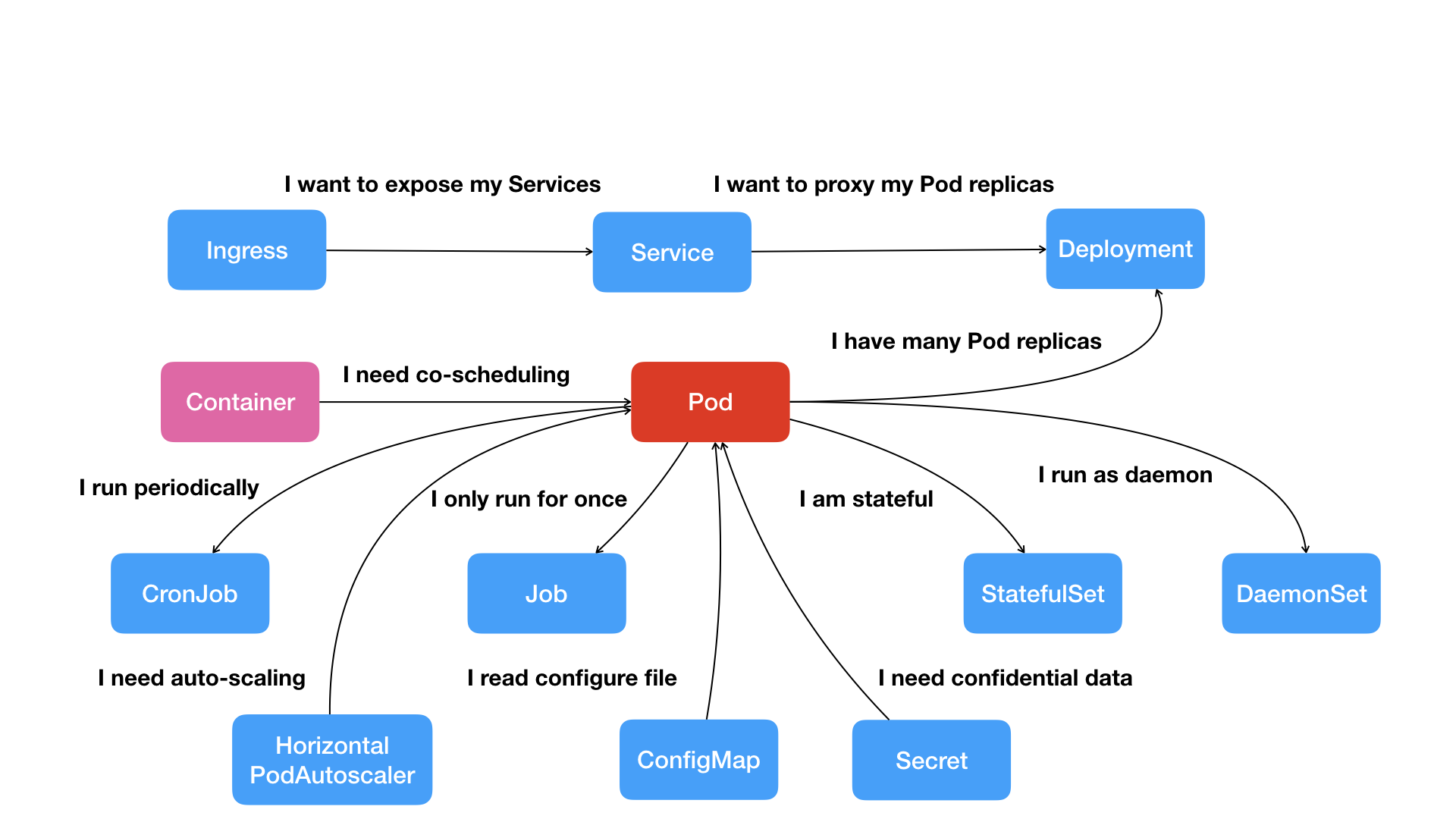
在过去的很多集群管理项目(如Yarn、Mesos、以及Swarm)所擅长的,都是把一个容器,按照某种规则,放置在某个最佳节点上运行起来。这种功能称为“调度”。
而Kubernetes所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系,这种功能就是:编排。
Kubernetes项目的本质是为用户提供一个具有普遍意义的容器编排工具;
Kubernetes真正的价值是提供了一套基于容器构建分布式系统的基础依赖。
Linux内核namespace机制:(隔离)
Linux Namespaces机制是一种资源隔离方案。PID、IPC、Network等系统资源不再是全局性的,而是属于某个特定的Namespace。每个namespace下的资源对于其他namespace下的资源是透明的,不可见的。例如使用ps命令只能列出自己namespace下的进程。这样namespace看上去就像一个单独的Linux系统。
(Namespace用于分离进程树、网络接口、挂载点以及进程间通信等资源)
Linux内核cgroups机制:(限制)
这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。简单说,cgroups可以限制、记录任务组所使用的物理资源。本质上来说,cgroups是内核附加在程序上的一系列钩子(hook),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
主要作用:
- 资源限制:cgroups可以对任务需要的资源总额进行限制。比如设定任务运行时使用的内存上限,一旦超出就发OOM。
- 优先级分配:通过分配的CPU时间片数量和磁盘IO带宽,实际上就等同于控制了任务运行的优先级。
- 资源统计:cgroups可以统计系统的资源使用量,比如CPU使用时长,内存用量等,这个功能非常适合当前云端产品按使用量计费的方式
- 任务控制:cgroups可以对任务执行挂起、恢复等操作
linux内核rootfs机制:(根文件系统)
根文件系统只是文件系统的一种特殊实现。
根文件系统首先是一个文件系统,根文件系统不仅具有普通文件系统的存储文件的功能,他还是内核启动时挂载(mount)的第一个文件系统,内核代码的映像文件保存在根文件系统中,系统引导启动程序会在根文件系统挂载后从中把一些初始化脚本(如rcs,inittab)和服务加载到内存中运行。
主要作用:
- init进程的应用程序必须运行在根文件系统上
- 根文件系统提供了根目录“ / "
- Linux挂载分区时所依赖的信息存放在根文件系统/etc/fstab这个文件中
- shell命令程序必须运行在根文件系统上,比如ls, cd等命令
总之:一套Linux体系,只有内核本身是不能工作的,必须要rootfs(比如etc中的配置文件,/bin /sbin中的命令,/lib 中的库文件)相互配合才能工作。
挂载:将一个文件系统与一个存储设备关联起来的过程;
rootfs是基于内存的文件系统,所有操作都在内存中完成,也没有实际的存储设备,所以不需要设备驱动程序的参与。基于以上原因,Linux在启动阶段使用rootfs文件系统,当磁盘驱动程序和文件系统成功加载后,Linux系统会将系统根目录从rootfs切换到磁盘文件系统。
根文件系统至少包含以下目录:
- /etc/ : 存储重要的配置文件
- /bin/:存储常用且开机时必须用到的执行文件
- /sbin/: 存储开机过程中所需的系统执行文件
- /lib/: 存储 /bin 及 /sbin 的执行文件所需的链接库,以及Linux的内核模块
- /dev: 存储设备文件
参考:
[1]. https://time.geekbang.org/column/article/17921
[2]. http://dockone.io/article/1513
[3]. http://blog.chinaunix.net/uid-20788636-id-4479145.html

















 2628
2628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









