







最近有个项目需要跨平台,项目本身是在Ubuntu下写的,而且在写代码的时候也没有考虑过要跨平台,再加上我也是第一次真正搞一个跨平台的项目,走了不少弯路,记录一下我学到的东西,希望能对别人有所帮助。
1.工具的选择
我们都知道,Qt本身是跨平台,理论上同一份代码只需要在不同平台下编译一次,就可以跑在不同的系统上。但事实上,跨平台并没有这么简单,当然,难者不会,会者不难,只要具备相关的知识,Qt跨平台也不是什么太难的问题。
所谓跨平台,一般指的是Windows和Linux下,其他OS不在我的讨论之内。
首先说明一下,Qt版本的选择问题。除了Qt的版本号外,从操作系统来说,Qt有Linux和Window之分。
在Linux下,Qt相应的安装包中没有任何编译器,因此当我们使用Qt编译的时候,实际上是使用Linux自带的C++编译器,也就是gcc和g++,有时候安装了Qt后无法编译,就是因为我们尚未安装这些编译器,因此自然无法编译项目。
举个例子,当我们在Ubuntu上安装Qt时,应该首先安装gcc和g++,然后再去安装Qt(顺序相反也可以):
sudo apt-get install build-essential libgl1-mesa-dev
chmod +x qt-opensource-linux-x64-5.7.0.run
sudo ./qt-opensource-linux-x64-5.7.0.run在Windows下,从编译器看,Qt分为两种。
一种是MingW版本,在这个版本里,编译时,使用的是Qt安装包中自带的MingW编译器,因此安装完Qt后不需要额外的设置,就可以直接使用。
另一种是MSVC版本,这个版本和Linux类似,都不会提供编译器,而是使用第三方的编译器,这里使用的就是VS的编译器,因此如果选择了这个版本,就必须安装对应的VS,如vs2015,vs2017等等,安装好VS后,Qt MSVC 版本的QtCreator就可以检测到相关的编译器,然后去编译代码。当然如果不顺利,如最常见的没有bug调试器等问题,也可以自己去设置,真遇到问题,再到网络上查询解决。
那么,Qt为什么要提供这么多的分类,为什么不包打天下,给我们一个一键傻瓜式的方式来使用它?这是有原因的。
Qt出现的时间较晚,在它之前大家都会有其他的编程方案,这么多年下来,也形成了很多固定的工具使用方式或者交流方式,比如:在Linux使用C++编程时,GCC和G++编译器必然是首选;很多第三方库,都会以VS的为工具编译动态库。这就导致了Qt如果仅提供自己的编译器(MingW编译器),那么很多网络上的第三方库将无法在Qt中使用,因为某些库不会以Qt来组织和编译。
我们都知道,一个编译器要使用动态库时,必须是相同编译器编译出来的才能使用,且位数也必须相同,即:vs无法使用MingW编译出来的动态库,反过来也一样,32位不能链接64位的动态库等等。(不懂请查询其他资料,这里不赘述)
因此,为了使用互联网上的广泛资源,必须提供不同平台,不同位数,不同编译器的诸多版本。
了解了这些之后,我们就可以选择自己的Qt版本了。在Linux下,也没什么好选择的,而在Windows下,如果仅使用Qt自己的库,那么Mingw版本也可,但如果要使用第三方库,那么建议使用MSVC版本,且VS的版本也要考虑使用那一个。
2、中文字符问题
(注:本节内容主要内容转载自 https://blog.csdn.net/e5max/article/details/80908620,由笔者添加部分内容而成)
一、问题是什么?
在学习Qt编程的过程中,大多数人都遇到过中文乱码的问题。总结起来有三类:
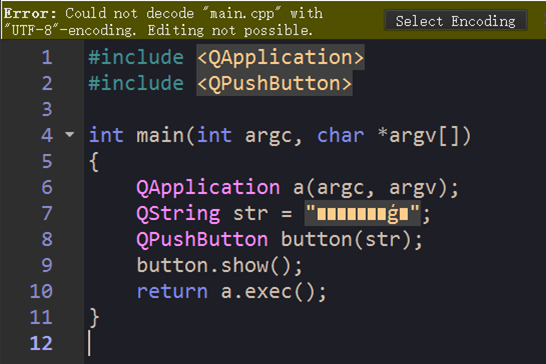
1、Qt Creator中显示的汉字变为乱码,编辑器上方有“Could not decode "..." with "UTF-8"-encoding. Editing not possible.”的错误提示。此时,出现乱码的文档是不可编辑的。如下图所示,“你好中文!”这5个中文字符变成了乱码:
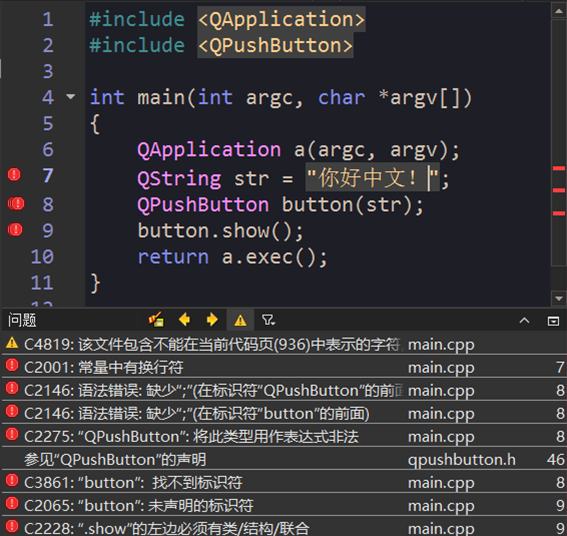
2、Qt Creator中显示的汉字正常,但编译的时候会出现“常量中有换行符”等一系列错误报警。其实,这也是文字编码的问题。如下图所示:
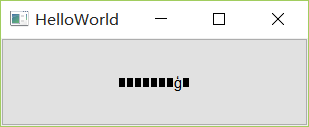
3、编译时未报错,但生成的程序中文乱码。如下图所示:
其中,第3条是网上提问的最多的,几乎是所有使用MSVC的初学者都会碰到的问题。很多回答是针对Qt4版本的,Qt5中不可用。
二、为什么会出现这些问题?
在解决问题之前,字符编码知识是必需的。你要知道ASCII、GB2312、GBK、Unicode、UTF-8、UTF-16、BOM是怎么回事。此外,你还要明白源码字符集、执行字符集是什么。详细内容可以在网上搜索一下,俯拾即是。
首先,请查询了解上面提到的诸多字符编码名词。然后查看下面我要说明的三块知识点:
1、字符在Qt中显示和处理流程示意图:
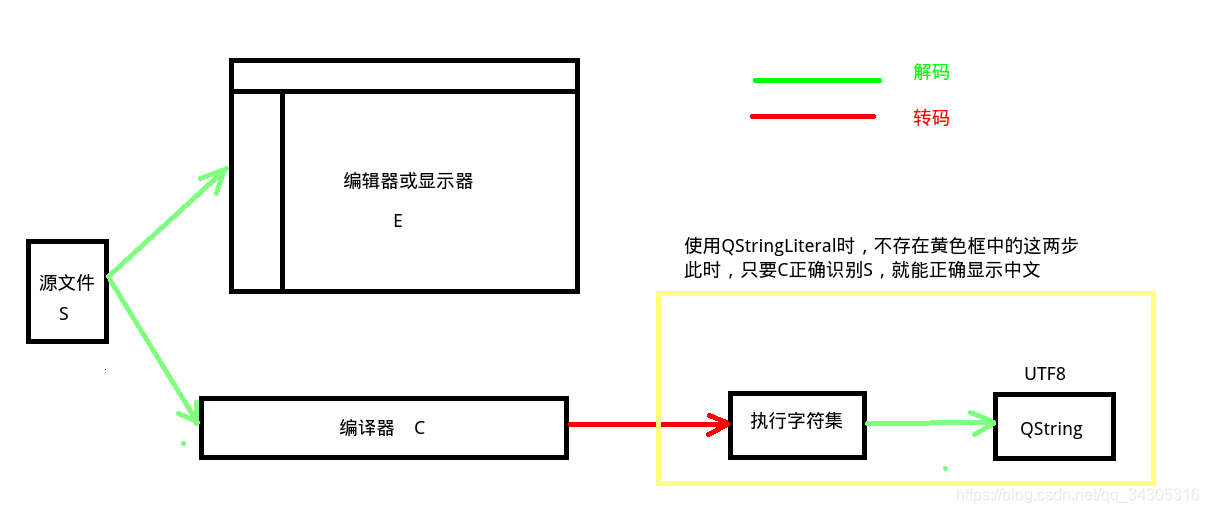
在上图中,S表示我们的代码文件的编码格式,E代表我们编辑器(这里就是QtCreator)的编码格式,C表示编译器使用的编码格式。
如果S和E一致,那么代码的显示就是正常的。但是要注意,如上图所示,显示和编译用的是不同的编码格式也就是说,Qt中代码显示正确并不代表编译器也能正确识别源文件。
如果S和C一致,那么编译器就能正确识别源代码,此时编译就不会报编码相关的错误。
但即使S和C一致,编译也成功了,但最终显示在界面上的汉字却有可能显示为乱码,这又是为什么呢?
2、执行字符集问题
当编译器识别源代码中的字符串无语法错误后(注意,仅是无语法错误,不代表识别正确),在编译时,它会将识别出来的字符串进行一个转码(如上图红色箭头所示),转码为执行字符集然后写入到我们最终生成的exe可执行文件中,因此,在运行程序时,实际使用的字符信息是经过转码得来的。
3、QString
QString这个类在Qt中表示字符串,是非常基本的类,然而基本却不代表不重要,也不代表它很简单。
QString在内部是使用UTF8来表示字符串的,这一点是不能更改的。
那么当我们需要将其他格式的字符信息在QString表示,该怎么做呢?答案是使用QString类中的fromXXX函数,如fromUTF8就表示以UTF8的格式解析传入的参数,然后将解析出来的字符转码为QString使用的格式,也就是UTF8。fromLatln1则表示以Latln1的格式解码传入的参数,然后转码为UTF8。
而在构造函数一个QString时,在底层默认调用QString::fromUTF8()。
我们也可以使用QString中的toXXX函数来完成UTF8到其他格式的转码。
有了上面2和3的知识,我们继续分析上面图片黄色方框中的部分。
红色箭头中,编译器会将识别到的字符串进行一次转码,转为相应的执行字符集,转码后的信息保存在最终生产的可执行程序中。当我们执行这个可执行程序的时候,当执行到该字符串相关的代码部分时,我们会使用它来构建生产QString对象,而由于我们在代码中可以指定QString构造时解析所使用的编码格式(即使用不同的fromXXX函数来构造QString),因此当指定的方式合适时,自然就可以正确显示中文字符。
而当我们对形如“xxx”的字符串使用QStringLitura宏时,情况又不一样了,此时黄色方框中的内容不存在。这是为什么呢?
我们在上述描述中可以知道,QString对象的构建是在运行时(at runtime),但当我们使用QStringLitura这个宏时,在编译期间,就会使用“xxx”所提供的字符信息直接生产QString内部数据,这样当程序运行时,就可以避免与QString相关的内存分配,拷贝,转码等一系列消耗,直接使用已生成的QString内部数据,这样可以提高程序的运行效率。
因此,此时黄色方框中的步骤就不存在了,此时,只要编译器可以正确识别源码,就可以正常显示字符。
以上就是所有内容,下面我们结合实际的例子,说明以上机制的运行方式,作为理解的参考。
1、Qt Creator 的编辑器默认使用UTF-8(代码页65001)编码来读取文本文件。而Visual Studio保存文件时默认采用的是本地编码,对于简体中文的 Windows操作系统,这个编码就是GB2312(代码页936)。如果使用Qt Creator读取由Visual Studio创建的文件,那么编 辑器就会以UTF-8编码格式读取GB2312编码格式的文件,出现中文乱码,因为这两套编码系统对汉字编码是不同的。至于英文部分不会乱码,是因为 UTF-8和GB2312在单字节字符部分是兼容的。
此时,S为GB2312,而E为UTF8,所以会使用UTF8去解码GB2312的文本,表现为:QtCreator中,中文字符乱码。
2、MSVC 在编译时,会根据源代码文件有无BOM来定义源码字符集。如果有BOM,则按BOM解释识别编码;如果没有,则使用本地字符集,对于简体中文的 Windows操作系统就是GB2312。那么,当MSVC遇到一个没有BOM的UTF-8编码的文件时,它通常会把文件看作GB2312的来处理。如果 文件全是英文没有问题,但如果包含中文,编译器就会出现误读。这种情况下,Qt Creator编辑器是正常的。但对于MSVC编译器,原代码会被它认识 成下图这个样子:
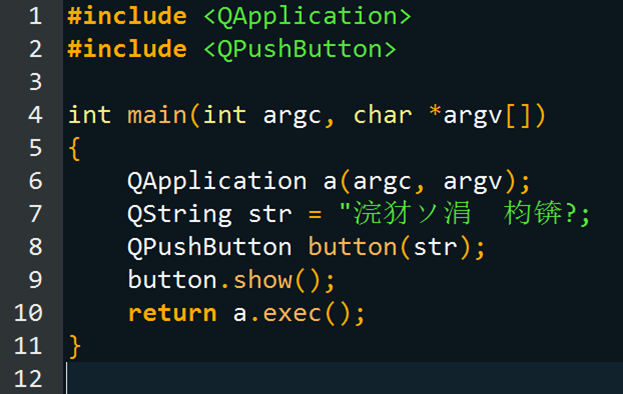
这是我用EverEdit指定本地编码重读后的结果,可以看到汉字出错,末端的引号也没了。
在 UTF-8中,一个中文字符(汉字或标点符号)占用3个字节,“你好中文!”这5个中文字符共占用15个字节;而在GB2312中,一个中文字符(汉字或 标点符号)占用2个字节,这时,MSVC把UTF-8编码的15个字节加上后面1个字节的英文引号合成16个字节当作8个中文字符处理。之后,MSVC在 这一行里直到末尾换行符出现都没有找到下一个引号,它以为你把字符串在这里敲回车换行了,于是报警称“常量中有换行符”,并引出一系列的错误。
不过,当以无BOM的UTF-8编码的字符串正好凑够偶数个字节时(比如偶数个汉字,或奇数个汉字加奇数个英文字母),编译器通常不会报警,因为它以为用GB2312编码读出的是正确的。
根据上面的描述:
1、当有BOM时,S为UTF8-BOM,E为UTF8,C为UTF8,此时,S和E相同,编辑器显示正常,S和C相同,编译器识别源码正确。
2、当无BOM时,S为UTF8,E为UTF8,C为GB2312,此时,S和E相同,编辑器显示正常,但S和C不同,因此在识别汉字部分时,就会编译报错,而报错的理由,上面描述非常详细,不再赘述。
3、不 管源文件是何种编码,只要MSVC能够正确识别,就可以通过编译。但MSVC的执行字符集默认是本地字符集。对我们来说,它生成的可执行文件中的文字是 GB2312编码的。而生成的Qt程序以UTF-8编码来识别GB2312编码的文字,对于“你好中文!”这几个字符,采用GB2312编码后再以 UFT-8编码来读取,就会变成如下的乱码:

当以无BOM的UTF-8编码的字符串正好凑够偶数个字节时(比如偶数个汉字,或奇数个汉字加奇数个英文字母),反而不会出现乱码。那是因为,编译器用GB2312编码读出的乱码本身就是UTF-8编码的,现在又用UTF-8解读,自然就正确了。这纯粹是歪打正着。
根据上面的描述:
1、当有BOM时,S为UTF8-BOM,E为UTF8,C为UTF8,此时,S和E相同,编辑器显示正常,S和C相同,编译器识别源码正确。 然后,MSVC编译器会将识别到对的字符转码为执行字符集,即GB2312,然后使用在代码中使用了fromUTF8来构造QString,即用UTF8解码GB2312字符,因此造成乱码。
2、当无BOM时,S为UTF8,E为UTF8,C为GB2312,此时,S和E相同,编辑器显示正常,但S和C不同,因此在识别汉字部分时,就会编译报错,但当汉字恰好为偶数时,编译器并不会报语法错误,此时识别出来的字符串是乱码(用GB2312解码UTF8),然后将该乱码转码为执行字符集,即GB2312(因为C使用的就是GB2312,因此这里实际上没有发生任何动作),然后使用在代码中使用了fromUTF8来构造QString,恰好歪打正着,显示反而正确了。
三、怎么解决这些问题?
首先,你要确定采用哪种源码字符集。你有两个选择:
-
采用本地编码字符集(不推荐,跨平台时会比较麻烦,但在Visual Studio环境下配合Add-in工具编程比较方便);
-
采用UTF-8编码字符集(推荐,适合跨平台)。
1 “采用本地编码字符集”方案,解决方法如下:
首先,要把项目中所有的头文件和源文件全都转换成GB2312编码保存。
-
第1个问题:在Qt Creator中打开项目,点击左侧工具栏“项目”,在“编辑器”选项卡中把“默认编码”改成“GB2312”。如下图所示:
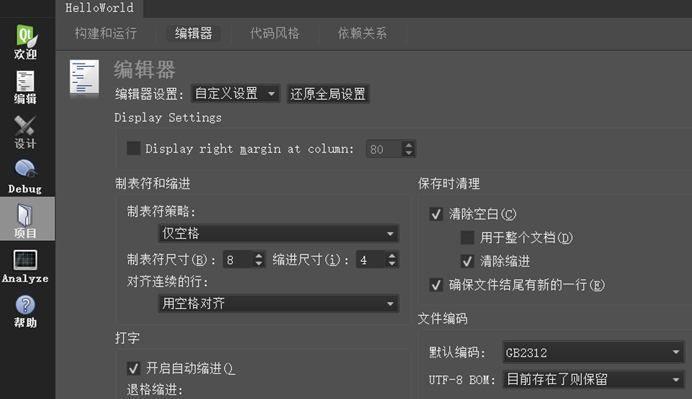
话说回来,既然选择本地字符集,大致上是放弃跨平台了。与其用轻量级的Qt Creator,不如用Visual Studio作开发环境更好。
-
第2个问题:“常量中有换行符”等一系列报警已不存在了。
-
第3个问题:在字符串常量上加QStringLiteral宏或QString::fromLocal8Bit函数,如:
QString str = "你好中文!";改为:
QString str = QStringLiteral("你好中文!");或者:
QString str = QString::fromLocal8Bit("你好中文!");不过,在这两种形式下,你都无法用tr方法来创建翻译了。
根据上面的描述:
此时,S、E、C都是GB2312,第一个和第二个问题都解决了,第三个则是因为在实际代码中使用的是fromUTF8构造QString,即用UTF8解码GB2312字符串,因此乱码。
此时,将fromUTF8改为fromLocal8Bit,即用本地字符集,也就是GB2312来解码GB2312,因此显示正确。
QStringLiteral已在上面解释。
这里说不能使用tr,是因为QStringLiteral它是在编译期间就决定了QString的内容,而tr可以进行翻译,是因为它在运行时,根据设置的翻译文件(如英文对应到中文的文件,里面包含了英文字符串到汉字字符串的映射),返回对应的字符串。
2 “采用UTF-8编码字符集”方案,解决方法如下:
首先,要把项目中所有的头文件和源文件全都转换成UTF-8+BOM编码保存。
-
第1个问题不存在了。
-
第2个问题也不存在了。
-
第3个问题,你也可以用上个方案中的方法来解决,但有更好的方法。那就是要用到中文字符的头文件和源文件开头加上MSVC的一个宏:
#if _MSC_VER >= 1600
#pragma execution_character_set("utf-8")
#endif这个宏告诉MSVC,执行字符集是UTF-8编码的,别瞎整成GB2312的!还有个好处,就是能用tr包中文,方便日后的翻译。最终效果如下:
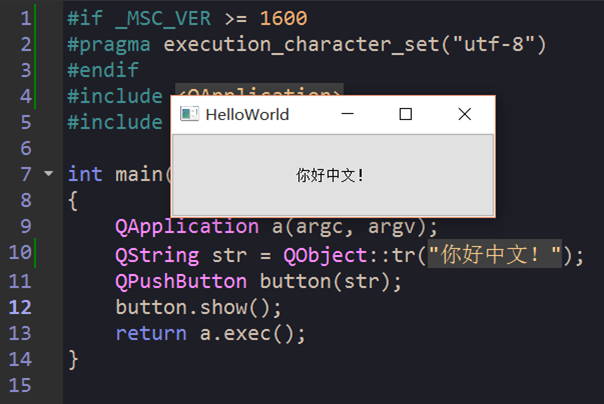
此时,当有BOM时,S为UTF8-BOM,E为UTF8,C为UTF8,此时,S和E相同,编辑器显示正常,S和C相同,编译器识别源码正确。
如果不适用上面的宏,MSVC编译器会将识别到对的字符转码为执行字符集,即GB2312,然后使用在代码中使用了fromUTF8来构造QString,即用UTF8解码GB2312字符,因此造成乱码。
使用了上面的宏,MSVC编译器会将识别到对的字符转码为执行字符集,即UTF8,然后使用在代码中使用了fromUTF8来构造QString,即用UTF8解码UTF8字符,因此显示正确。
3、中文字符续
除了第二部分遇到的问题外,在设置QSS时也遇到了中文字符问题。
在我的项目中,QSS是作为独立文件存在的,然后在程序运行时,加载进来设置样式,此时如果文件中有中文,可能也会有问题,此时最好的做法就是将QSS中的中文删除。
4、第三方库的使用
在项目开发中,使用第三方库必不可少。而当涉及到跨平台时,选取库时一定要提前做好功课,以免后续追悔莫及。
如果不考虑清楚,使用了一个本身就不能跨平台的库,那么后期如果真的需要跨平台了,就需要花很大的精力重新修改代码,而且可能会引入新的bug的问题。
因此,在使用第三方库时,一定要在两个平台上,各自建立一个项目,来测试它的功能,可使用性等。
-
必须保证可以在两个平台下编译成功第三方库,如果在某个平台下不能编译成功,最好弃用
-
先创建一个额外的工程,首先单独对这个工程做跨平台,看是否能成功
-
在各自平台下测试第三方库的功能和性能
在做到上述步骤,慎重考虑之后,再去决定是否选用该库。千万不要抱着先干了再说的想法,方法不当,会给自己带来很多工作上的麻烦,甚至无法完成任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









