







 本文介绍了使用Java开发网络爬虫的基本原理和步骤,包括从网页中抓取URL、存储和避免重复抓取,以及如何使用Jsoup库解析HTML提取数据。通过示例展示了如何从指定网站获取网页内容,并提取链接,最终保存到本地文件。
本文介绍了使用Java开发网络爬虫的基本原理和步骤,包括从网页中抓取URL、存储和避免重复抓取,以及如何使用Jsoup库解析HTML提取数据。通过示例展示了如何从指定网站获取网页内容,并提取链接,最终保存到本地文件。
之前学习j2ee的搭建,基本完成了。
接下来想学习下爬虫技术。要研究一项技术,首先得知道它的原理。
那么网络爬虫的原理是什么呢?
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的
URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
接下来我会一边研究网络爬虫的实现,一边记录产生的问题和解决方案。加油吧^_^!!
这里在网上找了个demo,先给大家看看:以下是利用Java模拟的一个程序,提取新浪页面上的链接,存放在一个文件里:
package testspider;
/**
* Descriptions
*
* @version 2017年3月31日
* @since JDK1.6
*
*/
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/");
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("f:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
} 建立一个java project把代码直接放到里面,运行之后会抓取新浪的所有URL存放在本地的F:/url.txt中
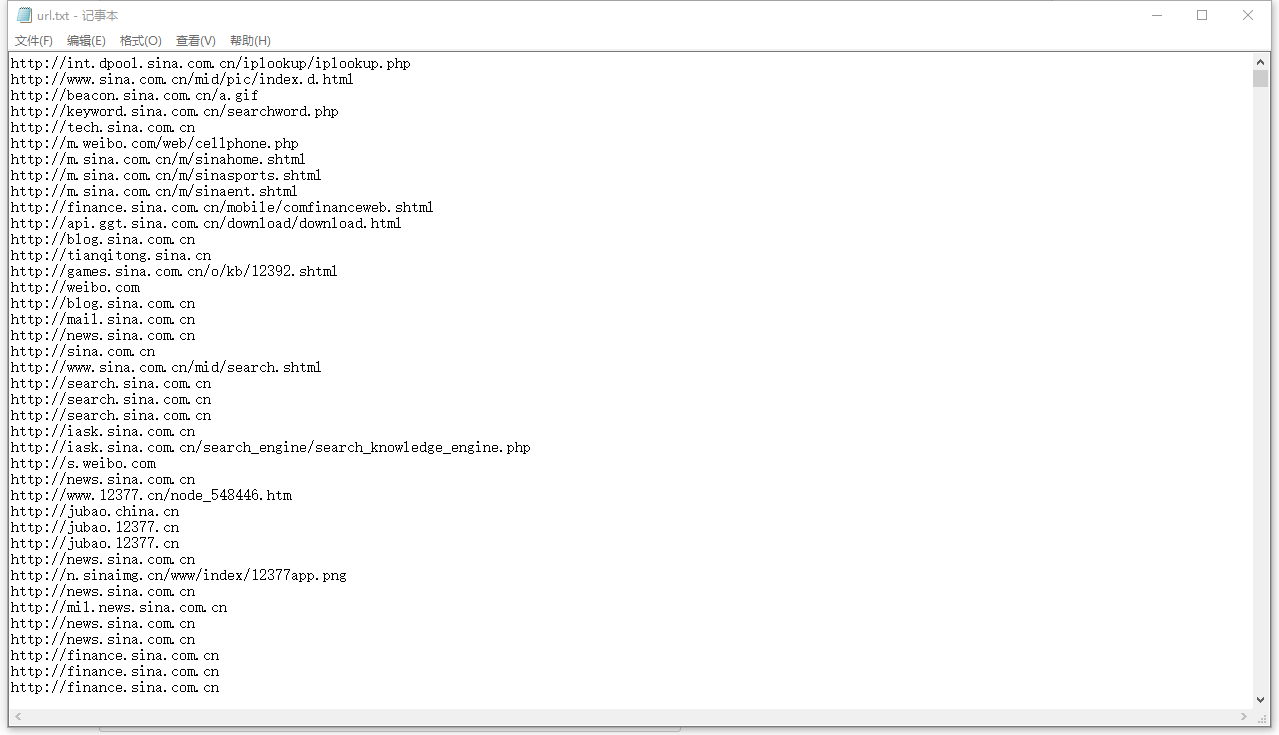
随便选择一条url访问,比如http://beacon.sina.com.cn/a.gif
是可以得到图片的,这只是爬虫的简单实现,接下来我会深入研究它的实现。
网络爬虫:
开发工具:eclipse JDK1.6
从网上找的demo并没有用到服务器。所以我也不用服务器了。也不涉及数据库。把爬到的信息存储在本地目录下。
首先,建一个java工程。第一个类根据URL获取对应网页内容。
package webspilder;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
@SuppressWarnings("deprecation")
public class DownloadPage
{
/**
* 根据 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









