






一 , 宽依赖 ,窄依赖
1 ,前情回顾 :
- 缓存 : 内存,硬盘,保存点。
- standalone 集群搭建。
- sparkPi 任务的提交。
- spark on yarn
- standalone-client 模式程序运行原理。
- standalone-cluster 模式程序运行原理。
- yarn-client 模式程序运行原理。
- yarn-cluster 模式程序运行原理。
2 ,架构理解 :
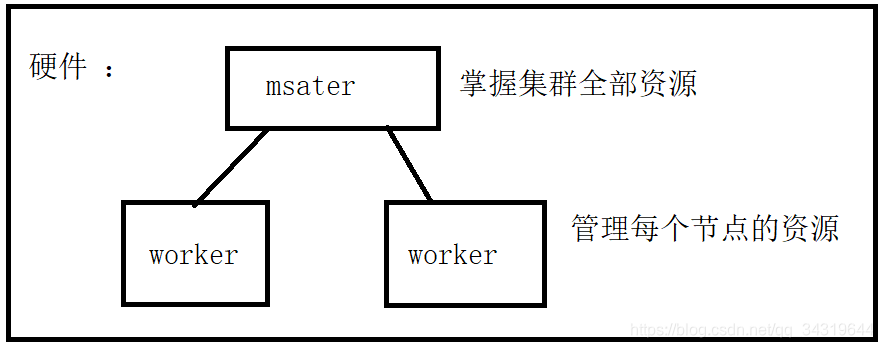
- Master ( standalone ) : 资源管理的主节点( 进程 ) • Cluster Manager : 在集群上获取资源的外部服务 ( 例如 standalone , Mesos , Yarn ) 。
主节点 - Worker Node ( standalone ) : 资源管理的从节点 ( 进程 ) 或者说管理本机资源的进程。
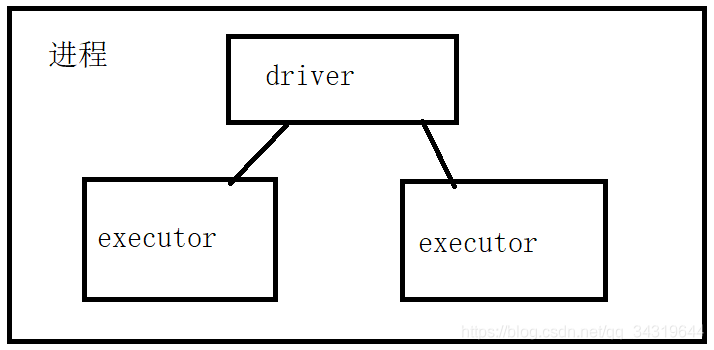
从节点 - Application : 基于 Spark 的⽤用户程序,包含了 driver 程序和运行在集群上的 executor 程序。
一个 spark 程序 - Driver Program :用来连接工作进程( Worker )的程序
主进程 - Executor:是在一个 worker 进程所管理的节点上为某 Application 启动的一个进程,该进
程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应⽤用都有各自独⽴立的
executors - Task :被送到某个 executor上的工作单元
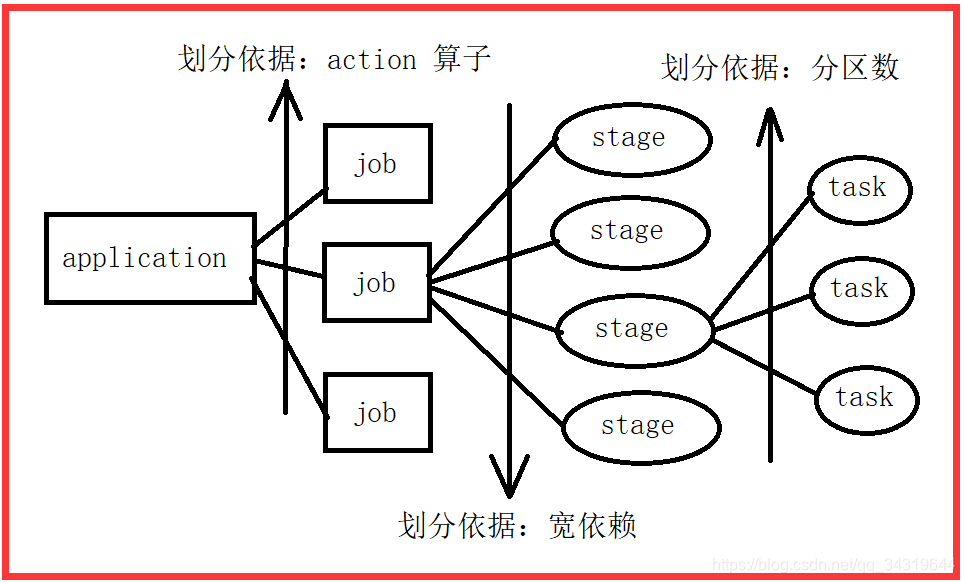
- Job:包含很多任务 ( Task ) 的并行计算,可以看做和 action 对应
- Stage:⼀个 Job 会被拆分很多组任务,每组任务被称为 Stage ( 就像 Mapreduce 分 map task
和 reduce task 一样)
3 ,架构图 :
- 硬件图 :
- 进程图 :
- 程序图 :
4 ,总结 :
- 每个程序有自己的 driver 。
- 每个程序的 executor 是独立的 。
- task 是一个个小任务。
- master 负责接收任务。
- stage : 一组并行的 task 。
5 ,rdd 之间有依赖关系 :通过不同算子,建立的依赖关系
6 ,rdd 的宽窄依赖 : 用 wc 举例子
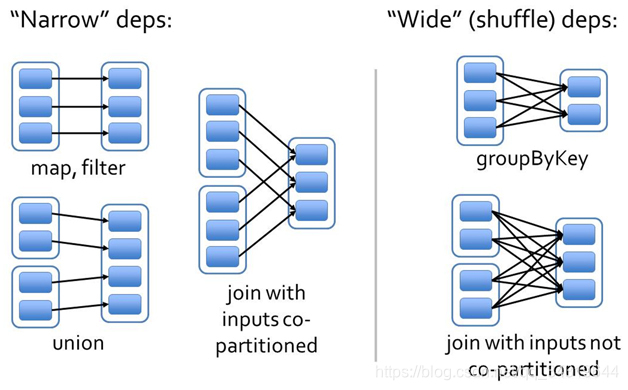
- 窄依赖 : 同一个分区的数据,去了同一个分区。
- 宽依赖 : 同一个分区的数据,去了不同分区。又叫 sheuffle 依赖 ( Shuffle Dependency )
二 ,stage
1 ,lineage 血统 ( 一条数据线:一个数据的前世今生 )
- lineage : RDD 依赖关系图
作用 : 容错
怎么容错 : 依赖关系图中的某一环节数据丢失的话,就根据依赖关系图,去追溯到那里,可以利用算子,重新计算出数据。 - 依赖的类型 : 宽依赖 / 窄依赖
(Wide Dependencies)/(Narrow Dependencies)。 - 容错原理 :
当一个节点宕机了,进行容错恢复时,对于窄依赖来讲,进行重计算时只要把丢失的父 RDD 分区重算即可,不依赖于其他节点。而对于 Shuffle Dependency 来说,进行重计算时需要父 RDD 的分区都存在,这样计算量就太大了比较耗费性能。
孙 : 窄依赖容易,宽依赖难 - 例子 : 3 个 stage ( 用宽依赖隔开 )
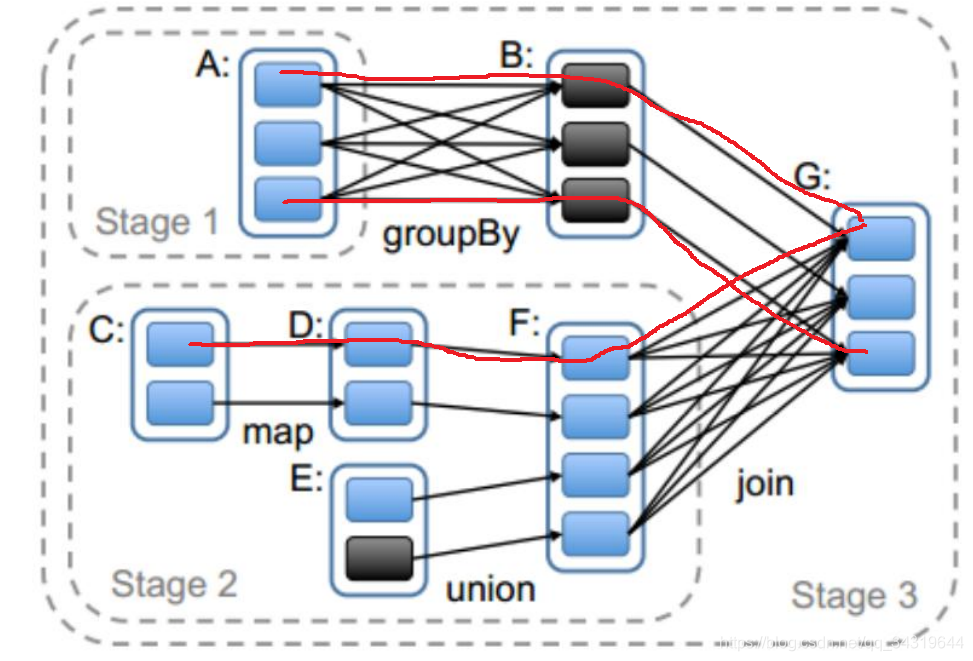
2 ,Stage : 阶段
- 划分 stage 的思路 :
从最后一个 RDD 开始,调用递归算法查找该 RDD 后开始遍历,判断父 RDD 和该 RDD 的依赖关系,如果是宽依赖,就把父 RDD 和前面所有的 RDD 都划分成一个 stage,若果是窄依赖,继续递归查找父 RDD 的父 RDD,递归的出口是直到找不到父 RDD,最后把所有的 RDD 统一划分一个 stage 。 - WordCount 的 stage 个数

- 孙 :
1 ,窄依赖放到一起。
2 ,遇到宽依赖了 : 前面的算作一个,从现在开始,往后看。
3 ,再遇到宽依赖了 : 前面的全部算作一个,从现在开始往后看。
3 ,dag : 有向无环图
- DAG ( Directed Acyclic Graph ) :叫做有向无环图
- DAG 解决了什么问题 :
1 ,每个 MapReduce 操作都是相互独立的,HADOOP不知道接下来会有哪些Map Reduce。
2 ,每一步的输出结果,都会持久化到硬盘或者 HDFS 上。 - spark 的优点 :
所以 Spark 中引入了 DAG,它可以优化计算计划,比如减少 shuffle 数据。 - dag : 就是各个 stage 连接起来组成的图 :
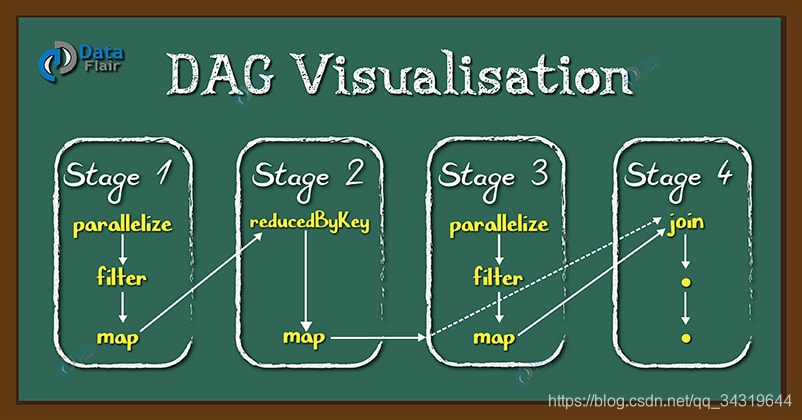
4 ,处理数据的方式 : 落地
- 一条一条的处理
- 并不是所有数据一起处理
- 数据处理后落地
- 落地到款依赖之前那一步
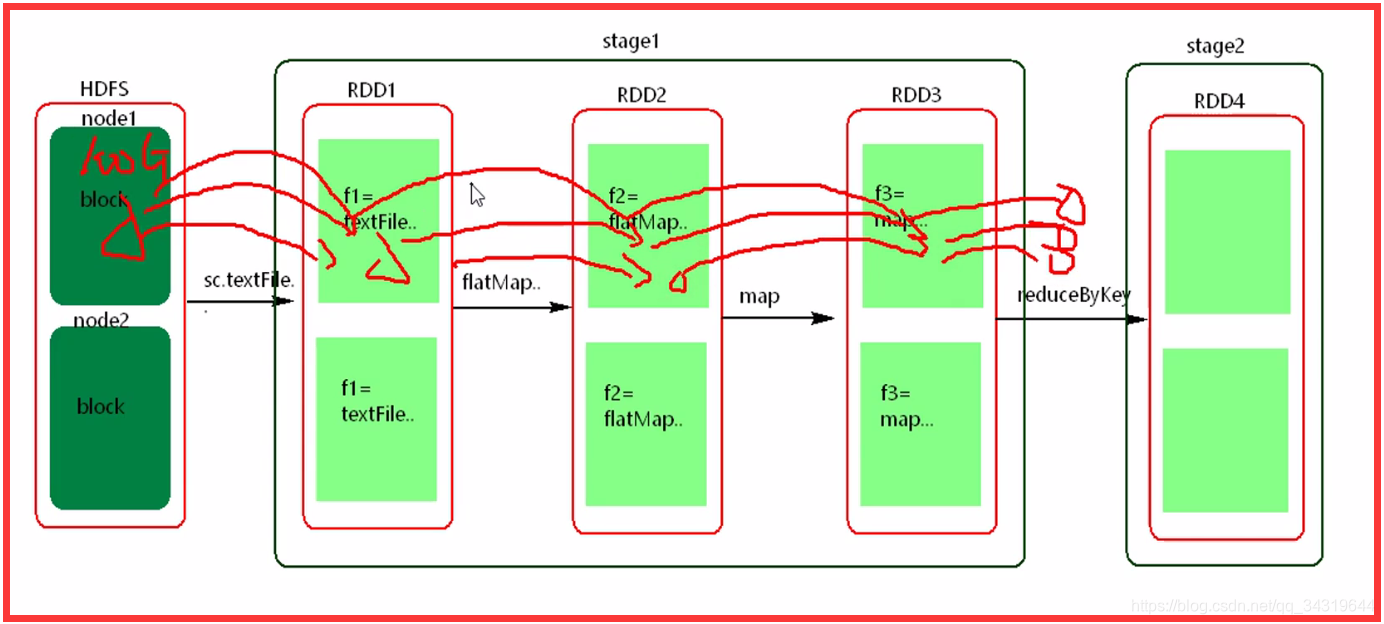
5 ,dag 与 action 算子 :
- 关系 : 1 对 1
- 原理 : 本质上在 Action 算子中通过 SparkContext 进行了提交作业的 runJob 操作,触发了RDD DAG 的执行。
6 ,applycation , job , stage , task 关系图 :

7 ,task 划分 : 粗箭头代表 task ,细箭头代表 shuffle

8 ,spark 的最大优势 :
迭代的场景
9 ,pipeline : spark 处理书的模式 ( 管道处理模式 )
- 一个 stage 由一组并行的 task 组成
- stage 的并行度由谁决定 : 由stage 的最后一个 rdd ( final rdd ) 的分区数决定。
- pipeline 图解 :
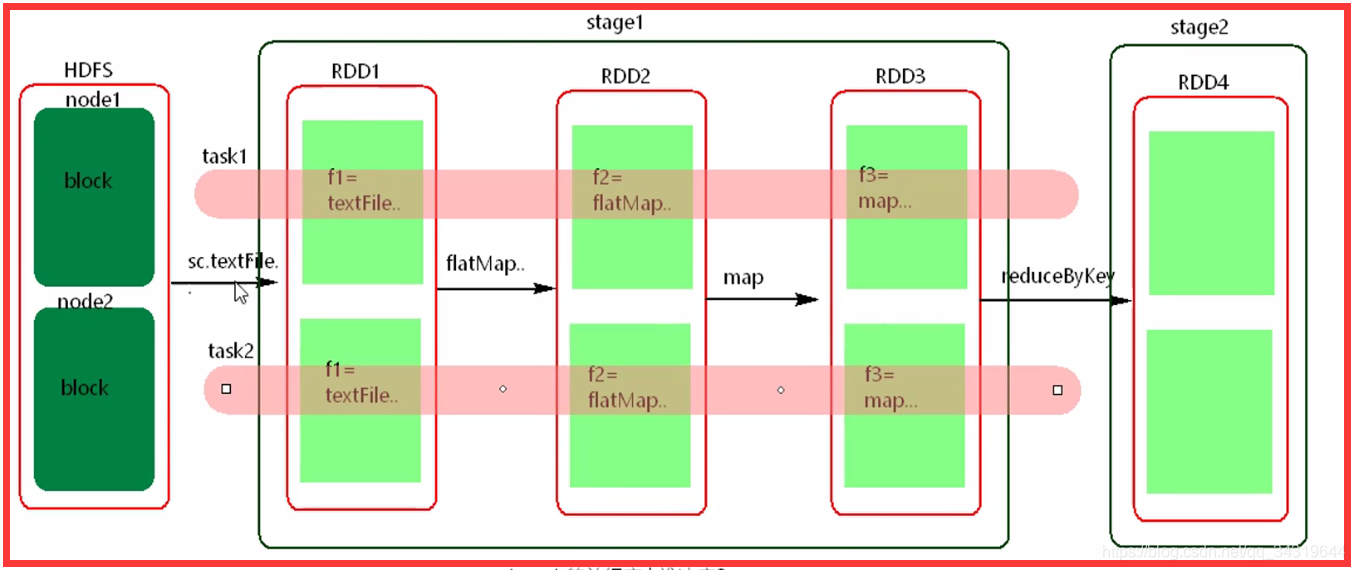
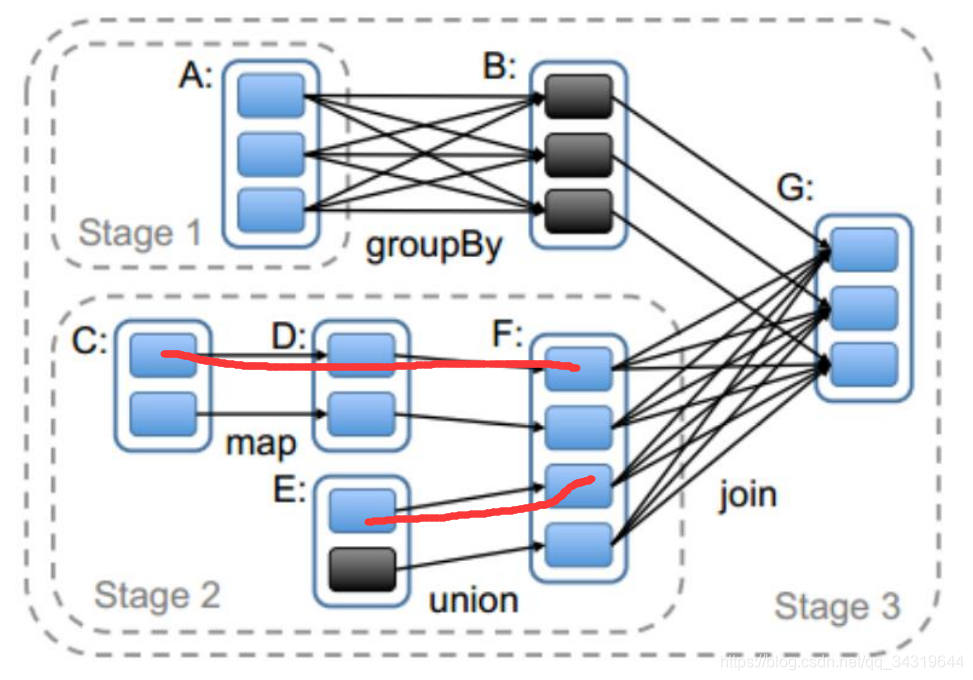
10 ,一个 stage 的多个并行 task 中,处理的逻辑是相同的吗 ?
不是,因为,如图
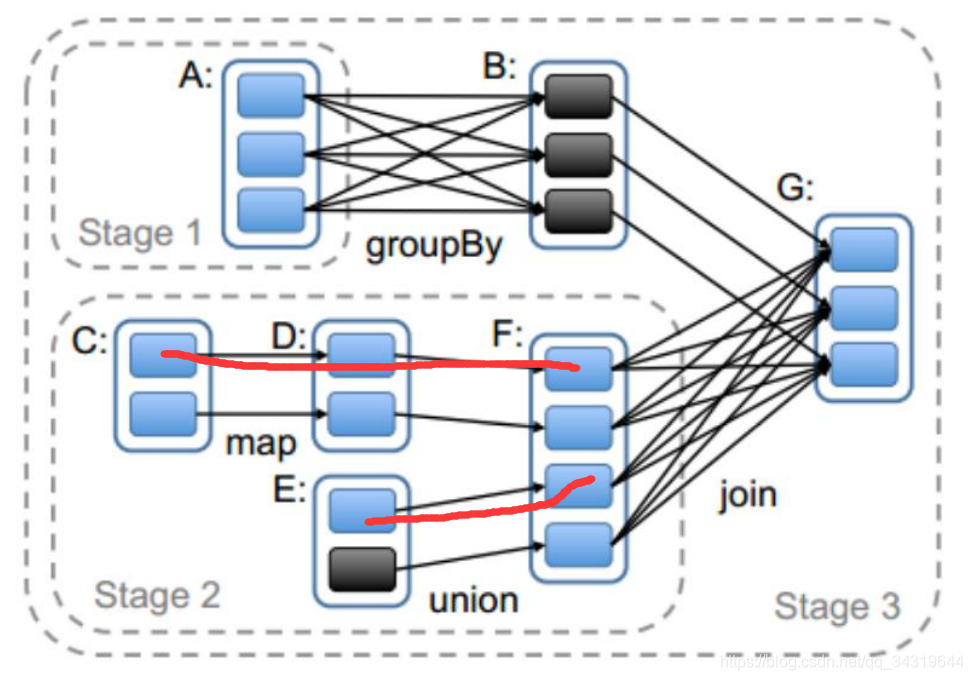
11 ,管道中的数据,何时落地 :
- 持久化时
- shuffle write 时
12 ,如何提高 stage 的并行度 :
增加分区数
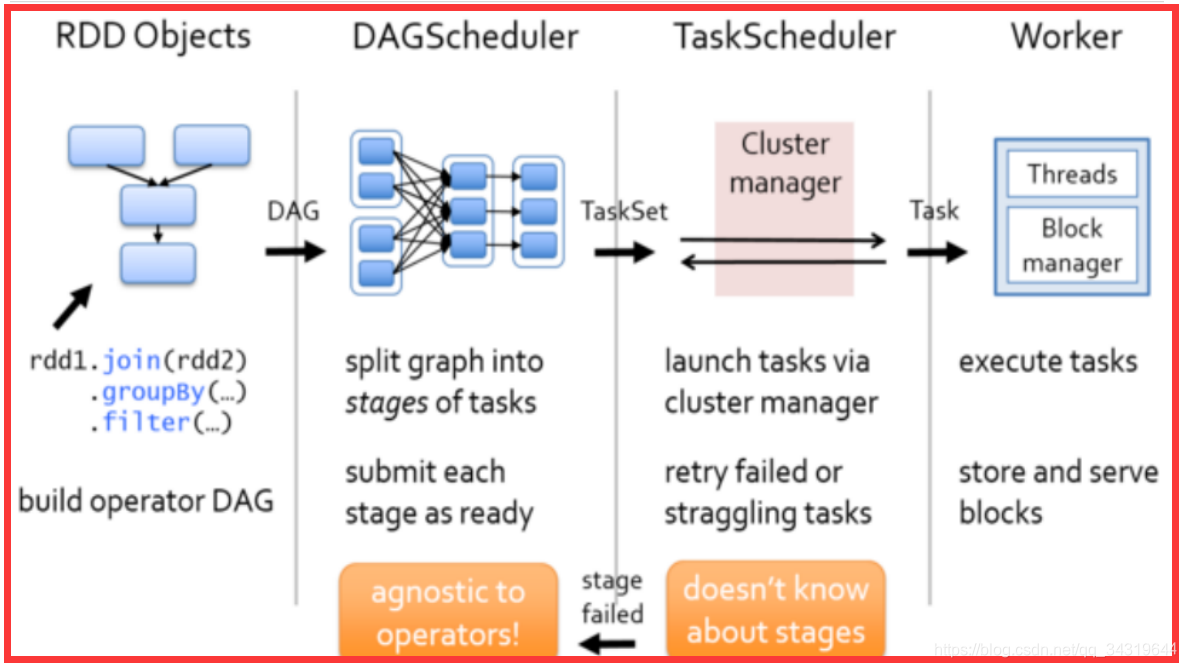
13 ,任务执行流程 :
- driver 做了什么事情 : 前三步
- executor 在哪里执行 : worker 节点
- dagScheduler 失败重试 :4 次
- taskScheduler 失败重试 : 3 次
- 如果发生错误,taskScheduler 首先失败重试,然后 dagScheduler 失败重试,如果还是失败,就失败了。
14 ,推测执行 :
默认关闭
如果有任务执行缓慢,会有另外的机器执行这个任务,谁先结束,用谁的。














 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









