







 本文介绍了利用Huffman编码实现文件压缩的思路与步骤,包括统计字符频率、构建Huffman树、生成编码、压缩文件、生成配置文件等。同时,文中提到了在实现过程中遇到的问题,如非法值处理、字节填充、配置文件生成等,并给出了解决方案。对于大文件和特殊字符(如汉字、图片、音频视频)的处理,作者也进行了讨论,确保了压缩和解压缩的正确性。
本文介绍了利用Huffman编码实现文件压缩的思路与步骤,包括统计字符频率、构建Huffman树、生成编码、压缩文件、生成配置文件等。同时,文中提到了在实现过程中遇到的问题,如非法值处理、字节填充、配置文件生成等,并给出了解决方案。对于大文件和特殊字符(如汉字、图片、音频视频)的处理,作者也进行了讨论,确保了压缩和解压缩的正确性。
文件压缩与解压缩>
最近这段时间一直在学习树的这种数据结构,也接触到了Huffman树以及了解了什仫是Huffman编码,而我们常用的zip压缩也是利用的Huffman编码的特性,那仫是不是可以自己实现一个文件压缩呢?当然可以了.在文件压缩中我实现了Huffman树和建堆Heap的代码,zip压缩的介绍>
下面开始介绍自己实现的文件压缩的思路和问题...
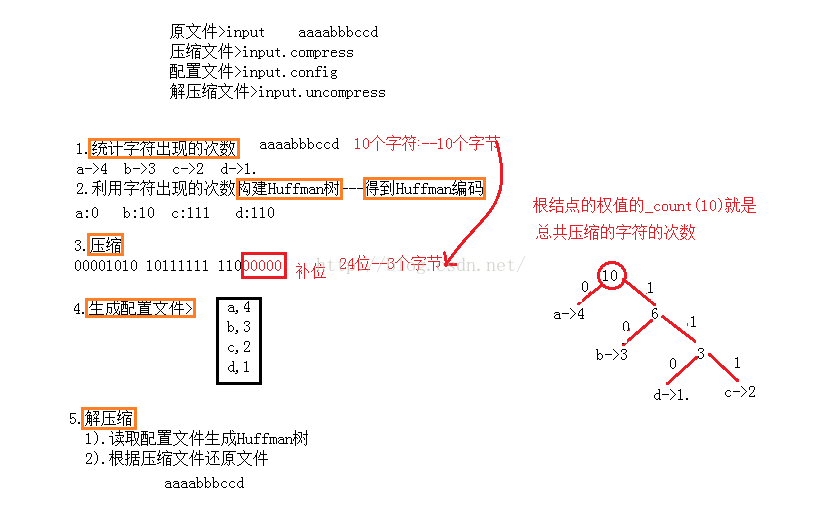
1).统计>读取一个文件统计这个文件中字符出现的次数.
2).建树>以字符出现的次数作为权值使用贪心算法构建Huffman树(根据Huffman树的特性>字符出现次数多的一定靠近根结点,出现次数少的一定远离根结点).
3).生成Huffman编码>规则左0右1.
4).压缩>再次读取文件,根据生成的Huffman编码压缩文件.
5).生成配置文件>将字符以及字符出现的次数写进配置文件中.
6).解压缩>利用配置文件还原出Huffman树,根据压缩文件还原出原文件.
7).测试>判断解压是否正确需要判断原文件和解压缩之后的文件是否相同,利用Beyond Compare软件进行对比.
下面是我举的一个简单的范例,模拟压缩和解压缩的过程,希望有读者有帮助
利用Beyond Compare软件进行对比>

在实现中出现了很多的问题,下面我提出几个容易犯的问题,仅供参考
1).在使用贪心算法构建Huffman树的时候,如果我们以unsigned char一个字节来存储它总共有2^8=256个字符,如果将所有的字符都构建Huffman树,这不仅降低了效率还将分配极大的内存.所以我设立了非法值这个概念,只有当字符出现的次数不为0的时候才将该字符构建到Huffman树中.
2).在写压缩文件的时候我们是将字符对应的Huffman编码转化为对应的位,每当填满一个字节(8位)后再写入压缩文件中.如果最后一个字节没有填满我们就将已经填的位移位空出后几个位置,将未满的位置补0补满一个字节再写入压缩文件中.
3).如果我们将源文件压缩之后再去解压,因为你的Huffman树和Huffman编码都是在压缩函数中得到的,此时再去解压那仫你的Huffman编码以及不存在了该如何去还原文件呢?这就是为什仫要生成配置文件的原因了,在配置文件中写入了字符以及字符出现的次数.在解压缩中根据配置文件构建新的Huffman树.
4).由压缩文件还原文件的时候如何知道压了多少个字符呢?也就是说因为我们在压缩的时候最后一个字节是补了0的在解压缩的时候可能会把这个补的位当成字符的编码来处理.一种想法是在统计字符出现的次数的时候设置一个变量,每读取一个字符该变量就加1,最后将该变量写进配置文件中.另外一种想法就是根据根结点的权值,通过上述简单的实例观察可知根结点权值中的_count就是字符出现的次数.
解决了以上几个问题,我的程序已经可以压缩那256个字符并正确的还原了,那仫如果是大文件或者是汉字,图片以及音频视频呢?
1).因为有些特殊的字符编码,所以我们统计字符出现的次数的时候应该用的是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1777
1777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









