










前言
ShardingSphere-JDBC 在5.x版本移除了默认数据源配置, 那在项目中大多不需要分片的表, 怎么办?看看官方怎么说
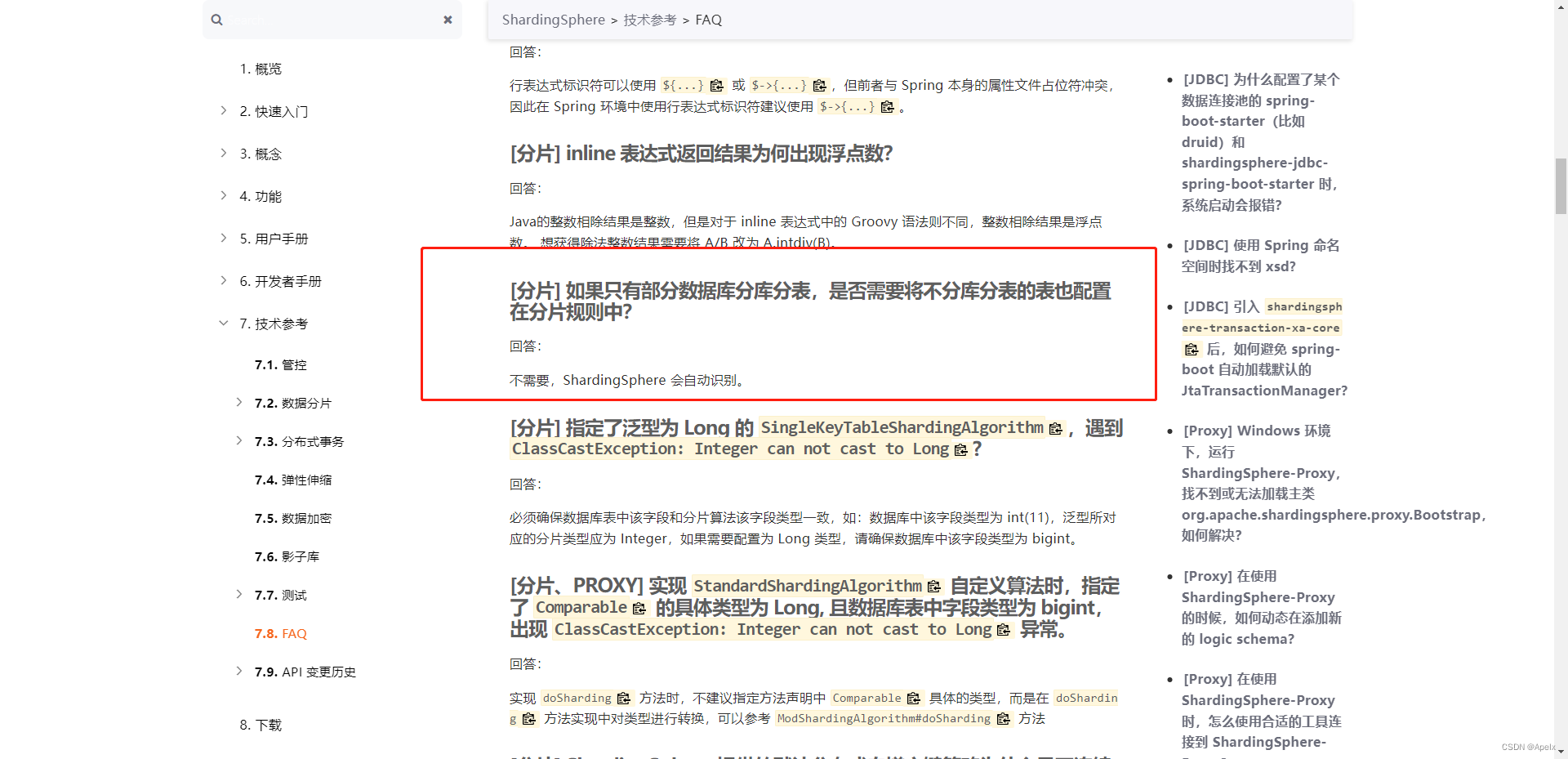
github上也有issues
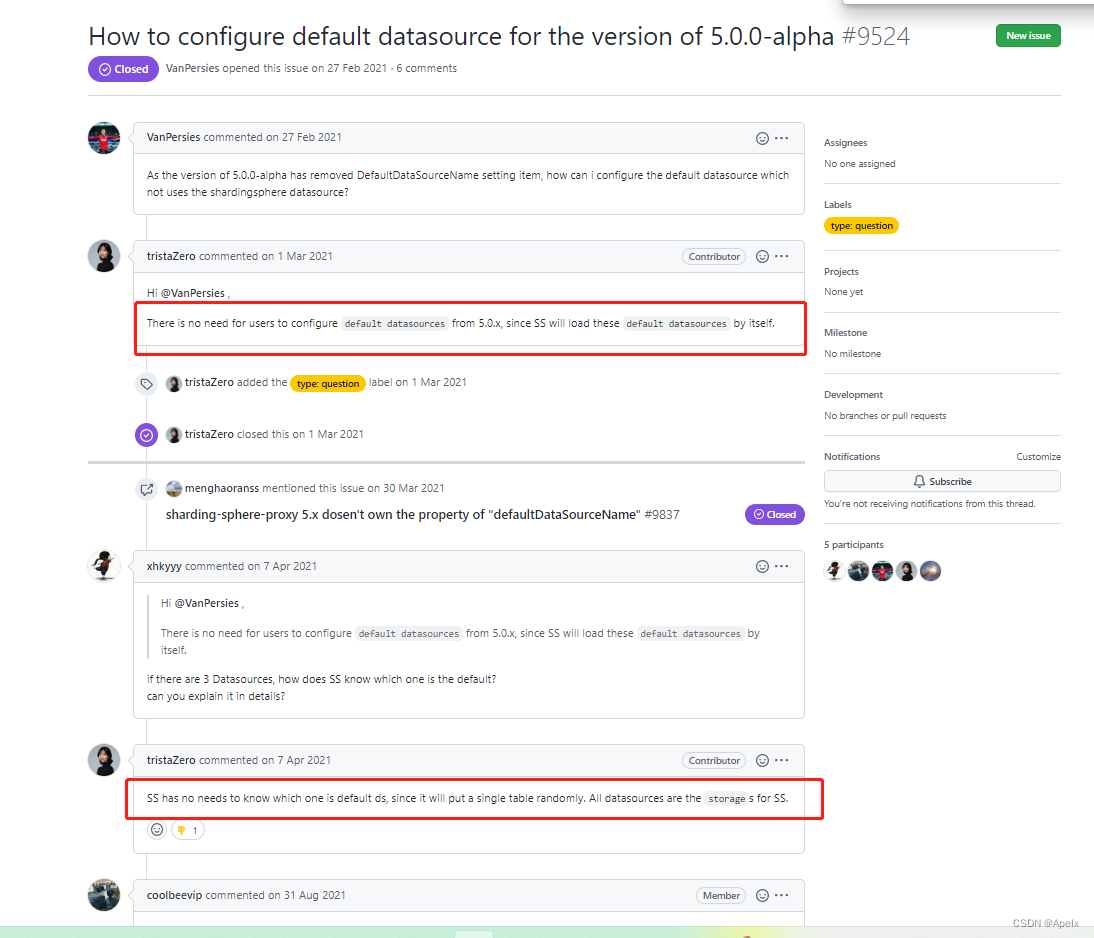
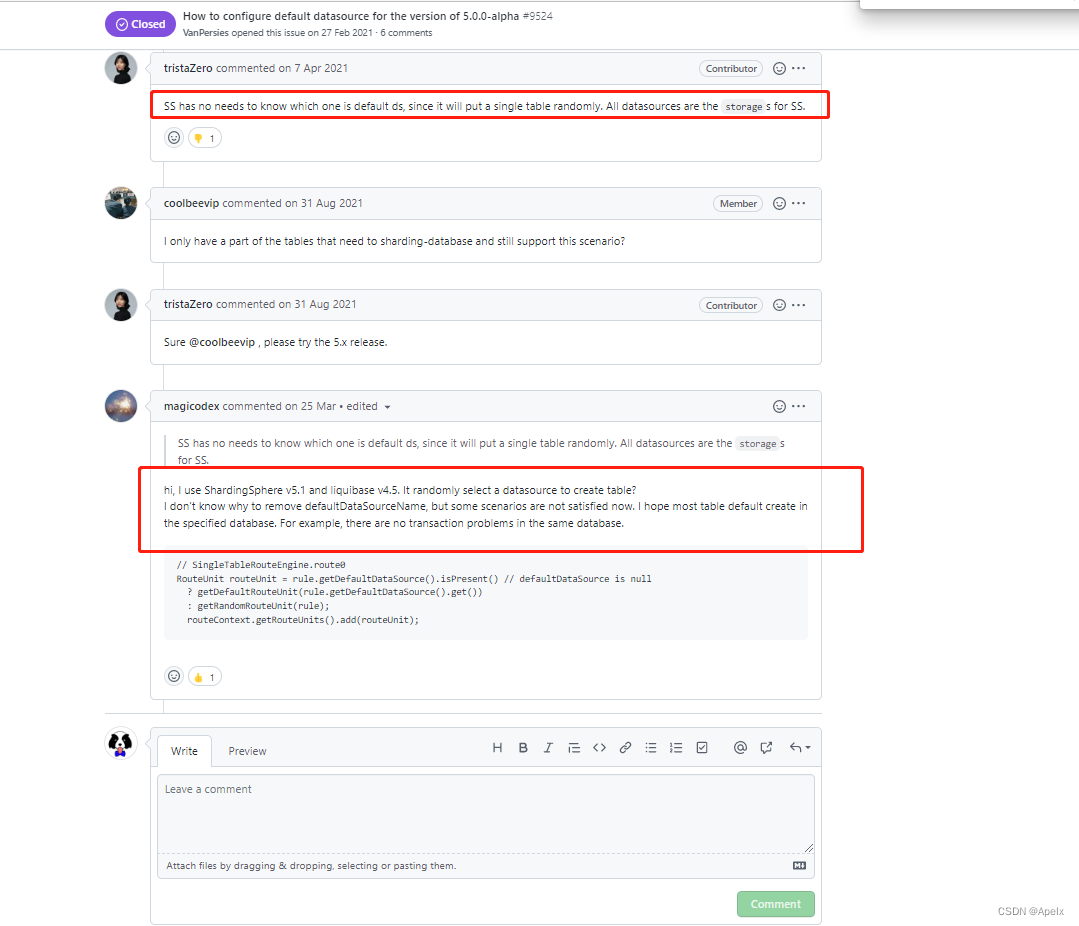
看了半天,很遗憾, 没有看到满意的解决方案
如果在项目里分了多个库,不需要分片的表我就想指定用一个数据源,怎么破?
low点的解决方案1
每个表都配置一下默认actualDataNode
server:
port: 8080
spring:
application:
name: sharding-jdbc
autoconfigure:
exclude: com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/sharding-jdbc?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: root
main:
allow-bean-definition-overriding: true
jpa:
show-sql: false
hibernate:
ddl-auto: none
shardingsphere:
mode:
# 运行模式类型。可选配置:Memory(不需要下面repository持久化)、Standalone、Cluster
type: Memory
datasource:
names: ds_1,ds_2
ds_1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
# 注意: 使用druid作为连接池,这里要改成 url
url: jdbc:mysql://192.168.32.110:3306/sharding-jdbc?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: root
ds_2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.32.111:3306/sharding-jdbc?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
username: root
password: root
rules:
sharding:
tables:
# 5.0之后移除了默认数据源,如果在这里不指定不分片表的话,会由sharding内部自己找数据源
tbl_test1:
actual-data-nodes: ds_2.tbl_test1
tbl_test2:
actual-data-nodes: ds_2.tbl_test2
props:
sql-show: true
我项目里有100张表,只有两张表需要分片, 其他的表要配置98次, 是不是有点low?
low点的解决方案2
那是不是可以完全基于API的方式使用sharding
在构建Sharding的AlgorithmProvidedShardingRuleConfiguration#tables(Collection<ShardingTableRuleConfiguration)时,将自定义不需要配置表名放在配置文件里,然后一个for来放进去
#自定义配置
sharding:
exclude:
# 不需要分片的表
tables: tbl_test1,tbl_test2
# 默认的数据源
default:
data-source-name: ds_2
@Value("${sharding.default.data-source-name}")
private String shardingDefaultDataSourceName;
@Value("${sharding.exclude.tables}")
private String shardingExcludeTables;
@Bean
public RuleConfiguration ruleConfiguration(){
AlgorithmProvidedShardingRuleConfiguration ruleConfiguration = new AlgorithmProvidedShardingRuleConfiguration();
String[] tables = shardingExcludeTables.split(",");
for (String table : tables) {
ruleConfiguration.getTables().add(new ShardingTableRuleConfiguration(table, shardingDefaultDataSourceName + "." + table));
}
// .... 省略需要分片的表配置
return ruleConfiguration;
}
API的方式没有配置文件方式灵活,而且这样解决,正常的表还需把表名配置到配置文件中,还是有点low
探索解决之道
既然上面那么麻烦,那是不是可以让系统自己去识别系统有多少张表, 已经在sharding中配置了哪些表,他们的差集就是就是不需要分片的表,把这些表的规则添加到Sharding的rule中,再指定我们自己想指定的默认数据源
本质上还是如解决方案2一样,向rule中添加不需要分片的表的规则,指定actualDataNode, 区别是不用自己去配置表,由系统来完成
想法有了之后,开始落地
先理解一下内部机制,从看源码开始,毋庸置疑从自动配置类读起
/**
* Spring boot starter configuration.
*/
@Configuration
@ComponentScan("org.apache.shardingsphere.spring.boot.converter")
@EnableConfigurationProperties(SpringBootPropertiesConfiguration.class)
@ConditionalOnProperty(prefix = "spring.shardingsphere", name = "enabled", havingValue = "true", matchIfMissing = true)
@AutoConfigureBefore(DataSourceAutoConfiguration.class)
@RequiredArgsConstructor
public class ShardingSphereAutoConfiguration implements EnvironmentAware {
private String schemaName;
private final SpringBootPropertiesConfiguration props;
private final Map<String, DataSource> dataSourceMap = new LinkedHashMap<>();
@Bean
public ModeConfiguration modeConfiguration() {
return null == props.getMode() ? null : new ModeConfigurationYamlSwapper().swapToObject(props.getMode());
}
@Bean
@Conditional(LocalRulesCondition.class)
@Autowired(required = false)
public DataSource shardingSphereDataSource(final ObjectProvider<List<RuleConfiguration>> rules, final ObjectProvider<ModeConfiguration> modeConfig) throws SQLException {
Collection<RuleConfiguration> ruleConfigs = Optional.ofNullable(rules.getIfAvailable()).orElse(Collections.emptyList());
return ShardingSphereDataSourceFactory.createDataSource(schemaName, modeConfig.getIfAvailable(), dataSourceMap, ruleConfigs, props.getProps());
}
@Bean
@ConditionalOnMissingBean(DataSource.class)
public DataSource dataSource(final ModeConfiguration modeConfig) throws SQLException {
return !dataSourceMap.isEmpty() ? ShardingSphereDataSourceFactory.createDataSource(schemaName, modeConfig, dataSourceMap, Collections.emptyList(), props.getProps())
: ShardingSphereDataSourceFactory.createDataSource(schemaName, modeConfig);
}
@Bean
public TransactionTypeScanner transactionTypeScanner() {
return new TransactionTypeScanner();
}
@Override
public final void setEnvironment(final Environment environment) {
dataSourceMap.putAll(DataSourceMapSetter.getDataSourceMap(environment));
schemaName = SchemaNameSetter.getSchemaName(environment);
}
}
很显然,sharding需要代理数据源才能解析sql, 在通过分片规则重新拼接sql再转发。RuleConfiguration下与分片规则相关的是AlgorithmProvidedShardingRuleConfiguration,如下
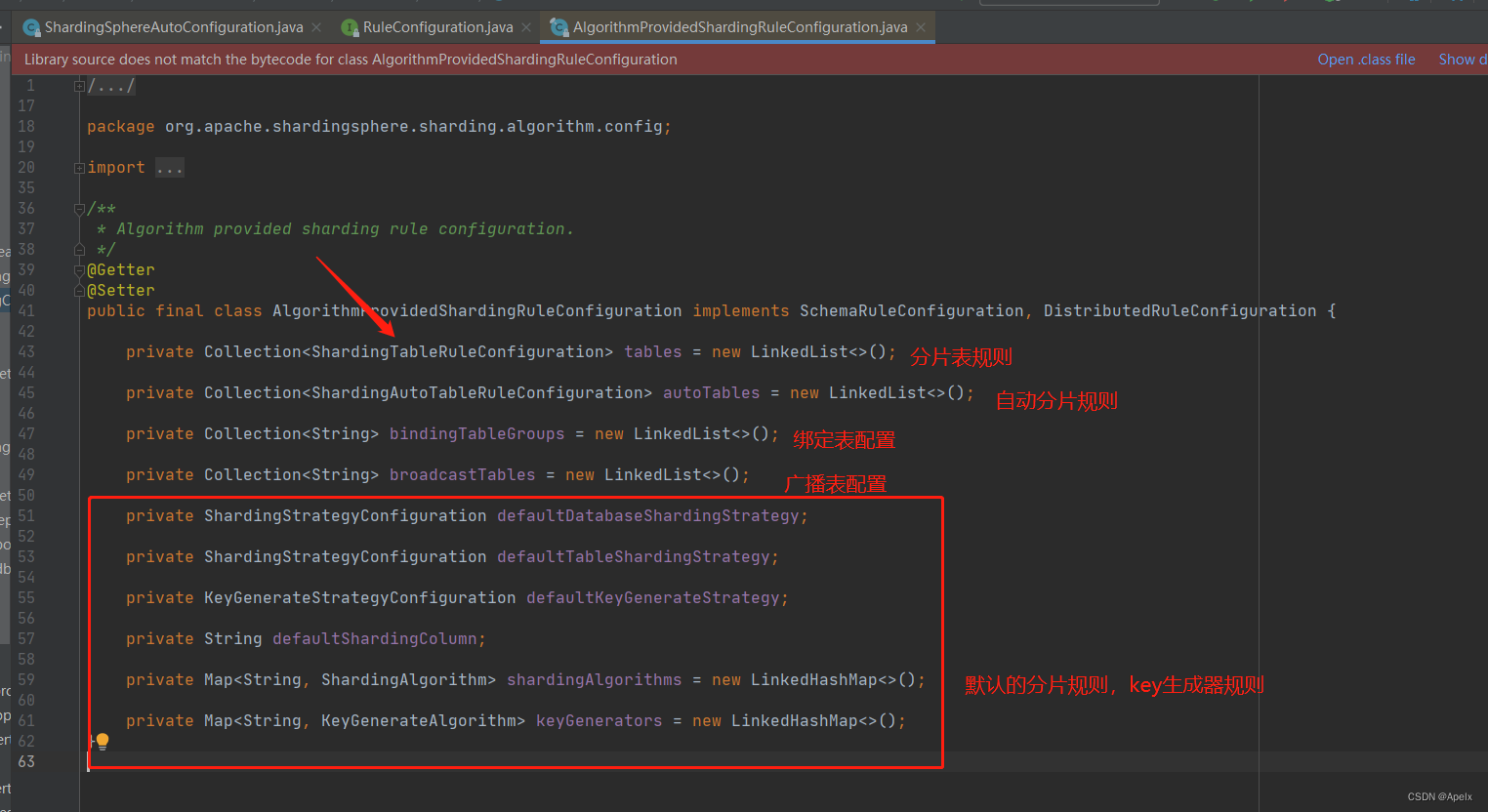 而自定义的分片规则就是tables里, Collection 如下
而自定义的分片规则就是tables里, Collection 如下

看明白了,来实现! 先获取系统中所有的表,借助jpa entityManager,可以拿到所有entity, 从而获取到所有的表名, InitializingBean 就不用多讲了, 再对Sharding的RuleConfigration后置处理一下,把不需要分片的表添加到rule中
/**
* 实体Util
*
* @author apelx
* @since 2022-05-14
*/
@Component
public class EntityBeanUtil implements InitializingBean {
private static Map<Class<?>, SingleTableEntityPersister> map = new ConcurrentHashMap<>(16);
@Autowired
private EntityManager entityManager;
@Override
public void afterPropertiesSet() throws Exception {
EntityManagerFactory entityManagerFactory = entityManager.getEntityManagerFactory();
SessionFactoryImpl sessionFactory = (SessionFactoryImpl) entityManagerFactory.unwrap(SessionFactory.class);
MetamodelImplementor metamodel = sessionFactory.getMetamodel();
Map<String, EntityPersister> entityPersisterMap = metamodel.entityPersisters();
Set<Map.Entry<String, EntityPersister>> entries = entityPersisterMap.entrySet();
for (Map.Entry<String, EntityPersister> entry : entries) {
// 全限定类名
String className = entry.getKey();
SingleTableEntityPersister entityPersister = (SingleTableEntityPersister) entry.getValue();
// 表名
String tableName = entityPersister.getTableName();
map.put(Class.forName(className), entityPersister);
}
}
public static Map<Class<?>, SingleTableEntityPersister> getEntityMap() {
return map;
}
public static Set<String> getAllTableNames() {
return map.values().stream().map(SingleTableEntityPersister::getTableName).collect(Collectors.toSet());
}
}
/**
* Sharding后置处理RuleConfig
*
* @author apelx
* @since 2022-05-14
*/
public class ShardingPostProcess {
private final String defaultDatasourceName;
ShardingPostProcess(String defaultDatasourceName) {
this.defaultDatasourceName = defaultDatasourceName;
}
/**
* 对所有分片规则中的表与当前系统中所有实体类表进行对比
* 没有配置规则在shardingRule中, 添加默认规则,使用指定的默认数据源
*
* @param rules
*/
public void postProcess(RuleConfiguration rules) {
if (rules instanceof AlgorithmProvidedShardingRuleConfiguration) {
Collection<ShardingAutoTableRuleConfiguration> autoTables = Optional.ofNullable(((AlgorithmProvidedShardingRuleConfiguration) rules).getAutoTables()).orElse(new ArrayList<>(0));
Collection<String> broadcastTables = Optional.ofNullable(((AlgorithmProvidedShardingRuleConfiguration) rules).getBroadcastTables()).orElse(new ArrayList<>(0));
Collection<ShardingTableRuleConfiguration> tables = Optional.ofNullable(((AlgorithmProvidedShardingRuleConfiguration) rules).getTables()).orElse(new ArrayList<>(0));
// 已配置分片规则的表
Set<String> shardingTables = autoTables.stream().map(ShardingAutoTableRuleConfiguration::getLogicTable).collect(Collectors.toSet());
shardingTables.addAll(new HashSet<>(broadcastTables));
shardingTables.addAll(tables.stream().map(ShardingTableRuleConfiguration::getLogicTable).collect(Collectors.toSet()));
// 系统所有实体表名
Set<String> allTables = EntityBeanUtil.getAllTableNames();
// 取差集
Collection<String> differenceSet = CollectionUtil.subtract(allTables, shardingTables);
if (CollectionUtil.isEmpty(differenceSet)) {
return;
}
if (((AlgorithmProvidedShardingRuleConfiguration) rules).getTables() == null) {
((AlgorithmProvidedShardingRuleConfiguration) rules).setTables(new ArrayList<>(differenceSet.size()));
}
for (String tableName : differenceSet) {
ShardingTableRuleConfiguration config =
new ShardingTableRuleConfiguration(tableName, defaultDatasourceName + "." + tableName);
((AlgorithmProvidedShardingRuleConfiguration) rules).getTables().add(config);
}
}
}
}
接下来就是重头戏了!
sharding的自动配置类需要注入数据源,这些分片规则都是保存在它数据源里的!刚开始我还没意识到哪有问题,我禁了sharding的autoConfig类,自己弄了一个配置类,与它的内容一样,在构建数据源的时候,我在规则里添加那些不需要分片表的规则,与我配置的自定义数据库相绑定,然后规则放到数据源中。但是! 但是!问题来了 数据源都没创建,jpa EntityManager怎么能注入呢,它是要依赖数据源的! , 在创建数据源的时候又想用jpa EntityManager,这就是个伪命题!
...... 此处省略尝试的配置
思考了很久,终于还是想到了解决思路
既然不能互相矛盾,那肯定是要先让数据源创建出来的,在sharding的自动配置完成了之后,它为我们做的是将它的数据源放到了ioc,这样在上层ORM框架执行sql,会被它的数据源解析,分片,发送。那么我是不是可以在整个ioc初始化完之前,在sharding-datasource的bean生成之后、在我自己定义的EntityBeanUtil创建完之后,重新生成一下sharding的datasource, 此时我已经能拿到所有的表了,之前的sharing分片规则我也能拿到,最后再替换掉ioc里的 ShardingDatasource,问题就迎刃而解了
实操
## 自定义配置默认数据源
sharding:
default:
datasource: ds_2
ShardingPostProcess 这个类注入到spring容器只是起到一个过桥的作用,仅仅是在他创建的方法里去实现我替换Sharding 数据源的操作
/**
* 解决5.x未配置分片的表无法指定dataSource
* <p>
* 在shardingSphereDataSource创建好之后, 我在做一个桥接的bean,顺序在dataSource创建完成之后, 再获取到spring的bean工厂
* 接下来就简单了, 之前的规则保留,再添加不需要分片表的规则,重新创建dataSource, 替换掉原ioc容器里的dataSource
*
* @author apelx
* @since 2022-05-14
*/
@Configuration
@ComponentScan("org.apache.shardingsphere.spring.boot.converter")
@EnableConfigurationProperties(SpringBootPropertiesConfiguration.class)
@AutoConfigureAfter(value = ShardingSphereAutoConfiguration.class)
@RequiredArgsConstructor
public class SharingConfig implements BeanFactoryAware, EnvironmentAware {
@Value("${sharding.default.datasource}")
private String defaultDatasourceName;
private String schemaName;
private final SpringBootPropertiesConfiguration props;
private final Map<String, DataSource> dataSourceMap = new LinkedHashMap<>();
private DefaultListableBeanFactory beanFactory;
@Bean
@DependsOn(value = "entityBeanUtil")
public ShardingPostProcess shardingPostProcess(final ObjectProvider<List<RuleConfiguration>> rules, final ObjectProvider<ModeConfiguration> modeConfig) throws SQLException {
ShardingPostProcess shardingPostProcess = new ShardingPostProcess(defaultDatasourceName);
// 后置处理添加自定义的规则,再重新构建dataSource
Collection<RuleConfiguration> ruleConfigs = Optional.ofNullable(rules.getIfAvailable()).orElse(Collections.emptyList());
ruleConfigs.forEach(shardingPostProcess::postProcess);
DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(schemaName, modeConfig.getIfAvailable(), dataSourceMap, ruleConfigs, props.getProps());
// 覆盖掉dataSource
beanFactory.destroySingleton("shardingSphereDataSource");
beanFactory.registerSingleton("shardingSphereDataSource", dataSource);
return shardingPostProcess;
}
/**
* Set the {@code Environment} that this component runs in.
*
* @param environment
*/
@Override
public void setEnvironment(Environment environment) {
dataSourceMap.putAll(DataSourceMapSetter.getDataSourceMap(environment));
schemaName = SchemaNameSetter.getSchemaName(environment);
}
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = (DefaultListableBeanFactory) beanFactory;
}
}
结语
到此搞定, 改一下自定义默认的数据源名,就可以实现需求了
测试环节就省略了,有兴趣实现一下还是很有意思的
项目地址 gitee
有问题欢迎留言交流















 1482
1482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









