






Java Development - Collections
- 1. What
- 2. Why
- 3. How
- **3.1 What is the difference between List, Set, and Map (List、Set、Map的区别)**
- **3.2 ArrayList**
- **3.2.1 Difference between ArrayList and LinkedList (ArrayList和LinkedList的区别)**
- **3.2.3 Synchronize ArrayList (同步ArrayList)**
- **3.2.4 Dynamic sizing of ArrayList (ArrayList扩容机制)**
- 3.3 LinkedList
- 3.4 Set
- 3.4.1 HashSet (Hash 表)
- **3.4.2 TreeSet (红黑树)**
- **3.4.3 LinkedHashSet(HashSet+LinkedHashMap)**
- 3.5 Map
- 3.5.1. HashMap(数组+链表+红黑树)
- **3.5.2 ConcurrentHashMap**
- **3.6 Queue**
- 3.7 DualPivotQuicksort 双轴快排算法
- 4. Samples
1. What
1.1 Definition (定义)
- The Collection in Java is a framework that provides an architecture to store and manipulate the group of objects.
Java中的集合是一个框架,它提供了一个架构来存储和操作一组对象。 - Java Collections can achieve all the operations that you perform on a data such as searching, sorting, updating, insertion, and deletion.
Java集合可以实现对数据执行的全部操作,例如搜索、排序、更新、插入和删除 - Java Collection means a single unit of objects. Java Collection framework provides many interfaces (Set, List, Queue, Deque) and classes (ArrayList, Vector, LinkedList, PriorityQueue, HashSet, LinkedHashSet, TreeSet).
Java集合是指单个对象组。Java集合框架提供了许多接口(Set, List, Queue, Deque)和类(ArrayList, Vector, LinkedList, PriorityQueue, HashSet, LinkedHashSet, TreeSet)。 - Conceptually Java Collection also includes Map (HashMap, LinkedHashMap, TreeMap), althougth Map does not implement the Collection interface.
概念上Java集合也包括映射表(HashMap, LinkedHashMap, TreeMap), 尽管映射表并没有实现Collection接口
1.2 Hierarchy of the Collection Framework 集合框架的层级结构
The java.util package contains all the classes and interfaces for the Collection framework.The following figure illustrates the hierarchy of the collection framework:
在java.util路径下的包里面包含了集合框架中的所有类和接口。下图展示了集合框架的层级结构:
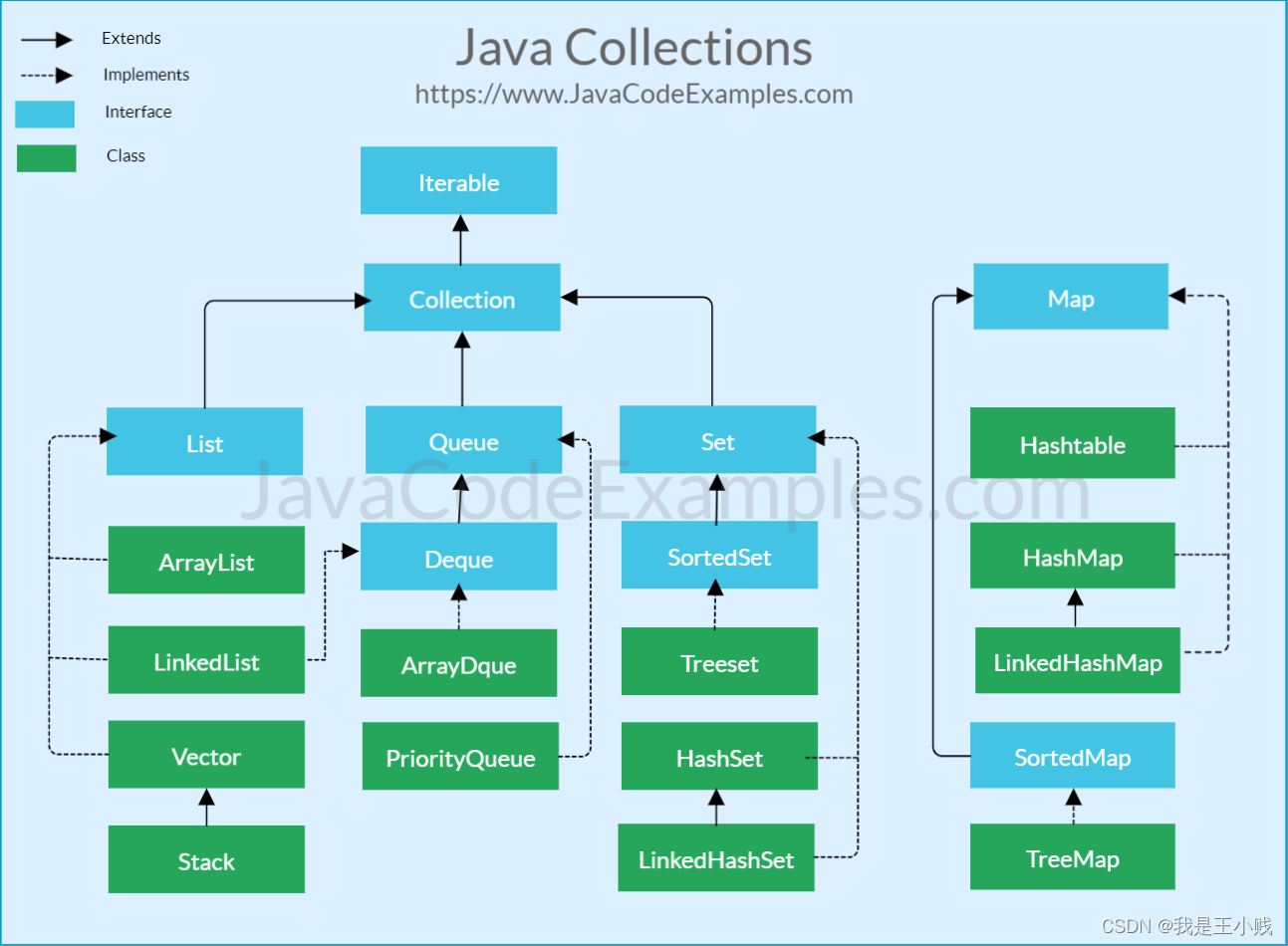
As can be seen from the above collection framework diagram, the Java collection framework mainly includes two types of containers, one is collection, which stores an element collection, and the other is map, which stores key / value pair mappings. The collection interface has three sub types, list, set and queue. Then there are some abstract classes, and finally there are concrete implementation classes. The commonly used ones are ArrayList, LinkedList, HashSet, LinkedHashSet, HashMap, LinkedHashMap, and so on.
从上面的集合框架图可以看出,Java集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图 (Map),存储键/值对映射。Collection 接口又有三个子类型:List、Set 和 Queue。再下面是一些抽象类,最后是具体的实现类。常用的有ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap等。
In addition to Collection, the framework also defines several Map interfaces and classes. Key / value pairs are stored in the Map. Although Map are not Collection, they are fully integrated into collection framework.
除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合框架中。
2. Why
2.1 Advantages of the Collection Framework (集合框架的优点)
Before the Collection Framework(or before JDK 1.2) was introduced, the standard methods for grouping Java objects (or collections) were Arrays or Vectors, or Hashtables. All of these collections had no common interface. Therefore, though the main aim of all the collections is the same, the implementation of all these collections was defined independently and had no correlation among them. And also, it is very difficult for the users to remember all the different methods, syntax, and constructors present in every collection class.
在集合框架引入之前(或JDK1.2之前),对Java对象(或集合)进行分组的标准方法是使用Arrays 、Vectors或Hashtables。所有这些集合都没有公共接口。因此,尽管所有集合的主要目标都相同,但所有集合的实现都是独立定义的,它们之间没有相关性。而且,用户很难记住每个集合类中存在的所有不同方法、语法和构造函数。
Let’s understand this with an example of adding an element in a hashtable and a vector :
可以通过在哈希表和向量中添加元素的示例来理解这一点:
public static void main(String[] args)
{
// Creating instances of the array,vector and hashtable
int arr[] = new int[] { 1, 2, 3, 4 };
Vector<Integer> v = new Vector();
Hashtable<Integer, String> h = new Hashtable();
// Adding the elements into the vector
v.addElement(1);
v.addElement(2);
// Adding the element into the hashtable
h.put(1, "epam");
h.put(2, "epams");
// Array instance creation requires [],while Vector and hastable require ()
// Vector element insertion requires addElement(),but hashtable element insertion requires put()
// Accessing the first element of the array, vector and hashtable
System.out.println(arr[0]);
System.out.println(v.elementAt(0));
System.out.println(h.get(1));
// Array elements are accessed using [],
// vector elements using elementAt()
// and hashtable elements using get()
}
As we can observe, none of these collections(Array, Vector, or Hashtable) implements a standard member access interface, it was very difficult for programmers to write algorithms that can work for all kinds of Collections. Another drawback is that most of the ‘Vector’ methods are final, meaning we cannot extend the ’Vector’ class to implement a similar kind of Collection. Therefore, Java developers decided to come up with a common interface to deal with the above-mentioned problems and introduced the Collection Framework in JDK 1.2 post which both, legacy Vectors and Hashtables were modified to conform to the Collection Framework.
从上面例子可以观察到,这些集合(Array,Vector或Hashtable)都没有实现一个标准的成员访问接口,程序员很难编写可以适用于各种集合的算法。另一个缺点是大多数“Vector”方法都是 final 修饰的,这意味着程序员无法扩展“Vector”类来实现类似结构的集合。因此,Java开发人员决定提出一个通用的接口来处理上述问题,并在JDK 1.2帖子中引入了集合框架,其中,遗留的 Vector 和 Hashtables 都进行了修改以符合集合框架。
Advantages of the Collection Framework: Since the lack of a collection framework gave rise to the above set of disadvantages, the following are the advantages of the collection framework :
集合框架的优点:由于缺乏集合框架导致了上述一组缺点,以下是集合框架的优点:
- Consistent API: The API has a basic set of interfaces like Collection, Set, List, or Map, all the classes (ArrayList, LinkedList, Vector, etc) that implement these interfaces have some common set of methods.
一致的 API:该 API 具有一组基本的接口,如Collection、Set、List、或 Map,实现这些接口的所有类(ArrayList、LinkedList、Vector 等)都有一些通用的方法集。 - Reduces programming effort: A programmer doesn’t have to worry about the design of the Collection but rather he can focus on its best use in his program. Therefore, the basic concept of Object-oriented programming (i.e.) abstraction has been successfully implemented.
减少编程工作:程序员不再担心集合的设计,而是可以专注于它在程序中的最佳用途。因此,面向对象编程(即)抽象的基本概念已经成功实现。 - Increases program speed and quality: Increases performance by providing high-performance implementations of useful data structures and algorithms because in this case, the programmer need not think of the best implementation of a specific data structure. He can simply use the best implementation to drastically boost the performance of his algorithm/program.
提高程序运行速度和质量:通过数据结构和算法的高可用实现来提高性能,因为在这种情况下,程序员不需要考虑特定数据结构的最佳实现。他可以简单地使用最佳实现来大幅提高其算法/程序的性能。
2.2 Difference between Array and ArrayList (Array 和 ArrayList的区别)
The main differences between the Array and ArrayList are given below:
| SN | Array | ArrayList |
|---|---|---|
| 1 | An array is a fixed-length data structure. | ArrayList is a variable-length data structure. It can be resized itself when needed. |
| 2 | It is mandatory to provide the size of an array while initializing it directly or indirectly. | We can create an instance of ArrayList without specifying its size. Java creates ArrayList of default size. |
| 3 | An array can store both objects and primitive type. | We cannot store primitive type in ArrayList. It automatically converts primitive type to object. |
主要区别如下:
| SN | Array | ArrayList |
|---|---|---|
| 1 | 数组是固定长度的数据结构。 | ArrayList 是一个可变长度的数据结构。 它可以在需要时自行调整大小。 |
| 2 | 在直接或间接初始化数组时,必须提供数组的大小。 | 可以创建 ArrayList 的实例而不指定其大小。 Java 创建ArrayList的时候会给一个默认长度10。 |
| 3 | 数组可以存储对象和基本类型。 | 在 ArrayList 中不能存储基本类型。它自动将基本类型转换为对象。 |
2.3 Difference between ArrayList and Vector (ArrayList 和 Vector 的区别)
The main differences between the ArrayList and Vector are given below:
| SN | ArrayList | Vector |
|---|---|---|
| 1 | ArrayList is not synchronized. | Vector is synchronized. |
| 2 | ArrayList is not a legacy class. | Vector is a legacy class. |
| 3 | ArrayList increases its size by 50% of the array size. | Vector increases its size by doubling the array size. |
| 4 | ArrayList is not thread-safe as it is not synchronized. | Vector list is thread-safe as it’s every method is synchronized. All vector methods have synchronized modifier. However, for composite operations, vector still needs to be synchronized. |
主要区别如下:
| SN | ArrayList | Vector |
|---|---|---|
| 1 | ArrayList未同步 | Vector是同步的 |
| 2 | ArrayList不是传统类 | Vector是遗留类 |
| 3 | ArrayList扩容长度增加1.5倍 | Vector扩容长度2倍 |
| 4 | ArrayList不是线程安全的 | Vector是线程安全的。在每个方法上面加了synchronized关键词,但是对于复合操作还需要整体加锁。 |
3. How
3.1 What is the difference between List, Set, and Map (List、Set、Map的区别)
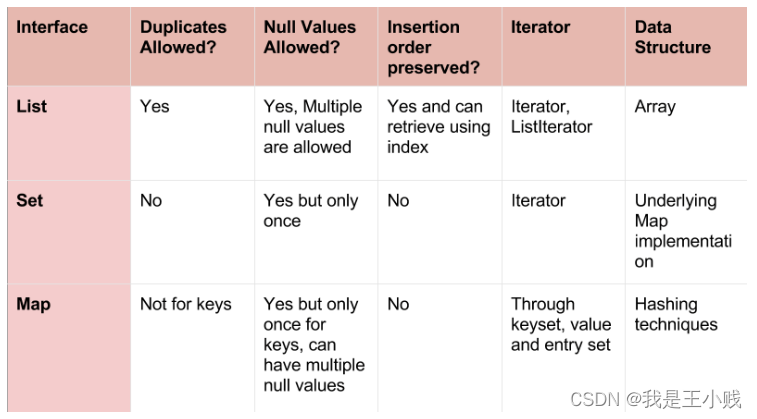
| 接口 | 是否允许重复对象? | 允许空值? | 是否可排序? | 迭代器 | 数据结构 |
|---|---|---|---|---|---|
| List | 允许 | 允许多个空值 | 可排序,可通过索引查到 | Iterator,ListIterator | 数组 |
| Set | 不允许 | 允许仅一个空值 | 不可以 | Iterator | 底层用Map实现 |
| Map | key不允许 | 允许Key一个空值,value多个空值 | 不可以 | 通过keyset、value和entry set | 用Hash实现 |
3.2 ArrayList
ArrayList class is an array that can have dynamic size. The difference from an ordinary array is that it has no fixed size limit, and we can add or delete elements.
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
ArrayList extands AbstractList,implement List interface.
ArrayList 继承了 AbstractList ,并实现了 List 接口。
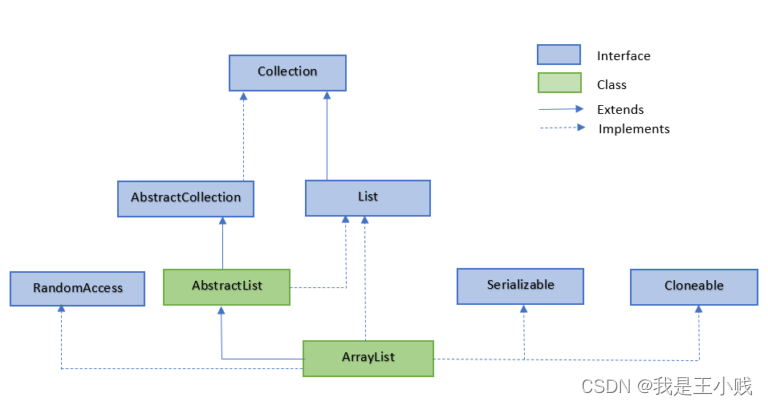
ArrayList class in java.util package, it needs to be imported before use, this is a demo:
ArrayList 类位于 java.util 包中,使用前需要引入它,语法格式如下:
import java.util.ArrayList;
ArrayList<E> objectName =new ArrayList<>();
- Generic data type, used to set the data type of objectName, can only be a reference data type.
- E: 泛型数据类型,用于设置 objectName 的数据类型,只能为引用数据类型。
- objectName: 对象名。
3.2.1 Difference between ArrayList and LinkedList (ArrayList和LinkedList的区别)
| SN | ArrayList | LinkedList |
|---|---|---|
| 1 | ArrayList uses a dynamic array. | LinkedList uses a doubly linked list. |
| 2 | ArrayList is better to store and fetch data. | LinkedList is better to manipulate data. |
| 3 | ArrayList provides random access. | LinkedList does not provide random access. |
| 4 | ArrayList takes less memory overhead as it stores only object address | LinkedList takes more memory overhead, as it stores the address of that object as well as the address of pre and next node. |
| SN | ArrayList | LinkedList |
|---|---|---|
| 1 | ArrayList 使用动态数组 | LinkedList使用双链表 |
| 2 | ArrayList 更适合存储和查找数据 | LinkedList更适合操作数据 |
| 3 | ArrayList 提供了随机访问 | LinkedList不提供随机访问 |
| 4 | ArrayList 只存储对象地址 | LinkedList存储当前节点对象地址和前后节点的地址,内存开销较大 |
3.2.3 Synchronize ArrayList (同步ArrayList)
We can synchronize ArrayList in two ways.
有两种方式用来同步ArrayList :
- Using Collections.synchronizedList() method
List<String> namesList = Collections.synchronizedList(new ArrayList<String>());
//List methods are synchronized
namesList.add("Alex");
namesList.add("Brian");
//Use explicit synchronization while iterating
synchronized(namesList)
{
Iterator<String> iterator = namesList.iterator();
while (iterator.hasNext())
{
System.out.println(iterator.next());
}
}
- Using CopyOnWriteArrayList
CopyOnWriteArrayList<String> namesList = new CopyOnWriteArrayList<String>();
//List methods are synchronized
namesList.add("Alex");
namesList.add("Brian");
//No explicit synchronization is needed during iteration
Iterator<String> iterator = namesList.iterator();
while (iterator.hasNext())
{
System.out.println(iterator.next());
}
3.2.4 Dynamic sizing of ArrayList (ArrayList扩容机制)
private Object[] grow(int minCapacity) {
// Get the old capacity, which is the current capacity
// 获取老容量,也就是当前容量
int oldCapacity = elementData.length;
// If the current capacity is greater than 0 or the array is not DEFAULTCAPACITY_EMPTY_ELEMENTDATA
// 如果当前容量大于0 或者 数组不是DEFAULTCAPACITY_EMPTY_ELEMENTDATA
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
//If the array is DEFAULTCAPACITY_EMPTY_ELEMENTDATA (if the capacity is equal to 0, this is the only case left)
// 如果 数组是DEFAULTCAPACITY_EMPTY_ELEMENTDATA(容量等于0的话,只剩这一种情况了)
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
Let’s take a look at the operation in if, first create a new array, then copy the old array to the new array and assign it to elementData to return. The purpose of the ArraysSupport.newLength function is to create an array of size oldCapacity + max(minimum growth, preferred growth).
MinCapacity is an incoming parameter. As we have seen above, its value is the current capacity (old capacity) + 1, then the value of minCapacity - oldCapacity is always 1, and the value of minimum growth is always 1.
The function of oldCapacity >> 1 is to perform bit operation on oldCapacity and shift it by one bit to the right, which is halved, and the value of preferred growth is half of the size of oldCapacity.
我们来看一下if里面的操作,先创建一个新的数组,然后将旧数组拷贝到新数组并赋给elementData返回。ArraysSupport.newLength函数的作用是创建一个大小为oldCapacity + max(minimum growth, preferred growth)的数组。
minCapacity是传入的参数,我们上面看过,它的值是当前容量(老容量)+1,那么minCapacity - oldCapacity的值就恒为1,minimum growth的值也就恒为1。
oldCapacity >> 1的功能是将oldCapacity 进行位运算,右移一位,也就是减半,preferred growth的值即为oldCapacity大小的一半。
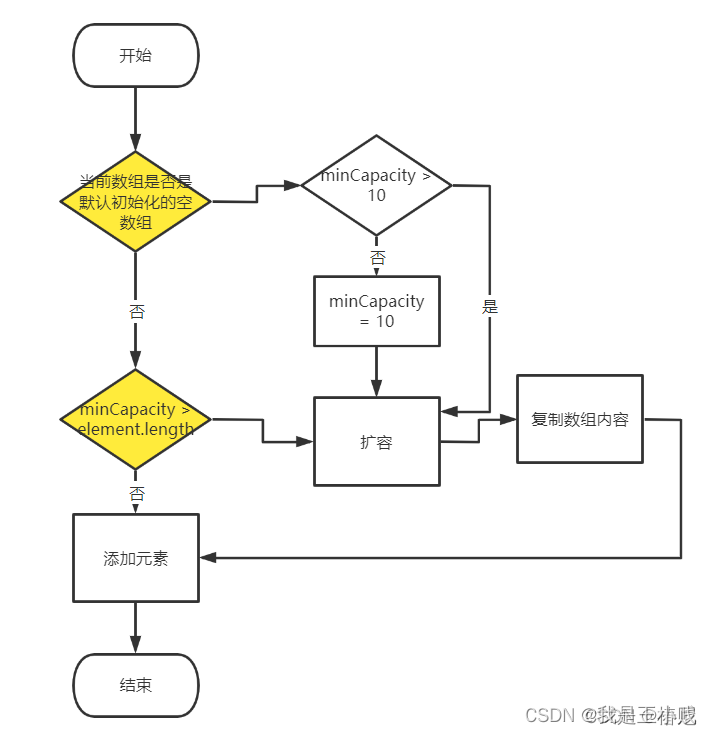
Summarize:
- After jdk1.8 “the default initialized capacity of ArrayList is 10”, but the capacity is actually assigned to 10 when the first element is added. In jdk1.7, the default initialization capacity is indeed 10.
- When is the expansion mechanism of ArrayList triggered? Fired when the elements in the collection exceed the original capacity.
- The expansion factor of ArrayList is 1.5, and the expansion is 1.5 times of the original.
总结:
- jdk1.8之后“ArrayList的默认初始化容量是10”,但是是在添加第一个元素时才真正将容量赋值为10。而在jdk1.7中默认初始化容量确实是10。
- ArrayList的扩容机制在什么时候触发?是在集合中的元素超过原来的容量时触发。
- ArrayList的扩容因子是1.5,扩容为原来的1.5倍。
A simple flowchart is attached:
附一张简易的流程图:
3.3 LinkedList
LinkedList uses a linked list structure to store data, which is very suitable for dynamic insertion and deletion of data, yet the speed of random access and traversal is relatively slow.
In addition, it also provides methods that are not defined in the List interface, which are specially used to operate the header and footer elements, which can be used as stacks, queues and bidirectional queues.
LinkedList 是用链表结构存储数据的,很适合数据的动态插入和删除,但是随机访问和遍历速度比较慢。
另外,他还提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
3.4 Set
Set pays attention to the unique property. The system set is used to store unordered (the order of storage and retrieval is not necessarily the same) elements, and the values cannot be repeated. The equality of objects is essentially determined by the hashCode value of the object (java calculates the serial number based on the memory address of the object). If you want two different objects to be considered equal, you must override the hashCode method and the equals method of Object.
Set 注重独一无二的性质,该体系集合用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。对象的相等性本质是对象 hashCode 值(java 是依据对象的内存地址计算出的此序号)判断的,如果想要让两个不同的对象视为相等的,就必须覆盖 Object 的 hashCode 方法和 equals 方法。
3.4.1 HashSet (Hash 表)
The hash table stores the hash value. The order of HashSet storage elements is not according to the order of storage (obviously different from List) but according to the hash value, so the data is also taken according to the hash value.
The hash value of the element is obtained by the hashcode method of the element. HashSet first judges the hash
value of the two elements. If the hash value is the same, then the equals method is compared. If the result of equls is true, the HashSet is regarded as the same element. If equals is false then it is not the same element.
How are elements with the same hash value equals false stored, that is, they are extended under the same hash value (it can be considered that elements with the same hash value are placed in a hash bucket). That is, a column is stored like a hash. Figure 1 shows the case where the hashCode values are not the same; Figure 2 shows the case where the hashCode values are the same but the equals are not the same.
哈希表里存放的是哈希值。HashSet 存储元素的顺序并不是按照存入时的顺序(和 List 显然不同)而是按照哈希值来存的,所以取数据也是按照哈希值取的。
元素的哈希值是通过元素的hashcode 方法来获取的, HashSet 首先判断两个元素的哈希值,如果哈希值一样,接着会比较 equals 方法,如果 equls 结果为true ,HashSet 就视为同一个元素。如果 equals 为 false 就不是同一个元素。
哈希值相同 equals 为 false 的元素是怎么存储呢, 就是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中)。也就是哈希一样的存一列。如图1 表示 hashCode 值不相同的情况;图2 表示hashCode 值相同,但 equals 不相同的情况。
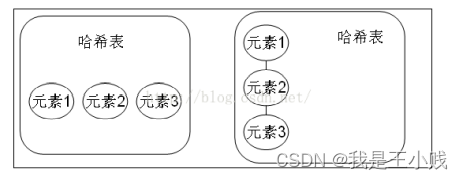
Difference between HashMap and HashSet (HashMap 和 HashSet 的区别)
The bottom layer of HashSet is based on HashMap. (The source code of HashSet is very small, because except for clone() , writeObject() , readObject() which HashSet has to implement by itself, other methods directly call the methods in HashMap.
HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常少,因为除了 clone() 、 writeObject() 、 readObject() 是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
| HashMap | HashSet |
|---|---|
| Implements the Map interface | Implements the Set interface |
| Store key-value pairs | only store objects |
| Use put() to add elements to the Map | Use add() to add elements to the Set |
| HashMap uses key to calculate hashcode | HashSet uses the member object to calculate the hashcode value, the hashcode may be the same for two objects, so use the equals() method to determine whether the objects are equal |

How HashSet checks for duplicates? HashSet 如何检查重复
When you add an object to a HashSet, the HashSet will first calculate the hashcode value of the object to determine where the object is added, and will also compare it with the hashcode values of other added objects. If there is no matching hashcode, HashSet will assume that the object is not repeated. But if objects with the same hashcode value are found, the equals() method will be called to check whether the objects with equal hashcodes are really the same. If the two are the same, the HashSet will not let the join operation succeed.
当你把对象加⼊ HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加⼊的位置,同时也会与其他加入的对象的hashcode值作比较。如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调⽤ equals() 方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
The relevant contracts of hashCode() and equals():
- If two objects are equal, the hashcode must also be the same
- Two objects are equal, return true for both equals methods
- Two objects have the same hashcode value, they are not necessarily equal
- To sum up, if the equals method has been overridden, the hashCode method must also be overridden
hashCode() 与equals() 的相关契约:
- 如果两个对象相等,则hashcode⼀定也是相同的
- 两个对象相等,对两个equals方法返回true
- 两个对象有相同的hashcode值,它们也不⼀定是相等的
- 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
- hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两
个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
Difference between == and equals
- == is to determine whether two variables or instances point to the same memory space, and equals is to determine the internal memory pointed to by two variables or instances.
Is the value of the storage space the same? - == refers to comparing memory addresses, and equals() compares the contents of strings
- == refers to whether the references are the same, and equals() refers to whether the values are the same
== 与 equals 的区别
- ==是判断两个变量或实例是不是指向同⼀个内存空间,equals是判断两个变量或实例所指向的内
存空间的值是不是相同 - ==是指对内存地址进行比较,equals()是对字符串的内容进行比较
- ==指引用是否相同,equals()指的是值是否相同
3.4.2 TreeSet (红黑树)
- TreeSet is implemented with TreeMap. The bottom layer is to use the principle of red-black tree to sort the objects of the new add() according to the specified order (ascending order, descending order).
- Both Integer and String objects can be sorted by default TreeSet, but objects of custom classes are not allowed. The class defined by yourself must implement the Comparable interface and override the corresponding compareTo() function before it can be used normally.
- When overriding the compare() function, return the corresponding value so that the TreeSet can be sorted according to certain rules.
- Compare the order of this object with the specified object. If the object is less than, equal to, or greater than the specified object, returns a negative integer, zero, or a positive integer, respectively.
- TreeSet是用TreeMap实现的。底层是使用红黑树的原理对新 add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
- Integer 和 String 对象都可以进行默认的 TreeSet 排序,而自定义类的对象是不可以的,自己定义的类必须实现 Comparable 接口,并且覆写相应的 compareTo()函数,才可以正常使用。
- 在覆写 compare()函数时,要返回相应的值才能使 TreeSet 按照一定的规则来排序。
- 比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
3.4.3 LinkedHashSet(HashSet+LinkedHashMap)
For LinkedHashSet, it inherits from HashSet and is implemented based on LinkedHashMap. The bottom layer of LinkedHashSet uses LinkedHashMap to save all elements. It inherits from HashSet, and all its methods and operations are the same as HashSet. Therefore, the implementation of LinkedHashSet is very simple, only four construction methods are provided, and the parent is called by passing an identification parameter. The constructor of the class, the bottom layer constructs a LinkedHashMap to realize, the operation is the same as the operation of the parent class HashSet, you can directly call the method of the parent class HashSet.
对于 LinkedHashSet 而言,它继承与 HashSet、又基于 LinkedHashMap 来实现的。LinkedHashSet底层使用 LinkedHashMap 来保存所有元素,它继承与 HashSet,其所有的方法操作上又与 HashSet 相同,因此 LinkedHashSet 的实现上非常简单,只提供了四个构造方法,并通过传递一个标识参数,调用父类的构造器,底层构造一个 LinkedHashMap 来实现,在相关操作上与父类 HashSet 的操作相同,直接调用父类 HashSet 的方法即可。
3.5 Map
3.5.1. HashMap(数组+链表+红黑树)
HashMap stores data according to the hashCode value of the key. In most cases, its value can be directly located, so it has a fast access speed, but the traversal order is uncertain. HashMap only allows the key of at most one record to be null, and allows the value of multiple records to be null.
HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap 最多只允许一条记录的键为 null,允许多条记录的值为null。
HashMap is not thread-safe, that is, multiple threads can write HashMap at the same time at any time, which may lead to data inconsistency. If you need to meet thread safety, you can use the synchronizedMap method of Collections to make HashMap thread-safe, or use ConcurrentHashMap.
HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。
We use the following picture to introduce the structure of HashMap:
我们用下面这张图来介绍HashMap 的结构:
3.5.1.1 JAVA7 实现
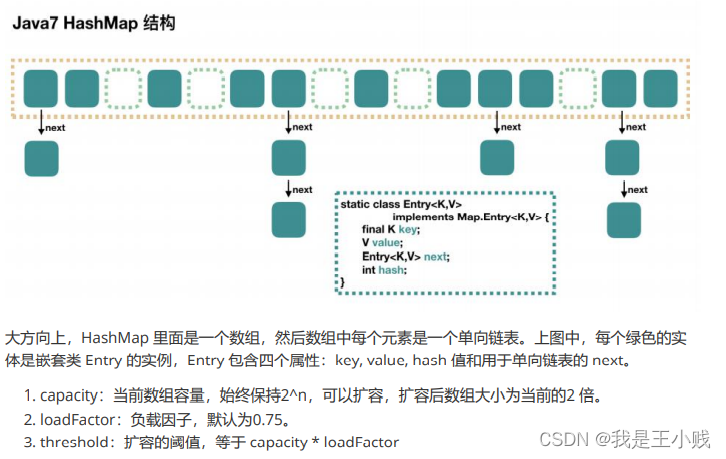
3.5.1.2 JAVA8 实现
Java8 has made some modifications to HashMap. The biggest difference is that it uses a red-black tree, so it consists of an array + a linked list + a red-black tree.
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由数组+链表+红黑树组成。
According to the introduction of Java7 HashMap, we know that when searching, we can quickly locate the specific subscript of the array according to the hash value, but after that, we need to compare the linked list one by one to find what we need. The time complexity depends on The length of the linked list is O(n). In order to reduce the overhead of this part, in Java8, when the number of elements in the linked list exceeds 8, the linked list will be converted into a red-black tree, and the time complexity can be reduced to O(logN) when searching at these positions.
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
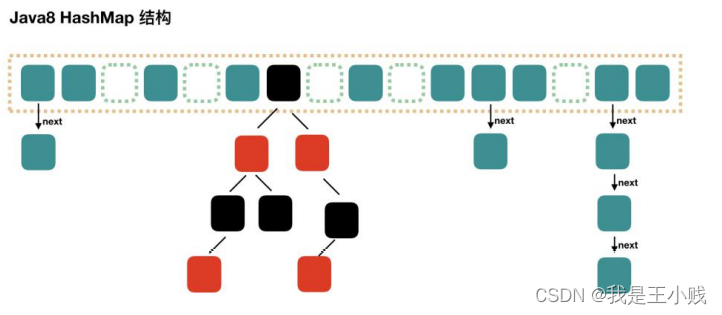
3.5.2 ConcurrentHashMap
3.5.2.1 Segment (段)
ConcurrentHashMap and HashMap have similar ideas, but because it supports concurrent operations, it is a bit more complicated. The entire ConcurrentHashMap consists of segments, and Segment means “part” or “segment”, so it will be described as a segment lock in many places. Note that in the text, I use “slot” in many places to represent a segment.
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个segment。
3.5.2.2 Thread safety (Segment inherits ReentrantLock for locking) 线程安全(Segment继承 ReentrantLock 加锁)
A simple understanding is that ConcurrentHashMap is an array of Segments, and Segments are locked by inheriting ReentrantLock, so each operation that needs to be locked locks a segment, so as long as each Segment is guaranteed to be thread-safe, the global thread safety.
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
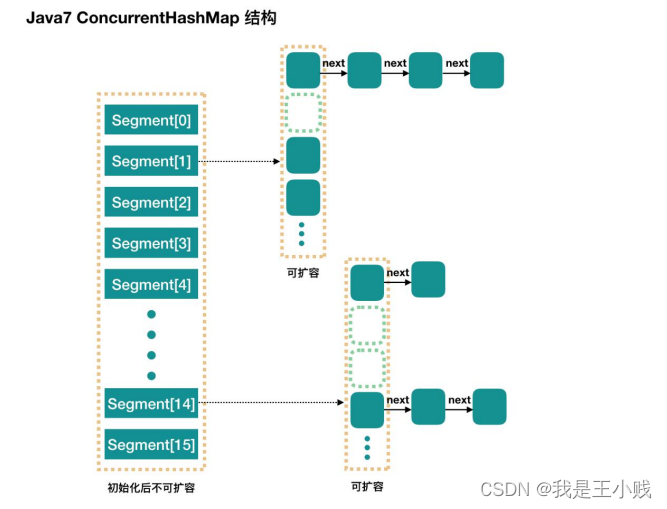
3.5.2.3. Degree of parallelism (default 16) 并行度(默认16)
concurrencyLevel: parallelism level, concurrency, number of segments, the default is 16, that is to say, ConcurrentHashMap has 16 segments, so theoretically, at this time, up to 16 threads can simultaneously write concurrently, as long as their operations are distributed in different Segment on. This value can be set to other values during initialization, but once initialized, it cannot be expanded. To be specific inside each Segment, in fact, each Segment is very similar to the HashMap introduced earlier, but it needs to ensure thread safety, so it is more troublesome to process.
concurrencyLevel:并行级别、并发数、Segment 数,默认是16,也就是说 ConcurrentHashMap 有16 个 Segments,所以理论上,这个时候,最多可以同时支持16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
3.5.2.4 Java8 implementation (red-black tree introduced) Java8 实现(引入了红黑树)
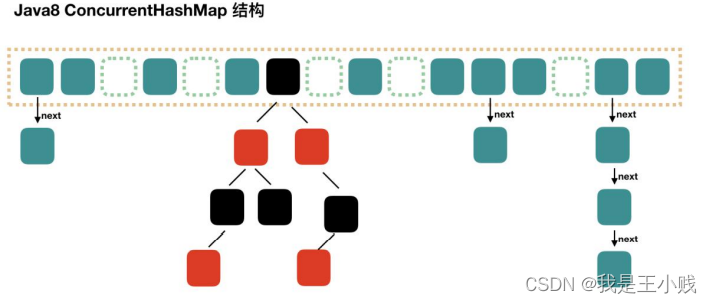
3.5.3. Difference between ConcurrentHashMap and Hashtable?ConcurrentHashMap 和 Hashtable 的区别
The difference between ConcurrentHashMap and Hashtable is mainly reflected in the way to achieve thread safety.
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。

3.5.4. TreeMap(Sortable 可排序)
TreeMap implements the SortedMap interface, which can sort the records it saves according to the key. The default is to sort in ascending order of the key value. You can also specify the sort comparator. When iterator is used to traverse the TreeMap, the obtained records are sorted. If using sorted maps, TreeMap is recommended. When using TreeMap, the key must implement the Comparable interface or pass in a custom Comparator when constructing the TreeMap, otherwise an exception of type java.lang.ClassCastException will be thrown at runtime.
TreeMap 实现 SortedMap 接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用 Iterator 遍历 TreeMap 时,得到的记录是排过序的。如果使用排序的映射,建议使用 TreeMap。在使用 TreeMap 时,key 必须实现 Comparable 接口或者在构造 TreeMap 传入自定义的Comparator,否则会在运行时抛出 java.lang.ClassCastException 类型的异常。
3.5.5. LinkedHashMap(record insertion order 记录插入顺序)
LinkedHashMap is a subclass of HashMap, which saves the insertion order of records. When using Iterator to traverse LinkedHashMap, the first record must be inserted first, or it can be constructed with parameters and sorted according to the access order.
LinkedHashMap 是 HashMap 的一个子类,保存了记录的插入顺序,在用 Iterator 遍历LinkedHashMap 时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
3.6 Queue
3.6.1 PriorityQueue
PriorityQueue is a priority-based unbounded priority queue. The elements of the priority queue are sorted according to their natural order, or according to the Comparator provided when constructing the queue, depending on the construction method used.
PriorityQueue 是一个基于优先级的无界优先级队列。优先级队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序,具体取决于所使用的构造方法。
The queue does not allow null elements nor insertion of incomparable objects (objects that do not implement the Comparable interface).
该队列不允许使用 null 元素也不允许插入不可比较的对象(没有实现Comparable接口的对象)。
The head of the PriorityQueue queue refers to the element with the smallest ordering rule. If multiple elements are the minimum value, one is randomly selected.
PriorityQueue 队列的头指排序规则最小那个元素。如果多个元素都是最小值则随机选一个。
PriorityQueue is an unbounded queue, but the initial capacity (actually an Object[]) will automatically expand as elements are added to the priority queue, without specifying the details of the capacity increase strategy.
PriorityQueue 是一个无界队列,但是初始的容量(实际是一个Object[]),随着不断向优先级队列添加元素,其容量会自动扩容,无需指定容量增加策略的细节。
The use of PriorityQueue is the same as that of ordinary queues, the only difference is that PriorityQueue will decide who is at the head of the queue and who is at the end of the queue according to the sorting rules. By default, PriorityQueue uses the natural ordering method, with the smallest element dequeued first.
PriorityQueue使用跟普通队列一样,唯一区别是PriorityQueue会根据排序规则决定谁在队头,谁在队尾。默认情况下PriorityQueue使用自然排序法,最小元素先出列。
PriorityQueue priority rules can be customized by us according to specific needs, there are 2 ways:
PriorityQueue优先级规则可以由我们根据具体需求而定制, 方式有2种:
- Add the element itself to implement the Comparable interface to ensure that the element is a sortable object
添加元素自身实现了Comparable接口,确保元素是可排序的对象 - If the added element does not implement the Comparable interface, the comparator can be specified directly when creating the PriorityQueue queue.
如果添加元素没有实现Comparable接口,可以在创建PriorityQueue队列时直接指定比较器。
PriorityQueue is an unbounded, thread-unsafe queue. It is a queue implemented by an array and has a priority. The elements stored in the PriorityQueue must be comparable objects, if not, the comparator must be specified explicitly.
PriorityQueue是一种无界的,线程不安全的队列。是一种通过数组实现的,并拥有优先级的队列。PriorityQueue存储的元素要求必须是可比较的对象, 如果不是就必须明确指定比较器。
3.6.2 BlockingQueue
BlockingQueue is actually a blocking queue, which is a thread-safe queue based on a blocking mechanism. The implementation of the blocking mechanism is to avoid concurrent operations by adding locks when enqueuing and dequeuing.
BlockingQueue其实就是阻塞队列,是基于阻塞机制实现的线程安全的队列。而阻塞机制的实现是通过在入队和出队时加锁的方式避免并发操作。
The main difference between BlockingQueue and ordinary Queue is:
BlockingQueue不同于普通的Queue的区别主要是:
- The thread safety of the queue is guaranteed by locking when entering and exiting the queue.
通过在入队和出队时进行加锁,保证了队列线程安全。 - Supports blocking enqueue and dequeue methods: when the queue is full, the enqueued thread will be blocked until the queue is full; when the queue is empty, the dequeued thread will be blocked until there are elements in the queue.
支持阻塞的入队和出队方法:当队列满时,会阻塞入队的线程,直到队列不满;当队列为空时,会阻塞出队的线程,直到队列中有元素。
BlockingQueue is often used in the producer-consumer model. The producer adds elements to the queue, and the consumer gets elements from the queue; usually, the producer and the consumer are composed of multiple threads.
BlockingQueue常用于生产者-消费者模型中,往队列里添加元素的是生产者,从队列中获取元素的是消费者;通常情况下生产者和消费者都是由多个线程组成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9jkKSZ7Q-1666593763709)(/.attachments/image-7fe4ef7a-324c-4693-bb37-869b7323f12a.png)]
In addition to throwing exceptions and returning specific values, BlockingQueue also provides two types of blocking methods: one is to block when the queue has no space/element until there is space/element; the other is to block when there is no space/element in the queue; A specific time to try to enqueue/dequeue, the waiting time can be customized.
除了抛出异常和返回特定值方法与Queue接口定义相同外,BlockingQueue还提供了两类阻塞方法:一种是当队列没有空间/元素时一直阻塞,直到有空间/有元素;另一种是在特定的时间尝试入队/出队,等待时间可以自定义。
3.6.2.1 ArrayBlockingQueue
ArrayBlockingQueue is an array-based blocking queue that uses an array to store data and needs to specify its length, so it is a bounded queue.
ArrayBlockingQueue是基于数组的阻塞队列,使用数组存储数据,并需要指定其长度,所以是一个有界队列。
Here is a simple example of ArrayBlockingQueue:
下面是ArrayBlockingQueue的一个简单示例:
public void testArrayBlockingQueue() throws InterruptedException {
// 创建ArrayBlockingQueue实例,设置队列大小为10
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10);
boolean r1 = queue.add(1); // 使用add方法入队元素,如果无空间则抛出异常
boolean r2 = queue.offer(2); // 使用offer方法入队元素
queue.put(3); // 使用put方法入队元素;如果无空间则会一直阻塞
boolean r3 = queue.offer(4, 30, TimeUnit.SECONDS); // 使用offer方法入队元素;如果无空间则会等待30s
Integer o1 = queue.remove(); // 使用remove方法出队元素,如果无元素则抛出异常
Integer o2 = queue.poll(); // 使用poll方法出队元素
Integer o3 = queue.take(); // 使用take方法出队元素;如果无元素则一直阻塞
Integer o4 = queue.poll(10, TimeUnit.SECONDS); // 使用poll方法出队元素; 如果无空间则等待10s
}
- ArrayBlockingQueue is a bounded blocking queue, and its capacity needs to be specified during initialization.
ArrayBlockingQueue是一个有界阻塞队列,初始化时需要指定容量大小。 - When used in the producer-consumer model, if the production speed and consumption speed basically match, using ArrayBlockingQueue is a good choice; when the production speed is much greater than the consumption speed, the queue will be filled, and a large number of production threads will be blocked. block.
在生产者-消费者模型中使用时,如果生产速度和消费速度基本匹配的情况下,使用ArrayBlockingQueue是个不错选择;当如果生产速度远远大于消费速度,则会导致队列填满,大量生产线程被阻塞。 - The exclusive lock ReentrantLock is used to achieve thread safety. The same lock object is used for enqueue and dequeue operations, that is, only one thread can perform enqueue or dequeue operations; this means that producers and consumers cannot operate in parallel. It will become a performance bottleneck in high concurrency scenarios.
使用独占锁ReentrantLock实现线程安全,入队和出队操作使用同一个锁对象,也就是只能有一个线程可以进行入队或者出队操作;这也就意味着生产者和消费者无法并行操作,在高并发场景下会成为性能瓶颈。
For the specific source code of ArrayBlockingQueue, please refer to this article:
ArrayBlockingQueue 具体源码可参考这篇文章:
https://juejin.cn/post/6999798721269465102
3.6.2.2 ArrayBlockingQueue 与 LinkedBlockingQueue 的区别
Same point:
Both ArrayBlockingQueue and LinkedBlockingQueue implement blockable insertion and deletion of elements through the condition notification mechanism, and meet the characteristics of thread safety;
相同点:
ArrayBlockingQueue 和 LinkedBlockingQueue 都是通过 condition 通知机制来实现可阻塞式插入和删除元素,并满足线程安全的特性;
difference:
- The bottom layer of ArrayBlockingQueue is implemented with an array, while LinkedBlockingQueue is implemented with a linked list data structure;
- ArrayBlockingQueue uses only one lock to insert and delete data, while LinkedBlockingQueue uses putLock and takeLock respectively for insertion and deletion, which can reduce the possibility of threads entering the WAITING state because the thread cannot acquire the lock, thereby improving the Efficiency of concurrent execution of threads.
不同点:
- ArrayBlockingQueue 底层是采用的数组进行实现,而 LinkedBlockingQueue 则是采用链表数据结构;
- ArrayBlockingQueue 插入和删除数据,只采用了一个 lock,而 LinkedBlockingQueue 则是在插入和删除分别采用了putLock和takeLock,这样可以降低线程由于线程无法获取到 lock 而进入 WAITING 状态的可能性,从而提高了线程并发执行的效率。
For the specific source code of LinkedBlockingQueue, please refer to this article:
LinkedBlockingQueue 具体源码可参考这篇文章:
https://juejin.cn/post/6844904019559710727
3.6.3 CopyOnWriteArrayList
CopyOnWriteArrayList is very efficient in the case of many queries and few modification operations, which can not only ensure thread safety, but also have good efficiency. However, if there are many modification operations, it will lead to frequent copying of the array, and the efficiency will decrease.
CopyOnWriteArrayList在查询多,修改操作少的情况下效率是非常可观的,既能够保证线程安全,又能有不错的效率。但是如果修改操作较多,就会导致数组频繁的copy,效率就会有所下降。
Why CopyOnWriteArrayList can guarantee thread safety:
- Lock when doing modification operations
- Each modification is to copy the elements to a new array, and assign the array to the member variable array.
- Use the volatile keyword to modify the member variable array, so that the visibility of the array reference can be guaranteed, and the latest array reference can be obtained before each modification.
CopyOnWriteArrayList为什么能够保证线程安全:
- 在做修改操作的时候加锁
- 每次修改都是将元素copy到一个新的数组中,并且将数组赋值到成员变量array中。
- 利用volatile关键字修饰成员变量array,这样就可以保证array的引用的可见性,每次修改之前都能够拿到最新的array引用。
3.7 DualPivotQuicksort 双轴快排算法
DualPivotQuicksort is the default sorting algorithm for Collections.
The dual axis is to select two main elements to ideally divide the interval into 3 parts, so that not only can the number of elements increase to 2 each time, but the divided interval changes from the original two to three. The worst case is The left and right are the same size and both are the largest or the smallest, but the probability of this is much lower than that of the largest or the smallest, so the optimization of the dual-axis quick release is still quite large.
双轴快排算法是集合默认的排序算法。
双轴就是选取两个主元素理想将区间划为3部分,这样不仅每次能够确定元素个数增多为2个,划分的区间由原来的两个变成三个,最坏最坏的情况就是左右同大小并且都是最大或者最小,但这样的概率相比一个最大或者最小还是低很多很多,所以双轴快排的优化力度还是挺大的。
First of all, in the initial situation, we select the leftmost and rightmost two values in the interval to be sorted as pivot1 and pivot2. exist as two axes. At the same time, we will process the leftmost and rightmost data of the array in advance and put the smallest on the left. So pivot1 < pivot2.
首先在初始的情况我们是选取待排序区间内最左侧、最右侧的两个数值作为pivot1和pivot2。作为两个轴的存在。同时我们会提前处理数组最左侧和最右侧的数据会比较将最小的放在左侧。所以pivot1<pivot2。
The final goal of the current round is that those smaller than privot1 are on the left side of privot1, those larger than privot2 are on the right side of privot2, and those between privot1 and privot2 are in the middle.
而当前这一轮的最终目标是,比privot1小的在privot1左侧,比privot2大的在privot2右侧,在privot1和privot2之间的在中间。
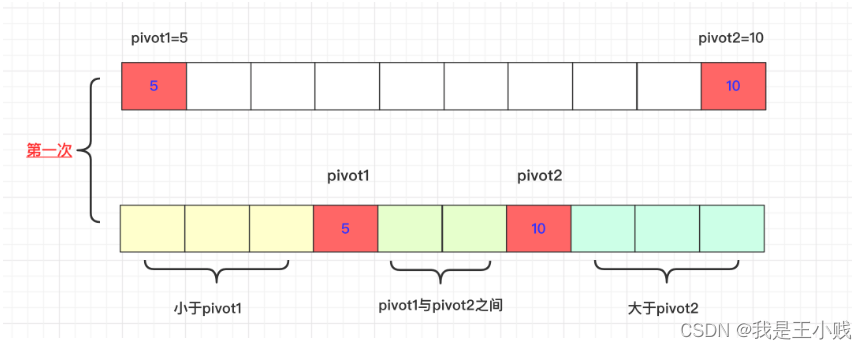
After doing this once, recursively carry out the next dual-axis quicksort until the end, but how to deal with the analysis in this execution process? How many parameters are needed?
这样进行一次后递归的进行下一次双轴快排,一直到结束,但是在这个执行过程应该去如何处理分析呢?需要几个参数呢?
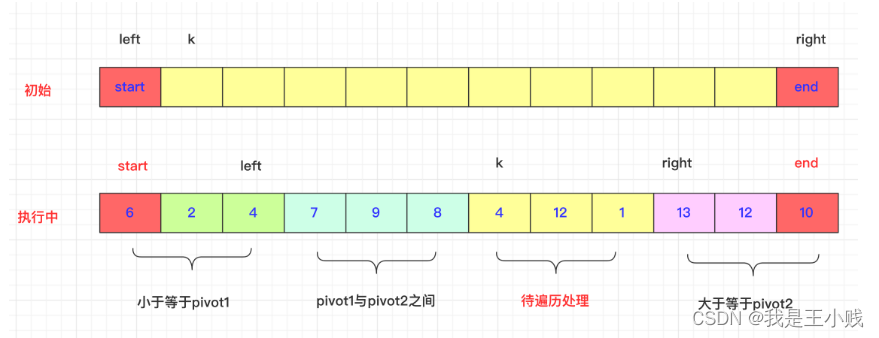
- Suppose the sorting interval [start, end] is known. The array is arr, pivot1=arr[start], pivot2=arr[end]
假设知道排序区间[start,end]。数组为arr, pivot1=arr[start],pivot2=arr[end] - Three parameters left, right and k are also required.
还需要三个参数left,right和k。 - The initial left is start, and the [start, left] area is the area smaller than or equal to pivot1 (the first one is equal to).
left初始为start,[start,left]区域即为小于等于pivot1小的区域(第一个等于)。 - Right corresponds to left, the initial is end, and [right, end] is the area greater than or equal to pivot2 (the last one is equal to).
right与left对应,初始为end,[right,end]为大于等于pivot2的区域(最后一个等于)。 - The initial value of k is start+1, which is a pointer traversed from left to right. The traversed value is properly exchanged with pivot1 and pivot2. When k>=right, it can be stopped.
k初始为start+1,是一个从左往右遍历的指针,遍历的数值与pivot1,pivot2比较进行适当交换,当k>=right即可停止。
k交换过程
First, K is in the middle of left and right, traverse the position of k and compare it with pivot1 and pivot2:
首先K是在left和right中间的,遍历k的位置和pivot1,pivot2进行比较:
If arr[k]<pivot1, then ++left first, then swap(arr,k,left), because the initial start does not move before the end of the process. then k++; continue
如果arr[k]<pivot1,那么先++left,然后swap(arr,k,left),因为初始在start在这个过程不结束start先不动。然后k++;继续进行
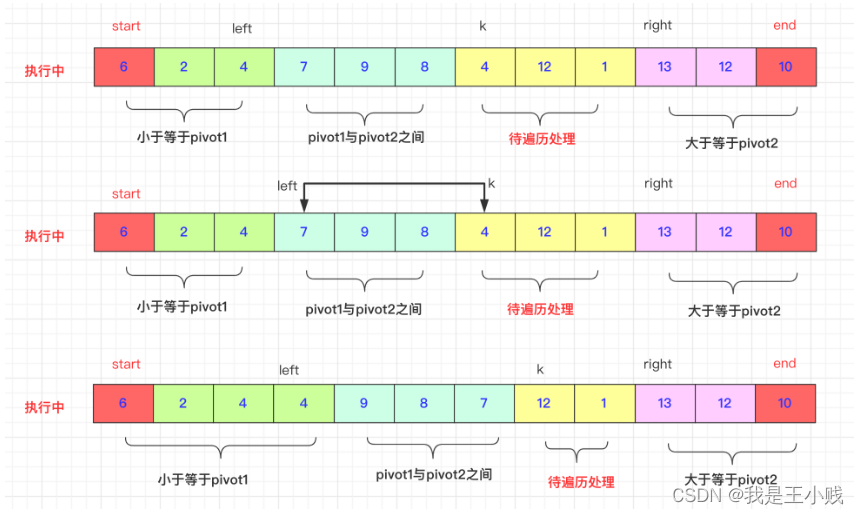
And if arr[k]>pivot2. (the interval can be arranged by yourself), the difference is that the right may be continuously greater than arr[k], such as 9 3 3 9 7 If we need to skip 9 to 3 in front of 7 to exchange normally, This is consistent with the exchange idea of quicksort. Of course, the specific implementation is right–to a suitable position smaller than arr[k]. Then swap(arr,k,right)** Remember that k cannot be added by itself at this time. **Because the one with exchange may be smaller than pivot1 and exchange with left.
而如果arr[k]>pivot2.(区间自行安排即可)有点区别的就是right可能连续的大于arr[k],比如9 3 3 9 7如果我们需要跳过7前面9到3才能正常交换,这和快排的交换思想一致,当然再具体的实现上就是right–到一个合适比arr[k]小的位置。然后swap(arr,k,right)**切记此时k不能自加。**因为带交换的那个有可能比pivot1还小要和left交换。
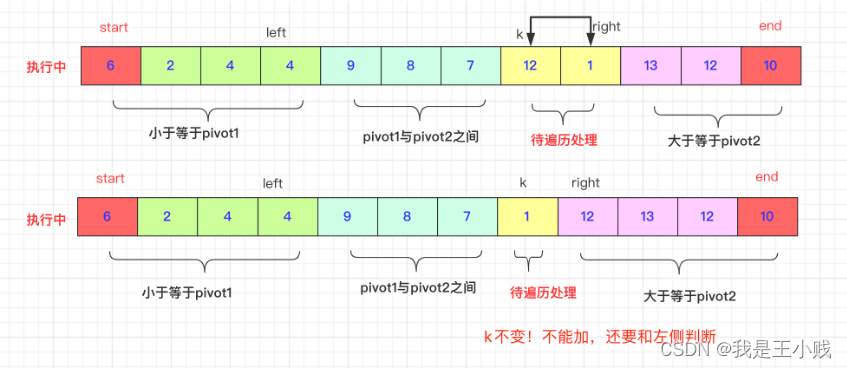
If it is between the two, k++ can.
如果是介于两者之间,k++即可
收尾工作
After executing this trip, that is, k=right, the values of pivot1 and pivot2 need to be exchanged.
在执行完这一趟即k=right之后,即开始需要将pivot1和pivot2的数值进行交换
swap(arr, start, left);
swap(arr, end, right);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NxtbgvE1-1666593763713)(/.attachments/1663724861907-7403adb9-2387-4cc2-a90e-43990ea57511.png)]](https://img-blog.csdnimg.cn/8c3f620d2f174bd6b71904c75f5f0d01.png)
Then the three intervals can recursively execute the sorting function according to the number.
然后三个区间根据编号递归执行排序函数即可。
4. Samples
4.1 Parallel Streaming Data Processing (并行流式数据处理)
Many of the stream processing are suitable for the idea of divide and conquer, which greatly improves the performance of the code when processing a large set. The designers of java8 also saw this, so they provide parallel streams processing. In the above examples, we all call the stream() method to start stream processing. Java8 also provides parallelStream() to start parallel stream processing. ParallelStream() is essentially implemented based on the Fork-Join framework of java7, and its default thread The number is the number of cores of the host.
流式处理中的很多都适合采用 分而治之 的思想,从而在处理集合较大时,极大的提高代码的性能,java8的设计者也看到了这一点,所以提供了 并行流式处理。上面的例子中我们都是调用stream()方法来启动流式处理,java8还提供了parallelStream()来启动并行流式处理,parallelStream()本质上基于java7的Fork-Join框架实现,其默认的线程数为宿主机的内核数。
Although it is simple to start parallel streaming, you only need to replace stream() with parallelStream(), but since it is parallel, it will involve multi-thread safety issues, so before enabling it, you must first confirm whether parallel is worthwhile (parallel efficiency Not necessarily higher than sequential execution), the other is to ensure thread safety. These two items are not guaranteed, so there is no point in parallelism, after all results are more important than speed.
启动并行流式处理虽然简单,只需要将stream()替换成parallelStream()即可,但既然是并行,就会涉及到多线程安全问题,所以在启用之前要先确认并行是否值得(并行的效率不一定高于顺序执行),另外就是要保证线程安全。此两项无法保证,那么并行毫无意义,毕竟结果比速度更加重要。
4.1.1 认识和开启并行流
Parallel streaming is a stream that divides the content of a stream into multiple data blocks and processes each different data block separately with different threads. For example, there is such a requirement:
并行流就是将一个流的内容分成多个数据块,并用不同的线程分别处理每个不同数据块的流。例如有这么一个需求:
There is a List collection, and each apple object in the list has only weight. We also know that the unit price of apple is 5 yuan/kg. Now we need to calculate the unit price of each apple. The traditional way is as follows:
有一个 List 集合,而 list 中每个 apple 对象只有重量,我们也知道 apple 的单价是 5元/kg,现在需要计算出每个 apple 的单价,传统的方式是这样:
List<Apple> appleList = new ArrayList<>(); // 假装数据是从库里查出来的
for (Apple apple : appleList) {
apple.setPrice(5.0 * apple.getWeight() / 1000);
}
We complete the calculation of the price of each apple by traversing the apple objects in the list through an iterator. The time complexity of this algorithm is O(list.size()) As the size of the list increases, the time-consuming will also increase linearly. Parallel streams can greatly reduce this time. The way to process the collection in parallel is as follows:
我们通过迭代器遍历 list 中的 apple 对象,完成了每个 apple 价格的计算。而这个算法的时间复杂度是 O(list.size()) 随着 list 大小的增加,耗时也会跟着线性增加。并行流可以大大缩短这个时间。并行流处理该集合的方法如下:
appleList.parallelStream().forEach(apple -> apple.setPrice(5.0 * apple.getWeight() / 1000));
The difference from ordinary streams is the parallelStream() method called here. Of course, it is also possible to convert a normal stream to a parallel stream by stream.parallel() . Parallel streams can also be converted to sequential streams via the sequential() method, but be careful: parallel and sequential conversion of streams does not actually change the stream itself, just a flag. And perform multiple parallel/sequential transformations of the stream on a pipeline, which takes effect on the last method call.
和普通流的区别是这里调用的 parallelStream() 方法。当然也可以通过 stream.parallel() 将普通流转换成并行流。并行流也能通过 sequential() 方法转换为顺序流,但要注意:流的并行和顺序转换不会对流本身做任何实际的变化,仅仅是打了个标记而已。并且在一条流水线上对流进行多次并行 / 顺序的转换,生效的是最后一次的方法调用。
并行流如此方便,它的线程从那里来呢?有多少个?怎么配置呢?
The default ForkJoinPool thread pool is used internally by the parallel stream. The default number of threads is the number of cores of the processor, and the configuration system core property:
并行流内部使用了默认的 ForkJoinPool 线程池。默认的线程数量就是处理器的核心数,而配置系统核心属性:
java.util.concurrent.ForkJoinPool.common.parallelism can change the thread pool size. But the value is a global variable. Changing it affects all parallel streams. There is currently no way to configure a dedicated number of threads per stream. Generally speaking, the number of processor cores is a good choice.java.util.concurrent.ForkJoinPool.common.parallelism 可以改变线程池大小。不过该值是全局变量。改变他会影响所有并行流。目前还无法为每个流配置专属的线程数。一般来说采用处理器核心数是不错的选择。
4.1.2 测试并行流的性能
In order to test the performance more easily, we let the thread sleep for 1s after each calculation of the apple price, indicating that other IO-related operations were performed during this period, and output the time-consuming of program execution and the time-consuming of sequential execution:
为了更容易的测试性能,我们在每次计算完苹果价格后,让线程睡 1s,表示在这期间执行了其他 IO 相关的操作,并输出程序执行耗时,顺序执行的耗时:
public static void main(String[] args) throws InterruptedException {
List<Apple> appleList = initAppleList();
Date begin = new Date();
for (Apple apple : appleList) {
apple.setPrice(5.0 * apple.getWeight() / 1000);
Thread.sleep(1000);
}
Date end = new Date();
log.info("苹果数量:{}个, 耗时:{}s", appleList.size(), (end.getTime() - begin.getTime()) /1000);
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cQSkv471-1666593763714)(/.attachments/1663724903258-79309a91-7796-48ca-ba3e-536c50d00603.png)]](https://img-blog.csdnimg.cn/4c5ac84d4d6e4c4cbbf31e5895415f89.png)
并行版本
List appleList = initAppleList();
Date begin = new Date();
appleList.parallelStream().forEach(apple ->
{
apple.setPrice(5.0 * apple.getWeight() / 1000);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
);
Date end = new Date();
log.info("苹果数量:{}个, 耗时:{}s", appleList.size(), (end.getTime() - begin.getTime()) /1000);
耗时情况
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xEt1pNgX-1666593763714)(/.attachments/1663724927154-a3c19e2e-4438-487c-bd7c-d60db083772a.png)]](https://img-blog.csdnimg.cn/e00883b578964163bb276b3f555b6944.png)
Consistent with our prediction, my computer is a quad-core I5 processor. After parallelization is turned on, each of the four processors executes a thread, and the task is completed in the last 1s!
跟我们的预测一致,我的电脑是 四核I5 处理器,开启并行后四个处理器每人执行一个线程,最后 1s 完成了任务!
可拆分性影响流的速度
Through the above test, some people will easily come to a conclusion: parallel stream is very fast, we can completely abandon the external iteration of foreach/fori/iter and use the internal iteration provided by Stream. Is this really the case? Are parallel streams really so perfect? The answer is of course no. You can copy the code below and test it on your own computer. After testing it can be found that parallel streams are not always the fastest way to process.
通过上面的测试,有的人会轻易得到一个结论:并行流很快,我们可以完全放弃 foreach/fori/iter 外部迭代,使用 Stream 提供的内部迭代来实现了。事实真的是这样吗?并行流真的如此完美吗?答案当然是否定的。大家可以复制下面的代码,在自己的电脑上测试。测试完后可以发现,并行流并不总是最快的处理方式。
For the first n numbers processed by the iterate method, regardless of whether it is parallel or not, it is always slower than the loop. The non-parallel version can be understood as the stream operation is slower than the bottom layer without loop. Why is the parallelizable version slow? There are two points to note here:
对于 iterate 方法来处理的前 n 个数字来说,不管并行与否,它总是慢于循环的,非并行版本可以理解为流化操作没有循环更偏向底层导致的慢。可并行版本是为什么慢呢?这里有两个需要注意的点:
- iterate produces boxed objects, which must be unboxed into numbers to sum
iterate 生成的是装箱的对象,必须拆箱成数字才能求和 - It is difficult for us to divide iterate into multiple independent chunks to execute in parallel
我们很难把 iterate 分成多个独立的块来并行执行
This question is interesting and we have to realize that some stream operations are easier to parallelize than others. For iterate, each application of this function depends on the result of the previous application. So in this case, not only can we not effectively divide the stream into small chunks for processing. On the contrary, it also increases the cost again because of parallelization.
这个问题很有意思,我们必须意识到某些流操作比其他操作更容易并行化。对于 iterate 来说,每次应用这个函数都要依赖于前一次应用的结果。因此在这种情况下,我们不仅不能有效的将流划分成小块处理。反而还因为并行化再次增加了开支。
For the LongStream.rangeClosed() method, the second pain point of iterate does not exist. It generates values of basic types without unboxing operations, and it can directly split the number 1 - n to be generated into 1 - n/4, 1n/4 - 2n/4, … 3n/4 - n such four parts. So rangeClosed() in parallel is faster than iterating outside the for loop.
而对于 LongStream.rangeClosed() 方法来说,就不存在 iterate 的第两个痛点了。它生成的是基本类型的值,不用拆装箱操作,另外它可以直接将要生成的数字 1 - n 拆分成 1 - n/4, 1n/4 - 2n/4, … 3n/4 - n 这样四部分。因此并行状态下的 rangeClosed() 是快于 for 循环外部迭代的。
package lambdasinaction.chap7;
import java.util.stream.*;
public class ParallelStreams {
public static long iterativeSum(long n) {
long result = 0;
for (long i = 0; i <= n; i++) {
result += i;
}
return result;
}
public static long sequentialSum(long n) {
return Stream.iterate(1L, i -> i + 1).limit(n).reduce(Long::sum).get();
}
public static long parallelSum(long n) {
return Stream.iterate(1L, i -> i + 1).limit(n).parallel().reduce(Long::sum).get();
}
public static long rangedSum(long n) {
return LongStream.rangeClosed(1, n).reduce(Long::sum).getAsLong();
}
public static long parallelRangedSum(long n) {
return LongStream.rangeClosed(1, n).parallel().reduce(Long::sum).getAsLong();
}
}
package lambdasinaction.chap7;
import java.util.concurrent.*;
import java.util.function.*;
public class ParallelStreamsHarness {
public static final ForkJoinPool FORK_JOIN_POOL = new ForkJoinPool();
public static void main(String[] args) {
System.out.println("Iterative Sum done in: " + measurePerf(ParallelStreams::iterativeSum, 10_000_000L) + " msecs");
System.out.println("Sequential Sum done in: " + measurePerf(ParallelStreams::sequentialSum, 10_000_000L) + " msecs");
System.out.println("Parallel forkJoinSum done in: " + measurePerf(ParallelStreams::parallelSum, 10_000_000L) + " msecs" );
System.out.println("Range forkJoinSum done in: " + measurePerf(ParallelStreams::rangedSum, 10_000_000L) + " msecs");
System.out.println("Parallel range forkJoinSum done in: " + measurePerf(ParallelStreams::parallelRangedSum, 10_000_000L) + " msecs" );
}
public static <T, R> long measurePerf(Function<T, R> f, T input) {
long fastest = Long.MAX_VALUE;
for (int i = 0; i < 10; i++) {
long start = System.nanoTime();
R result = f.apply(input);
long duration = (System.nanoTime() - start) / 1_000_000;
System.out.println("Result: " + result);
if (duration < fastest) fastest = duration;
}
return fastest;
}
}
共享变量修改的问题
Although parallel streams easily implement multi-threading, it still does not solve the problem of modifying shared variables in multi-threading. There is a shared variable total in the following code, which uses sequential flow and parallel flow to calculate the sum of the first n natural numbers:
并行流虽然轻易的实现了多线程,但是仍未解决多线程中共享变量的修改问题。下面代码中存在共享变量 total,分别使用顺序流和并行流计算前n个自然数的和:
public static long sideEffectSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).forEach(accumulator::add);
return accumulator.total;
}
public static long sideEffectParallelSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).parallel().forEach(accumulator::add);
return accumulator.total;
}
public static class Accumulator {
private long total = 0;
public void add(long value) {
total += value;
}
}
The result of each output of sequential execution is: 50000005000000, while the results of parallel execution are varied. This is because there is a data race every time the totle is accessed. Therefore, it is not recommended to use parallel streams when there are operations that modify shared variables in the code.
顺序执行每次输出的结果都是:50000005000000,而并行执行的结果却五花八门了。这是因为每次访问 totle 都会存在数据竞争。因此当代码中存在修改共享变量的操作时,是不建议使用并行流的。
并行流的使用注意
The following points need to be paid attention to when using parallel streams:
在并行流的使用上有下面几点需要注意:
Try to use raw data streams such as LongStream / IntStream / DoubleStream instead of Stream to process numbers to avoid the extra overhead of frequent unboxing.
尽量使用 LongStream / IntStream / DoubleStream 等原始数据流代替 Stream 来处理数字,以避免频繁拆装箱带来的额外开销。
To consider the total computational cost of a stream’s operation pipeline, let N be the total number of tasks to operate and Q the time per operation. N * Q is the total time of the operation, and a higher value of Q means a higher probability of benefit from using parallel streams.
要考虑流的操作流水线的总计算成本,假设 N 是要操作的任务总数,Q 是每次操作的时间。N * Q 就是操作的总时间,Q 值越大就意味着使用并行流带来收益的可能性越大。
For example, several types of resources are sent from the front end and need to be stored in the database. Each resource corresponds to a different table. We can consider that the number of types is N, and the network time spent storing the database + the time spent inserting is Q. In general, the network time-consuming is relatively large. Therefore, this operation is more suitable for parallel processing. Of course, when the number of types is greater than the number of cores, the performance improvement of this operation will be discounted to a certain extent.
例如:前端传来几种类型的资源,需要存储到数据库。每种资源对应不同的表。我们可以视作类型数为 N,存储数据库的网络耗时 + 插入操作耗时为 Q。一般情况下网络耗时都是比较大的。因此该操作就比较适合并行处理。当然当类型数目大于核心数时,该操作的性能提升就会打一定的折扣了。
The following is a splittable performance table for some common collection frameworks corresponding to streams:
以下是一些常见的集合框架对应流的可拆分性能表:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bHqNojiu-1666593763715)(/.attachments/1663600029868-9bf4c2a8-5d96-4c84-9a95-b4d7cf7901fe.png)]](https://img-blog.csdnimg.cn/c4bbf8d2d15d4b21a4704b973d6c474c.png)

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











